Claude Unleashes Its Most Powerful 'High-Risk' Model Fable 5 Overnight, But at a Sky-High Price
 06/10 2026
06/10 2026
 536
536
Powerful as a 'myth,' expensive for good reason.
In the early hours of June 10 (Beijing Time), Anthropic released its most powerful model, Claude Fable 5/Mythos 5, without any prior preheat (meaning 'warm-up' or 'teaser'). The former is available to the public, while the latter remains in controlled projects like Project Glasswing.
Fable translates to ' fable ' (fable or allegory). At first glance, Fable 5 seems like just another new addition to the Claude product line. However, according to Anthropic, Fable 5 belongs to the Mythos-class models—a public version of Mythos that they finally dare to release to ordinary developers and enterprises. Mythos, meanwhile, translates to ' mythology ' (myth or legend).

(Image source: Anthropic)
Why do we say they 'finally dare to release it'? The name Mythos has, over the past two months, become nearly synonymous with 'danger.' In April, Anthropic launched Project Glasswing, providing Claude Mythos Preview to a select group of security partners—including AWS, Apple, Cisco, CrowdStrike, Google, Microsoft, NVIDIA, Linux Foundation, and Palo Alto Networks—to identify and patch critical software vulnerabilities. At the time, Anthropic made it clear that Mythos Preview would not be widely released, simply because its cybersecurity capabilities were so powerful that they could potentially be abused.

(Image source: Anthropic)
Officials stated that Mythos had discovered numerous high-risk vulnerabilities, including long-undetected issues in major operating systems, browsers, and critical software. In the hands of defenders, it serves as a security tool; in the hands of attackers, it could become the next generation of automated vulnerability exploitation tools. Thus, Mythos was confined to Project Glasswing.
Until now, Anthropic has finally released this model. They've added a safety classifier to Fable 5, which may refuse high-risk requests or fall back to Opus 4.8. In simple terms, they've put guardrails around a model that previously couldn't be directly released and pushed it to market. Leikeji AGI (ID: leikejiagi) stayed up late compiling some information about this model—hopefully, you'll find it useful.
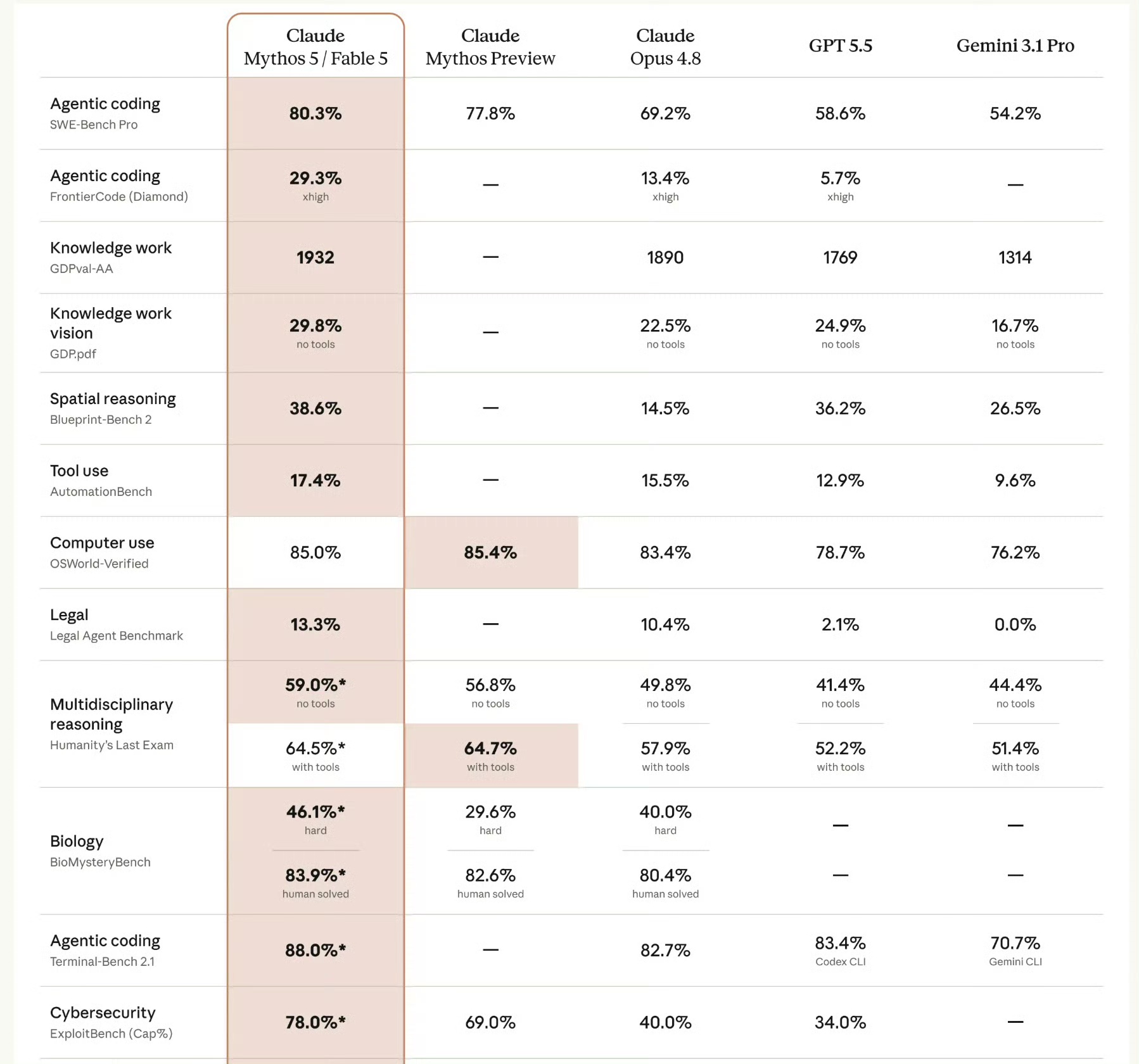
Fable 5's benchmark scores are nothing short of extraordinary. On SWE-Bench Pro, it achieved 80.3%, outperforming Mythos Preview's 77.8%, Opus 4.8's 69.2%, GPT 5.5's 58.6%, and Gemini 3.1 Pro's 54.2%. Based on this metric alone, it already stands out as a top-tier model.
The truly absurd part lies in FrontierCode Diamond, a benchmark closer to real-world software engineering that evaluates whether a model can write code that maintainers would accept. Fable 5 scored 29.3%, while Opus 4.8 managed only 13.4%, and GPT 5.5 just 5.7%. This isn't just a few percentage points ahead—the previous generation of Claude and its main competitors have been left far behind.
Many past AI programming models could write code, but the engineering quality was often unstable. Some code ran but was hard to maintain; some passed tests but caused issues in real projects. FrontierCode's harshness lies in its focus on whether a model has engineering taste and can handle long-term tasks in complex codebases. Fable 5's significant lead over Opus 4.8 here suggests that Anthropic has truly upgraded the 'soul' of agent-based coding.
(Image source: Anthropic)
On Terminal-Bench 2.1, Fable 5 scored 88.0%, compared to Opus 4.8's 82.7%, GPT 5.5 Codex CLI's 83.4%, and Gemini CLI's 70.7%. This means that when executing tasks in a terminal environment, reading error messages, modifying code, and continuing progress, Fable 5 has surpassed OpenAI's Codex CLI combination.
Benchmarks aren't everything. What truly frightens about Fable 5 is that it already behaves like a model capable of working on engineering sites. You throw a task at it, and it can read projects, break down tasks, invoke (meaning 'invoke' or 'utilize') tools, fix errors, and keep going. Anthropic's release notes mention that Stripe used Fable 5 to migrate a 50-million-line Ruby codebase, compressing work that would normally take a team two months into a single day. Even if such cases carry marketing hype, they can't obscure the fact that AI coding is moving from assistant (meaning 'assisting' in writing functions) to taking over engineering workflows.
Let's take DeepSeek V4-Pro Max as a somewhat inappropriate comparison. It scores 90.1% on GPQA Diamond, 93.5% on LiveCodeBench, and 80.6% on SWE Verified. These are already highly competitive scores within the open-source camp (meaning 'camp' or 'community'). Qwen3.7-Max has also made its presence felt in directions like GPQA, SWE Verified, and Terminal-Bench. For readers familiar with DeepSeek, this means domestic and open-source models aren't weak—many traditional strong benchmarks are approaching the capabilities of the most powerful closed-source models.
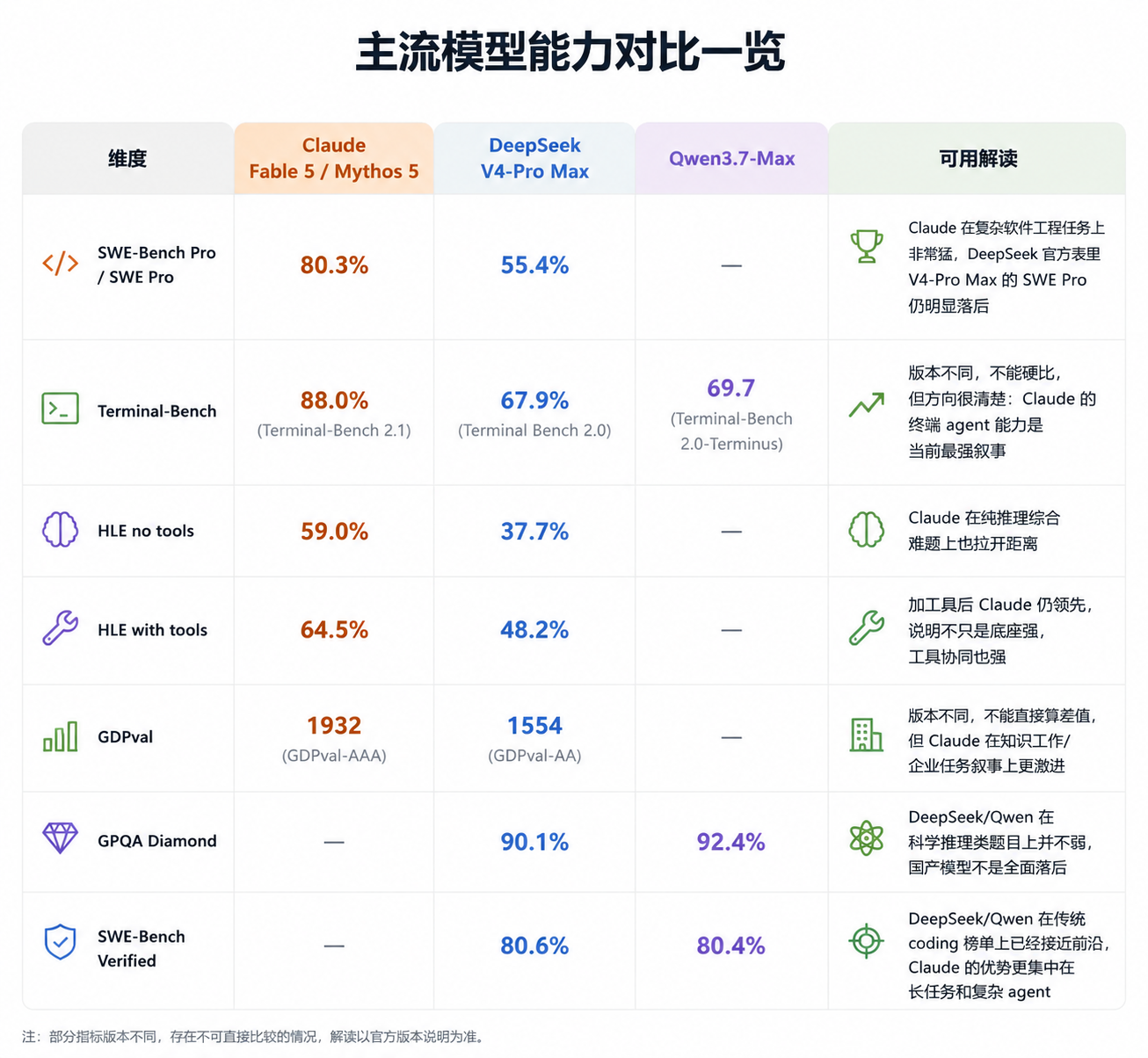
(Image source: Leikeji Graphics)
However, when it comes to metrics closer to real-world engineering and long-task execution, Fable 5's dominance becomes even more pronounced. On SWE-Bench Pro, Fable 5 scores 80.3%; DeepSeek V4-Pro Max's official SWE Pro score is 55.4%. On HLE with tools, Fable 5 scores 64.5%, while DeepSeek V4-Pro Max scores 48.2%. Though Terminal-Bench versions aren't identical, Fable 5 achieves 88.0% on 2.1, while DeepSeek V4-Pro Max scores 67.9% on 2.0. Fable 5 leads by a landslide in all these cases.
These numbers may not fully tell the story, but the direction is clear: DeepSeek excels in cost-effectiveness, open-source availability, and traditional capability metrics, while Fable 5 dominates in the most expensive and hardest-to-monetize tasks—especially long-task agents, complex engineering, tool coordination, and real codebase processing.
Visual and spatial reasoning are also skyrocketing. On knowledge work visual tasks like GDP.pdf, Fable 5 scores 29.8%, higher than Opus 4.8, GPT 5.5, and Gemini 3.1 Pro. On Blueprint-Bench 2, Fable 5 scores 38.6%, slightly higher than GPT 5.5's 36.2% and far above Opus 4.8's 14.5%. This explains why Anthropic emphasizes that Fable 5 can rebuild web applications from screenshots and extract precise numbers from scientific charts.
With Fable 5, processing multimodal content like images and videos feels more like connecting screens, charts, interfaces, and code into a complete task chain. When it understands a page, it has a chance to directly replicate it; when it comprehends a chart, it can transform the chart's structure into the next operational step.
What makes Anthropic hesitant to fully release Fable 5 are its cybersecurity and biological capabilities. On ExploitBench Cap%, Fable 5 scores 78.0%, compared to Mythos Preview's 69.0%, Opus 4.8's 40.0%, and GPT 5.5's 34.0%—a staggering gap. In security defense, this means the model can help enterprises and open-source maintainers find vulnerabilities faster; in the wrong hands, it could further lower the barrier to attack.
(Image source: Anthropic)
On BioMysteryBench hard, Fable 5 scores 46.1%, higher than Mythos Preview's 29.6% and Opus 4.8's 40.0%. Anthropic also mentions that Mythos 5 accelerates drug design workflows by about 10x, with molecular biology hypotheses favored by researchers in blind tests about 80% of the time. This sounds like great news for research but is enough to make regulators nervous.
Thus, Fable 5's strength doesn't just come from being 'smarter.' It excels in long tasks, engineering delivery, visual understanding, and high-value yet high-risk professional scenarios like security and research. In a sense, it is Anthropic's most powerful model currently available to the general public—period.
No matter how strong Fable 5 is, it can't escape one harsh reality: it's absurdly expensive. The official price is $10 per million input tokens and $50 per million output tokens. For comparison, Claude Opus 4.8 costs $5 for input and $25 for output—Fable 5 directly doubles those prices.
Even more awkwardly, its release coincides with a price war among large models. DeepSeek V4-Pro's current API price is $0.435 per million input tokens and $0.87 for output, with V4-Flash even cheaper at $0.14 for input and $0.28 for output.
Xiaomi's MiMo-V2.5 series also saw a permanent price cut in late May. The overseas version, MiMo-V2.5-Pro, now costs $0.435 for input and $0.87 for output, with officials emphasizing reductions of up to 99%. On Google's side, the Gemini API still offers numerous low-cost models, with Gemini 3.5 Flash priced at $1.5 for input and $9 for output. At the subscription level, Google also reduced the AI Ultra premium package from $250 to $200.
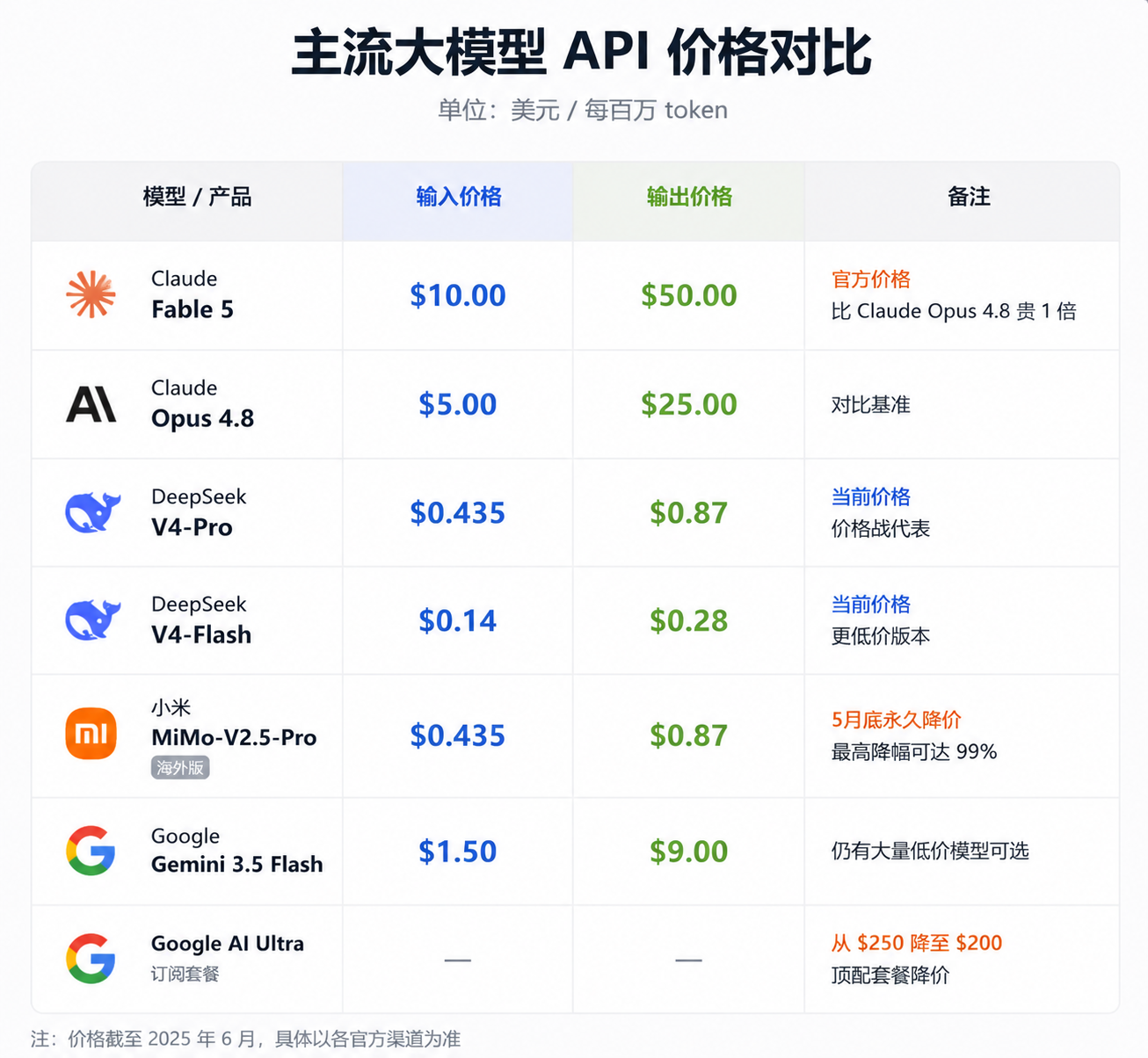
(Image source: Leikeji Graphics)
In other words, while the industry is pushing 1M-context, agent-based coding, and multimodal capabilities into lower price ranges, Anthropic has priced Fable 5 at $10 for input and $50 for output. Compared to DeepSeek V4-Pro and MiMo-V2.5-Pro, Fable 5's input price is about 23 times higher, and its output price is about 57 times higher. Even against Gemini 3.5 Flash, it's several times more expensive. This pricing alone could deter many ordinary developers.
But Anthropic's strategy is clear: they don't want Fable 5 to compete in areas where cheaper models suffice. Daily Q&A, light writing, and basic code completion don't warrant Fable 5. What they're selling is time savings in high-value tasks like large codebase migrations, long-context document analysis, complex enterprise workflows, cybersecurity defense, and scientific hypothesis generation. To put it bluntly: if you think your time is worth more, then Fable 5 is for you.
If a model can truly compress two months of engineering work into a single day, it deserves to be expensive. However, enterprises will first crunch the numbers—model pricing is just the first layer, data retention is the second, and compliance is the third. Fable 5 is classified as a Covered Model, requiring 30-day data retention on the Claude API and not supporting zero data retention (standard data retention policies). For financial, medical, legal, and core R&D teams, this isn't a trivial matter.

(Image source: Anthropic)
Additionally, Fable 5 has another complication: it automatically triggers safety reviews on sensitive topics like cybersecurity and biology. For some questions, it will outright refuse to answer; for others, it will revert to the less capable Opus 4.8. To ordinary users, this might just feel like 'getting rejected mid-question,' but for enterprises, it could become an engineering issue.
This has formed two very interesting factions. DeepSeek, MiMo, and Gemini are proving that powerful models will become increasingly affordable and easier for developers and businesses to deploy on a large scale. Anthropic, on the other hand, is demonstrating that truly top-tier models, those that are truly close to the core of productivity, may actually become more expensive, resembling luxury-grade infrastructure.
But which faction represents the true future? No one can say for sure.
The release of Claude Fable 5 will make many companies uncomfortable. OpenAI will feel the pressure because Anthropic continues to make its presence felt in agent coding and long tasks. Codex already has over 5 million weekly active users, and OpenAI is transforming ChatGPT, Codex, and future AI researchers into work portals. However, the emergence of Fable 5 reminds the market that Claude remains a formidable competitor in complex engineering tasks.
Google will also feel the pinch. Although the Gemini ecosystem boasts strong platform capabilities, with Gemma, NotebookLM, and Gemini Live all striving to improve, Gemini 3.1 Pro has lost in multiple tests according to Anthropic's official benchmark chart. Google's strength lies in its ecosystem and distribution, while Anthropic's advantage lies in the cutting-edge capabilities of its most powerful model.
Domestic models will also be forced to readdress a question: beyond affordability, can they handle the most difficult tasks for users? DeepSeek V4's 1M context, open-source weights, and extremely low price are highly disruptive. Xiaomi MiMo's price cuts will also continue to drive the API market downward. However, the existence of models like Fable 5 will constantly remind the market that while affordable models can cover a large number of tasks, the most difficult 5% or 10% may still be captured by the most expensive models.

(Image source: Anthropic)
The true market significance of Fable 5 is that it won't prompt all businesses to switch models immediately, nor will the value of affordable models disappear. Instead, it pushes large model competition into another dimension. In the future, the market will simultaneously demand two types of models: one is an affordable, stable, and mass-deployable workhorse; the other is an expensive, powerful, guarded, top-tier tool specifically designed to handle high-value tasks.
Anthropic seems to be using Fable 5 to tell the entire industry that it won't participate in every price war but that what it sells is the most valuable part. You have to consider including it in your procurement plans.
To put it bluntly, the stronger the model, the more real the questions become: Who is it sold to? How much should it cost? Who is responsible if something goes wrong? These questions, which seemed distant in the past, have now been laid on the table by Claude Fable 5.
AnthropicDeepSeekXiaomiQianWenClaude
Source: Leikeji
The images in this article are from the 123RF Authentic Library (123RF Royalty-Free Image Library). Source: Leikeji
-
![]()
Revenue Surges 50-Fold: Q1 Earnings Match Annual Profit, This Year's Hottest Business Revealed
-
![]()
Cook’s Gourd Holds No Magic Cure for Apple’s AI Woes
-
![]()
Stellantis Presents a Catalyst, Propelling Chinese Automobiles Towards Global Supremacy
-
![]()
The First AI Car! Seres + ByteDance, AIVA Targets the 200,000+ Market with Its First Vehicle Launching This Year | Mirror Pro
-
![]()
Most People Don't Understand Kimi's World Cup Prediction
-
![]()
Behind Saido: The Strategy of a Company Backed by CATL and ByteDance
-
![]()
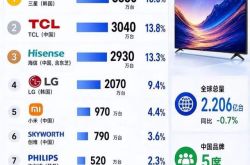
Market Disparity: Domestic OLED TVs Hold Less Than 10% Share, with Two Korean Giants Leading the Pack
-
![]()
Seres Faces Six Months of Declining Sales: Challenges Coexist with Opportunities