Bridging the 'Reality-Virtuality Gap' in VLA: China's Embodied AI Large Models Grow 'New Brains'
 06/15 2026
06/15 2026
 500
500

There Isn't Just One Answer for the Robot's 'Brain'
While most players in the embodied AI industry are rushing towards IPOs, some are focusing on large models instead.
On one hand, companies like Unitree Technology have passed the Sci-Tech Innovation Board IPO, and Zhiyuan is initiating a Hong Kong IPO, accelerating the industry's migration from primary to secondary markets. On the other hand, route competition within the industry is visibly intensifying, shifting from hardware form factors to data sources, and now to the core 'brain' architecture.
At this juncture, two domestic embodied AI companies have nearly simultaneously presented their 'answers.'
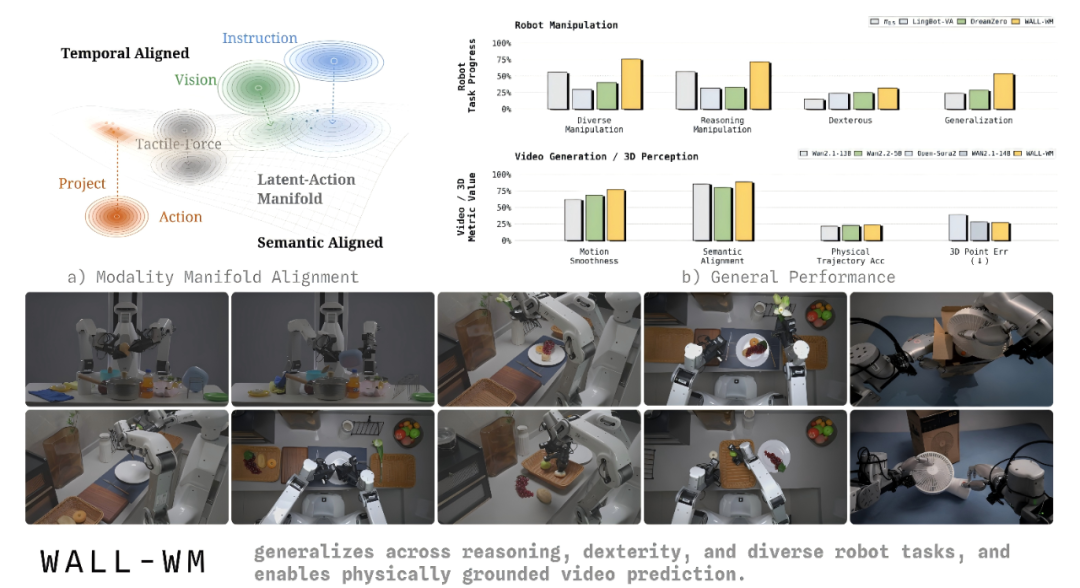
On May 29, Zibianliang Robotics released WALL-WM, the world's first 'event-level prediction' embodied AI world model, disrupting the decades-old 'frame-by-frame learning' paradigm. In early June, Xinghaitu followed with the new-generation embodied foundation model G0.5, leading across seven independent evaluations and outperforming π0.5 and previous champion solutions relying on multiple specialized models on the notoriously difficult long-term task benchmark BEHAVIOR-1K with a single general-purpose strategy model.
Why, amid the industry's prevailing narrative of 'prioritizing hardware over software,' have these two companies chosen this slower, heavier path?
01 Has the 'Ceiling' of Large Models Been Shattered?
Most mainstream embodied AI companies currently adopt the VLA (Vision-Language-Action) technical route. However, the evolutionary ceiling for embodied AI models under the VLA paradigm is clearly visible.
The foremost challenge is the global 'reality-virtuality gap.' In April 2026, Stanford University's 'AI Index Report 2026' revealed a sobering reality: due to the difficulty of fully simulating real-world physical properties in simulated environments, some robots achieved an 89.4% success rate in simulations, which plummeted to 12% in real home scenarios.
Meanwhile, VLA models, reliant on internet-sourced image-text data for training, can recognize objects but struggle to truly understand physical interaction laws like force application and deformation, earning them the industry nickname 'brain in a vat.'
More critically, VLA's fragile generalization capabilities in generalization and autonomy dimensions lead to sharp success rate declines when scenarios change or task chains lengthen. This data-driven 'blind walking' has become an industry bottleneck.
Facing this structural ceiling, Xinghaitu and Zibianliang Robotics have nearly simultaneously provided their answers from two distinct directions.
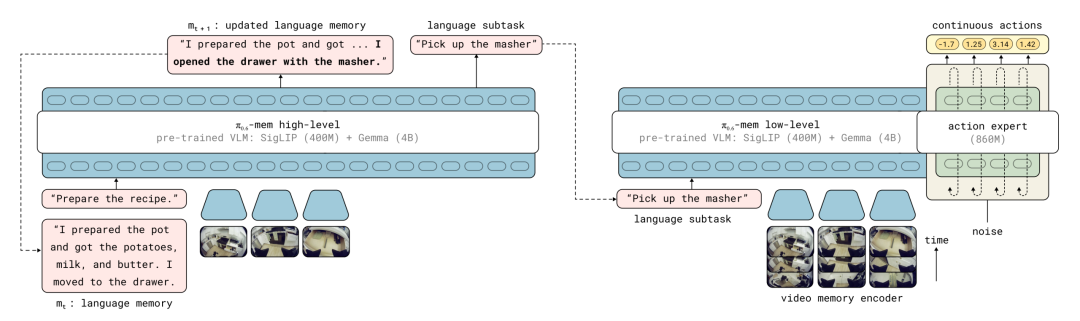
First, Xinghaitu's G0.5 approach can be understood as a radical 'bottom-layer reconstruction' within the VLA architecture.
It breaks free from the traditional VLA path dependency of 'VLM as encoder + independent action expert,' where VLM's hidden states must be compressed before passing to the action module, diluting core reasoning capabilities. G0.5's solution is direct: enabling the same model and weights to synchronously generate reasoning and action tokens in an autoregressive token sequence. Thus, VLM's generative capabilities like chain-of-thought reasoning, in-context learning, and prompt modulation can natively influence action generation without the information-loss-prone compression bottleneck.
Realizing this architecture required significant engineering effort.
G0.5 introduces a cross-embodiment action codec, unifying 18 robot embodiment data types into a 27-dimensional action space and avoiding token waste on static joints through an 'active degrees-of-freedom prediction' mechanism. For example, in dual-arm tasks, this sparse design saves nearly half the token volume.
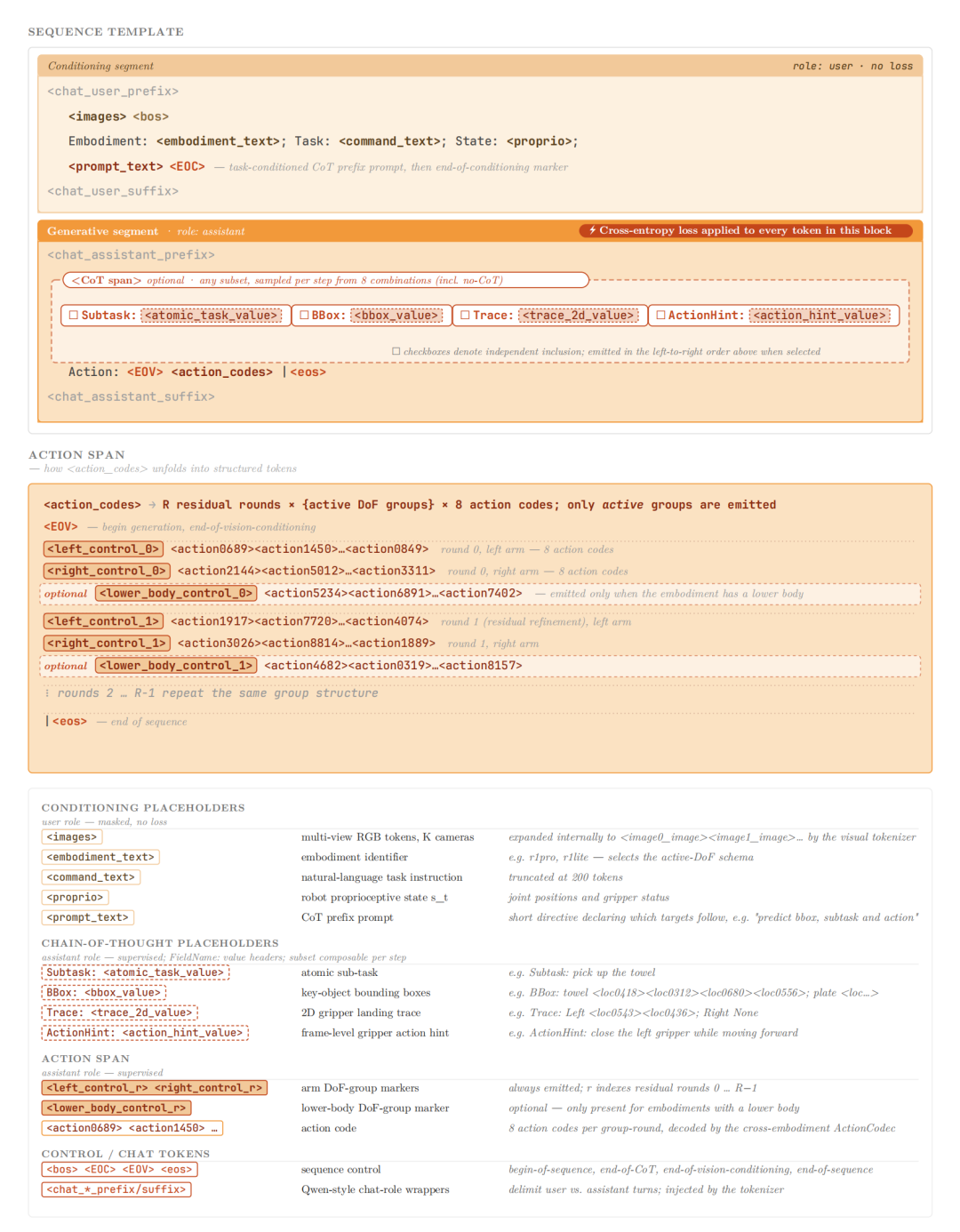
The native chain-of-thought mechanism enables the model to first output reasoning tokens like subtask decompositions and target boxes before generating actions. These reasoning results and action tokens are constrained by the same loss function, truly achieving 'thinking while acting.'
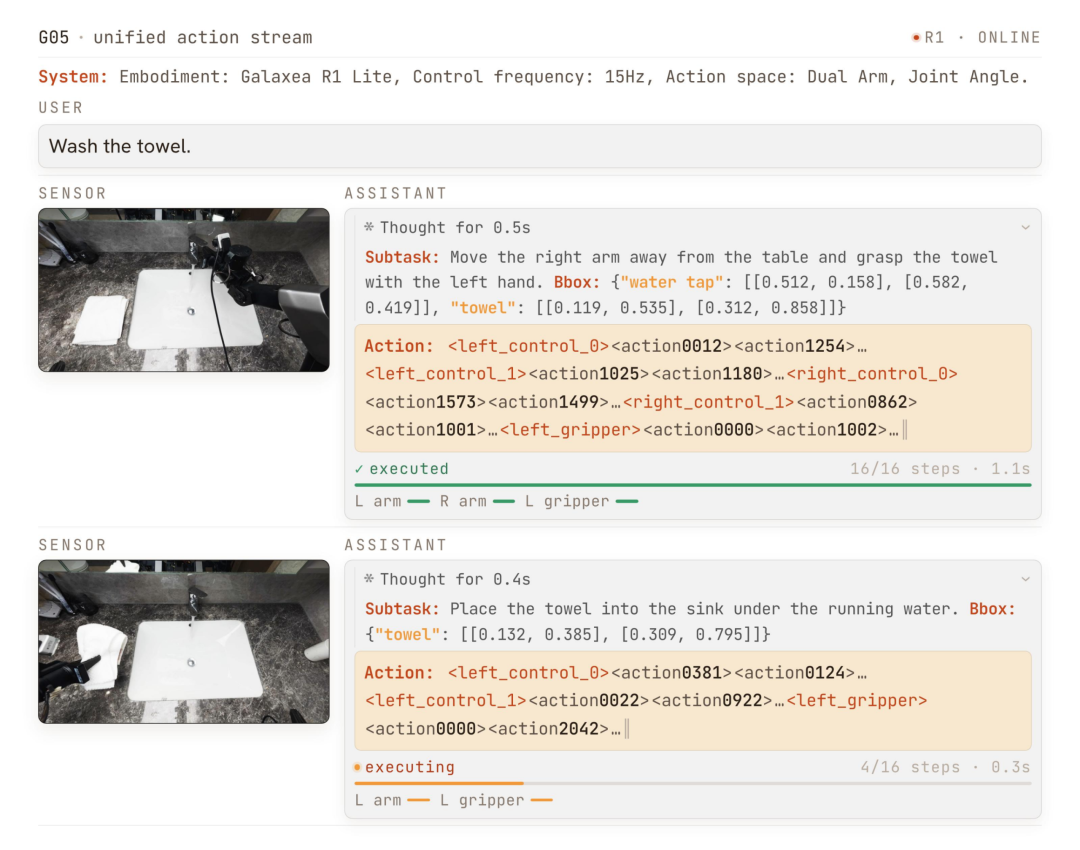
Additionally, the spatiotemporal attention module incorporates historical visual information into current decisions through decomposed spatiotemporal attention mechanisms, particularly suited for long-term tasks requiring repeated spatial traversal.
Quantitative data further illustrates the point.
On the DROID real-robot dataset's 10 desktop tasks, G0.5 achieved an 82.5% average success rate without any fine-tuning, a 25-percentage-point improvement over the previous model. It scored 87.3% in the SimplerEnv-Bridge cross-dataset transfer test, surpassing all comparison models, and achieved a 93.3% average score in the RoboTwin 2.0 dual-arm coordination test...
The most intuitive (intuitive) validation came from BEHAVIOR-1K, featuring 50 complete home-scenario long-term tasks with an average demonstration duration of 6.6 minutes. G0.5 surpassed the previous model's four-cycle training performance with just one epoch of training using a single pre-trained model, achieving a 0.2904 task success rate and outperforming the champion solution using four model ensembles.
If G0.5 represents a 'radical internal reconstruction' of VLA, then Zibianliang Robotics' WALL-WM, the world's first 'event-level prediction' embodied AI world model, represents a complete paradigm shift. It abandons the VLA path entirely, rethinking robot action learning from a 'world model' perspective.
Traditional VLA approaches slice robot actions into fixed-length 'frame chunks' for learning: predicting hand positions at 0.1s, 0.2s, etc., breaking a cup-grasping action into dozens of nearly identical frames for rote memorization by the model.
The result is that the model memorizes 'finger movements per frame' rather than the goal of 'grasping the cup.' Any change in table or rhythm immediately causes failure.
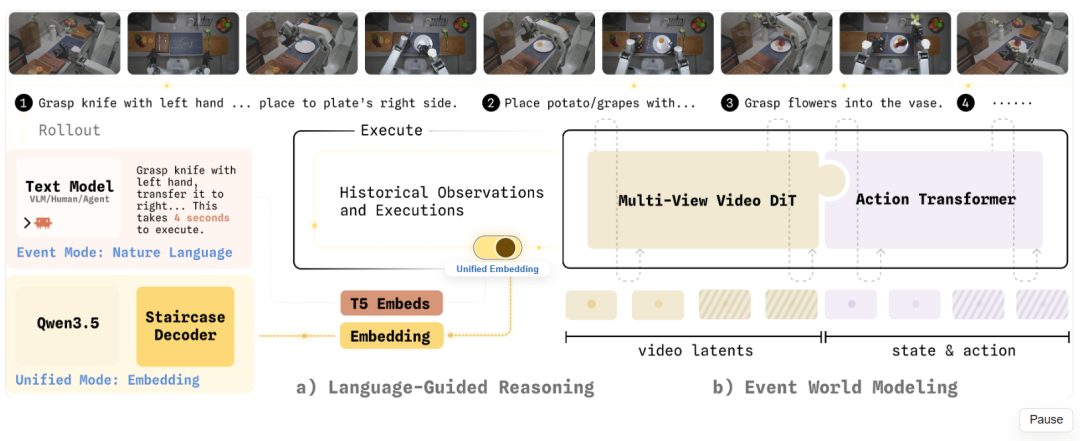
To achieve this key breakthrough, the Zibianliang team noted in their paper that text, vision, and action information have distinct manifold geometries and time scales in high-dimensional space, making 'complete alignment' inherently unrealistic.
Text represents low-entropy discrete semantics, vision high-dimensional continuous scene dynamics, and action is strongly constrained by the physical world. The three neither share spatial neighborhoods nor time scales. Forcing them into a shared space only results in pre-training priors being overwritten by action shortcuts, explaining why many VLA models perform well in simulations but poorly in real-world deployments.
WALL-WM's solution is thus 'counterintuitive.' It shifts the prediction unit from time frames to semantic events—reaching, grasping, lifting, moving, placing—these physically meaningful behavioral segments are what robots truly need to learn. The model no longer asks 'what will it look like in 0.1s?' but directly imagines 'what will it look like when grasping the cup?' and generates actions to reach that state simultaneously.
Specifically, WALL-WM doesn't directly generate actions from visual frames but first lets the model understand 'how the world will change in the next event,' then translates this change into the robot's executable trajectory. This represents a complete pathway reconstruction from perception to control: the event instruction entrance (entry point) tells the model 'what to do next'; the event world model previews 'how the world will change in the next event'; the action generation layer translates this change into the robot's executable trajectory.
Overall, G0.5 and WALL-WM have torn open cracks in the VLA route's approaching ceiling from 'architectural internal reconstruction' and 'world model paradigm shift' directions, respectively, demonstrating for the first time that a robot's 'brain' need not have a single answer.
02 What Soil Nurtured These Two 'Brains'?
Technological breakthroughs never occur in a vacuum.
Behind G0.5 and WALL-WM lie the long-term determination of two companies in technical route selection, data strategy, and capital deployment. The most significant (prominent) commonality is their adherence to a 'brain-first' strategy.
Xinghaitu founder Gao Jiyang hails from Waymo and Momenta's autonomous driving mass production R&D frontlines, with his founding team combining Tsinghua academic backgrounds and first-line engineering combat experience. While the industry generally follows a 'hardware-first' logic, Xinghaitu takes the opposite approach—investing heavily in large model pre-training architecture design and continuously feeding G-series model iterations with real deployment data from factories and commercial venues.

Zibianliang takes an even purer approach, establishing a 'unified end-to-end large model for brain and cerebellum' technical route from inception. They argue that the 'brain' is not a downstream application of AI models but a physical world foundation model parallel to language large models.

However, while both companies bet on the 'brain-first' route—a heavier yet more authentic path—they emphasize different aspects in their approaches.
Xinghaitu pursues a 'complete machine + intelligence' software-hardware integration strategy, with a product matrix covering wheeled dual-arm robots (R1 series), bipedal humanoids (Kengo), and multiple embodiment hardware variants, while providing a complete post-training toolchain including pre-trained models, data collection, evaluation, fine-tuning, and deployment. By 2026, the company had secured thousand-unit orders from domestic leading automakers and smart logistics enterprises.

Moreover, Xinghaitu has not confined its technical route to a single VLA framework. As early as March 2026, the team released world model research results Fast-WAM, abandoning the traditional inefficient 'imagine-then-execute' paradigm. Through deep reconstruction of the model's underlying logic, it compressed single-step reasoning latency to 190 milliseconds, achieving a 4x speedup while maintaining SOTA performance, paving the way for scalable industrial deployment of embodied AI.
Zibianliang also practices software-hardware integration but emphasizes the 'model-driven hardware' underlying logic. The company has released two robot embodiments ('Quantum I' and 'Quantum II') and achieved full self-research of core components like robotic arms, joint modules, and power drivers. Founder Wang Qian also proposes that the core competition in embodied AI lies in data closed loop (loop) construction and model evolutionary capabilities.

At this juncture, on June 9, Zhiyuan (AGIBOT) also launched the industry's first open and complete embodied AI ecosystem technology framework—AIMA (AI Machine Architecture)—officially initiating the 'Yuansheng' ecosystem development plan with a 2 billion yuan special project (special) fund commitment over the next five years. This further signals the industry's shift from 'embodiment' to 'robot brain' competition.
Whether G0.5, WALL-WM, or Zhiyuan's AIMA ecosystem at this moment, their emergence is no accident but the inevitable result of technical route, data strategy, and capital deployment synergies. As capital cools and the divide between data barriers and model architectures becomes clearer, the industry may be reaching a consensus: the true moat lies not in joint flexibility or mass production scale but deep within the code.
* Image sourced from the internet. Contact for removal if infringement occurs.
-
![]()
In-depth | Survival Transformation of 38 Million Freight Drivers: How Platformization Defines the Next Decade?
-
![]()
Why Have ‘Computing Power Rental’ Companies Emerged as the Biggest Winners in the AI Era Amid Soaring Chip Prices?
-
![]()
DeepSeek's Financing Details Revealed! How Liang Wenfeng Secured Control
-
![]()
Valued at 210 Billion Yuan, Generating 42 Billion Yuan in Annual Revenue, Xiaohongshu May Proceed with IPO
-
![]()
Three Straight Months of Growth in Heavy Truck Sales: Both New and Veteran Players Are on the Same Wavelength!
-
![]()
AI Rewrites the Logic of Going Global: Cross-border E-commerce Reaches a New Turning Point
-
![]()
DeepSeek Secures Over 50 Billion Yuan in Initial Funding Round: Tencent and CATL Among Investors
-
![]()
Trillionaire Musk