Why Are Convolutional Neural Networks and Transformer Architectures Unfit for Embodied AI?
 06/16 2026
06/16 2026
 466
466
If you grab your phone right now and ask a large language model, "What happens if I push a glass cup to the edge of a table?" it will likely respond that the cup will fall and shatter.
This answer may seem insightful, but the reality is—it doesn't truly understand why the cup falls. The model has simply encountered the words "cup," "fall," and "shatter" together too frequently in its training data and, based on probability, provides the most likely response. This type of "intelligent guesswork" functions well in the textual realm, but it becomes problematic when we attempt to deploy AI in robots that need to handle dishes, fold clothes, or navigate stairs.

Over the past few years, Convolutional Neural Networks (CNNs) and Transformer architectures have been the stars of the AI field. CNNs excel in computer vision, while Transformers have propelled language models to unprecedented heights. Together, they have largely shaped the technical landscape of contemporary AI. However, when the focus shifts from screens to the real world—when AI must step out of digital sandboxes and engage authentically in physical environments—a troubling question arises: Are these two architectures, which we rely on so heavily, fundamentally unsuited for "embodied AI"?
01. Eyes Can See, but Don’t Understand Objects
Let’s begin with CNNs. Designed to emulate the human visual system, CNNs use a series of learnable filters to scan images, extract features like edges, textures, and shapes, and then abstract these layer by layer until classification or recognition is achieved. This mechanism has outperformed humans on tasks like ImageNet and become the default approach for many visual tasks. However, the issue lies in its design philosophy—CNNs essentially learn "statistical associations between pixels and labels" rather than understanding "what objects are composed of."
Consider an intuitive example. Imagine a child sees a car partially obscured by a few potted plants. Even if they’ve never encountered this exact occlusion pattern before, they can effortlessly identify it as a car. Why? Because they possess a cognitive framework: "A car is made up of wheels, a body, windows, and other components." Even if one component is blocked, they can use clues from the others to complete the judgment. Standard CNNs, however, lack this ability.
Their judgments rely on overall pixel patterns. If the occlusion pattern changes slightly—for example, if the lights are blocked instead of the body—the carefully trained convolutional kernels become confused. Research indicates that traditional "black-box" deep CNNs perform unstably when dealing with partial occlusions. It wasn’t until researchers introduced more structured "object-part composition" methods, representing objects as a set of spatially combinable parts, that recognition robustness under occlusion significantly improved.
This issue becomes even more critical in the context of embodied AI. As robots navigate, they constantly encounter stacked boxes, intersecting pipes, half-open doors—all dynamic, partially occluded real-world scenes. If they rely solely on CNN-output "pixel features" for decision-making, lacking an intrinsic understanding of object composition, then a slight turn or change in lighting could render previously "recognized" objects unrecognizable.
That’s not the worst part. More troubling is CNNs’ strong bias toward textures—they tend to classify based on surface textures rather than object shapes. It’s akin to judging whether something is a cat not by examining the overall structure of ears, pupils, and whiskers but by fur color alone—mistaking any similarly colored animal for a cat and failing to recognize it when the fur changes. This bias is fatal in the unpredictable physical world.
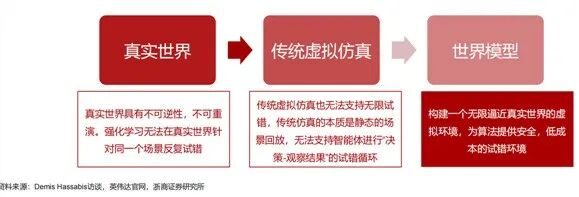
02. Statistical Correlation ≠ Causal Reasoning
If CNNs’ blind spot is "seeing without understanding," then Transformers’ problem is even more fundamental—they are not designed to understand causality.
The Transformer’s core strength is the self-attention mechanism, which captures dependencies between any two positions in a sequence simultaneously. This is incredibly powerful for language models—a word can relate to another thousands of words away, crucial for understanding semantics and generating coherent text. But note that "attention" only computes "statistical correlations." In training data, "thunder" and "rain" often appear together, so their attention weights are high, but the model doesn’t know whether thunder causes rain or if some other factor is at play. In short: Transformers are top-tier "pattern recognizers" but will never be "causal reasoners."
Embodied AI doesn’t need this kind of rote-learning "straight-A student." A robot moving parts in a factory must understand basic mechanics: when it pushes a box, the box’s speed and direction depend on the force applied, friction coefficient, and box mass. If the model hasn’t internalized these physical causes and effects but merely makes decisions based on statistical associations between visual inputs and actions, then even slight environmental changes—like a dry floor becoming wet or parts changing from metal to plastic—can render the entire strategy useless. Researchers have noted that current embodied large models are essentially "memorizing trajectories" rather than "understanding logic." They rely solely on mappings between visual inputs and actions, and any minor environmental change can cause complete failure.
In an interview, Turing Award winner Professor Yao Qizhi directly highlighted the issue: one of the biggest technical bottlenecks in today’s embodied intelligence is that these systems only imitate human behavior without explainable world models or physical causal reasoning. Moving from "imitation" to "reasoning" is precisely a threshold the existing Transformer architecture struggles to cross because its underlying logic is about predicting the next token, not deductive logic or causal inference.
03. Data Deserts and Energy Black Holes
Even if we temporarily overlook the fundamental architectural limitations and examine engineering realities, CNNs and Transformers are already struggling in embodied AI. Data is the first insurmountable hurdle.
Large language models succeed because the internet is an inexhaustible data mine—Wikipedia, news, forums, papers, code repositories—all ready-made, organized, and labeled textual data. Training a GPT-4-level model costs hundreds of millions of dollars, but the money can be spent because the data exists.
What about embodied AI? Robots need data from every real-world interaction: every grasp, every step, every push and pull—behind each frame of data lies a real physical action and corresponding multimodal sensory feedback. Such data is extremely difficult to collect at scale: a single high-quality data point from a teleoperation device can cost 3–5 RMB per year of use, and the entire industry has aggregated only about 500,000 hours of high-quality embodied data—less than one ten-thousandth of the data used to train large language models. A general-purpose embodied model requires at least tens of millions of hours of data support—when you lay out this gap, the severity of the problem becomes clear.
Even if the data problem were solved, computational costs remain a concern. The Transformer’s attention mechanism has a well-known weakness: its computational complexity scales quadratically with sequence length. In language models, this "O(n²)" complexity is already troublesome, but in embodied AI scenarios, sensor streams are continuous, high-frequency, and multimodal—visual, tactile, inertial measurement units, joint angles—data floods in constantly. Running a Transformer model with billions of parameters on a robot to process this multidimensional temporal data would drive power consumption and latency to unacceptable levels. Research points out that under global attention, every token must compute with all others, leading to quadratic complexity growth, while even the most basic neighboring relationships in CNNs require massive redundant computations in Transformers.
04. Rethink, Don’t Blindly Follow
Of course, saying CNNs and Transformers are unsuitable for embodied AI doesn’t mean these architectures have no role in the field. CNNs can be used for multimodal feature extraction in perception, and Transformers can handle high-level task planning and semantic understanding. The issue is that we cannot place "understanding physical causality"—a completely mismatched expectation—on architectures designed for discrete sequences or static images.
Embodied AI needs models that inherently embed physical laws—models that naturally understand continuity, conservation laws, and causal chains rather than relying on massive data to brute-force fit surface features of these laws. It needs efficient temporal reasoning capabilities to perform real-time closed-loop control with limited computational resources. It must evolve from "mimicking human actions" to "understanding physical logic"—learning to "think before acting" and improving generalization by modeling causal relationships.
A control theory scholar at Cambridge University once offered a thought-provoking metaphor: Using Transformers to learn physical laws is like playing a violin sonata on a piano—the sound may be close, but the complex physical couplings between bow and string can never be reproduced.
- End -
-
![]()
What is the Future for Domestic Large-Scale AI Models?
-
![]()
Insights into China's Gimbal Camera Market Structure, Player Dynamics, and Development Trends in 2026
-
![]()
Massive Capital Influx! NVIDIA's $25 Billion Bond Issuance Secures $85 Billion in Oversubscribed Demand, How Will the AI Chip Giant Secure Long-Term Liquidity?
-
![]()
Has DJI Caught Up with Insta360?
-
![]()
The Hidden Update of visionOS 27 is Incredible: Uncovering the Major Upgrades Apple Didn't Mention
-
![]()
Volunteer Application Agent: Tencent is Restrained, Alibaba is Aggressive
-
![]()
A Glimmer of Innovation Dances on the Tightrope
-
![]()
The AI Glasses Track is Fully Taking Off: How Far Are We from Them Being 'Must-Haves'?