How Transformer Empowers Vehicles: From Clear Object Recognition to Comprehensive Environmental Understanding
 06/22 2026
06/22 2026
 510
510
In the rapidly evolving landscape of autonomous driving technology, the Transformer architecture, originally renowned for its prowess in natural language processing, has increasingly become the cornerstone of intelligent vehicle perception and decision-making. A retrospective glance at recent technological advancements reveals that both Tesla's FSD and the intelligent driving solutions developed by domestic new automotive forces are converging towards this innovative architecture. The integration of Transformer has propelled vehicles beyond mere clear object recognition, ushering them into a new era of environmental comprehension.
Why Traditional Visual Recognition Falls Short
Prior to the widespread adoption of Transformer, visual recognition in autonomous driving predominantly relied on Convolutional Neural Networks (CNNs). CNNs excel at extracting local features; for instance, through layer-by-layer filtering, they can discern edges and shapes within images, ultimately assembling a vehicle or pedestrian. While this method proves highly efficient for static, single-object recognition, it exposes its limitations when confronted with complex traffic scenarios.
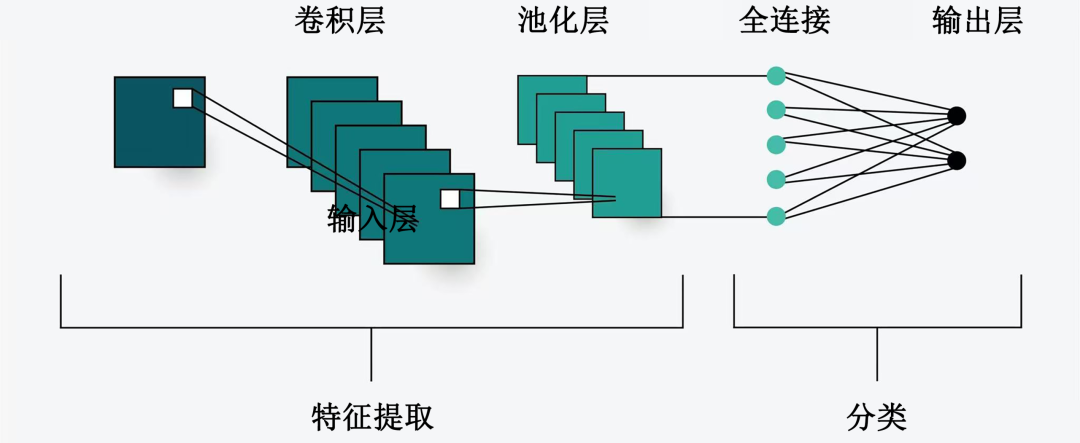
Image Source: Internet
Autonomous driving is intricately linked to the road environment. When driving, a driver's gaze is not solely fixed on the vehicle directly ahead; rather, they subconsciously monitor overtaking intentions in the left rearview mirror while also paying attention to pedestrians at the right front intersection. Traditional CNNs resemble individuals scrutinizing a painting with a magnifying glass; although they can discern details clearly, they struggle to grasp the overall artistic conception (meaning or essence) of the painting at a glance. They are inadequate in handling long-distance, global spatial relationships and sometimes necessitate stacking very deep layers to establish connections between disparate objects.
As the number of sensors proliferates, vehicles must simultaneously process images from multiple cameras and convert these two-dimensional images into three-dimensional spatial coordinates. In this process, ensuring that features from different image perspectives fit together seamlessly, akin to a puzzle, becomes crucial for technological breakthroughs—a feat at which Transformer excels.
How the Attention Mechanism Interprets the Road
The crux of Transformer lies in its attention mechanism. If we liken the sensor inputs of autonomous driving to a massive data stream, the attention mechanism acts as a filter. It no longer rigidly allocates computational power evenly across all pixels but can autonomously discern which information is more critical. For instance, on a highway, the algorithm will focus more on the speeds of vehicles in adjacent lanes and distant road signs, while assigning minimal weight to roadside grass or clouds in the sky.

Image Source: Internet
This mechanism transcends physical spatial constraints. From Transformer's perspective, every pixel point in an image can directly "communicate" with any other pixel point. This means that the front of a vehicle captured by the left camera and the rear captured by the right camera can instantaneously establish a connection within the algorithm, enabling the system to recognize that it is a long trailer crossing the road. The establishment of this global perspective facilitates the vehicle's environmental modeling to transition from fragmentation to holistic integration.
Moreover, Transformer is not solely concerned with spatial connections; it also excels at processing temporal sequence information. Road environments are in a constant state of flux; an action by a pedestrian or a turn signal from a vehicle contains clues for predicting the future. By inputting continuous time sequences into the architecture, Transformer can comprehend the evolution trend of traffic flow, much like understanding the context of a sentence. This unified processing of spatiotemporal information significantly enhances the judgment accuracy of intelligent driving systems in complex, interactive environments.
How Multiple Sensors "Collaborate" in the Same Space
One of the most formidable challenges in autonomous driving is fusing data from cameras, LiDAR, and millimeter-wave radars. Traditionally, each sensor performed its function independently, with results aggregated afterward. However, this post-fusion method often results in the loss of original data details. The advent of Transformer has catalyzed the maturity of BEV (Bird's-Eye View) technology, providing a unified mathematical framework that enables deep interaction among various sensor data at the fundamental level.

Image Source: Internet
Through positional encoding technology, Transformer can map camera images from different perspectives into a unified three-dimensional coordinate system. Imagine an omniscient perspective above the vehicle, where all image information is stretched and projected onto a planar map in real-time. During this process, the attention mechanism automatically fills in occluded areas, utilizing surrounding contextual information to infer potential risks in blind spots.
This fusion method not only resolves spatial misalignment issues but also significantly enhances the system's ability to recognize irregular obstacles. At complex urban intersections, while traditional rule-based algorithms are still deliberating over an object's classification, Transformer-based Occupancy Networks can directly provide information on the volume occupation of objects in space. This approach, which prioritizes avoidance over classification, represents a qualitative leap in the safety of intelligent driving systems.

The Evolution from Perception to Decision-Making: How Far Have We Come?
Today, the application of Transformer is no longer confined to the perception end; it is evolving towards an end-to-end full-stack architecture. In early intelligent driving architectures, perception, prediction, and planning were relatively independent modules connected by extensive code logic. Although this approach was manageable, it could lead to system paralysis in extreme operating conditions due to incomplete rule coverage.

Image Source: Internet
The end-to-end architecture seeks to emulate the processing mode of the human brain, allowing Transformer to directly learn the mapping from raw sensor inputs to final driving instructions (such as steering angle and acceleration intensity). In this architecture, the system no longer requires cumbersome intermediate layers; instead, it acquires driving habits akin to those of human drivers through training on massive amounts of exemplary driving data. It can not only comprehend the road but also understand complex social rules and unwritten norms.
Of course, this evolution does not occur overnight. Currently, the industry grapples with challenges in balancing the computational consumption of large models with the performance of onboard chips, as well as ensuring the decision-making transparency of deep learning models. However, it is undeniable that Transformer has fundamentally reshaped the technological foundation of autonomous driving. It has transformed the car from a mere machine executing instructions into an intelligent entity capable of understanding and continuously evolving through learning. In the future, as algorithmic efficiency further improves, this architecture will continue to revolutionize our mode of travel.
-- END --
-
![]()
Dreame Technology Implements Major Strategic Retrenchment Amid Controversy: Retains Four Core Sectors, Continues Pursuit of Car Manufacturing
-
![]()
AI Phones Haven't Gone Mainstream Yet, and Now Agent Phones Are Taking Off? A Deep Dive into the AI Strategies of Eight Mobile Giants
-
![]()
AI Smartphones Haven't Gone Mainstream Yet, But Agent Smartphones Are Already Taking Off? Breaking Down the AI Strategies of Eight Smartphone Giants
-
![]()
Mega Review of 2026 Mid-Range Smartphones: Post Price Hikes, Which Model Reigns Supreme Among vivo, OPPO, Honor, and Xiaomi in the 3000 Yuan Bracket?
-
![]()
Without the Support of These Companies, SpaceX Would Struggle to Launch Rockets!
-
![]()
Enflame Technology Clears IPO Hurdle: A Daring Venture into CUDA-Incompatible Realm
-
![]()
Significant Shifts in Home Appliance Market Trends During This Year’s 618 Shopping Festival
-
![]()
Insta360 Fights Back! Standing Up to Black PR Operations", "Insta360 Innovation, Black PR Operations, Patent Litigation, Market Competition, Financial Performance", "Insta360 Innovation, targeted by b