From Data Scarcity to Open Source Boom: How China's Embodied AI Data Industry Can Break Through
 05/15 2026
05/15 2026
 727
727

By 2026, the humanoid robot and embodied AI industries will enter a decisive phase of implementation, with industry consensus shifting from 'large model-driven' to 'embodied implementation.' The core determinant of this direction is no longer just hardware parameters like motors, reducers, and dexterous hands but 'embodied data.'
Currently, the reality is that the 'brain' is 'dull' while the 'cerebellum' is 'advanced.' Robots can run and jump but struggle with tasks like screwing, wiring harnesses, and handling fragile items. Model parameters keep growing, yet generalization capabilities remain stagnant. The root cause is that embodied AI is facing an unprecedented data scarcity crisis—not a lack of visual text but a shortage of real, physical, interactive, and generalizable 'physical AI data.'
Recently, companies like Daimeng, JD.com, Zhiyuan, and Passini have successively opened up real-world datasets, marking the industry's direct confrontation with this core bottleneck.
Data is Not Fuel but an 'Innate Deficiency'
First, it must be clarified that traditional data cannot feed 'physical intelligence.' What is needed is not more videos but the 'physical quartet': vision + action + force + touch, along with long sequences, first-person perspective, real-world scenarios, and cross-platform generalizability.
It is widely known that current robot training still heavily relies on VR teleoperation, non-physical teleoperation, internet videos, and simulated synthetic data, all of which suffer from three fatal flaws:
Lack of Physical Common Sense: Vision-language models (VLMs) only 'see' but do not 'touch,' lacking force, touch, deformation, and slippage information. Robots do not understand 'weight, hardness, brittleness.'
Strong Platform Binding: Data is deeply coupled with hardware, resulting in extremely low reuse rates across different robot models and scenarios, leading to data silos.
Inefficiency and High Cost: Traditional VR teleoperation data collection requires massive investment, with quality heavily dependent on manual labor, making it difficult to support industrial-scale applications.
It can be said that the essence of the conflict in embodied AI data lies in the inability to balance operational precision with environmental understanding. Without physical intuition, even large models are merely 'repeat executors,' incapable of handling open, dynamic, and unstructured real-world environments.
Meanwhile, the data gap is enormous, leaving the industry still in the 'Stone Age.' Relevant data shows that compared to the data volume required for ChatGPT, the gap in robot embodied data reaches 4-5 orders of magnitude. Even leading companies that build their own data collection facilities still face severe shortages of effective physical interaction data:
High-precision assembly, flexible operations, and force-controlled tasks require almost blank datasets combining touch + force + vision + action modalities.
Long-sequence, complex task, and first-person perspective (EGO) + end-effector positioning (UMI) fused data are scarce.
Real industrial/household/logistics scenario data is far less abundant than laboratory-controlled data, rendering them ineffective upon real-world deployment.
To address these 'innate deficiencies' in data, the industry's current mainstream solution is UMI+Ego. Luming Robotics positions it precisely: UMI is the staple food, and Ego is the vitamin, complementary rather than substitutable.
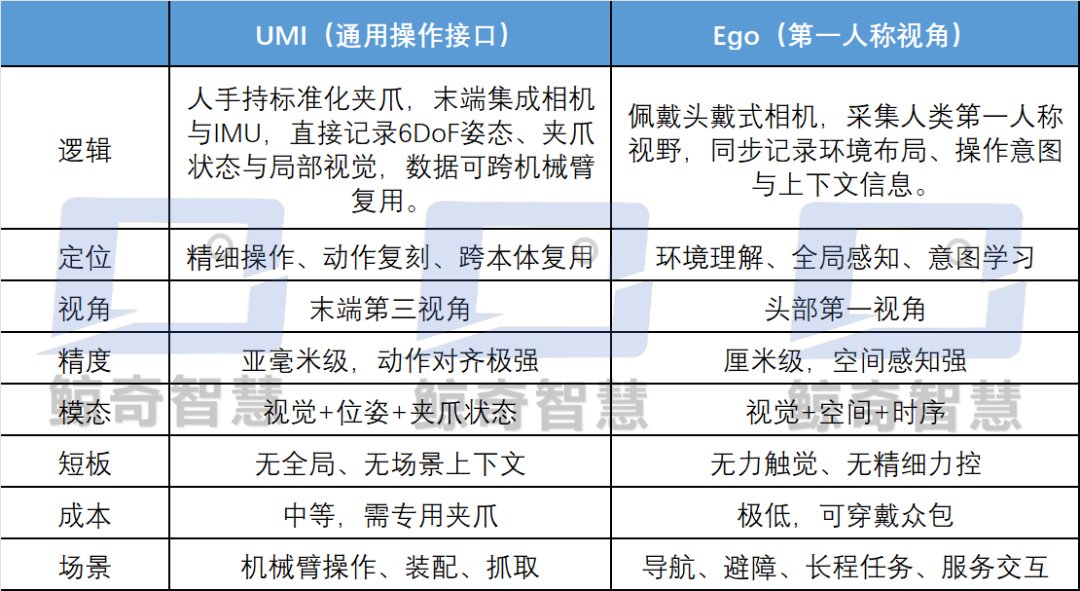
UMI alone = robots with 'clumsy hands and blind eyes'; Ego alone = robots with 'high eyes but low hands.' The fusion of UMI+Ego forms the data foundation for general-purpose embodied AI, which is also the underlying logic behind Luming Robotics' FastVue Mini Go head-mounted + gripper collaboration solution.
Industry-Wide 'Hemostasis': The Data Open Source Boom Targets Pain Points
2026 marks the first year of open-source embodied AI data. Companies like Daimeng Robotics, JD.com, Zhiyuan Robotics, and Lego Robotics have collectively opened up large-scale datasets, signaling the industry's shift from 'data scrambling' to 'ecosystem building' and from 'private closed-loop competition' to 'open standard co-construction.'
1. Daimeng: The Tactile Data Pioneer
Recently, Daimeng Robotics released the world's largest full-modality dataset containing tactile data, with an initial open-source release of 10,000 hours and plans to reach millions of hours and nearly a billion data points within the year. It integrates ultra-high-resolution tactile (contact force, deformation, slippage, texture) + vision + action, addressing the challenges of pure vision's inability to 'see clearly and touch accurately.'
It fills the gap in fine operation data, adapting to industrial scenarios like screwing, wiring harnesses, and handling flexible materials, improving training efficiency by 10 times. However, it is worth noting that the current open-source volume is limited, tactile device costs are high, and crowdsourced expansion is challenging.
2. JD.com: The Benchmark for Supply Chain Scenarios
Relying on over 3,600 warehouses and 200,000 stores, the data comes from real logistics, retail, and healthcare scenarios, closely aligning with industrial implementation needs. JD.com has simultaneously launched a data trading platform, forming a closed loop of 'collection-cleaning-training-trading,' with 95% data efficiency and a 60% cost reduction. However, the data is biased toward logistics and supermarkets, with insufficient coverage of households and precision industries, and weak tactile information.
3. Zhiyuan: Long-Duration Real-World and Generalization Paradigm
Some time ago, Zhiyuan Robotics released the world's first million-hour-scale full-domain real-world robot dataset, with long-duration tasks exceeding Google's Open X-Embodiment by 10 times. It features 100% real-world scenarios, including occlusions, clutter, and lighting variations, enabling direct transfer and deployment, with synchronized open-sourcing of simulation data.
Meanwhile, to create an 'ImageNet moment' for embodied AI, Zhiyuan has unified evaluation standards, lowering the entry barrier for small and medium-sized manufacturers. However, collection costs remain high, scalable crowdsourcing is difficult, and the tactile dimension is still weak.
From the recent consensus on open-sourcing datasets among leading companies, it is clear that the data competition has shifted from 'quantity' to 'quality': real-world scenarios > laboratory scenarios, multimodal > pure vision, long-duration > short task segments, and physically interactive > pure observation. Leading companies have abandoned pure in-house R&D and usage, turning to open supply.
Tactile data will also become the next high ground in data competition, with Daimeng's tactile technology route representing a core barrier for dexterous hands, precision assembly, and service robots. It also Side verification s that during the commercialization phase of embodied AI robots, data must serve real-world deployment.
Of course, it must be clarified that data open sourcing is not philanthropy but a struggle for data standards: those who open source first define data formats, annotation specifications, and evaluation benchmarks, locking in ecological discourse power.
This rejection of 'showroom data' also helps embodied data step out of the greenhouse, enabling generalizability, tradability, cross-platform compatibility, and end-to-end training, embracing the complexity of the physical world, and driving embodied AI from 'action imitation' to 'task generalization,' forming a positive flywheel of 'data → model → real robot → feedback → better data.'
The Path to Data Breakthrough: China's Embodied Data Competition
In the future, the competition in embodied AI will essentially be a competition for data sovereignty. Whoever masters high-quality, multimodal, cross-platform, and real-world data will control the future of general-purpose physical intelligence.
Currently, UMI+Ego has established the paradigm, and open sourcing has reconstructed the supply. Chinese companies now stand in the first tier. The next step is not about flashier hardware but about truer, more comprehensive, cheaper, and more usable data.
However, it must be clarified that data is no longer a byproduct of the industry but the primary productivity of embodied AI. It has become an independent track, with professional data factories, annotation platforms, and trading markets emerging, similar to the AI training data industry.
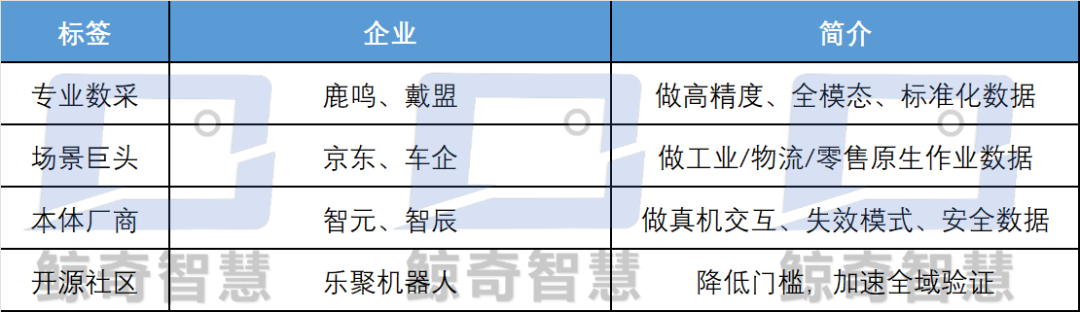
Similarly, we must recognize that four major bottlenecks in data still persist in the long term.
First is modality incompleteness, with 90% of data lacking tactile and force information. Pure vision cannot distinguish between 'gentle placement' and 'heavy smashing' or perceive slippage and deformation, causing robots to hesitate, mishandle, or break objects upon applying force.
Daimeng's tactile open sourcing is just the beginning; the industry still lacks large-scale, low-cost, high-resolution tactile datasets.
Second is insufficient model generalization, with data not transferring across platforms, leading to silos. Most manufacturers still collect data for their own platforms, rendering it ineffective when switching to another robotic arm. The value of UMI lies in decoupling end-effectors from platforms, but industry adoption remains below 30%, with much investment becoming sunk costs.
Third is scenario distortion, where laboratory data ≠ real-world data. Clutter, dust, vibrations, and lighting variations reduce POC success rates from 80% to 30% in mass production. Zhiyuan and JD.com's emphasis on real-world scenarios directly addresses this pain point.
Finally, there is the persistent issue of cost inversion, where collection costs exceed the robot's usable value. If household robots are priced below 100,000 yuan, they cannot bear data collection costs of hundreds of yuan per hour.
In the future, crowdsourcing, lightweight, and automated annotation must become the norm, similar to JD.com's approach of mobilizing 600,000 participants for data collection. Using lightweight Ego devices, crowdsourcing in households, food delivery, cleaning, factories, and other scenarios can minimize data costs, turning data collection into 'digital manual labor.'
The recent open-sourcing by Lego, Zhiyuan, JD.com, and Daimeng essentially publicizes the industry's foundational capabilities. Small and medium-sized enterprises no longer need to build their own data factories and can focus on scenario adaptation and model fine-tuning, accelerating mass production and deployment to first address 'profitable' scenarios.
Such as automotive parts, 3C sorting, logistics handling, and hotel delivery—highly repetitive, labor-shortage, and clear ROI scenarios—prioritizing data investment can form positive cash flows to fund R&D. Meanwhile, promoting the establishment of three major standards—cross-platform data interfaces, multimodal annotation specifications, and real-robot evaluation benchmarks—can resolve dataset incompatibility and model reuse challenges. WhaleQi Commentary
The data revolution is the true starting point for physical AI. 2026 marks the shift of embodied AI from 'muscle-flexing' to 'inner strength cultivation.' In the past, the industry was obsessed with gait, payload, and appearance; now, it finally admits that the lifeblood of physical intelligence lies not in motors and joints but in data.
The dense actions of Daimeng, JD.com, Zhiyuan, and Luming Robotics herald a new era: whoever masters high-quality physical interaction data will dominate physical AI.
Without a data revolution, even the most dazzling robots are merely 'exquisite toys.' Only by transforming data deserts into oases can embodied AI truly enter factories, households, and hospitals, becoming the core carrier of new quality productivity. The second half of physical AI is not a model competition but a data war.
*Editor's Note: Original content is not easy; please respect the author. For reprinting, please contact us.
-
![]()
AI Agent Smartphones: The Next Competitive Edge Transcends Large Models
-
![]()
Over 880 Million Yuan Worth of Orders Unveiled, Bidding Launched for Shenzhen Eastern Public Transport
-
![]()
Tesla's Robotaxi Hits the Road: A Monumental Gamble with an Uncertain Future
-
![]()
Ford and Geely Forge New Joint Venture in Spain, Sidestepping Changan and JMC
-
![]()
199 RMB! Godox's First Camera Review: Subpar Photography, Transparent Viewfinder Frame is the Highlight
-
![]()
AI Smartphones: A Modern-Day 'Emperor's New Clothes'?
-
![]()
Yonyou Network: A Company Selling 'Transformation' but Struggling in Its Own Transition
-
![]()
Focus | CCCC’s Takeover of Greentown Comes to Fruition: Why Did the 11-Year ‘Control Without Authority’ Era End?







