Computing Power Embarks on a 'Game of Thrones': Cloud Titans Challenge NVIDIA's 'Exorbitant Pricing'
 04/24 2026
04/24 2026
 501
501

This is not merely about replacement; it's a reconstruction. NPUs are propelling AI computing power into the 'Lego Era'.
Source | Silicon-Based Quadrant
For the past decade, NVIDIA has virtually single-handedly defined the narrative of AI computing power.
From the A100 to the H100, and now the H200, GPUs have served as a continuously expanding industrial assembly line for computing power, propelling deep learning from the lab into the era of large models.
However, an often-overlooked fact is that GPUs were initially designed for graphics rendering, not AI.
This means that GPUs have always been a 'general-purpose parallel computing architecture' rather than an 'AI-native architecture'.
As a result, a more fundamental trend is emerging:
As AI computing scales exponentially, the marginal efficiency of GPUs begins to decline.
The industry is pivoting towards redesigning computing paradigms, giving rise to a new type of computing power chip based on dedicated computing chip design logic (ASIC) — the NPU.
On April 22 (U.S. time), at the Google Cloud Next event, Google unveiled two eighth-generation NPU chips: the TPU8t and TPU8i, designed specifically for AI training and inference, respectively. The TPU8t boasts a 124% improvement in performance per watt over its predecessor, while the TPU8i delivers an 117% boost, along with an 80% increase in performance per dollar. Industry commentators have suggested that 'if sold externally, it could rival NVIDIA'.
Developing their own chips is not a path unique to Google among cloud service providers.
Amazon, the global leader in cloud services, released its first NPU for inference — Inferentia1 — in 2018, followed by the second-generation Inferentia2 in 2023. It also launched its NPU for training, Trainium3, at the end of last year. Microsoft Cloud, ranked second, released its first cloud-based NPU (Maia 100) in 2023 and followed up with the Maia 200 earlier this year.
A similar trend is evident in China. Alibaba unveiled its first NPU (Hanguang 800) in 2019, focusing on cloud-based inference and visual computing. Since 2018, Baidu has released its self-developed AI chip, Kunlun 1, based on ASIC logic, and has since iterated to the third generation of Kunlun chips.
In 2026, ByteDance, a major consumer of computing power chips, is also set to enter the NPU market. Foreign media reports indicate that ByteDance has begun discussions with Samsung to develop its own NPU chip, codenamed SeedChip, specifically designed for AI inference tasks. The first batch of samples is expected to be delivered by the end of March 2026.
The trend in 2026 is that chips will no longer be monolithic; Google, ByteDance, Alibaba, and others aim to 'integrate' their own dedicated modules into NVIDIA's ecosystem.
Cloud providers developing their own NPUs could revolutionize the cost structure, energy consumption profiles, and even business models of AI.
01 What is an NPU?
Google's TPU and Alibaba's Hanguang 800 are essentially forms of NPUs.
An NPU (Neural Processing Unit) chip, as the name suggests, is a chip designed for neural network processing.
To understand the difference between NPUs and GPUs, one must delve into their underlying logic. NPUs generally fall under the category of application-specific integrated circuits (ASICs), while GPUs belong to general-purpose processing chips.
Chips can be broadly categorized into three types based on design logic: general-purpose computing chips, FPGAs (reconfigurable hardware), and ASICs (application-specific integrated circuits).
First are general-purpose computing chips, such as CPUs and GPUs, which use a single instruction to drive hundreds or thousands of threads in parallel, making them highly adept at handling large-scale parallel computing tasks. They typically do not alter their hardware but instead change 'task scheduling' through software (CUDA). This is why NVIDIA is often described as a software company at heart. The core characteristics of GPUs are high programmability, adaptability to all computing tasks, and complex architectures (requiring substantial cache). However, the trade-off is that greater generality leads to lower efficiency.
The second category is ASICs (application-specific custom chips), designed specifically for a particular task (such as image recognition or speech processing). With fixed data flows and extremely high energy efficiency, ASICs represent a design methodology that 'hardcodes algorithms into silicon.' The downside is that once the circuitry is imprinted on the silicon, the function cannot be altered, making them less flexible. ASICs essentially transform AI computing from a 'software problem' into a 'physical problem,' but this also means they offer the least flexibility and have long update cycles.
The third category is FPGAs (reconfigurable hardware), which can change their hardware layout through 'rewiring' and modify software code to alter chip functionality, akin to a set of 'Lego bricks.' They occupy a middle ground between general-purpose and dedicated chips and are commonly used in prototype development or edge computing where algorithms iterate rapidly.
GPUs are powerful and can perform many tasks in parallel. If fully utilized, they can be incredibly potent, but they come with higher unit costs and greater energy consumption. In contrast, NPUs are designed to perform one task or a narrow range of tasks, offering limited functionality but at a lower unit cost and with greater energy efficiency.
02 Not Selling Chips, But Offering More Cost-Effective Cloud Services
Cloud service providers are not in the business of selling chips; instead, they aim to provide more cost-effective computing power.
In 2015, Google began researching NPUs after discovering a problem: the demand for neural network inference in its data centers was surging, but GPU efficiency was insufficient.
As a result, Google launched the TPU project internally. The first-generation TPU, designed solely for data inference, was born in 2015. In 2018, Google Cloud TPU was made available to the public, and from 2020 to 2024, it entered the 'integrated training and inference' phase.
In 2026, with the release of TPU 8, Google for the first time clearly divided its approach into two paths: the TPU 8t for training and the TPU 8i for inference. This reflects a broader trend: the focus of AI computing power is shifting from training to inference.
Industry organizations predict that by 2030, 75%-80% of AI computing power will be used for inference. This means that while a GPT model may be trained once, it will run inference billions of times. Therefore, whoever can reduce the cost of inference from one cent to 0.1 cents will become the future king of computing power.
Google's two chips were designed by two different partners: the TPU8t by Broadcom and the TPU8i by MediaTek. Both are expected to be based on TSMC's 2nm process, with mass production anticipated by the end of 2027. The most significant change in TPU 8 is its attempt to address the 'memory wall' issue through higher-bandwidth HBM and denser inter-chip interconnects.
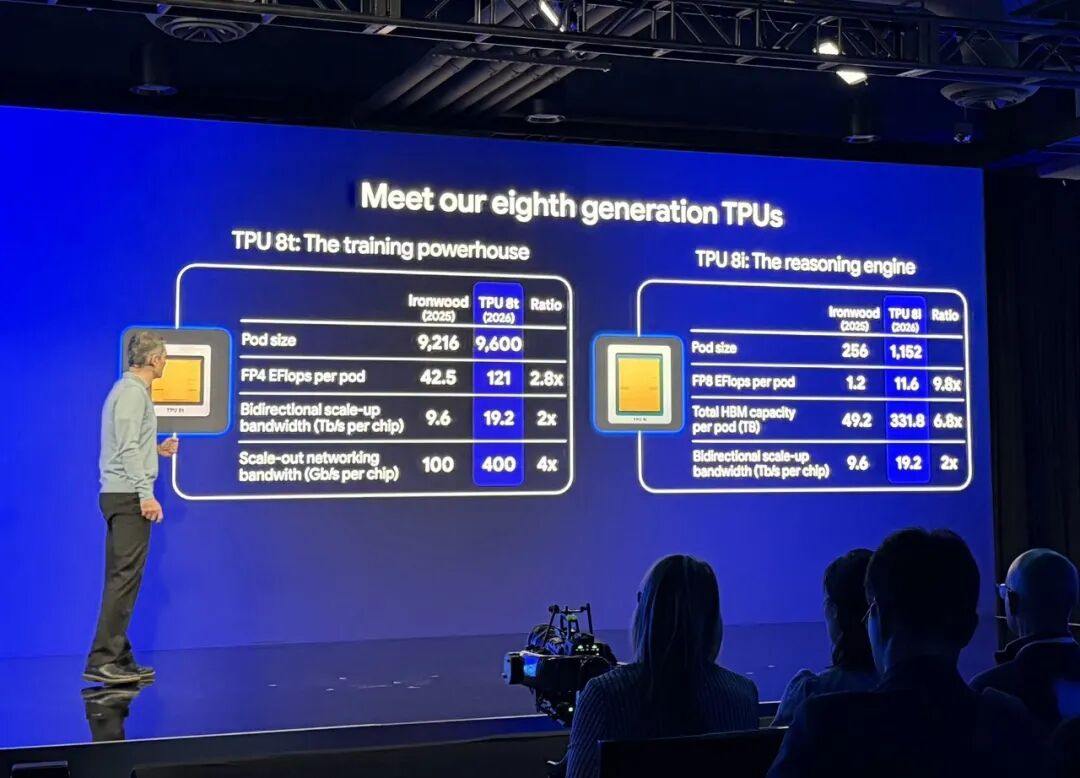
It is reported that compared to the previous-generation Ironwood product, the TPU 8i inference chip increases its HBM capacity from 216GB to 288GB, boosts bandwidth from 6,528 to 8,601GB/s, and triples on-chip SRAM to 384M. The cluster scale expands from tens of thousands to 134,000 chips, with a maximum connectivity of 1 million chips.
NPUs are not exclusive to Google; Amazon, Microsoft, and others also have NPU products, while domestic companies like Huawei's Ascend, Cambricon, and Horizon Robotics have released similar offerings.
Previously, cloud providers purchased NVIDIA's 'full stack,' but now they want to buy NVIDIA's 'foundation' and build their own 'houses.'
03 Seizing the Initiative in the Era of Computing Power
Behind the release of the TPU 8 series lies a very clear strategy: de-NVIDIA-ization.
If the TPU succeeds, AI computing power will shift from 'GPU monopoly' to 'multi-architecture competition.'
However, replacing NVIDIA is no easy feat.
The most critical issue is the ecosystem. NVIDIA's CUDA remains the industry standard, with 4 million developers. On the other hand, TPUs are too specialized; GPUs can be used for AI training and inference, graphics processing, and rendering, whereas TPUs have a single function.
Industry insiders generally believe that the significance of NPUs is not to 'replace GPUs' but to redefine the structure of AI computing power. In the future, GPUs may serve as the general-purpose computing foundation, while TPUs/NPUs act as dedicated AI acceleration layers.
NVIDIA has also recognized this trend. By the end of 2025, NVIDIA invested $20 billion to acquire Groq, whose LPU (Language Processing Unit) can run large language models (LLMs) more than 10 times faster than traditional GPUs.
This resembles the competition among most smartphone manufacturers over the past decade. When the most critical SoC chips in smartphones were already monopolized by Qualcomm and MediaTek, with strong moats, developing in-house SoC chips required significant investment and carried high risks.
Therefore, to gain a unique advantage and be more competitive in the market, most smartphone companies chose not to develop their own SoC chips but instead optimized specific functions of existing SoCs.
Previously, smartphone manufacturers like Samsung, vivo, and OPPO all chose to develop their own NPUs to enhance photography capabilities, achieving differentiation, such as vivo's V1 imaging chip and OPPO's MariSilicon chip.
The competition for computing power among cloud providers is also intensifying, with more and more NPUs for training and inference emerging and continuously improving their capabilities.
The true watershed in the future computing power industry will be: whoever can minimize AI inference costs will seize the initiative in the next era of computing power.
-
![]()
From iQIYI to AI Qiyi: A 'Cost-Saving Marvel' or a 'Crisis of Trust'?
-
![]()
Be Honest Like Liang Wenfeng
-
There's Still One More Round of Playoffs in the Intelligent Driving Industry
-
Hisense's 'Soft-Shelled Crab' Moment: Can It Make the Leap to Global Leadership Amidst Transformation Challenges?
-
![]()
Where is the AI Infra Industry Chain Bottlenecked?
-
![]()
Is NVIDIA's 'AI Grid Vision' a Delicious Pie? Someone Did the Math~
-
![]()
Token's Great Leap Forward | Business Wave
-
![]()
From OEM manufacturing to becoming a bestseller in North America, Chinese manufacturing is capturing global attention with the help of TikTok Shop