Don't Be Fooled by Your Home AI Again! D Lab Community's Latest Method, TraceLift, Exposes 'Fake Reasoning' and Ensures Model Thinking Processes Are Truly Reliable
 05/18 2026
05/18 2026
 620
620
Interpretation: The Future of AI Generation
TraceLift: Making the Reasoning Process Truly 'Helpful'
The correct answer is not the endpoint. For a planner-executor system, the value of a reasoning trajectory depends on whether it makes it easier for the subsequent executor to succeed.
From 'Is the Answer Correct?' to 'Is the Reasoning Useful?'
In the past few years, improvements in the reasoning capabilities of large models have largely relied on verifiable feedback: for math problems, the final answer is checked; for code problems, unit tests are run, and rewards are given if they pass. This logic is simple, direct, and effective. However, when the reasoning trace is no longer just an explanation but is consumed by subsequent models, tools, or executors, the problem becomes more complex.
Many systems are no longer 'a single model directly giving the final answer' but have evolved into a two-stage process: the planner first writes reasoning, plans, constraints, or intermediate steps, and then the executor generates the final code, answer, or action based on these contents. In such cases, the correctness of the final result only indicates that the system ultimately succeeded but does not necessarily mean that the reasoning written by the planner is reliable. A trace may appear smooth and may even lead to the correct answer, but it may not truly contain the key information the executor needs.
TraceLift focuses on this more nuanced issue: how to train a reasoning planner so that the reasoning it generates is not only superficially reasonable but also truly enhances the success rate of a frozen executor.
The Core Viewpoint of TraceLift
TraceLift treats reasoning traces as 'intermediate products' rather than ordinary explanatory texts. The quality of these intermediate products should not be determined solely by the final answer or by whether an LLM judge deems them to resemble reasoning; instead, it should be evaluated based on their actual assistance to the subsequent executor.
Its training framework can be summarized into three parts: the planner generates a reasoning trace, the frozen executor consumes the trace and generates the final artifact, and the verifier determines whether the final artifact is correct. Building on this, TraceLift introduces an additional Reasoning Reward Model to assess the reasoning quality of the trace itself and uses executor uplift to measure whether the success rate of the same frozen executor truly increases 'with this reasoning' compared to 'without reasoning.' The method is illustrated in the following figure:
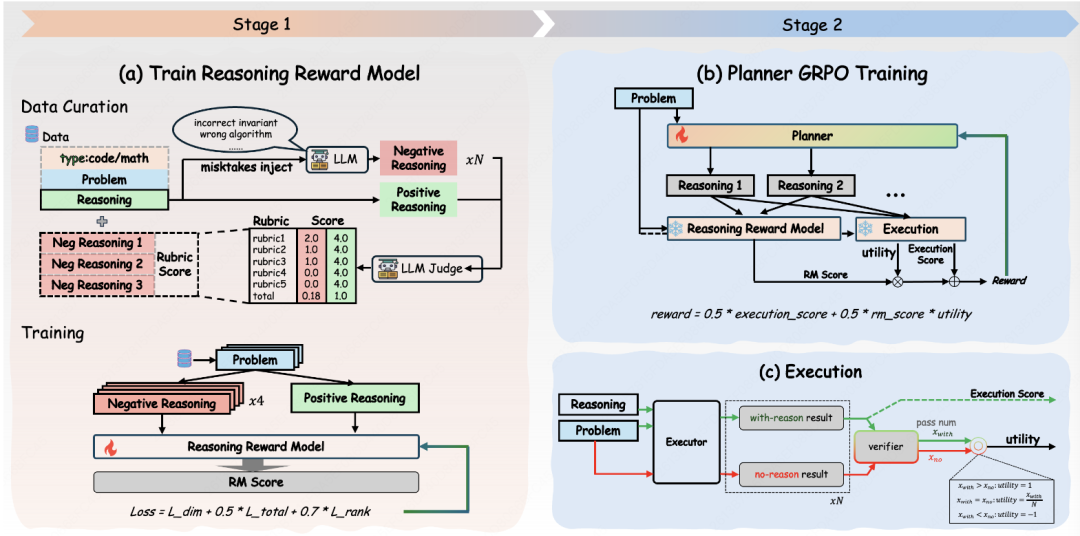
TraceLift Framework Overview
The final reward is not a single outcome reward but combines three types of signals: whether the final task is successful, whether the reasoning trajectory itself is of high quality, and whether this reasoning truly enhances the executor. This way, the model does not receive high rewards just because 'the answer happened to be correct' or is overly rewarded just because 'the reasoning is well-written.'
TraceLift-Groups: Data Specifically Designed to Learn 'Reasoning Quality'
To enable the Reasoning RM to learn to distinguish reasoning quality, TraceLift constructs TraceLift-Groups. This dataset does not simply collect questions and answers but constructs a set of reasoning traces around the same question: one high-quality reference trace and multiple flawed traces subjected to local perturbations. These flawed traces are still relevant to the task but disrupt key reasoning support.
The data comes from two sources: GSM8K train and OpenCodeReasoning, resulting in a total of 6,000 reasoning groups. Perturbations in code tasks include incorrect algorithms, missing boundary cases, off-by-one reasoning, incorrect invariants, infeasible complexity, and vague pseudo-solutions; perturbations in math tasks include arithmetic errors, incorrect operations, missing conditions, mismatched units, unsupported leaps, and premature answers. The key focus of this design is to enable the RM to learn 'which reasoning is more reliable and better supports subsequent execution for the same question' rather than simply learning 'whether the final answer is correct.'
Representative Results: Where Does TraceLift Truly Improve?
Below are just a few of the most illustrative results, without overwhelming tables.
1. Code: The Planner Writes Better, and the Executor Truly Passes Tests More Easily
In code tasks, TraceLift uses a fixed planner-executor protocol: the planner first generates reasoning, and the frozen executor then writes code based on the reasoning, with the final code's correctness determined by tests. In other words, during evaluation, the executor remains unchanged, and what varies is the intermediate reasoning generated by the planner.
On Qwen3-4B, TraceLift shows improvements over Exec-only across all code benchmarks.

This set of results indicates that TraceLift does not make the executor stronger but enables the planner to generate reasoning that is more suitable for the executor to consume. For code tasks, this typically means clearer algorithmic paths, more complete boundary conditions, and more explicit data structures and implementation constraints.
2. Math: The More Critical the Reasoning Trajectory, the More Valuable TraceLift Becomes
Math tasks rely more heavily on whether the intermediate steps truly support the final answer. Errors in variable definitions, units, operation order, condition preservation, or intermediate quantity tracking can all lead the subsequent executor astray. On Qwen2.5-7B, TraceLift shows significant gains on math benchmarks.

Especially notable is the +21.00 pp gain on SVAMP: TraceLift rewards not 'longer explanations' but reasoning that better helps the executor correctly track objects, relationships, and computational paths.
3. LoRA / Full-Parameter: Gains Are Not Simply from More Parameters
A natural question is whether TraceLift's improvements are solely due to more extensive training or larger parameter budgets. The paper compares LoRA and full-parameter GRPO using Qwen2.5-7B. Under the same parameterization settings, TraceLift outperforms Exec-only in both cases.

Full-parameter training can indeed raise some upper limits, but it cannot replace better rewards. The key to TraceLift is not 'training with more parameters' but aligning the reward with a finer-grained goal: whether this reasoning is both reliable and useful to the executor.
4. Reward Ablation: Looking Only at Final Correctness Is Insufficient, and So Is Looking Only at Reasoning Quality
TraceLift's reward design incorporates two critical axes: final verifier success and uplift-weighted reasoning reward. The paper conducts an ablation study on Qwen2.5-7B code, and the results are clear.

No-uplift removes executor grounding, retaining only the intrinsic quality score from the reasoning RM, resulting in performance even lower than Exec-only. This demonstrates that reasoning that 'looks high-quality' does not necessarily mean the executor can truly use it. RM-uplift only, which removes the final verifier anchor, also underperforms compared to the complete TraceLift, showing that uplift cannot replace final task success. LLM-as-judge replacement is also unsatisfactory because the paper finds that direct judge scores are severely saturated: out of 600 logged samples, 573 scored greater than 0.95, a saturation rate of 95.50%, with an average judge score of 0.990. Such signals are nearly indistinguishable among traces within a GRPO group.
The complete TraceLift retains three things simultaneously: final task success, reasoning quality, and actual executor benefit.
What Did We Actually Test?
TraceLift's experiments cover multiple models, tasks, and training settings rather than isolated results. Models include Qwen2.5-7B, Llama3.1-8B, and Qwen3-4B; tasks include code and math; code evaluations include HumanEval, HumanEval+, MBPP-full, and LiveCodeBench; math evaluations include GSM8K, GSM-Hard, SVAMP, and MATH500; training settings include GRPO planner optimization, LoRA GRPO, and full-parameter GRPO; additional analyses cover the number of executor comparisons, reward component ablation, LLM-as-judge replacement, reasoning length, and executor utility dynamics.
The overall conclusion is that TraceLift consistently outperforms execution-only training under a fixed planner-executor protocol. Its gains come not from longer reasoning or a stronger executor but from more reasonable training signals: reasoning trajectories must be both of high quality and enhance the executor.
TraceLift's Positioning: Not Just Making Models 'Think More' but Making Reasoning More Actionable
Many reasoning methods tend to treat 'longer Chain-of-Thought' as a signal of improved capability. However, TraceLift's perspective is closer to that of an engineering system: a reasoning trajectory is an interface, and the quality of the interface lies not in how much it writes but in whether it clearly conveys the information the executor needs. In code, this information might include algorithm selection, boundary conditions, complexity constraints, type handling, and loop invariants. In math, it might include variable definitions, intermediate states, unit conversions, condition preservation, and target object tracking. TraceLift rewards these truly usable contents for the executor rather than fluent but vague explanations.
Thus, TraceLift can be understood as a form of executor-grounded reasoning training: it does not just train models to 'provide reasoning' but trains them to provide 'reasoning that is truly helpful for downstream execution.'
Which Scenarios Are Suitable for TraceLift?
TraceLift is most suitable for planner-executor-style systems: a model first generates a plan, reasoning, or intermediate trajectory, and then another frozen executor generates the final answer, code, or action. Code generation is a natural scenario because the planner needs to specify algorithms, constraints, and boundary conditions, while the executor handles implementation. Math reasoning is also well-suited because the reliability of intermediate steps directly affects the final answer.
It is also suitable for scenarios where reward signals should not be 'fooled' by 'final correctness.' If only the final result is considered, the model may learn shortcuts; if only an LLM judge is used, the model may learn superficially fluent explanations. TraceLift's advantage lies in combining final success, reasoning quality, and executor utility into a single training signal.
Summary
The core viewpoint of TraceLift can be summarized in one sentence:
In a planner-executor system, reasoning trajectories are not just explanations but intermediate products consumed by downstream models.
Therefore, when training a reasoning planner, we should not only ask whether the final answer is correct, nor should we only ask whether the reasoning appears reasonable. Instead, we should further ask: Did this reasoning truly help the executor?
The most core results include:
Code: On Qwen3-4B, code micro avg. improved from 65.88 to 68.32
Math: On Qwen2.5-7B, math micro avg. improved from 64.72 to 69.23
LoRA / Full: Under the same parameterization, TraceLift consistently outperforms Exec-only
Reward ablation: No-uplift, RM-uplift only, and LLM-as-judge are all weaker than the complete TraceLift
Judge score saturation: Direct LLM judge scores >0.95 for 95.50% of samples, making it difficult to serve as an effective dense reward
TraceLift provides a clear new direction for reasoning training: not just rewarding 'correct answers' but rewarding reasoning processes that can truly be utilized by subsequent executors.
References
[1] Correct Is Not Enough: Training Reasoning Planners with Executor-Grounded Rewards
-
![]()
Ford and Geely Forge New Joint Venture in Spain, Sidestepping Changan and JMC
-
![]()
199 RMB! Godox's First Camera Review: Subpar Photography, Transparent Viewfinder Frame is the Highlight
-
![]()
AI Smartphones: A Modern-Day 'Emperor's New Clothes'?
-
![]()
Yonyou Network: A Company Selling 'Transformation' but Struggling in Its Own Transition
-
![]()
Focus | CCCC’s Takeover of Greentown Comes to Fruition: Why Did the 11-Year ‘Control Without Authority’ Era End?
-
![]()
Final Verdict: The 2026 China Auto Forum Shines with Unique Characteristics at a Pivotal Moment
-
![]()
Tencent Maintains Matrix Approach, Alibaba Merges Entry Points: Tech Titans Initiate AI Agent Consolidation
-
![]()
Geely Secures Portion of Ford’s Spanish Production Capacity







