World Models: The Top Technical Narrative in Embodied AI
 05/12 2026
05/12 2026
 497
497

Editor's Note: Enabling AI to think and act like humans was once the ultimate fantasy in science fiction. Today, with general large models taking the leap into the physical world, the embodied AI brain has become the ultimate high ground in the tech competition.
Yet the evolution of technology is never a smooth journey; data scarcity, generalization challenges, and even the slightest hallucination create chasms between demos and real-world deployment.
As end-to-end becomes an industry buzzword and VLA models continuously push boundaries, we need sober reflection: What is the optimal architecture for an embodied AI brain? How can the flywheel of computing power and data drive the emergence of physical intelligence?
On the eve of this technological paradigm shift, Xinghe Frequency has curated a special series, 'Embodied AI Brain.' We will delve into evolving technological paradigms, attempt to penetrate the surface hype of technical concepts, return to the essence of systems and architectures, and document the evolutionary journey of agents from having bodies to possessing wisdom.
Previous Article: 'Embodied AI: Time to Break Free from the 'China Innovates, Overseas Markets Popularize' Cycle'
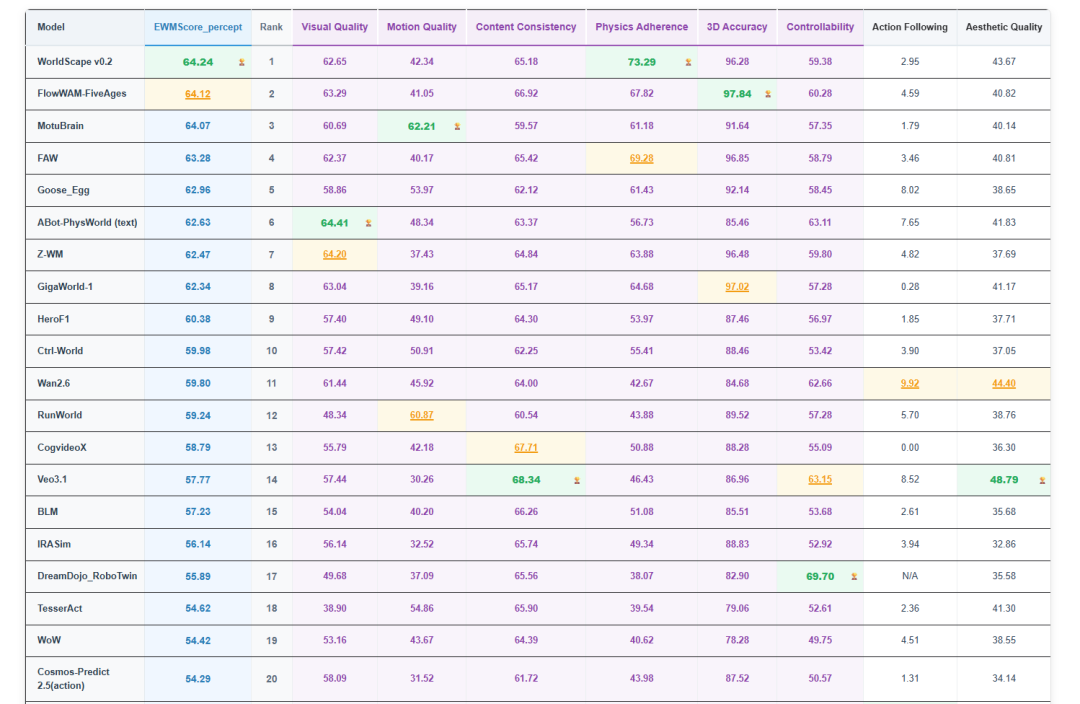
Less than three months after its release, the top spot on the WorldArena leaderboard changed hands ten times, witnessing an intense ranking tug-of-war.
This evaluation system, jointly launched by top institutions such as Tsinghua University, Peking University, the University of Hong Kong, Princeton University, and the Chinese Academy of Sciences, is currently the international authoritative public evaluation standard in the field of embodied AI world models.
The focal point of competition among multiple companies is to find new narratives about world models following VLA.
In fact, the surge in world models represents a collective choice driven by industry technological evolution and capital investments.
Earlier this year, Jim Fan, head of NVIDIA's robotics division, published a lengthy article highlighting the core shortcoming of VLA models—their lack of physical causal understanding—and explicitly stated that world models represent the future of general-purpose robots.
Following closely, WorldArena officially launched, establishing a rigorous evaluation system with 16 sub-indicators and 3 real-world tasks. It became a litmus test for global world models and provided a unified benchmark for technical comparisons.
Capital markets are equally enthusiastic.
In March, AMI, a world model company founded by former Meta Chief Scientist and Turing Award winner Yann LeCun, completed a $1.03 billion seed funding round, setting a record for seed funding in Europe's AI sector.
In the domestic market, Jijia Vision secured 2.5 billion yuan in funding within a month, becoming China's first world model unicorn, while Shengshu Technology obtained a 2 billion yuan Series B funding round led by Alibaba Cloud.
From academic consensus to leaderboard competition, from giant corporations' strategies to capital inflows, world models in the embodied AI field of 2026 are transitioning from auxiliary tools to core engines for physical world understanding and embodied decision-making.
The industry's focus has shifted from VLA models in 2025 to world models that understand physics and predict the future.

Chinese Companies Lead WorldArena
From the global perspective of WorldArena, Chinese players have transformed from participants to leaders.
Companies such as Manifold Space, Shengshu Technology, Fifth Era of CAS, Jijia Vision, and Starry Era have successively reached the top, surpassing overseas giants like Google and NVIDIA.
Manifold Space emerged as the latest dark horse, with its self-developed WorldScape v0.2 reaching the summit in late April and securing first place in three indicators: comprehensive perception, physical adherence, and trajectory accuracy.
The technical core of WorldScape 0.2 lies in its implementation of multi-expert collaboration through a Mixture of Experts (MoE) architecture. By adopting a phased learning approach, it constructs a world model that balances physical authenticity and spatial accuracy.
Its greatest technical advantage is achieving extremely high reasoning efficiency with a minimal parameter scale, successfully transforming this robust world understanding capability into highly successful embodied control strategies and establishing a complete technical loop from perception and prediction to action.
Fifth Era of CAS, the supplier of Unitree's 001 model, secured second place overall and first in 3D accuracy with its model FlowWAM-FiveAges.
While specific details remain undisclosed, the model's name suggests breakthroughs in dynamic fluidity and causal prediction within physical spaces compared to its predecessors, ultimately demonstrating clear advantages in physical adherence and 3D accuracy.
Currently ranked third is Shengshu Technology's MotuBrain, which secured first place in two sub-indicators: motion quality and process scoring.
MotuBrain integrates previously fragmented world models and action models, proposing and implementing a new paradigm—the World Action Model.
Its core lies in enabling a single model to possess both cognitive and action capabilities, transitioning from understanding and generating the world to acting within it, thereby completing a closed loop from perception and decision-making to execution.
Its characteristics can be summarized as 'Four Unified Brains': unified brain with multiple capabilities, unified brain with multiple forms, unified brain with seamless integration, and unified brain with foresight, aiming to overcome the final hurdle preventing robots from autonomously completing multi-step continuous tasks in open, dynamic environments.

In addition to these three companies, GigaWorld-1, the first embodied world model to surpass 60 points in comprehensive score, comes from Jijia Vision.
Technologically, it is an action-control world model designed specifically for embodied scenarios.
It deeply inherits the core architecture of its predecessor, EmbodieDreamer, while introducing two technical innovations:
First, it incorporates an explicit action modeling mechanism, fundamentally ensuring geometric consistency during video generation.
Second, it innovatively integrates a differentiable physics engine to obtain precise physical parameters, enabling realistic simulation and strict adherence to complex physical interaction processes.
Additionally, the model was trained using tens of thousands of hours of high-quality real robot operation videos accumulated by the team, significantly enhancing its generalization capabilities in open scenarios.
Starry Era represents the first Chinese company on the leaderboard to surpass both Google and NVIDIA.
Its Ctrl-World, developed in collaboration with Stanford's Chelsea Finn (PI Founder) team, is the world's first controllable generative world model. It adopts an action-conditioned architecture to overcome three major bottlenecks of traditional world models: single-view hallucinations, imprecise action control, and poor long-term consistency.
Its design philosophy is highly pragmatic:
First, it embeds physical engine constraints during training, enabling the model to learn and adhere to Newtonian mechanics, ensuring physically plausible scene generation and interactions.
Second, it integrates multi-view joint and video prediction models, implicitly modeling depth maps and 3D spatial structures while predicting RGB images, thereby acquiring precise depth perception and spatial awareness.
Finally, the model design closely aligns with practical robotic applications, such as strategy evaluation, motion planning, and data synthesis.
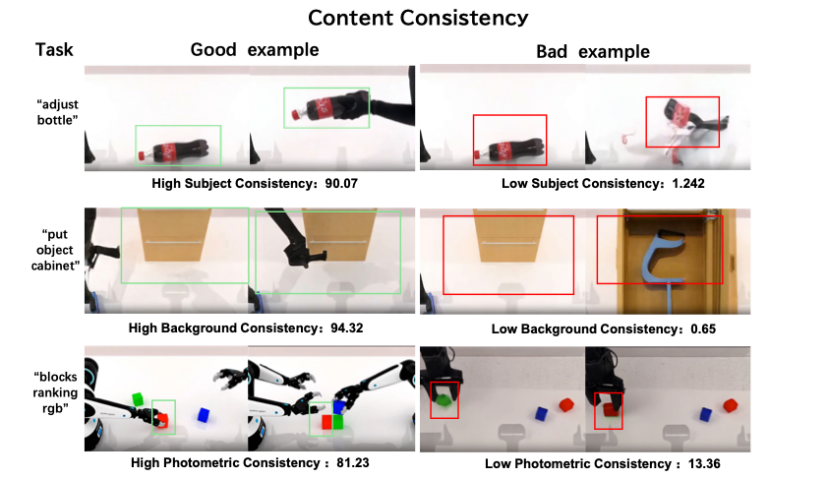
The models from these five companies each have distinct characteristics—some rely on physical intuition for rehearsal, others on VLA collaboration for verification, some on geometric precision accumulation, and others on causal reasoning.
However, they all share one commonality: they no longer settle for making AI appear similar but compel AI to think correctly.
This represents the true threshold of world models.

Three Types of Players Converge in the World Model Arena
As world models gain traction, players layout (Note: ' layout ' is kept as-is since it represents a strategic term without a direct English equivalent; it means 'strategic layout /positioning') under the surface are gradually emerging. Both major corporations and startups are as if by prior agreement (unanimously) stepping into the river of embodied AI.
In engineering practice, world models are not a one-size-fits-all technical proposition. Players entering the field can be broadly categorized into three groups based on their technical approaches: major corporation adherents, all-in world model advocates, and VLA+world model fusionists.
Among major corporations, NVIDIA, Google, Alibaba, and Tencent are actively positioning themselves.
Their core advantage lies not in the radicalism of a single technical route but in the depth of their computing power, scenarios, data, and engineering capabilities.
Alibaba's approach is particularly representative; they treat world models as a critical piece in their AI infrastructure puzzle, establishing a complete pipeline from model development to real-world deployment.
The Tongyi Qianwen team introduced Wan2.6, a native multimodal video model focusing on multimodal fusion and efficient deployment. It supports scene generation driven by text and images while balancing visual realism and physical consistency.
It is adaptable to multiple scenarios such as robot training and virtual simulation, while deeply collaborating with the Tongyi large model family, enabling bidirectional empowerment between world models and general AI capabilities.
The Gaode team launched ABot-PhysWorld, a video model designed for predicting physical world patterns. It accurately foresees object motion trajectories under complex interactions while maintaining multi-step causal consistency.
In WorldArena evaluations, ABot-PhysWorld secured first place in visual quality for a single indicator.
Ant Group's Lingbo took a distinct path emphasizing open-source ecosystems, introducing two world models with different focuses.
LingBot-VLA is a foundational model for embodied AI, achieving cross-entity and cross-task generalization capabilities, promoting the large-scale deployment of 'one brain for multiple machines.'
Meanwhile, LingBot-World focuses on high-precision physical modeling, creating high-fidelity, interactive virtual training environments for scenarios such as embodied AI, autonomous driving, and game development.

Another group of players has chosen a more radical approach—not treating world models as patches or auxiliary modules for VLA but directly building native intelligent systems for the physical world with world models as their foundation.
Representatives of this camp include Taishi Intelligent Navigation, Daxiao Robotics, and Qianjue Technology.
Taishi Intelligent Navigation released AWE3.0, the world's first general-purpose embodied large model capable of practical tasks, boasting advantages in sub-millimeter precision operations, flexible object perception and control, stable execution of long-duration tasks, and cross-scenario migration.
The robot A1, equipped with this model, set a Guinness World Record by successfully assembling sub-millimeter-grade wire harnesses 105 times within an hour.
Daxiao Robotics took a different path—edge deployment.
Its Enlightened 3.0 model helps machines understand physical world causality through a unified multimodal understanding-generation-prediction architecture.
Among them, Kairos 3.0-4B is the world's first embodied world model capable of real-time generation on the THOR edge platform, with a video generation time-to-duration ratio of 1:1.5, meaning the model's reasoning speed essentially keeps pace with changes in the physical world.
Additionally, another group of players has abandoned the limitations of a single technical route, opting instead for deep integration of VLA and world models.
By leveraging their synergistic complementarity, they enhance robots' autonomous decision-making and execution capabilities. ZhiYuan Robotics' strategy is the most systematic and representative in this regard.
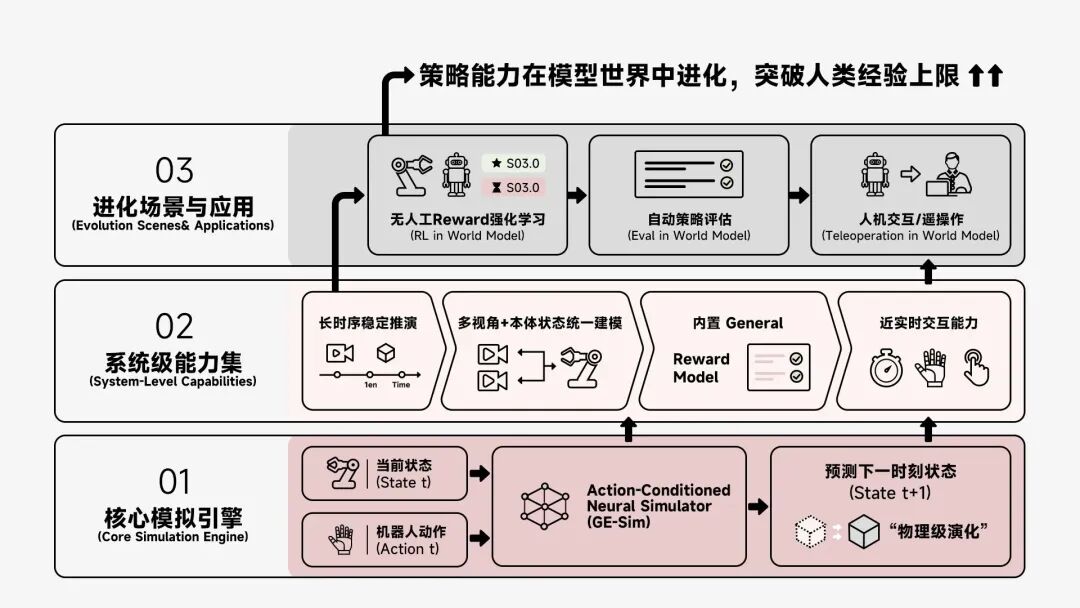
In April, ZhiYuan released Genie Envisioner 2.0, a truly interactive world model.
It is not merely a generative model but a usable system capable of strictly responding to robot action signals, generating high-fidelity environmental changes, and adhering to physical and semantic logic.
Previously, ZhiYuan had established a three-tier collaborative world model framework:
EnerVerse-AC, the action generation layer, converts high-level instructions into specific executable robot actions, ensuring precision and continuity.
Genie Envisioner, the virtual modeling layer and core of the world model, constructs high-fidelity, physically consistent virtual scenarios, simulating environmental changes and action feedback to provide high-quality virtual data for VLA training.
Act2Goal, the autonomous execution layer, closes the loop between action generation, scenario simulation, and autonomous decision-making, enabling robots to autonomously adjust action strategies based on virtual scenario deductions and significantly improving success rates in unfamiliar tasks.
These three layers form a closed-loop collaboration, deeply integrating the physical reasoning capabilities of world models with the real-time execution capabilities of VLA, effectively mitigating the shortcomings of single-technical-route approaches.
Overall, while the three types of players follow different paths, they share a unified goal: to propel world models from generating images to understanding and intervening in the physical world.
Major corporations rely on technical depth to build foundations, all-in advocates bet on paradigm shifts for the future, and fusionists seek optimal solutions through engineering—these three rivers are converging into the deep sea of embodied AI.

The world model is destined to undergo a value reconstruction.
In fact, there is no unified definition of the world model in the industry. Different teams, based on their distinct understandings of cognition, have developed three markedly different technical approaches:
Represented by Google's Genie, which reconstructs the world through video generation.
Represented by Li Feifei's WorldLabs, which explicitly models the world through 3D spatial generation.
Represented by Yann LeCun's JEPA, which enables AI to directly learn the abstract structure of the world.
From a practical application perspective, the world model often serves as a supporting role, primarily empowering VLA models, reducing data costs, and enhancing task robustness.
In terms of core value, the current primary role of the world model is to understand the physical world, predict future states, and compensate for the lack of causal reasoning in VLA models.
The world model can construct a virtual internal world by learning physical laws, predict action outcomes and environmental changes, provide VLA with pre-emptive predictive capabilities, and enhance adaptability in complex scenarios.
Secondly, it enhances data efficiency, addressing the data hunger of VLA.
VLA model training relies on expensive and scarce real-world data. The world model can generate high-fidelity synthetic data, covering long-tail scenarios and extreme cases.
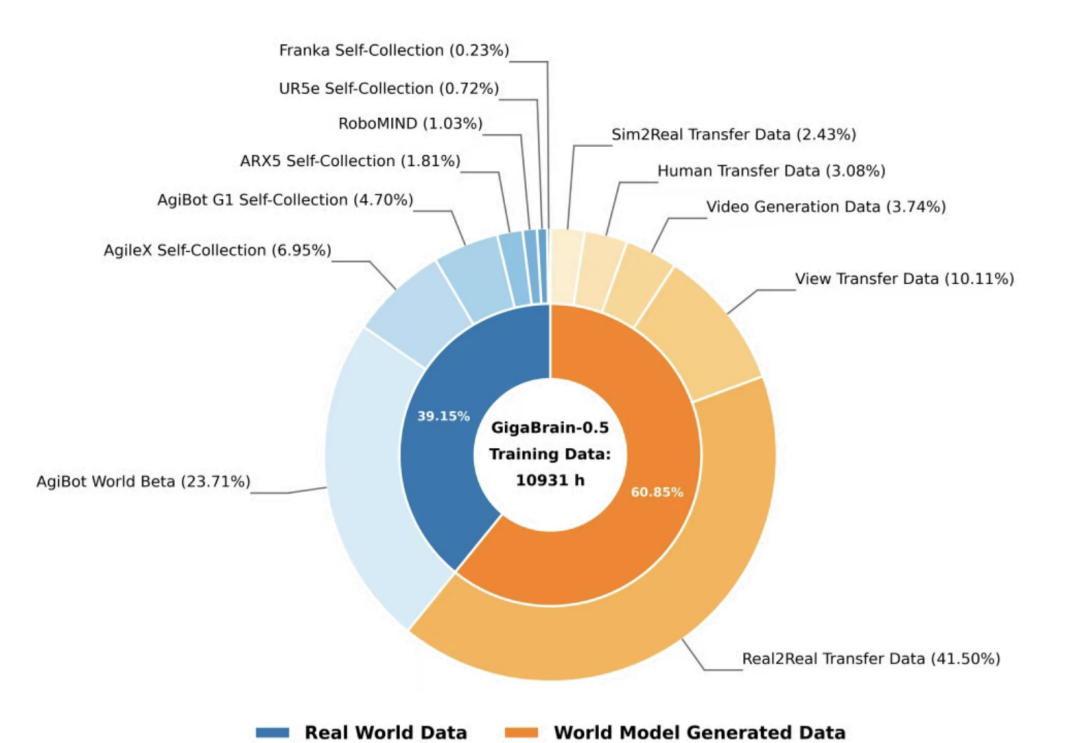
For example, in Juejia Shijie's GigaBrain-0.5M pre-training data, 61% is synthesized by its self-developed world model, GigaWorld, significantly reducing reliance on real-world data.
Finally, it improves the robustness of long-duration tasks.
VLA models are prone to action drift and procedural errors in multi-step, long-duration tasks. The world model can predict environmental evolution throughout the process, correct action deviations in real-time, and ensure task continuity.
For instance, Zhiyuan Robot's Act2Goal, through virtual simulation of the entire process, enables robots to not only autonomously complete tasks within the training domain but also tackle unseen tasks, ultimately truly understanding the operational process of tasks and improving success rates in unfamiliar long-duration tasks.
So, where will the world model head in the future? This topic has been a subject of intense debate this year.
One school of thought, led by Jim Fan, advocates for the replacement theory.
Earlier this year, NVIDIA's DreamZero, through autoregressive Transformers and real-world observation injection techniques, enabled robots to achieve zero-shot/few-shot generalization across tasks, environments, and embodiments.
Compared to traditional VLA models, DreamZero demonstrates a better understanding of the physical world, supports real-time closed-loop control, and exhibits significant improvements in generalization in real-world robot experiments.
Companies like Genelist from the United States support a fusion perspective, arguing that the relationship between the world model and VLA is not an A or B issue but rather an A and B issue.
Logically, VLA will not disappear but will internalize its capabilities and undergo a role transformation.
The core strengths of VLA lie in semantic understanding, real-time action execution, and efficient on-device inference, which are difficult for the world model to fully replace in the short term.
The future technological paradigm may involve the world model serving as the core brain, responsible for overall planning, physical simulation, and future prediction, while VLA acts as a perception-execution component, responsible for real-time environmental understanding, language instruction parsing, and precise action execution.
The two will deeply integrate and collaboratively iterate, with the world model generating virtual data to train VLA and enhance its generalization capabilities, while VLA's real-world interaction feedback optimizes the world model and improves its physical fidelity, forming a closed-loop evolution.
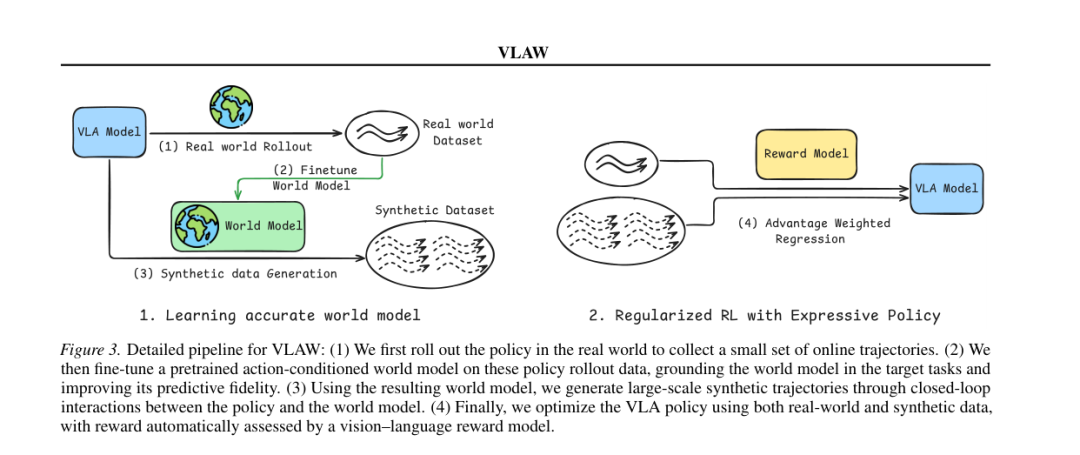
From a medium- to long-term development perspective, the evolution of the world model will progress through three stages:
In the short term, the world model will continue to play a crucial supporting role in physical data generation and long-duration task simulation.
In the medium term, with continuous improvements in control latency optimization and physical simulation accuracy, the functional boundaries between VLA and the world model will blur, forming a tightly interactive embodied native intelligence network.
In the long term, the industry may no longer need to distinguish between VLA and the world model separately. Designers will directly construct a holistic intelligent agent from the ground up that can simultaneously understand the physical world, perform voice reasoning, and achieve high-precision force feedback control.
The 2026 world model craze is not merely an industry trend but an inevitable outcome of the leap from perceptual imitation to cognitive understanding in embodied intelligence, driven by technology, capital, and market forces.
The ultimate goal of the world model is to enable robots to truly understand the physical world and possess autonomous intelligence.
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!
-
![]()
AI Agent Smartphones: The Next Competitive Edge Transcends Large Models
-
![]()
Over 880 Million Yuan Worth of Orders Unveiled, Bidding Launched for Shenzhen Eastern Public Transport
-
![]()
Tesla's Robotaxi Hits the Road: A Monumental Gamble with an Uncertain Future







