Be Honest Like Liang Wenfeng
 04/24 2026
04/24 2026
 480
480

"Not seduced by praise, not intimidated by slander, following the path, and maintaining integrity."
This quote is from Xunzi's 'Against the Twelve Scholars' and was placed at the end of DeepSeek's release announcement.
'Against the Twelve Scholars' is not a mild piece. In it, Xunzi criticizes influential doctrines and figures of his time, including even Confucians like Zisi and Mencius.
The so-called 'Against the Twelve Scholars' is not simply about negation (negating) others but about re-identifying what is truly reliable when the marketplace of ideas is extremely lively and various voices vie for interpretive authority.
Liang Wenfeng is certainly not trying to criticize others; he is not even interested in speaking out externally. This is merely a self-explanation and a confirmation of his own path.
The outside world cares about us, but we don't give a damn.
For some time, DeepSeek has been in a very special position.
The release of V4 has been delayed, and it has been continually surrounded by speculation about financing, delays, and talent turnover.
With the dream of AGI ahead, praise, skepticism, emotions, and public opinion are all just noise.
The outside world may have many opinions, but in the end, what responds to everything is the model and the product.
This is what makes Liang Wenfeng and DeepSeek special. They possess a rare idealism, but this idealism is not just a lightweight slogan; it is something very engineering-focused and specific: strengthening the model, lowering costs, expanding context, supplementing Agent capabilities, and placing real user experiences in front of users.
And they are also very honest.
Idealistic people are not necessarily honest.
For example, Elon Musk clearly has idealism, with Interstellar migration (interplanetary colonization) and general AGI within reach. But Musk is clearly not honest enough. For those in the model circle today, honesty is an even rarer quality.
After the release of today's new model, it has become very difficult to directly obtain a relatively objective evaluation of the model's capabilities. You see a bunch of benchmarks and tests, which are two different things from actual experience.
DeepSeek's article provides their internal judgment of the real experience: Currently, DeepSeek-V4 has become the Agentic Coding model used by employees within the company. According to evaluation feedback, the user experience is better than Sonnet 4.5, and the delivery quality is close to that of Opus 4.6 in non-thinking mode, but there is still a certain gap compared to Opus 4.6 in thinking mode.
Quite clear and straightforward, it basically eliminates the space for external wild evaluators to step in.
So I suggest that all model vendors, when releasing models, in addition to the benchmarks that hardly anyone looks at anymore, include their own internally stamped and certified real impressions.
This is very crucial.
Because Agentic Coding is not an exam question. It's one thing for a model to score a few more points on a leaderboard, and quite another to actually place it in a code repository, let it read requirements, view files, modify code, run tests, fix bugs, and continue iterating.
There are many things in real experiences that benchmarks can hardly cover. Losing track of the goal when tasks get long, forgetting previous constraints while using it, modifying files it wasn't supposed to modify—these things can really drive you crazy.
So DeepSeek's statement is not about thinking it's strong; it's not that the benchmark says it's strong, but that it provides a coordinate very close to real user language.
It's very clear about where it's strong, who it's close to, and where it still lags behind. This kind of expression is actually much more advanced and useful than saying it "comprehensively surpasses so-and-so model."
Let's talk specifically about the model.
1M Context
Many models currently default to a 256K context level. For ordinary chat, this is already quite long. But for Agent tasks, it is often insufficient. When vibe coding or running something like a lobster or a horse, the model needs to continuously retain information over a long task.
Many times, model tasks fail not because their standalone intelligence is insufficient but because their working memory is inadequate.
They forget what they read earlier; they lose track of requirements emphasized by the user at the beginning; the project structure starts to drift by the third round of modifications. When the context is insufficient, the Agent easily becomes a short-sighted executor and struggles to complete the entire task.
This is where the significance of a 1M context lies. It makes the model more like a collaborator who can work for extended periods.
Strictly speaking, this is not yet "continual learning" in the parametric sense because the model weights are not updated.
But from a product experience perspective, it already approximates a form of continual learning within the context: the model can continuously absorb materials, user feedback, historical decisions, and intermediate outputs within the same task window and then incorporate these into subsequent reasoning and execution.
Many future AI applications will not be "I ask a question, you answer one" but rather "I give you a goal, and you help me complete a complex task." In this case, the context becomes the model's workbench and its short-term memory. The longer the context, the more opportunities the model has to evolve from a single-round tool into a continuous collaboration system.
To better support long contexts, DeepSeek has reworked the most expensive layer of the Transformer: attention.
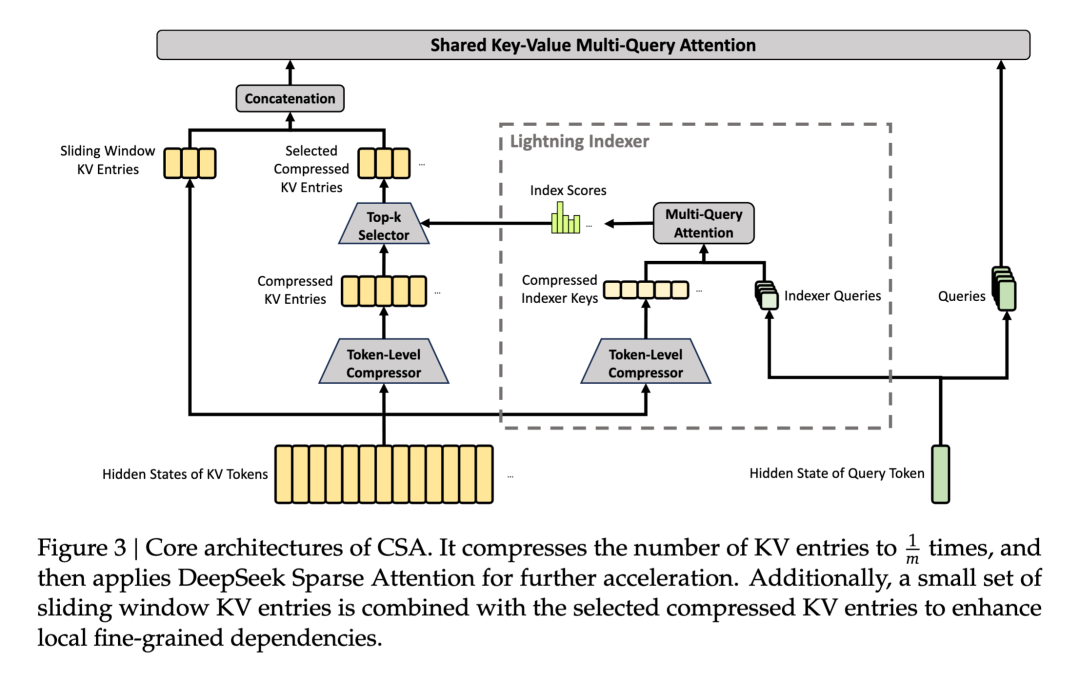
Everyone knows the problem with traditional attention: as the context lengthens, the costs become unreasonable. This is because the model doesn't just roughly scan the preceding text as a single article; instead, for every position it generates, it must establish relationships with a large number of preceding positions. As context length increases, computational and memory pressures rise very steeply.
V4's approach is to break down "viewing the context" into finer granularity. It no longer requires the model to view the entire history in a flat, uniform manner across all layers but instead lets different attention modules handle memory tasks at different scales.
Some modules are responsible for finer compression and filtering: first organizing continuous small segments of tokens into more compact memory units, then having the current position focus only on the most relevant parts.
Other modules are responsible for coarser-scale global perception, compressing longer stretches of history into fewer memory nodes and then establishing relatively complete connections between these nodes. It sacrifices some local detail but gains a holistic grasp of very long histories.
I think this direction is very DeepSeek.
Because DeepSeek's most critical technical ethos over the past two years has always been not about "stacking big" but about "sparsification" and cost reduction.
V2 and V3's MoE represented sparsification at the parametric level: the model's total capacity was large, but each token only invoked a subset of experts, so capabilities increased without costs exploding proportionally.
V4 takes this a step further by advancing sparsification to the context itself: not all historical tokens enter attention with equal resolution but are compressed, filtered, and layered before being used by the model.
So I don't think this 1M context should be seen merely as a product selling point.
It's more like an extension of DeepSeek's technical route (roadmap): first using MoE to resolve the contradiction between "model capacity and inference costs," then using a new attention structure to resolve the contradiction between "context length and computational costs." The former makes large models cheaper; the latter makes long tasks more feasible.
API Pricing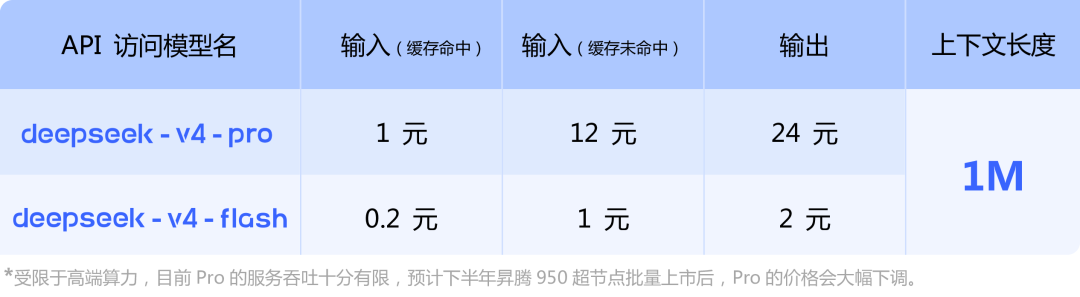
The reason DeepSeek caused such a stir last year is not just because it was strong or cheap but because it made everyone realize for the first time very strongly that strength and affordability could coexist.
This had a huge psychological impact on the industry. Previously, everyone assumed that top-tier models were expensive and that low-cost models had to compromise on capabilities. But DeepSeek shattered this default assumption. Being cheap but not useful wouldn't change the industry; being strong but too expensive would only serve a few scenarios. But being both strong and affordable changes the cost structure, and when costs move, the ecosystem above it moves too.
Looking roughly at public API pricing, the price of deepseek-v4-pro is basically the same as the newly released kimi-k2.6. The former is more expensive when the cache is not hit but cheaper for output.
However, k2.6's price is for a 256K context length, while deepseek-v4-pro offers a 1M context. According to the previous billing rules of Xiaomi's MiMo token plan, increasing the context from 256k to 1m would double the API price.
Moreover, we need to see the gray supplementary information below. Currently limited by high-end computing power, the service throughput of Pro is very limited. It is expected that after the batch launch of Ascend 950 supernodes in the second half of the year, Pro's price will drop significantly.
This indicates that the current Pro version's price has been deliberately set high because the thrust computing power has not yet caught up. In the future, when the Pro version's price drops significantly, it could be halved or even halved again from the existing price.
Domestic Computing Power Is Ready
There have been rumors that DeepSeek-V4, instead of following industry norms by giving early adaptation priority to NVIDIA, has first given it to domestic chip manufacturers like Huawei.
At the time, this sounded like just another rumor because the default process in the large model industry has always revolved around CUDA. Before releasing a new model, model vendors would let core players in NVIDIA's hardware and software ecosystem adapt early to ensure the model runs fast and stably on mainstream GPUs as soon as it goes live.
Now it seems that a full domestic AI stack is basically ready.
As we mentioned earlier, DeepSeek wrote in its release announcement that due to limitations in high-end computing power, the current service throughput of Pro is very limited. It is expected that after the batch launch of Ascend 950 supernodes in the second half of the year, Pro's price will drop significantly.
Huawei Computing's official account also stated that Ascend has consistently supported DeepSeek's series of models. This time, through close collaboration between the two sides' chip-model technologies, all products in the Ascend supernode series will support DeepSeek V4 models. Ascend CANN has also arranged a live broadcast for the debut of DeepSeek V4 on Ascend.
CUDA's advantage is not that NVIDIA's individual cards are very strong but that models, frameworks, operator libraries, development tools, deployment experience, and engineering talent have all grown around it for many years. Moving from CUDA to CANN requires a large number of low-level operators, precision alignment, communication, scheduling, and inference services to work smoothly and well enough.
The fact that DeepSeek-V4 can run as an important service foundation on Ascend supernodes is a very critical validation for domestic computing power. DeepSeek's cost-effectiveness doesn't come out of nowhere; it must have a supply of computing power behind it.
If it always relies on expensive, limited, and unstable external GPUs, even the strongest models will struggle to maintain low prices in the long run. Only if domestic computing power can take over can DeepSeek continue to push the "strong model + low price" approach.
So I think this can be seen as one of the hardest industry signals in DeepSeek-V4: the model is here, long contexts are here, Agent capabilities are here, APIs are here, and now even the domestic computing power foundation is starting to connect.
The closed loop (closed loop) is beginning to form.
DeepSeek is responsible for delivering model capabilities and cost curves, Huawei Ascend is responsible for supplying high-end inference computing power and supernodes, CANN is responsible for supplementing the domestic software stack, and developers and Agent products are responsible for driving demand.
Why DeepSeek-V4's release is so exciting.
It's not just an isolated model update but connects many previously scattered threads: Liang Wenfeng's idealism, DeepSeek's honest expression, 1M context, Agent capabilities, low-priced APIs, Ascend supernodes, and the scaling up of domestic computing power.
Each one is important on its own, but together, they are truly exciting.
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







