Is NVIDIA's 'AI Grid Vision' a Delicious Pie? Someone Did the Math~
 04/24 2026
04/24 2026
 375
375
Previously, at its annual GTC conference, NVIDIA unveiled a grand vision named 'AI Grid,' attempting to transform global telecom networks into infrastructure for artificial intelligence (AI).
The so-called 'AI Grid' is a network composed of interconnected AI infrastructure nodes, covering AI factories, regional access points, central computer room s, mobile switching centers, and base station sites. These nodes are equipped with full-stack AI infrastructure and connected via secure, high-bandwidth, low-latency networks, enabling seamless flow of data, models, agents, and workloads, allowing the entire grid to function like a unified distributed system.
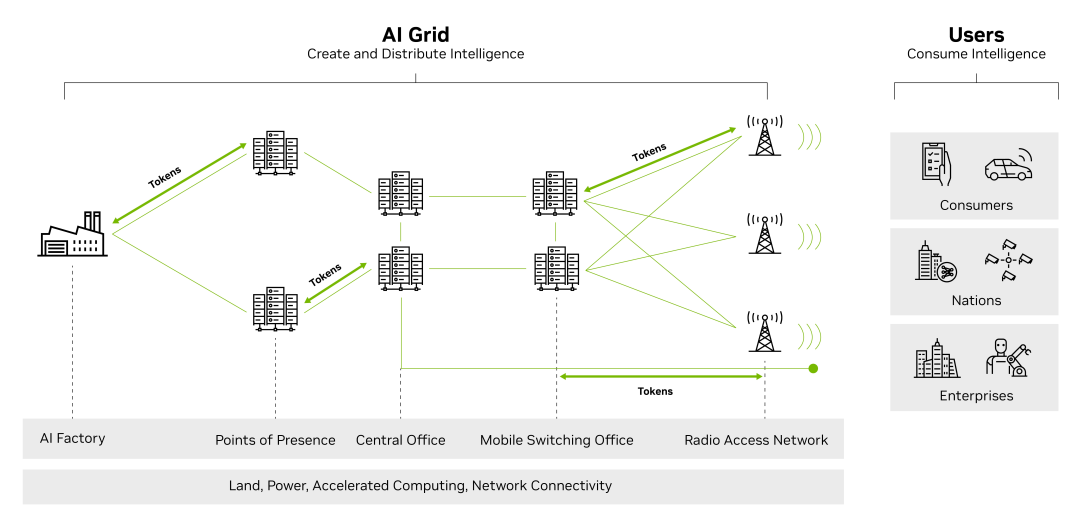 Source: NVIDIA's official website
Source: NVIDIA's official website
Telecom operators currently exploring the 'AI Grid' space include T-Mobile US, Comcast, and SoftBank. NVIDIA has consistently emphasized that telecom companies' existing assets (towers, fiber, and spectrum) make them naturally suited to host distributed inference infrastructure. However, the core question remains: If this vision truly represents the future, should telecom operators invest substantial funds into distributed AI infrastructure now?
To address this question, ABI Research recently released an analysis report, helping telecom companies crunch the numbers. The report covers edge GPU deployment, network latency constraints, and total cost of ownership in the implementation of 'AI Grid.' Its primary goal is to clarify the core contradiction: Is NVIDIA's vision viable today, or is it an expensive gamble on a future that has yet to arrive?
Is Reducing Latency the Core Rationale?
The most compelling reason for deploying GPUs at the near or far edge of the network is latency—applications requiring near 'real-time' execution and control have strict latency requirements. The closer inference servers are physically located to end-users, the faster the response should be.
However, ABI's analysis suggests that this argument, while seemingly reasonable, is flawed—at least for today's mainstream AI workloads. For generative AI, the most critical metric is Time To First Token (TTFT, a key indicator for measuring webpage load performance, reflecting the time from a user's request to the browser receiving the first byte). Network latency is not a primary factor here. Standard network round-trip times may indeed reach 100 milliseconds, but the bigger culprits causing latency—including DNS resolution, tunnel establishment, and computationally intensive prefilling and decoding stages—remain unchanged regardless of where inference servers are physically deployed. For a medium-scale prompt of around 1,000 tokens, the prefilling stage alone takes approximately 160 milliseconds, while the decoding stage can extend to several seconds.
In practice, this means that for regular chatbot interactions, moving inference servers closer to users does not significantly improve the experience. The computational latency during token generation completely outweighs the time saved in network transmission. Guilherme Soubihe, CEO of Latitude, pointed this out in an interview with RCR Wireless: 'The vast majority of data center-grade GPU capacity is already being used by hyperscale cloud providers and cutting-edge model developers for training and fine-tuning large language models, and these workloads do not derive meaningful benefits from edge locations because network latency is largely irrelevant.'
However, the situation is more nuanced. NVIDIA's GTC conference demo showed that edge deployment reduced chatbot round-trip latency from 2,000 milliseconds to 400 milliseconds. Suman Kanuganti, CEO of Personal AI, questioned the framework of latency discussions, which typically focus on individual requests. 'AI Grid is not optimized for single calls but for concurrency,' he said. He cited benchmark results: Under P99 burst traffic, a four-node AI Grid can maintain voice latency below 500 milliseconds while improving throughput by 80% compared to the baseline. Centralized deployments, under the same load, experience performance degradation. In other words, the edge's advantage lies not in shaving milliseconds off individual requests but in maintaining deterministic quality of service for millions of concurrent sessions simultaneously. Thus, while latency benefits may not be obvious for individual consumer queries, the calculus changes for operators handling massive concurrent sessions.
Physical AI is the domain where latency truly becomes an architectural necessity. Autonomous vehicles, delivery drones and robots, video surveillance, smart glasses, and AR/VR drastically compress the acceptable latency window—cloud-based inference simply cannot meet these requirements.
ABI illustrates this with a straightforward example: At 100 milliseconds of latency, a self-driving car traveling at 100 km/h would effectively be 'blind' for 2.8 meters. When dealing with safety-critical systems requiring near-real-time execution, routing inference through distant cloud data centers is infeasible. The same principle applies to a range of emerging applications, including last-mile delivery robots and real-time video analytics.
Of course, the issue is timing. Most of these physical AI applications are still years away from scaling in any meaningful way. Peter Linder, Head of Thought Leadership for Ericsson Americas, argues that the rationale for deployment must come from a combination of network efficiency gains and future revenue potential, not just the demands of physical AI itself. Kanuganti takes a more aggressive stance, asserting that voice AI, video intelligence, and enterprise AI services are already viable use cases. If autonomous vehicles, drones, and humanoid robots are truly as close to mass adoption as some claim, then infrastructure development must begin now.
Are Construction Costs Justifiable?
Even if latency arguments and application scenarios eventually align, the financial challenges of building a distributed AI grid remain daunting. ABI concludes that large-scale, nationwide edge server deployments aimed at reducing standard latency are not financially viable within the next two to three years.
Base station deployments, in particular, face severe unit economics challenges—each base station serves a limited user base and has narrow geographic coverage, making returns per site challenging outside dense, high-value areas.
To ground the discussion in real data, ABI conducted a simulated calculation using T-Mobile US as an example. T-Mobile US stated at the GTC conference that 'kinetic tokens' would present a massive opportunity for global telecom operators. To leverage its infrastructure assets, operators would need AI-RAN systems and GPU deployments in their networks. Assuming T-Mobile US operates approximately 13,000 rooftop base station sites in the U.S. and begins equipping them with AI-RAN servers (using NVIDIA's ARC-1 server, priced at $60,000 each, with each server providing compute power for three base stations), with deployment completed by 2035 to achieve full GPU coverage at rooftop sites—the cumulative total cost, including deployment, cooling, and other ancillary costs, would reach $3.7 billion. The chart below shows the annual total cost of ownership for this example deployment scenario:
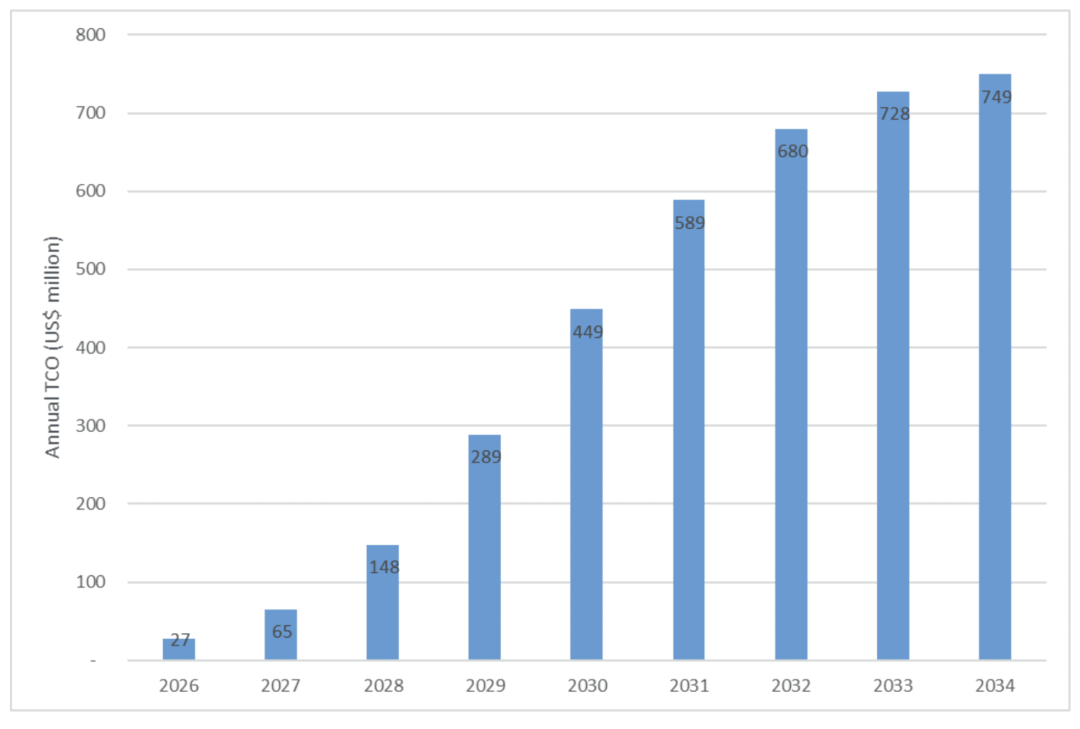 Figure: Annual total cost of ownership for T-Mobile US's gradual deployment of GPU servers across all rooftop sites
Figure: Annual total cost of ownership for T-Mobile US's gradual deployment of GPU servers across all rooftop sites
Assuming corresponding revenue growth, amortizing the investment over nine years makes the deployment of 'AI Grid' more manageable. Furthermore, the $3.7 billion estimate is almost negligible for NVIDIA's scale, but telecom operators and their investors require a robust business case to justify this expenditure—especially when the investment rivals the scale of deploying a new generation of wireless networks.
The reality of infrastructure exacerbates the financial challenges. Kanuganti notes that 'communication towers were not designed to house and cool high-density computing equipment,' explaining why early adopters are starting with wired near-edge facilities that have redundant power, cooling, and physical security measures. Linder emphasizes this point, stating, 'Wireless sites often operate in harsh environments, so we use specially designed ASIC-based computing to optimize power, performance, and cost, eliminating fans wherever possible.'
Both perspectives lead to the same conclusion: Far-edge construction depends on improvements in hardware energy efficiency, the emergence of hardware form factors designed specifically for edge AI, and the advent of AI-RAN architectures that integrate wireless processing with AI inference into shared computing platforms.
Given all these constraints, ABI predicts that initial AI inference deployments will concentrate on core network nodes (typically fewer than 10 per country), gradually expanding outward to base station sites as low-latency demands grow and economics improve. Many application scenarios, including video surveillance, autonomous driving, last-mile delivery robots, smart glasses, and AR/VR applications, make edge inference not an option but an architectural necessity. Early 'AI Grid' deployments primarily serve to future-proof telecom networks, laying the groundwork for the distributed computing ultimately required for 6G.
Is NVIDIA's 'Pie' Delicious?
Under NVIDIA's vision, 'AI Grid' aims to seamlessly handle AI workloads across computing locations, optimizing cost, performance, and user experience. In short, it decides where models should run and how tokens should flow based on latency, cost, and strategic objectives.
Enabling Real-Time AI Applications: Real-time AI applications like conversational assistants, AR/VR, online gaming, and industrial robots require strict latency control to deliver immersive customer experiences. 'AI Grid' enables large-scale operation of such latency-sensitive applications by deploying compute workloads as close as possible to end-users and devices.
Optimizing Token Costs at Scale: Multimodal generation and advanced inference models can generate 100 times more tokens than simple text-based large language models (LLMs), significantly increasing network data volumes and driving up cloud egress costs. 'AI Grid' mitigates this by deploying these token-intensive workloads on distributed AI nodes with the most cost-effective computing and network connections, reducing data egress and bandwidth consumption without sacrificing service quality.
Geographically Resilient Architecture for Elasticity and ROI: 'AI Grid' can run various workloads, from AI applications to network functions, while optimizing utilization at each node. This improves infrastructure return on investment and reduces operational overhead compared to single-purpose systems. By treating multiple distributed AI nodes as a virtual system, they can scale capacity more intelligently, handle sudden demand spikes, and significantly reduce single points of failure.
Regional Compliance and Data Sovereignty: Enterprises can define where data and models are stored and executed on 'AI Grid,' enabling deployments compliant with regional regulations while leveraging globally coordinated capabilities.
Based on these benefits, NVIDIA is actively constructing a narrative where telecom companies become critical nodes in the new AI grid. However, it is important to recognize soberly that this framework benefits NVIDIA far more than any other party. Device sales, software licensing, ecosystem binding—no matter how 'AI Grid' ultimately takes shape, NVIDIA will emerge as the biggest winner. For telecom operators, the path is far less clear.
Early movers may not see tangible financial returns in the short term; they are primarily securing a strategic position in what companies like NVIDIA call the 'AI supercycle.' However, whether this positioning justifies billions in capital expenditures before any revenue sources are validated remains an open question~
References: ABI on AI infra | AI grid may be the next telecoms arms race (Analyst Angle)——RCRWirelessNvidia’s AI grid and the telco dilemma——RCRWirelessWhat Is an AI Grid?——NVIDIA's official websiteNVIDIA's Telecom Ambitions: Reshaping the $2 Trillion Network Industry——C114 Communications NetworkJensen Huang's Physical AI Vision: Transforming 5G Networks into Distributed AI Computers!——IoT Intelligence
-
![]()
The ‘White Glove’ Phenomenon at Auto Shows: Far from Over This Year
-
![]()
DeepSeek Strikes Again, Domestic Large Models Can't Sit Still
-
![]()
DeepSeek V4 Is Finally Here! What Do We Know?
-
![]()
DJI VS Insta360 Two-Way Game: Intense Competition in the Handheld Camera Track, Disruption by Mobile Phone Giants
-
![]()
From iQIYI to AIQIYI: A 'Cost-Reducing Marvel' or a 'Crisis of Trust'?
-
![]()
Big Tech Companies Throw Their Weight Behind Robots
-
![]()
Apple’s New CEO: The Perfect Blend of ‘Jobs + Cook’
-
![]()
Behind Oracle's Global Layoff of 30,000: AI Bubble or AI Replacement?