Say Goodbye to Expensive Subscription Fees! Intel Unveils Hybrid AI Solution: Will Agents Become as Ubiquitous as Utilities?
 04/22 2026
04/22 2026
 678
678
Fresh Lobster, Free Locally?
The first three months of the year have seen OpenClaw become an absolute sensation.
Regardless of whether they're tech-savvy or not, everyone around me is dreaming that once this thing is installed, it will automatically click the mouse, reply to emails, organize local folders, and even handle demanding tasks like coding, creating courseware, and trading stocks.
However, the reality is that this tool not only demands high computer specifications but also requires a hefty monthly Token fee for large models, directly deterring many ordinary people eager to try it out.
Just as everyone was fretting over the cost, Intel stepped in.
On April 21, 2026, Intel held the "Accelerating Agentic AI with Hybrid AI" 2026 Intel Hybrid AI Deployment Solution Sharing Event in Beijing, aiming to share their cloud-plus-local hybrid approach to raising lobsters, which not only saves on expensive subscription fees but also ensures your private files remain confidential.

(Image Source: Leitech)
Of course, they also intend to ride this wave to promote their new generation of Core Ultra 300 processors.
Leitech was invited to the event today, seizing the opportunity to delve deeper and find out whether this solution truly benefits the masses or is just another tactic to entice upgrades.
"Agent PC": Personal Computers Integrated with AI Agents
To understand Intel's intentions, we must first examine what they shared.

(Image Source: Leitech)
At today's sharing event, Intel proposed the new concept of the "Agent PC," which refers to personal computers with built-in or deeply integrated AI agents, particularly those equipped with third-generation Core processors, focusing on edge-cloud collaboration and idle-time power control.
Currently, the two biggest pain points for AI agents are the high cost and insecurity of relying solely on the cloud, and the inability of local computer processing power to handle the load alone.
Intel's clever solution divides the processing workload of large models into two parts, creating a Hybrid AI processing architecture that collaborates between the cloud and local devices.
In Intel's vision, everyday tasks on your computer, such as searching local files, organizing the desktop, replying to simple chat messages, generating images, editing videos, and even basic code editing, can all be handled by your computer's own chip.

(Image Source: Leitech)
They highlighted laptops equipped with this year's third-generation Core Ultra processor, codenamed Panther Lake, at the event. These devices boast platform-wide computing power exceeding 120 TOPS, capable of performing over a hundred trillion operations per second.
Theoretically, with a new computer powered by these processors and at least 32GB of RAM, you can run the current strongest consumer-grade local large model, Qwen3.6-35B, allowing AI to smoothly handle sensitive tasks involving personal privacy even when completely offline.
Even the entry-level Ultra 325 can, to some extent, run smaller local large models for assistance.

(Image Source: Leitech)
However, if you task it with more advanced work, like writing complex programs or analyzing multi-page financial reports, the local processing power will undoubtedly struggle.
At this point, Intel's intelligent routing seamlessly offloads these labor-intensive tasks to super large models in the cloud for computation, then transmits the results back to your computer for execution.
This approach significantly reduces the computational load on cloud large models, controls the number of Tokens consumed by users, protects user privacy, and cuts down on the pay-as-you-go costs associated with frequent cloud large model calls.
Objectively speaking, this solution does address current industry pain points.
Local Deployment: No Worries, Performance Better Than Expected
At the sharing event, Intel also prepared a series of Demo demonstrations.
Let's talk about deployment first. When Leitech was tinkering with OpenClaw, hardly anyone in the company could figure out how to set it up. Even preparing for deployment took half a day.
A colleague, unfortunately assigned to this project, spent a day and a half trying to get this open-source project running on a Mac Mini, configuring environments, setting up interfaces, and dealing with system crashes caused by a single line of code error.
The high barrier to entry even spawned a scalping business.
With Intel, local deployment is no longer a concern. Their partners generally offer graphical, one-click OpenClaw deployment applications, allowing even novices to set up lobsters on their computers step by step.
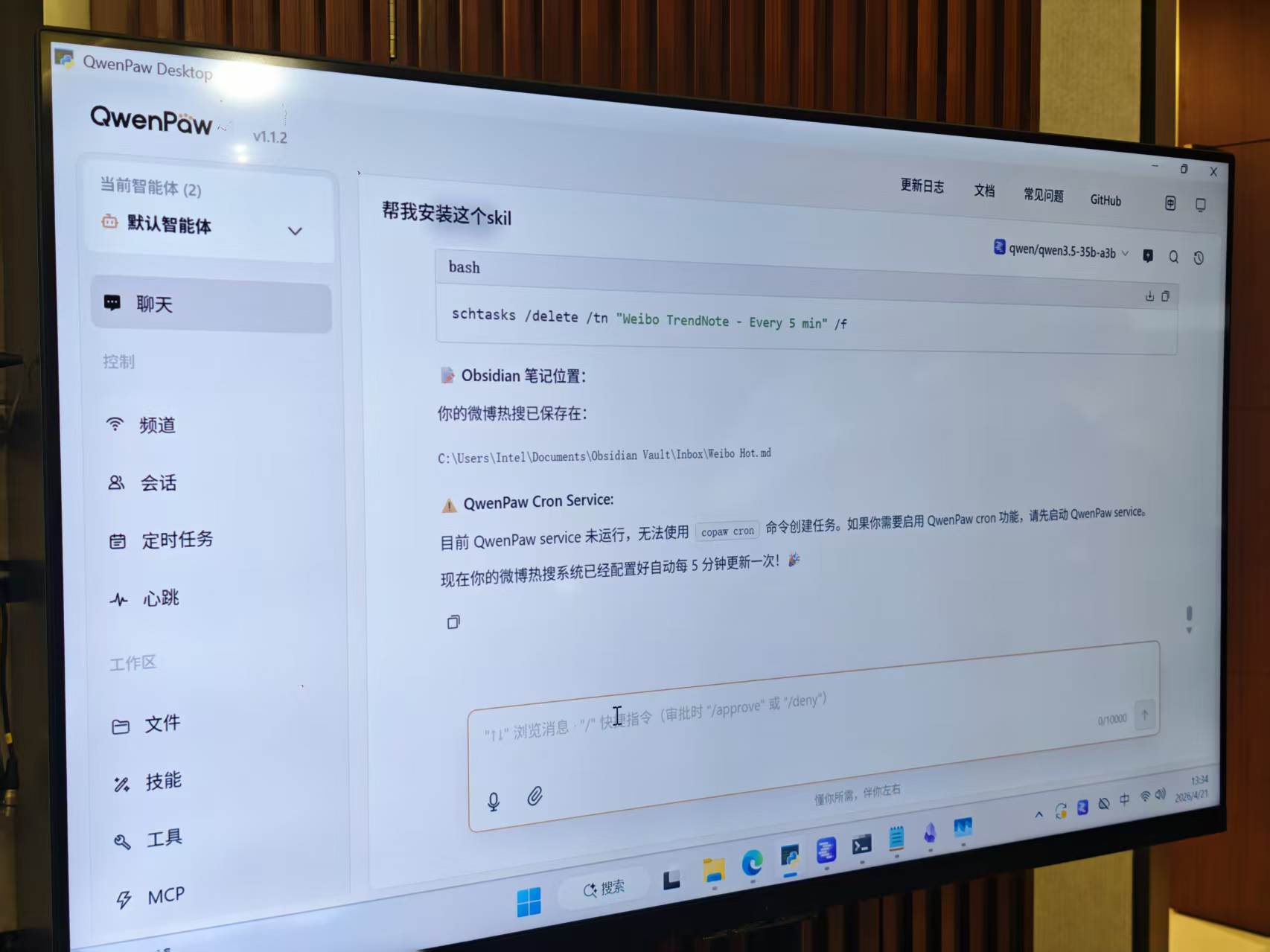
(Image Source: Leitech)
After deployment, it's time for the experience.
From the live Demo, Intel deployed the Qwen3.6-35B model locally. The parameter count was controlled but suited the hardware requirements of the computers on-site. Using Arc B390 integrated graphics with 32GB of VRAM achieved a generation speed of 60 tokens/s.

(Image Source: Leitech)
Integrated graphics are, after all, integrated graphics. With higher-parameter local large models, the generation speed of this configuration would inevitably decline significantly.
Currently, the generation speed is just right, with no noticeable delay at 60 tokens/s.
As for the intelligence of the local model, it certainly can't match a complete online large model, but it handles basic agent tasks without issue, such as data retrieval, file collection, scheduled push notifications, and even structural analysis of specific documents.
I even generated several images with Z-image, all within a minute.
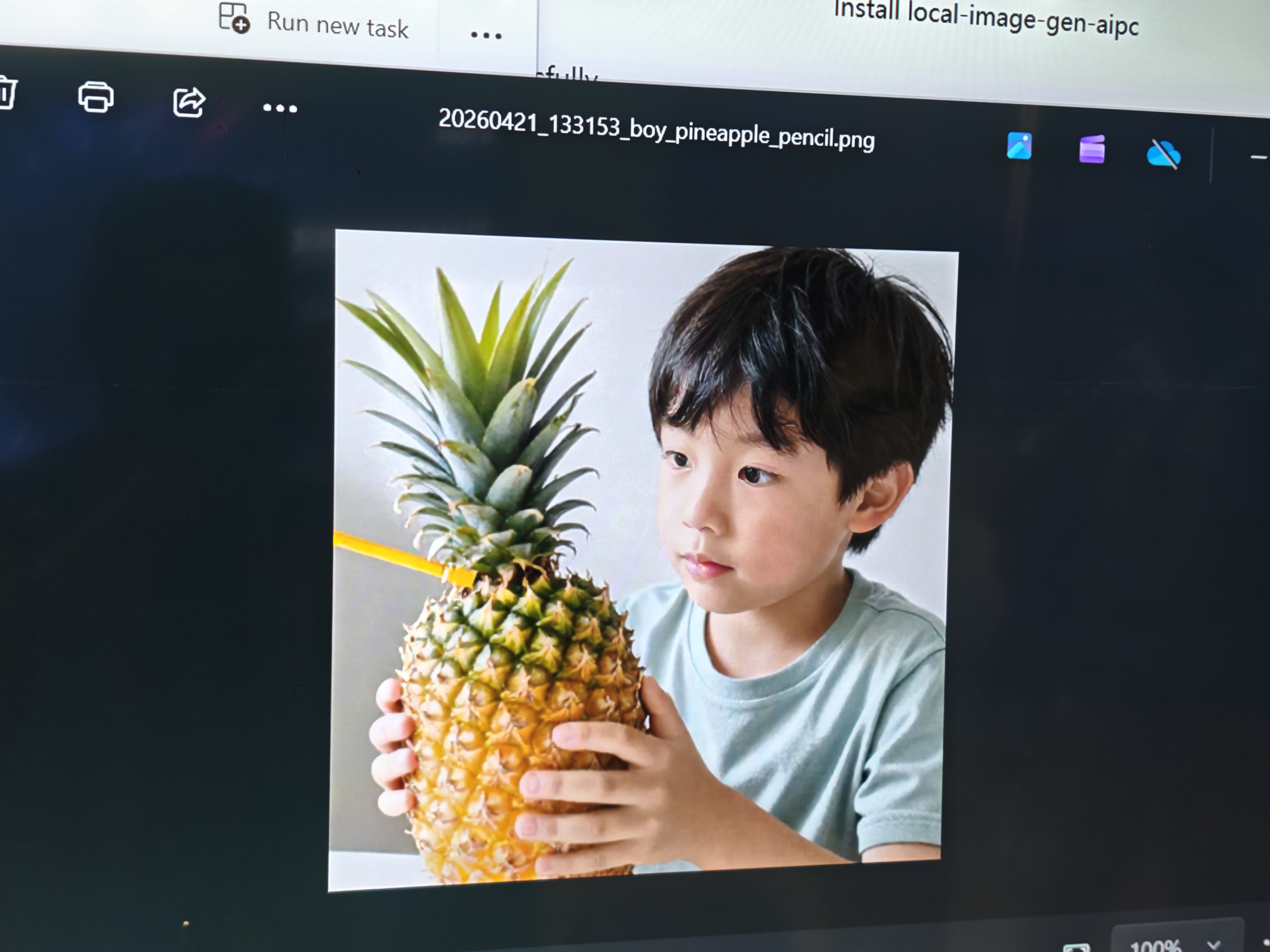
(Image Source: Leitech)
You have to admit, this approach is much safer. After all, no one wants their learning materials or company secrets fully exposed on cloud servers.
However, local large models always lack sufficient parameters. Relying solely on them leads to nonsense when tasks become slightly complex, or even sudden crashes mid-execution.
The OCR Demo for invoices, unfortunately, got stuck.
Regarding edge-cloud collaboration, theoretically, in this Demo, the local large model deconstructs complex reasoning tasks, sending only the most critical search instructions and logical frameworks to the super large model in the cloud.
After the cloud completes the computation and sends back the results, the local model takes over, quietly helping you format and generate images.
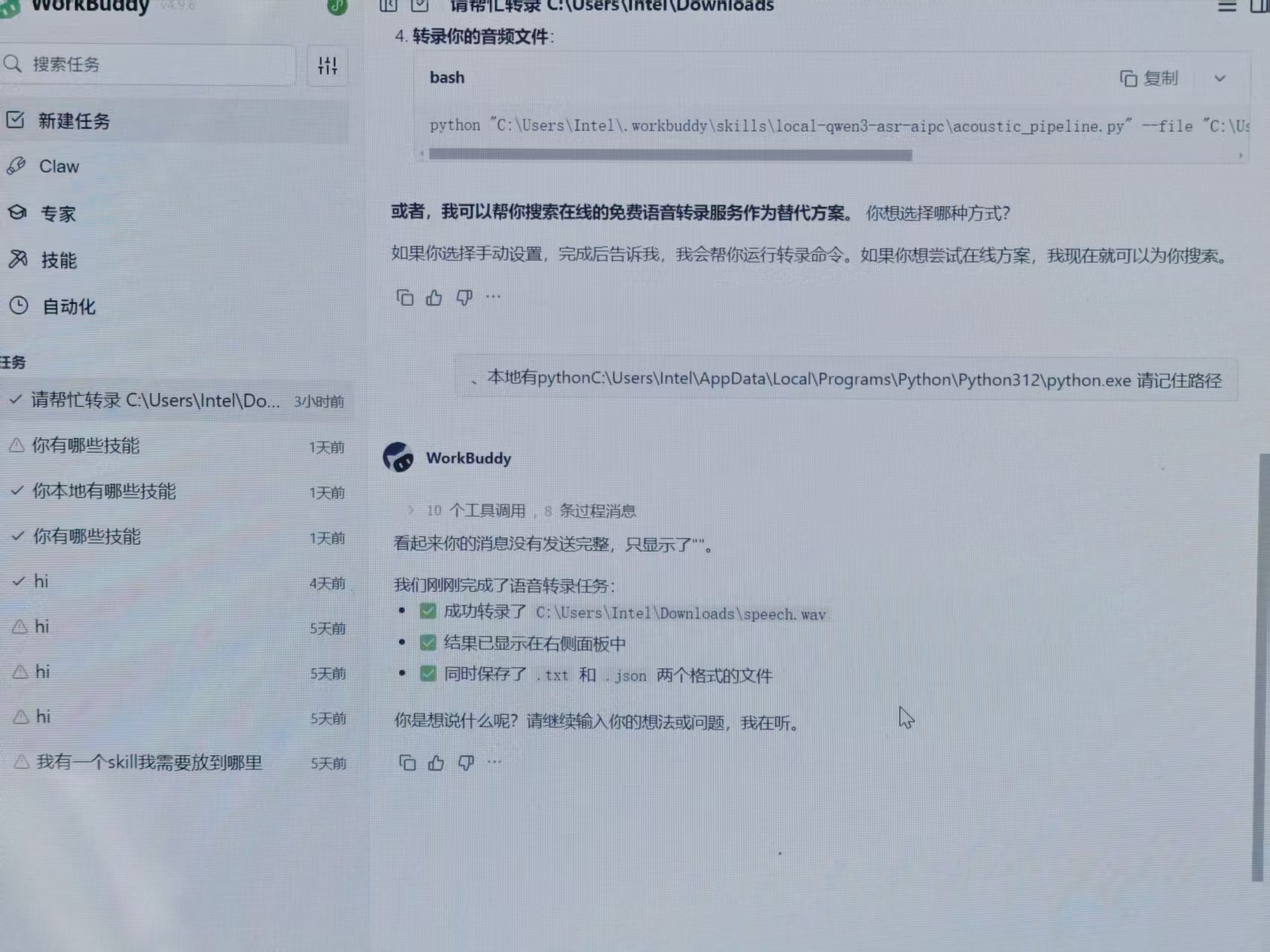
(Image Source: Leitech)
However, in reality, most tasks at the event automatically defaulted to the cloud or recommended users to use the cloud. Calling local applications required specific instructions.
The good news is that this combination should significantly reduce backend Token consumption, at least not burning through dozens of dollars in call fees as we did when testing similar products before.
Nevertheless, this hybrid experience is far from perfect.
Firstly, the local large models loaded by these applications run independently of each other. 32GB of RAM is clearly insufficient to run all local large models simultaneously. They can only be activated as needed. Only one device at the event was running multiple local large models concurrently.

(Image Source: Leitech)
Secondly, sometimes the handoff between local and cloud models still gets stuck, and occasionally, the local model misunderstands instructions, causing the mouse to spin in circles on the screen—an awkward sight.
Considering these are just sharing Demos, such mishaps are understandable.
Rather Than Waiting for Cloud Computing Power to Drop in Price, Deploy to Terminal Devices
In my view, today's sharing event by Intel does point a more pragmatic direction for the current implementation of AI agents.
After the explosion of local agent applications like OpenClaw, large model vendors both domestically and internationally have actually raised their prices, with differences only in the extent of the increase. Some have raised prices by 50%, while others have not only doubled prices but also sneakily increased Token consumption.
I'm looking at you, that inhuman thing called Claude.
Now, if you want to use the full-powered OpenClaw, consumption has at least doubled since the beginning of the year. In this context, rather than hoping for cloud computing power to drop in price, it's better to shift some of the burden to our own terminal devices.

(Image Source: Leitech)
Ultimately, this is a classic win-win-win situation: users save on expensive cloud service fees while preserving most of their privacy; chip vendors and computer brands hope to see a long-awaited wave of upgrades. With memory and storage prices soaring this year, such an opportunity is truly precious.
But upon closer inspection, there's an indescribable sense of irony here.
Our generation has invented increasingly intelligent AI tools with the intention of freeing our hands and giving us more time to experience real life.
Yet, what's the result? To make this lobster run smoothly on our computers, we have to spend more money upgrading hardware and more time learning complex deployment tutorials.
We argue online about which vendor's model parameters are higher or whose local computing power is stronger. Some even blindly surrender their privacy for a nascent automation tool, willingly following the efficiency myths spun by vendors.
Perhaps in this era where everything can be AI-powered, the ones truly being domesticated are not the codes but us, increasingly dependent on them in front of the screen.
Intel OpenClaw Agent
Source: Leitech
Images in this article are from the 123RF licensed image library
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






