Analysis of the Architecture and Algorithm Applications of Li Auto's Next-Generation Foundation Model Mind VLA-o1
 03/23 2026
03/23 2026
 645
645
At GTC 2026, Zhan Kun from Li Auto officially released its next-generation autonomous driving foundation model, Mind VLA-o1. This move not only signifies Li Auto's unwavering commitment to the VLA (Vision-Language-Action) architecture but also reflects broader industry trends.
Judging from the announcements at this GTC, VLA has emerged as the mainstream algorithm in both autonomous vehicles and embodied AI. As we shared in our article "Two Schools of Embodied AI Algorithms: VLA and World Models," Wang Xingxing, CEO of Unitree Technology—another participant at GTC—also highlighted in his presentation that VLA is the dominant algorithm in current embodied AI research.
1. True VLA Integration in Vehicles: Three Major Challenges
However, despite Li Auto championing VLA for nearly a year and many industry players following suit, real-world performance often falls short of what is promised in advertisements or academic papers. During his GTC presentation, Zhan Kun admitted that current mainstream VLA models still face three critical challenges when deployed in vehicles:
Latency in Aligning Perception, Language, and Actions: In existing architectures, a slow alignment process between 3D visual understanding, language comprehension, and final action generation leads to significant processing delays, failing to meet the stringent real-time requirements of vehicle systems.
Computational Efficiency and System Cost Bottlenecks: VLA models often incorporate large-scale language capabilities, resulting in substantial computational and memory overheads. Running complex VLA models on compute-constrained in-vehicle hardware systems presents a highly practical challenge.
Data Expansion Challenges for Long-Tail Scenarios: Traditional data collection methods alone cannot effectively or comprehensively cover the complex and rare "long-tail scenarios" encountered in autonomous driving.
Therefore, to enable true large-scale VLA integration in vehicles, these three challenges must be overcome.
Currently, the third issue appears relatively easier to address. With the maturation of virtual simulation technologies and the increasing volume of real-world data collected by test vehicles, some solutions have emerged. However, the first two challenges require continuous iteration and development of both industrial and software technologies over time.
Building on this, Li Auto's next-generation autonomous driving foundation model, Mind VLA-o1, unveiled at GTC, represents their new software-level solution. While labeled as "next-generation," it should not be assumed that this model is already deployed in vehicles or that full-scale mass production is imminent this year (though, given Li Auto's track record of aggressive execution, this cannot be entirely ruled out).
During the presentation, Zhan Kun showcased a simplified diagram of the model's architecture. It features a highly typical end-to-end structure, where each module is integrated into a unified model for representation learning and decision-making. However, it is important to note that this is likely a highly abstracted illustration for ease of understanding, as real-world network architectures are inevitably far more complex.
Zhan Kun emphasized that Mind VLA-o1 is a "native multimodal" Transformer. By "native multimodal," he means that visual, linguistic, and action modalities are jointly trained and aligned from the model's inception, rather than being simply combined as separate modules at a later stage. This design enables the model to operate within a unified representation space, achieving higher computational efficiency and stronger generalization capabilities—the essence of an "end-to-end VLA."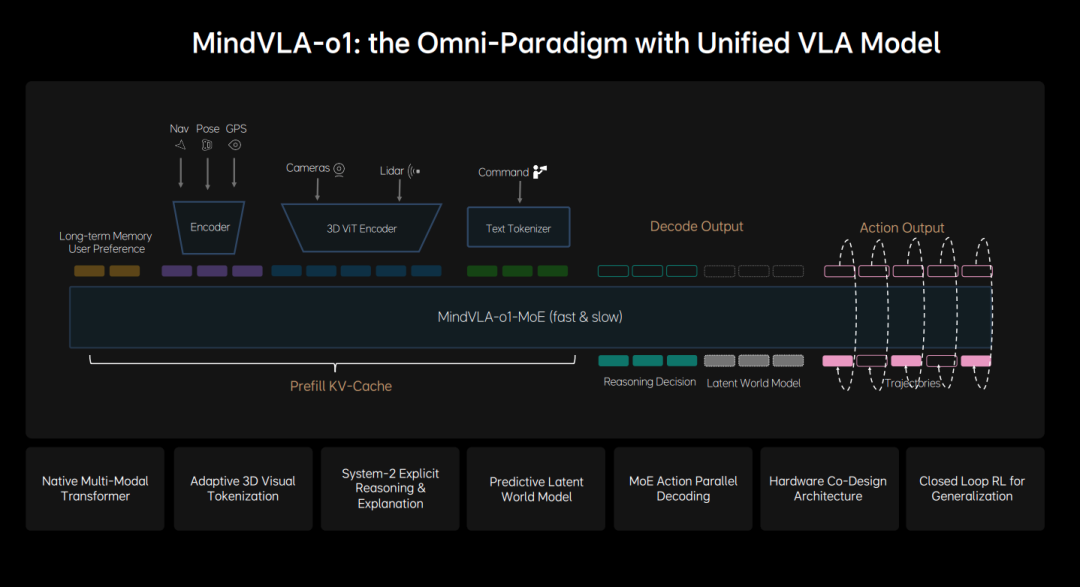
2. Mind VLA-o1 Input Layer: Building AI's "Sensory Perception" and "Memory"
Let's first examine the system's input component. At the input stage, the system must collect comprehensive environmental information and instructional inputs, much like a human. Specifically, it includes the following key input layers and encoders:
Sensory and Spatial Inputs: These receive visual data from multiple cameras and 3D geometric data from LiDAR. Li Auto has consistently emphasized its use of a native 3D ViT encoder. This data is extracted via the 3D ViT Encoder and LiDAR Encoder, directly encoded into native 3D spatial tokens. This approach to modeling the 3D world enables the AI to construct a true 3D representation of the physical environment during the feature extraction phase.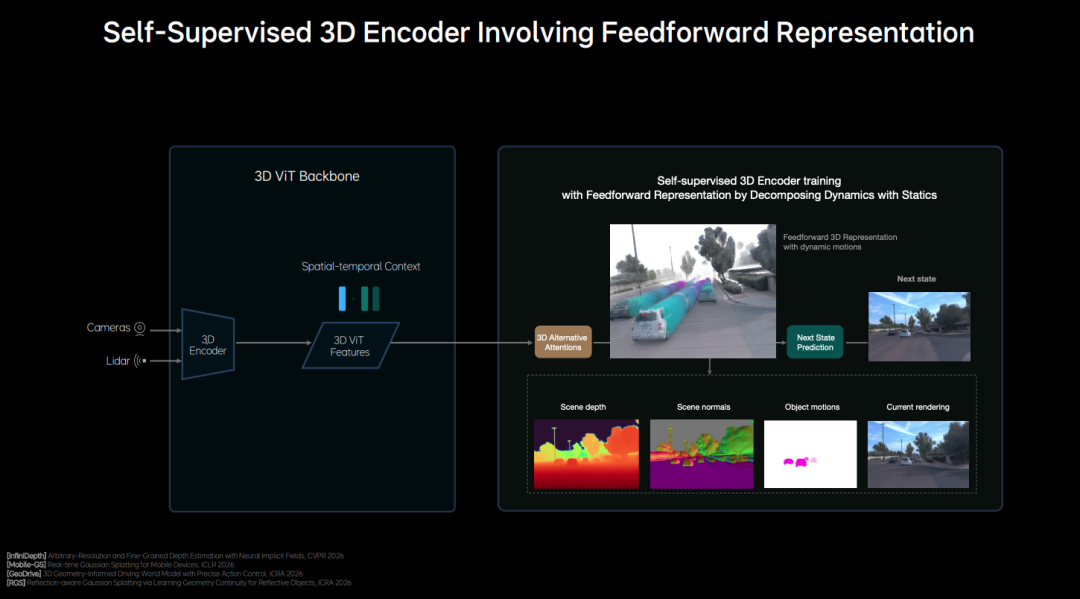
State & Navigation Inputs: These include the vehicle's current pose, GPS positioning, and navigation route information. These inputs are fed into the system via dedicated encoders.
Language Command Inputs: These receive natural language instructions from passengers (e.g., "Park the car next to the orange vehicle"). These instructions are transformed into language features understandable by the large model via a text tokenizer.
Contextual Inputs: The system also incorporates users' long-term memory and preferences to ensure AI decision-making aligns more closely with specific usage scenarios and individual driver habits.
From a product design perspective, Li Auto has developed a VLA system that natively supports voice interaction and integrates users' historical preferences. The company has also indicated that it retains a language model within the system—likely serving as one of the Experts in a Mixture of Experts (MoE) architecture. The language model plays several key roles: semantic understanding, common-sense knowledge, and interaction capabilities.
All input signals, once encoded by their respective encoders, are uniformly injected into the Prefill KV-Cache at the front end of the model. The Prefill KV-Cache is a technique used to accelerate large language model (LLM) inference: when the system receives a prompt, the model first enters a "prefill" stage, precomputing and storing the keys (Key) and values (Value) of all input tokens in the cache (KV-Cache). This eliminates the need for redundant computations during subsequent token generation (decoding), significantly boosting inference speed.
3. Mind VLA-o1 Output Layer: From "Multimodal Thinking" to "Precise Actions"
After processing through a unified MoE architecture, the system reaches the output layer (Decode Output). Here, the model not only generates final driving actions but also outputs its understanding and predictions of the surrounding world. This layer primarily consists of three parallel output modules:
Latent World Model: This is the AI's "imagination" layer. Rather than directly generating real images, it outputs a set of latent space representations (Future Latent Tokens) describing potential future evolutions. Through this layer, the model mentally simulates and predicts possible scenarios over the next few seconds (e.g., anticipating whether a neighboring vehicle might suddenly cut in). By predicting scene changes at low cost in the latent space, the system can assist in making better decisions. When making driving decisions, the model not only understands the current scene and makes logical judgments but also pre-imagines future scenarios in the latent space, visualizing driving decisions. Li Auto refers to this capability as "Generative Multi-modal Thinking."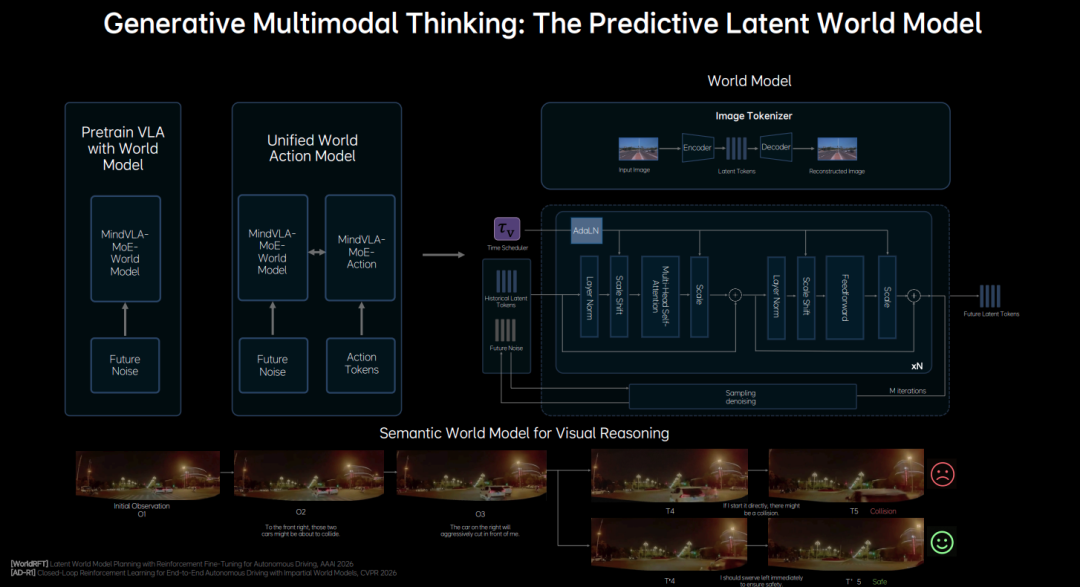
Explicit Reasoning and Decision-Making: This is the AI's "logical expression" layer. The model (via modules such as the LM head) outputs a logical reasoning process based on Chain-of-Thought (CoT) reasoning. It performs explicit semantic analysis and deep decision-making for complex scenarios. This corresponds to what Li Auto refers to as "System 2" and represents an area where current VLA models excel and demonstrate strong product differentiation.
High-Precision Action Output (Action Output / Trajectories): This is the system's final output for interacting with the physical world. The "Action Expert," responsible for actions, integrates all prior understanding and predictions to directly generate specific driving trajectories via the Action head. To meet the real-time requirements of autonomous driving, Li Auto has abandoned the traditional "point-by-point generation" approach in favor of "parallel decoding" technology, which generates all trajectory points simultaneously. Additionally, the system employs "discrete diffusion" technology for multi-step denoising and optimization, ensuring that the final output trajectories are both responsive and smooth.
In summary, Mind VLA achieves complex understanding and mental simulation of the physical world within a unified Transformer architecture through diverse perceptual, state, and language input layers. Ultimately, at the output layer, it simultaneously provides explicit language-based logical reasoning, future predictions via a latent world model, and low-latency, high-precision autonomous driving trajectories.
4. Training and Deployment: Closed-Loop Reinforcement Learning and Hardware-Software Synergy
After establishing the end-to-end architecture, the next step is model training. Li Auto has developed a closed-loop reinforcement learning framework for this purpose. In this framework, the model learns not only from real-world collected data but also continuously explores and optimizes within a "World Simulator." This means the system can experiment with new driving strategies in simulated environments and self-update based on environmental feedback.
Currently, companies focused on autonomous driving algorithm development have amassed vast repositories of foundational data. The emphasis now lies in supplementing this data with "difficult datasets" collected during human takeovers. Subsequently, these difficult datasets are used for simulation testing and feedback adjustment within the World Simulator, ultimately achieving closed-loop reinforcement learning.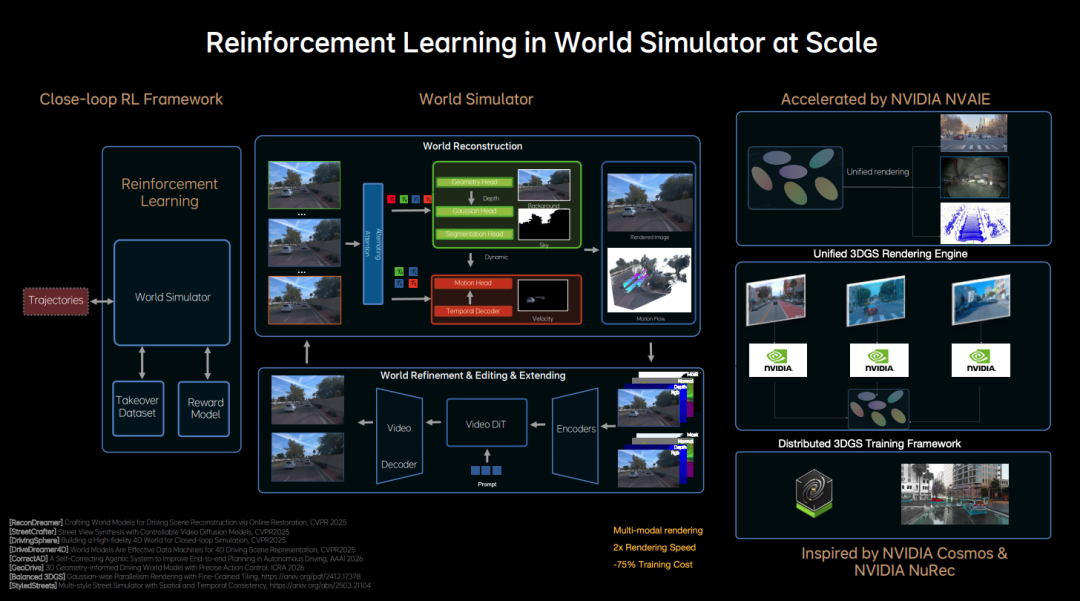
When constructing the World Simulator, Li Auto leveraged Nvidia Cosmos and Nvidia NeRF, two powerful tools, to build a unified 3D GS rendering engine and distributed training framework.
With the VLA end-to-end algorithm framework and the capability for continuous iterative training via virtual simulation, the final hurdle for autonomous driving algorithms becomes "how to optimally utilize existing in-vehicle computational power and memory bandwidth." In response, Li Auto stated that it has established a unified analytical framework that integrates model performance with hardware constraints. This hardware-software synergistic system will significantly enhance the design efficiency and ultimate deployment speed of end-side VLA models.
5. Conclusion: From Autonomous Driving to Embodied AI
In summary, the release of Li Auto's Mind VLA-o1 does not represent a fundamental restructuring of current autonomous driving technology but does mark a solid step forward toward higher-order "embodied AI."
From the broader perspective of GTC 2026, the unification around VLA architecture has become an irreversible trend. Through native multimodal Transformers, generative multimodal thinking, closed-loop reinforcement learning, and hardware-software collaboration design (co-design), Li Auto has addressed the three key pain points of latency, computational efficiency, and long-tail scenarios, offering the industry a perspective on the core challenge of "how to truly run VLA on in-vehicle chips."
As acknowledged during the presentation, this technological path remains fraught with challenges, and the perfect next-generation VLA will require time and data to reach mass production readiness. However, it is undeniable that when a system possesses native multimodal perception, human-like "System 2" logical reasoning, and the ability to "dream and simulate the future" in latent space, the very nature of the automobile transforms.
It will no longer be merely a vehicle operating under predefined rules but will evolve into an intelligent robot capable of truly understanding the physical world and making autonomous decisions. Represented by Mind VLA-o1, this new generation of foundation models serves as a critical key to unlocking the door to embodied AI. We have reason to believe that the future of physical AI comprehensively managing the real world will arrive sooner than we imagine.
Finally, while algorithms are essential tools for autonomous driving, the products themselves deeply interact with real-world application scenarios. For those interested in autonomous driving products, we recommend reading "Who Should Read
References and Images
Unleashing the Omni-Paradigm for Next-Gen Autonomous Driving with Unified VLA Models pdf - Li Auto Zhan Kun *Reproduction and Excerpting Prohibited Without Permission-
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
Why Is Nokia Making a Comeback in the AI Era?