Why are top intelligent driving players betting on reinforcement learning?
 07/02 2026
07/02 2026
 372
372
Recently, when some intelligent driving players have released large models, especially world models, one technology frequently appears alongside them—reinforcement learning. Horizon Robotics' HSD V2.0, released on June 29, features core upgrades centered around a dual technological foundation of world models and end-to-end reinforcement learning. Momenta announced at the Beijing Auto Show in April that its R7 reinforcement learning world model would be the first to enter mass production. Pony.ai released PonyWorld 2.0 in April, emphasizing that its core transformation lies in the AI's ability for self-diagnosis and directed evolution. NIO will push the world model + closed-loop reinforcement learning architecture to hundreds of thousands of vehicles in January 2026. QCraft has also introduced a solution based on a unified architecture of world models and reinforcement learning.
Reinforcement learning always seems to appear alongside world models. Why are top intelligent driving players betting on reinforcement learning?
What is the limit of imitation learning?
In the past few years, the mainstream training method for autonomous driving models has been imitation learning, where AI observes massive amounts of human driving data to learn how humans operate in specific scenarios. Under the framework of imitation learning, end-to-end autonomous driving systems have gradually become the mainstream architecture, integrating originally independent modules such as perception, prediction, and planning into a unified neural network that directly learns driving strategies from sensor inputs. This combination has made significant progress in the past few years, but its limitations are also evident.
The essence of imitation learning is to replicate existing human driving behaviors. What AI can learn will not exceed the range of what human drivers have done. This means the system struggles to handle extreme scenarios that human drivers rarely encounter, such as a tire suddenly rolling out in front, or a non-motorized vehicle suddenly appearing under nighttime backlight conditions. Models trained through imitation learning find it difficult to handle such scenarios well. Additionally, these scenarios occur very infrequently on real roads, making data collection extremely costly, yet they represent the most critical parts to overcome for autonomous driving safety.

Image source: Internet
The more critical issue is that imitation learning only allows AI to learn to drive like humans, but not to drive better than humans. Moreover, the real driving data used to train large models includes both good driving behaviors and a large amount of suboptimal ones. If the training goal is merely to imitate, the system will learn human flaws along the way.
The introduction of reinforcement learning is precisely to break through these limitations.
How does the training logic of reinforcement learning differ?
The training logic of reinforcement learning is entirely different from that of imitation learning. It does not require AI to imitate anyone but instead sets a goal for AI, such as completing driving tasks safely and efficiently, and then allows AI to try, receive feedback, and gradually optimize its behavior in an environment.
Reinforcement learning in autonomous driving mainly adopts a deep reinforcement learning framework, combining deep neural networks with reinforcement learning. In terms of algorithms, since autonomous driving involves continuous action spaces (steering wheel angle, throttle, braking, etc.) and high-dimensional state inputs (multi-sensor data), commonly used algorithms include Deep Deterministic Policy Gradient (DDPG), Soft Actor-Critic (SAC), and Proximal Policy Optimization (PPO). Among them, PPO has gained widespread application in the industry due to its training stability and relatively high sample efficiency.

Image source: Internet
The core mechanism of reinforcement learning is a continuous cycle of trial and error. At each moment, the agent perceives the environmental state and makes action decisions accordingly. The environment provides a reward signal, and the agent adjusts its subsequent decisions based on this signal, repeating the process to ultimately dynamically optimize to an optimal driving strategy. This process involves several key design elements.
The state space is the collection of environmental information that the agent can perceive. In autonomous driving scenarios, it includes the vehicle's own state (speed, acceleration, heading angle, etc.), the positions and motion trajectories of surrounding vehicles and pedestrians, and road structure information such as lane lines and traffic lights. The action space consists of the control instructions the agent can execute. In continuous control scenarios, it generally includes three-dimensional outputs: steering wheel angle, throttle opening, and brake pressure.
Among all design elements, the reward function is the most critical. It directly defines which behaviors are encouraged and which should be avoided, effectively setting the learning goal for AI. The reward function for autonomous driving needs to balance three conflicting indicators simultaneously: safety (avoiding collisions), efficiency (shortening travel time), and comfort (reducing abrupt acceleration and braking). Various design schemes have been proposed in related research, such as safety metrics based on two-dimensional time-to-collision paired with segmented rewards, or unifying multiple objectives into a comprehensive function.
The policy network is the deep neural network that carries the final decisions. It receives state inputs and outputs specific action instructions. The update of network parameters is based on the total reward accumulated by the agent during interaction—the higher the reward, the better the current strategy, and the network adjusts in that direction. Through repeated interactions with the environment, the policy network gradually and dynamically optimizes to an optimal driving strategy that maximizes cumulative rewards.

Image source: Internet
This logic has been validated in the gaming field. For example, AlphaGo playing Go and OpenAI playing Dota both used reinforcement learning to let AI play against itself, ultimately surpassing top human players. What the autonomous driving industry is doing now is essentially applying the same approach to the physical world.
However, there is a fundamental difference between autonomous driving and Go. The rules of Go are fixed, and the changes in the board after a move can be precisely calculated. In contrast, real roads have no fixed rules, and the behaviors of other vehicles and pedestrians cannot be precisely modeled. This leads to a key prerequisite for the implementation of reinforcement learning in autonomous driving: a sufficiently realistic training ground—the world model, which is repeatedly mentioned in the industry.
Why are world models and reinforcement learning always mentioned together?
The role of world models is to compress the laws of the physical world into a computable model, enabling the system to predict future states. More specifically, a world model is not just a simple simulator; it must accurately simulate physical interactions between objects, such as what happens when a vehicle hits a guardrail, the reaction time window of the vehicle behind when the one in front brakes suddenly, or the impact of wet road surfaces on braking distance in the rain. These are all parameters that need to be considered in a world model.
Only when the accuracy of the world model is sufficiently high can reinforcement learning achieve positive training results in this environment. If the world model itself is inaccurate, the strategies learned by AI in the virtual environment may completely fail on real roads.

Image source: Internet
Momenta's solution breaks down this process into three levels. The first level is world model pre-training, where physical laws, common sense, and causal relationships are compressed into the model through pre-training with massive amounts of real driving data, enabling the system to form a basic understanding of the physical world. The second level is world model simulation, where the world model is used for closed-loop simulation of autonomous driving, allowing the system to deduce how the world will evolve when its own behavior changes, and to evaluate performance in long-tail scenarios based on efficient scenario deduction capabilities. The third level is reinforcement learning within the world model, where, based on the first two levels, a highly realistic virtual training ground is constructed for reinforcement learning, allowing the system to repeatedly explore and make mistakes in an environment close to reality.
The value of world models for reinforcement learning can be summarized in two points.
The first is scale. Collecting data for an extreme scenario on real roads might require driving hundreds of thousands of kilometers, but in a world model, such scenarios can be generated on demand. Intersections with mixed non-motorized vehicles and pedestrians under backlight conditions, suddenly appearing electric bicycles, or occluded children can be quickly simulated in a world model.
Pony.ai's PonyWorld 2.0 takes this a step further. Its system can automatically identify specific scenarios where the world model's accuracy is insufficient and actively generate targeted data collection tasks. For example, the system can automatically push instructions to the team, requesting them to focus on collecting data for mixed non-motorized vehicle and pedestrian scenarios under backlight conditions at specific intersections during certain time periods. This means AI can guide human teams on where to collect what data, significantly improving training efficiency. At the same time, PonyWorld 2.0 can also automatically generate targeted training scenarios in the world model based on the weak points of the vehicle-end model, greatly reducing the storage and computational overhead of ineffective training data.

Image source: Internet
The second is safety. The essence of reinforcement learning is trial and error—AI needs to try different behaviors, observe the results, and then adjust its strategy. If this process were conducted on real roads, the cost would be very high. World models provide a zero-cost trial-and-error space where AI can repeatedly try, make mistakes, and learn without causing any actual damage.
From a technical implementation perspective, there are multiple specific paths for combining world models and reinforcement learning. Horizon Robotics' HSD V2.0 adopts a one-stage end-to-end + world model + reinforcement learning architecture. Momenta's R7 solution is also based on a three-layer closed loop of world model pre-training + simulation + reinforcement learning.
Of course, academia is also exploring new combination methods. For example, the WorldRFT framework combines latent world model planning with reinforcement learning fine-tuning, guiding representation optimization through hierarchical planning task decomposition. The DIVER framework combines diffusion models with reinforcement learning, using Group Relative Policy Optimization to guide the diffusion process and directly alleviating mode collapse issues while enhancing collision avoidance capabilities by optimizing trajectory-level diversity and safety rewards.

What challenges lie ahead in transitioning from technical validation to large-scale deployment?
If 2024 to 2025 represents the deployment competition for end-to-end architectures from 0 to 1, then the second half after 2026 will test the depth of understanding and continuous iteration capabilities of the end-to-end paradigm. The role of reinforcement learning in this stage is essentially to provide a mechanism for continuous evolution. Intelligent driving systems will no longer rely on engineers to continuously label data and adjust rules but can autonomously iterate in the virtual environment provided by world models.
From the perspective of actual industry development, the evolution direction of autonomous driving large models in 2026 will involve competition and deep integration of multiple technological routes. Currently, there are two mainstream integration modes. One is the one-stage end-to-end + world model + reinforcement learning, represented by companies such as WeRide, Bosch, and Momenta. The other is end-to-end + foundation models (VLM/VLA) + reinforcement learning + world models, with XPENG as a representative of this mode. The difference between the two modes lies in whether VLM/VLA exists as an independent module, but the core architecture in both cases cannot do without world models and reinforcement learning.
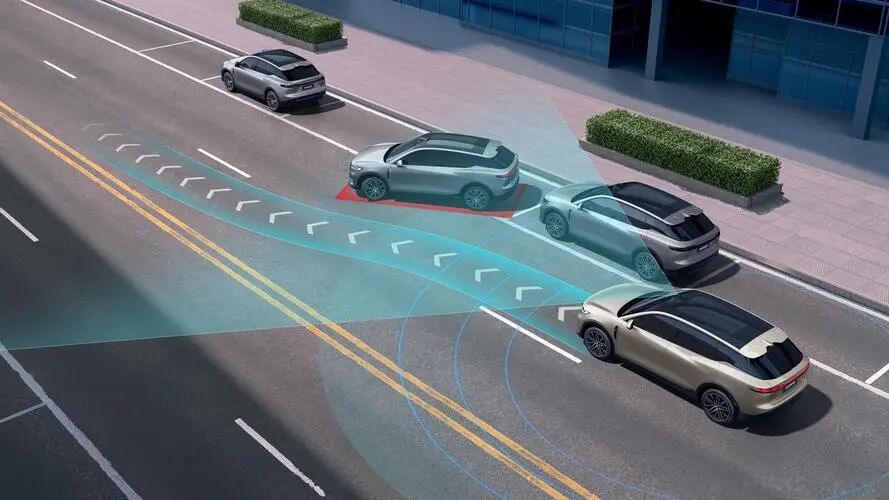
Image source: Internet
Of course, the application of reinforcement learning in autonomous driving also faces many challenges. The generalization ability of world models in complex long-tail scenarios still requires large-scale road testing for verification. The interpretability issue of end-to-end reinforcement learning solutions has not been fundamentally resolved—when the system makes a decision, it is difficult to trace the specific reasons behind it. Additionally, reinforcement learning has much higher requirements for computing power and training data volume than traditional methods, meaning not all companies have the capability to follow this technological route.
Nevertheless, the fact that multiple leading companies are simultaneously pushing reinforcement learning solutions toward mass production in 2026 already indicates that this technology is no longer just a concept but is becoming a standard component in the training of autonomous driving models. It addresses the issue of enabling AI not only to perform well in known scenarios but also to make correct judgments in never-before-seen scenarios. As world models begin to participate in real-road decision-making, the evolutionary logic of intelligent driving systems is being redefined.
-- THE END --
-
![]()
Behind the Release of Its First Self-Developed Chip, Is OpenAI's Full-Stack Ambition on Display?
-
![]()
Has Anthropic Targeted Chinese Users? Is a New Era of AI-Driven Racial Discrimination Emerging?
-
![]()
MathWorks: Generative AI Holds Great Potential, Yet a Trusted Toolchain is Essential for Flawless Operation
-
![]()
Small Earphones, Big Business
-
![]()
Volkswagen Slashes 100,000 Jobs, Mercedes-Benz Axes Year-End Bonuses: What’s Ailing German Auto Titans?
-
![]()
Doubao Can No Longer Offer Free Services to 345 Million Users: China's Era of Free AI Is Drawing to a Close
-
![]()
How Can Chinese Small Home Appliances Conquer Southeast Asia Through 'Dimensional Competition'?
-
![]()
Why are top intelligent driving players betting on reinforcement learning?