Can Li Auto’s MindVLA-o1 Make Autonomous Driving More Human-Centric?
 03/23 2026
03/23 2026
 645
645
Li Auto’s recently unveiled MindVLA-o1 has generated significant buzz in the industry. Smart Driving Frontier took this opportunity to delve into the distinctions between Li Auto’s and XPENG’s VLA systems. (Related reading: Both XPENG and Li Auto Are Betting on VLA—What Are the Technical Strengths of Each?)
Today, let’s explore the functionalities that Li Auto’s MindVLA-o1 has actually achieved. According to Li Auto’s introduction, the core logic of MindVLA-o1 is clear: it no longer treats autonomous driving as a mere assembly of perception, prediction, and planning modules. Instead, it seeks to directly emulate the driving logic of human drivers through a unified visual-language-action model.
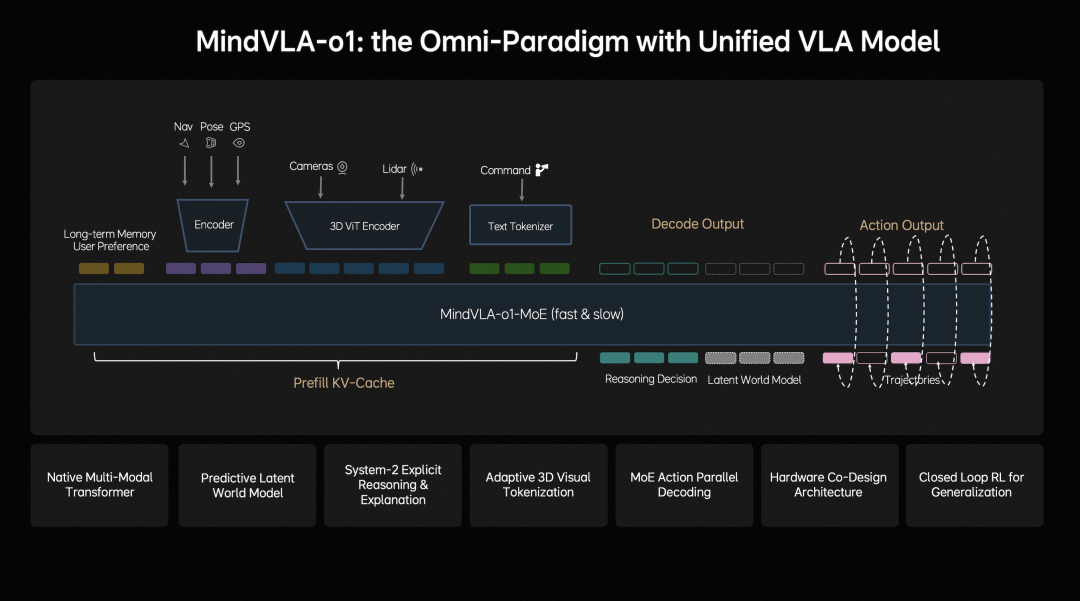
Image Source: Li Auto
This shift means that the vehicle no longer simply executes commands but makes decisions based on a nuanced understanding of the physical world.
In traditional autonomous driving systems, functions are compartmentalized: perception handles visual input, planning makes decisions, and control executes actions. While this approach offers structural clarity, it also has a significant drawback—modules tend to operate in isolation, leading to inefficient information transfer in complex scenarios and hindering the system from forming a cohesive understanding.
MindVLA-o1 aims to consolidate these capabilities into a single model, enabling it to not only “see what is there” but also “understand its meaning” and further determine “what to do next.”
From ‘Seeing the Road’ to ‘Understanding the Road’
At the perception level, MindVLA-o1 goes beyond refining image recognition by enhancing 3D spatial comprehension. Li Auto employs a vision-centric 3D ViT Encoder, utilizing LiDAR point clouds as 3D geometric cues to help the model better grasp real-world spatial structures. The significance of this approach lies in its ability to enable the model to not only identify vehicles, pedestrians, and obstacles ahead but also to place these targets within specific 3D relationships for a more comprehensive understanding.
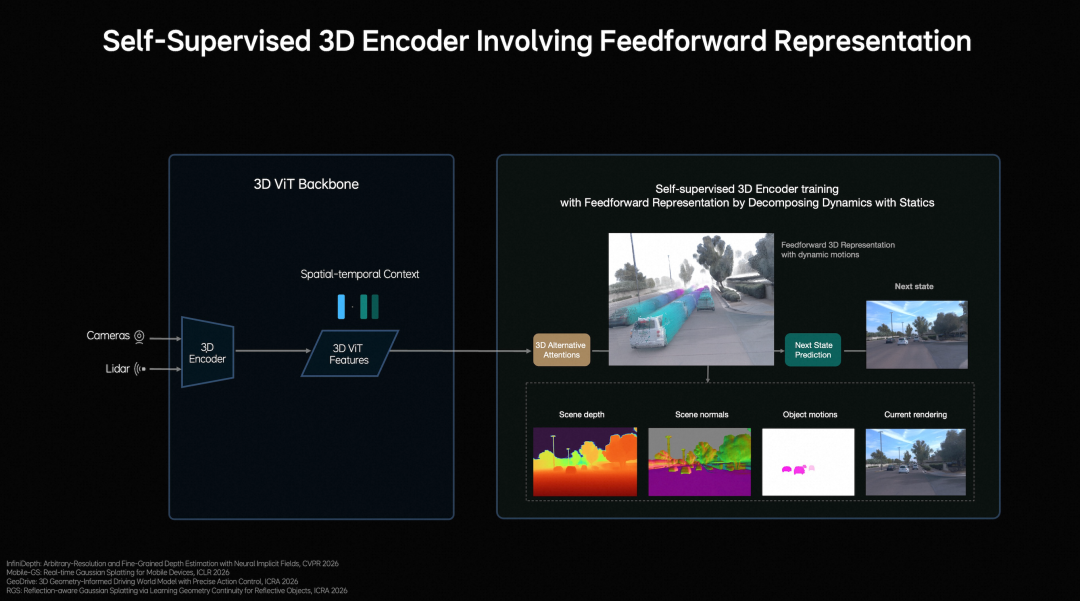
Image Source: Li Auto
This step is crucial because the real challenge in autonomous driving has never been merely “seeing” but “understanding.” The system’s judgment of the same target can vary significantly depending on factors such as distance, occlusion, and road structure. By integrating semantic and 3D spatial information, the model gains a more holistic grasp of the scene.
Li Auto also introduces feedforward 3DGS representation, modeling static environments and dynamic objects separately. It uses next-frame prediction as a self-supervised signal, enabling the model to learn depth, semantics, and motion changes simultaneously. Consequently, the model’s environmental understanding is no longer confined to single-frame images but incorporates a temporal dimension.
Smart Driving Frontier believes this represents a significant leap from 2D recognition to 3D scene understanding in autonomous driving. It addresses a practical issue: vehicles on the road never encounter static images but continuously changing spaces.
From ‘Judging the Present’ to ‘Predicting the Next Moment’
If spatial understanding addresses “seeing clearly in the present,” multimodal reasoning addresses “thinking ahead about what comes next.” Li Auto introduces a predictive latent world model in MindVLA-o1, enabling the model to simulate future scene changes in a latent space.
It does not simply predict the next frame but jointly trains the world model, multimodal reasoning, and driving behavior. This allows the model to internally explore future possibilities before making decisions.
This closely mirrors how human drivers think. Human drivers do not merely observe the current moment but anticipate what might happen next based on road conditions, speed, and the actions of other traffic participants.
MindVLA-o1 aims to embed this capability into the model. It pre-trains latent world tokens through massive video data, continuously reinforces the world model’s predictive ability, and aligns these capabilities with driving actions. As a result, the model not only reacts to the present but also forms judgments about the next few seconds in complex scenarios.
According to Smart Driving Frontier, this is one of the most valuable aspects of MindVLA-o1. Many large models claim to “think,” but in autonomous driving, truly useful thinking is not abstract reasoning but predicting future scene changes.
Speed, distance, trajectory, and relative position all require the model to have a stable understanding of time. Only by incorporating this capability into the system can “thinking deeper” transcend being just a slogan.
From ‘Outputting Actions’ to ‘Driving Stably’
Autonomous driving must ultimately deliver on actions, and action generation often reveals system weaknesses. Li Auto focuses on unified behavior generation.
MindVLA-o1 utilizes a VLA-MoE architecture with an Action Expert to extract information from 3D scene features, navigation goals, and driving instructions. It combines this with multimodal reasoning to directly generate high-precision driving trajectories.
It does not merely assemble results from several modules but minimizes intermediate losses between “understanding” and “action.”
Li Auto also incorporates two crucial designs in this area. One is parallel decoding, which generates all trajectory points simultaneously to enhance real-time performance. The other is discrete diffusion, which optimizes trajectories through multi-round iterations, making them more continuous, stable, and compliant with vehicle dynamics constraints.
This part may not sound as “sophisticated” as perception and reasoning, but it determines whether the vehicle drives smoothly. Whether the model can provide smooth, executable, and controllable actions in complex scenarios ultimately hinges on this layer.
Smart Driving Frontier believes that the significance of MindVLA-o1 in action generation lies not in “driving better” but in beginning to resemble a true driving system rather than a model that merely provides answers.
The real fear in autonomous driving is not failing to see but seeing and yet producing unstable, disjointed actions. Unified behavior generation addresses precisely this issue.
Is MindVLA-o1 an Evolving System?
MindVLA-o1 is not just a static model; it is supported by a comprehensive closed-loop reinforcement learning framework and hardware-software co-design. Li Auto upgrades traditional step-by-step optimization-based reconstruction to feedforward scene reconstruction, enabling the system to generate large-scale, high-fidelity driving scenarios more quickly and continuously train and optimize them using a world simulator.
The core idea is not to rely on a single training session but to let the model continuously refine itself through cycles between simulation and the real world.
Meanwhile, Li Auto considers model design and hardware constraints together. By analyzing computational capabilities and memory bandwidth limitations through the Roofline model and evaluating nearly 2,000 architectural configurations, it ultimately strikes a balance between accuracy and inference latency.
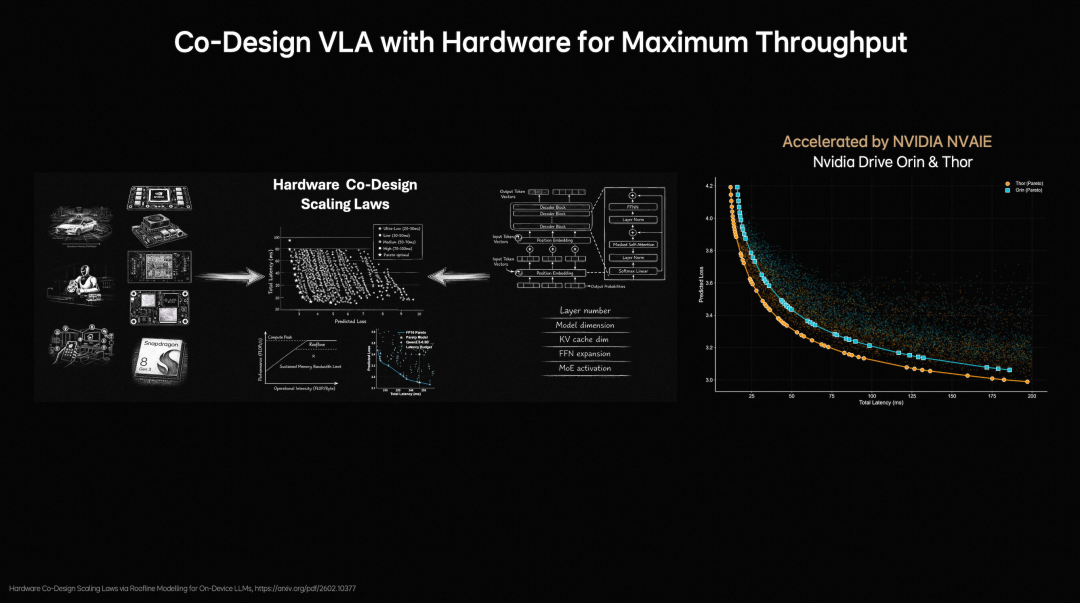
Image Source: Li Auto
This step is crucial because autonomous driving is not a laboratory model competition. No matter how powerful a model is, it is meaningless if it cannot be deployed, runs inefficiently, or cannot be adjusted quickly. MindVLA-o1 is taken seriously not just for its new architecture but also for prioritizing “how to deploy it” equally.
From this perspective, MindVLA-o1 does not achieve a single breakthrough but integrates a suite of capabilities oriented toward physical world intelligence.
Seeing farther involves 3D spatial understanding; thinking deeper involves multimodal reasoning; driving more stably involves unified behavior generation; evolving faster involves closed-loop reinforcement learning; and deploying more efficiently involves hardware-software co-design. Together, these five elements constitute its complete value.
Conclusion
Viewing MindVLA-o1 solely as a new autonomous driving model would be too narrow. What Li Auto truly aims to convey is that autonomous driving is evolving from a “functional system” to a “physical world intelligence system.” While it currently primarily serves vehicles, its structure is no longer limited to them. After unifying vision, language, and action, the model has the potential to extend to other physical systems, such as robots.
-- END --
-
![]()
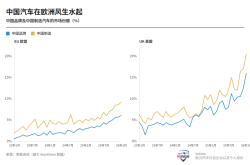
Tariffs Can't Stop Chinese Cars—EU Starts Rewriting the Rules: From Anti-Subsidy Duties to 'Made in Europe' and Beyond
-
![]()
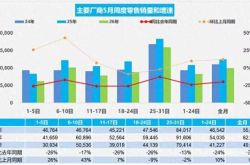
May Auto Sales Insight: Joint Ventures Falter, New Entrants Rise, with Exports Lending Support?
-
![]()
Model Substitution, Data Vending, and Remote-Control Backdoors! Ministry of State Security Alerts to Risks in 'AI Relay Platforms'
-
![]()
Zhao Ming Departs, IPO Postponed, AI Phones Underperform—Can Honor Still Live Up to Its Name?
-
![]()
Explosion of Recording Hardware! Four Major Product Categories Compete for New AI Entry Points, with Agent Capabilities Becoming Standard
-
![]()
China’s LEO Satellite Internet Achieves Strategic Progress: Over 100 Additional Satellites Set for Launch
-
![]()
Musk Sustains $88 Billion Loss in AI Pursuit, Now Rents GPUs to Rivals, Anticipating $500 Billion Revenue Over Three Years
-
![]()
Report | Token Economics: Envisioning a New Path for RMB Internationalization