DeepRoute.ai's 40B VLA Autonomous Driving Foundation Model and Methodology
 03/23 2026
03/23 2026
 638
638
As a rising star among China's ADAS/autonomous driving algorithm providers, DeepRoute.ai has seen a significant increase in mass-produced vehicles over the past two years, securing partnerships with Great Wall Motors, Geely, and even reportedly winning business from new-energy vehicle maker Leapmotor. Moreover, DeepRoute.ai was among the early adopters to promote and mass-produce "VLA" solutions.
Thus, it is a forward-looking autonomous driving solution provider with mass-production capabilities. At GTC 2026, DeepRoute.ai's CTO, Tongyi Cao, delivered a speech titled 'Redefining the Boundaries of Autonomous Driving with Foundation Model,' sharing its VLA methodology and theory based on the foundation model.
This article shares the core content and highlights of the speech through industry knowledge.
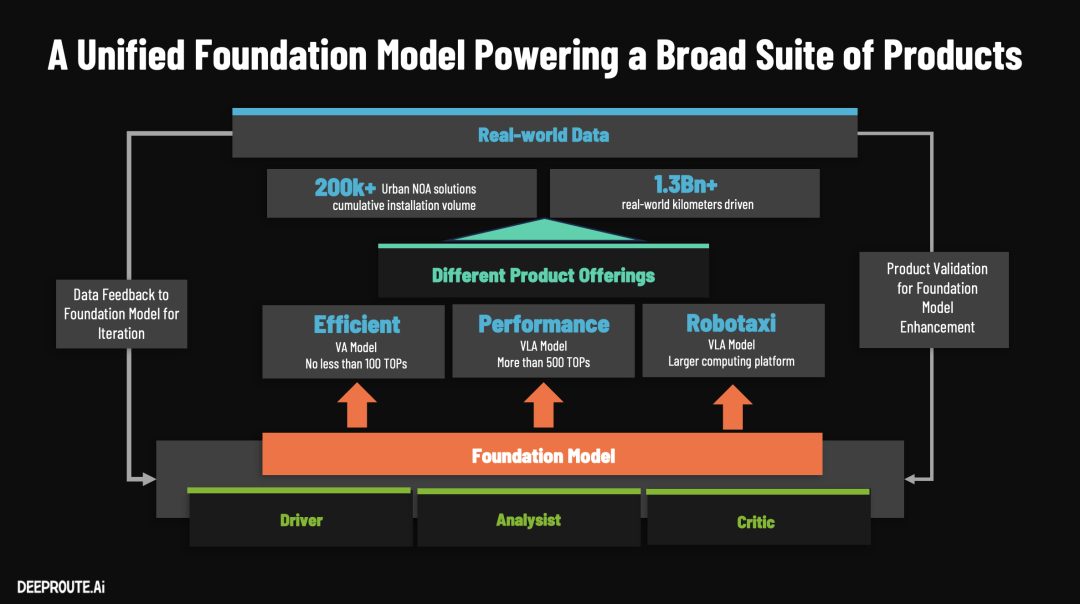
DeepRoute.ai's (DeepRoute.ai) core approach to achieving autonomous driving, even towards L5-level autonomy, is its belief in the 'Scaling Law.' By constructing a unified foundation model, it aims to drive simultaneous growth in model size and data scale.
This reflects the industry's confidence in the current end-to-end technologies, seeing the dawn of autonomous driving. The current industry focus is on optimizing algorithms, increasing model parameters, advancing compute chips, and refining engineering implementation.
Below are the technical highlights of DeepRoute.ai's foundation model architecture and autonomous driving software methods:
I. Technical Highlights of the Foundation Model (40B VLA) Architecture and Principles
DeepRoute.ai built a native 40B-parameter VLA (Vision-Language-Action) model based on 100 million GB of video data. Xpeng also announced at the end of last year that it had developed a 72B-parameter (72 billion) ultra-large-scale model trained on 200 million clips (approximately 10 billion GB of data).
DeepRoute.ai stated that it has made the following underlying innovations in training mechanisms and on-device deployment:
1. Architectural Innovation: 'Trinity' Model Roles This large model breaks away from the single role of being merely a 'driver.' It integrates three capabilities within a single model: driver, analyst, and commentator/referee. This capability reuse not only allows for shared cognition and scenario understanding but also effectively enhances the performance of driving tasks themselves. In essence, this model can interpret sensor input data streams like videos, reason and analyze them, and ultimately provide evaluations of good or bad outcomes.
2. Breakthrough in Pre-training Principles: From 'Trajectory Supervision' to 'Video Prediction' Traditional end-to-end models typically rely on driving trajectories for supervised training, but this results in significant data waste—out of 1 PB of driving video, trajectory data accounts for only about 10 GB, representing a data utilization rate of just 0.001%. DeepRoute.ai innovatively adopted video prediction tasks during the pre-training stage to enable the model to understand the world, meaning every pixel in the video serves as a supervisory signal, achieving 100% data utilization and providing ultra-high-quality representations of the physical world for large-parameter models.
3. Cross-Modal Reasoning Integration in Mid-training After acquiring an understanding of the world, the model undergoes joint training on three core tasks:
V+A (Vision+Action): Learning conventional end-to-end driving, a typical end-to-end architecture.
V+A -> L (Post-Action Explanation): Activating the analyst and referee roles, taking visual and action sequences as input, and outputting abstract descriptions of key events, causal explanations of behaviors, and evaluations of good or bad outcomes.
V -> L+A (Multimodal Logical Reasoning): Training drivers with reasoning capabilities. Given visual input, the model uses Chain-of-Thought (CoT) to first output linguistic descriptions of key events and decision-making logic before outputting specific driving trajectories.

4. Extreme On-Device Deployment Optimization and Mass-Production Distillation According to Tongyi Cao's presentation at GTC, DeepRoute.ai's VLA may currently achieve real-time closed-loop control at 10-15 Hz on the vehicle side (to understand why real-time closed-loop control is important, refer to our previous article 'Revealing Tesla FSD's Core: The 'Three Major Challenges' and 'Unique Solutions' of End-to-End Algorithms and Thoughts on Voice-Controlled Driving').

DeepRoute.ai stated that it has introduced KV Cache (avoiding redundant computation of historical features, a technique also adopted by Li Auto as mentioned at GTC), Multi-Token Prediction (MTP), quantization techniques, and a customized inference engine to strictly control the single-step processing delay within 60-85 milliseconds for inputs containing 1000 visual tokens and dozens of reasoning tokens. Additionally, the foundation model can be flexibly 'distilled' based on the on-device chip's compute capabilities: deploying a pure driving VA model on 100 TOPS platforms and a VLA model with logical reasoning capabilities on 500 TOPS platforms.
II. Highlights of Autonomous Driving Software and Data Methods
At the software and data engineering level, DeepRoute.ai has completely refactor (reconstructed) its data closed-loop and simulation systems, addressing industry pain points such as 'boring data harming model performance' and inefficient manual intervention:
1. Rapid Data Closed-Loop Fully Managed by Large Models Traditional data closed-loops (problem identification, diagnosis, mining, labeling, training) heavily rely on manual or small rule-based models, often taking 5 days (over 100 hours) per cycle with limited capability accumulation. DeepRoute.ai directly utilizes its foundation model (leveraging its analyst and referee capabilities) to take over the entire process of data mining, automatic diagnosis, Chain-of-Thought (CoT) labeling, and action scoring. This not only reduces the closed-loop cycle from 5 days to just 12 hours but, more importantly, ensures that all manual reviews and machine labeling results generated during the closed-loop process become new nourishment for the model's mid-training, achieving a flywheel effect of increasing AI capabilities.

2. Breakthrough Data Synthesis Technology for Long-Tail Scenarios Facing rare and high-risk scenarios (Long-Tail Scenarios) that are difficult to collect in reality, DeepRoute.ai employs advanced generative and synthesis techniques:
3D Reconstruction and Style Transfer: Utilizing Nvidia's 3D GUT for high-fidelity reconstruction and the Cosmos model for weather and lighting style transfer, transforming daytime footage into rainy or nighttime variants.
DiPIR Plug-and-Edit: This is a self-developed technology by DeepRoute.ai capable of seamlessly inserting generated 3D pedestrians, cyclists, or animals (such as sheep suddenly darting onto the highway) into real road videos while automatically matching lighting and shadows, systematically batch-generating 'extremely dangerous and hard-to-capture' training data.
3. Reinforcement Learning (RL) Self-Evolution in Simulated Environments During simulation backtesting, DeepRoute.ai's model no longer solely relies on human-provided standard answers (as humans struggle to label perfect trajectories in extreme scenarios). The foundation model can 'sample (Rollout)' multiple different driving solutions in reconstructed simulated scenarios (e.g., when encountering illegal lane cuts, whether to choose a harsh brake that feels uncomfortable or a lateral evasion). Subsequently, the model's internal 'commentator (Critic)' analyzes and scores these trajectories based on preset safety and comfort rules. Through continuous iteration of this closed-loop reinforcement learning (RL Policy Optimization), the model can output safer and more precise decisions in highly complex edge scenarios.
The above represents the core content shared by DeepRoute.ai at GTC 2026. We welcome comments to discuss more algorithm details behind the core.
References and Images
Redefining the Boundaries of Autonomous Driving with Foundation Model - Tongyi Cao, DeepRoute.ai *Strictly prohibited from reproduction or excerpting without permission*
-
![]()
May Auto Sales Insight: Joint Ventures Falter, New Entrants Rise, with Exports Lending Support?
-
![]()
Model Substitution, Data Vending, and Remote-Control Backdoors! Ministry of State Security Alerts to Risks in 'AI Relay Platforms'
-
![]()
Zhao Ming Departs, IPO Postponed, AI Phones Underperform—Can Honor Still Live Up to Its Name?
-
![]()
Explosion of Recording Hardware! Four Major Product Categories Compete for New AI Entry Points, with Agent Capabilities Becoming Standard
-
![]()
China’s LEO Satellite Internet Achieves Strategic Progress: Over 100 Additional Satellites Set for Launch
-
![]()
Musk Sustains $88 Billion Loss in AI Pursuit, Now Rents GPUs to Rivals, Anticipating $500 Billion Revenue Over Three Years
-
![]()
Report | Token Economics: Envisioning a New Path for RMB Internationalization
-
![]()
Trends丨Gartner's Latest Forecast: These Seven Transformations Will Reshape the Technology Landscape Over the Next Five Years