Global Agents Embrace 'Loop Engineering': AI's Self-Sufficient Work, Supervision, and Revision
 07/03 2026
07/03 2026
 429
429
Ending the Prompt Race.
Yesterday, Xiaolei stumbled upon a post by Andrew Ng on X, discussing the concept of Agent Loop (cyclical) engineering.

Image Source: X
If you've utilized Claude Code, Codex, Workbuddy, Kimi Work, or similar Agent products in the past six months, you've likely observed a significant shift. Instead of instructing AI step-by-step, you now input your requirements, and it proceeds to write, execute, and self-correct until the task is accomplished.
This sense of 'self-operation' is the manifestation of Loop engineering in Agent products.
'...You should no longer be crafting prompts for Coding Agents; instead, focus on designing Loops.' In June, a tweet by Peter Steinberger, founder of OpenClaw, ignited widespread discussion. Shortly before that, Addy Osmani, Google's engineering lead, systematically introduced the concept of Loops, marking the advent of Loop engineering.
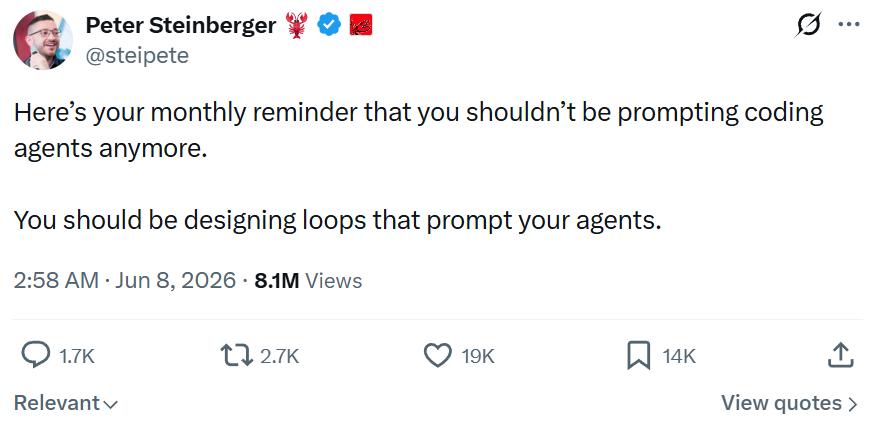
Image Source: X
However, public information suggests that Boris Cherny, founder of Claude Code, was the first to propose Loops and the one who truly made them shine. In late June, Anthropic even published a blog post detailing all four loop primitives in Claude Code.
In just a month, Loop engineering has undergone a remarkable evolution, becoming not only an industry consensus but also a mainstream focus. So, what exactly is a Loop? And what impact does it have on everyday users?
From Prompts to Harness and Loop: What Additional Benefits Do Agents Offer?
Traditionally, using AI revolved around crafting prompts. Whether you requested the model to write code, revise documents, or conduct research, the more detailed your prompts, the more satisfactory the outcomes. As models evolved into Agents, they not only needed to respond but also to determine when to read files, execute commands, search the web, or pause to seek human input. Prompt engineering and chain-of-thought techniques were no longer sufficient.
Thus, Harness engineering emerged. It can be understood as the operational framework surrounding the model, responsible for connecting tools, managing permissions, injecting context, and storing states. The model still handles reasoning and generation but is now placed in an environment capable of executing tasks.
Loop engineering takes this a step further, focusing on how to enable Agents to operate continuously in cycles around a specific goal.
OpenClaw's official documentation views Loops as the 'foundation.' Image Source: OpenClaw
Simply put, the user sets a goal, and the Agent first comprehends the task, gathers context, invokes tools, observes results, and determines whether the task is complete. If not, it continues to revise, execute, and check. This process mirrors human work routines: create a draft, identify issues, revise, and repeat until the result is satisfactory.
Thus, the emphasis of Loops lies not in the word 'cycle' itself but in what is placed inside the cycle.
Claude Code exemplifies this best. It doesn't merely connect Claude to a terminal but allows the model to repeatedly invoke tools, edit files, run commands, and observe results within a while-loop. The truly complex parts lie outside the loop: permission systems, context compression, plugins, skills, hooks, sub-agents, and session storage.
Whether an Agent can operate autonomously depends not on the model's whim but on a comprehensive engineering design that supports it.
This is the core context behind Andrew Ng's recent discussion of Loop engineering. By 2026, Claude Code, Codex, ZCode, MiniMax Code, and other Agent products have transformed 'write-run-review-revise' into a default capability.
Anthropic's blog post categorizes Loops into four types: turn-based, goal-based, time-based, and proactive.
- 'Help me write a login page'—it writes, tests, and revises. This is a goal-based loop.
- It replies to each message you send. This is turn-based.
- Time-based: You can set it to automatically check a PR every two hours and review updates for you.
- Proactive: It identifies problems and takes action independently, such as noticing a drop in test coverage and adding test cases itself.
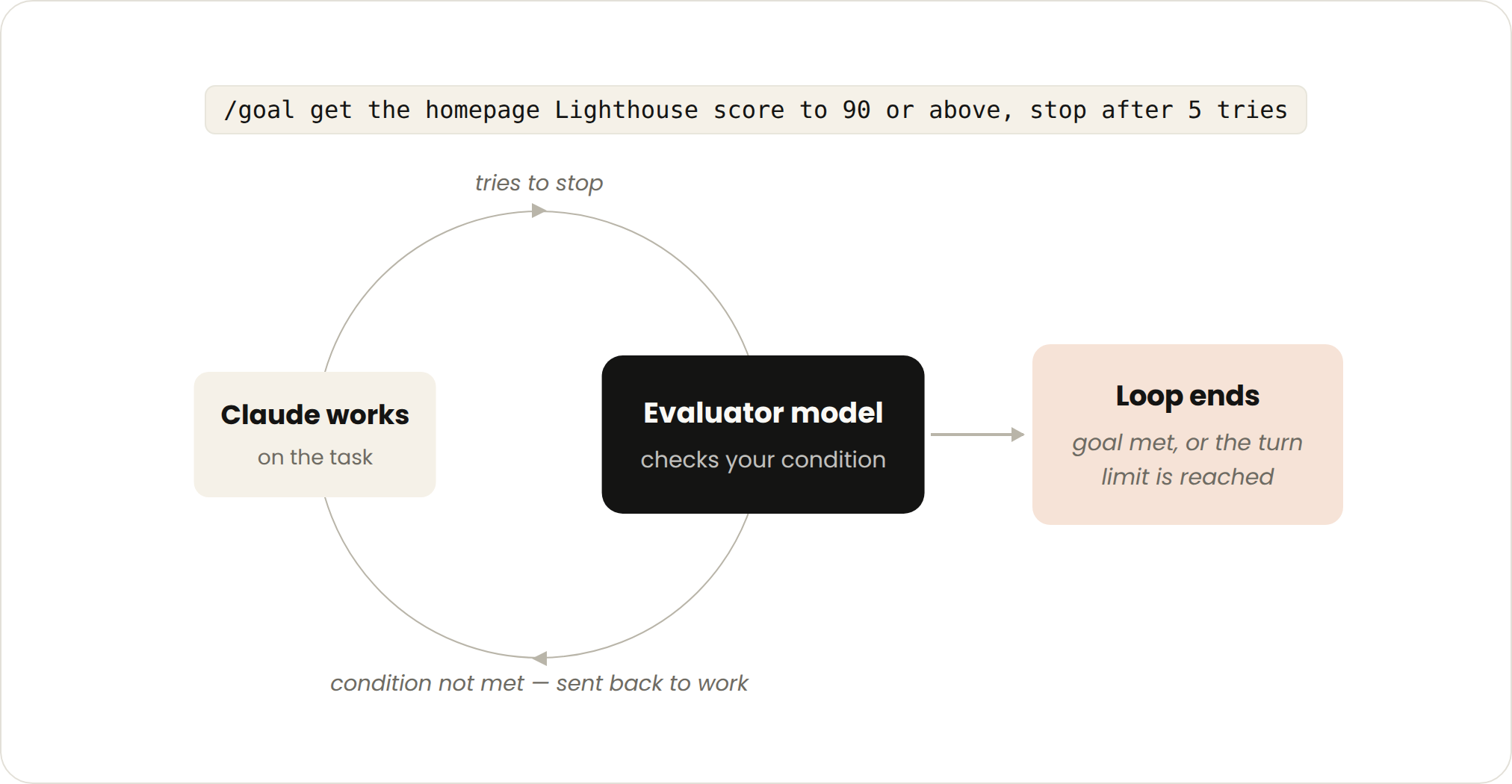
Goal-Driven Loop. Image Source: Anthropic
The sudden surge in discussions in May and June is also linked to product advancements. OpenAI's Codex is no longer just an entry point for 'helping you write code' but operates in an independent environment to read repositories, modify files, run tests, and return logs and results.
On Anthropic's side, Claude Code itself has become the prime example of Loop engineering. Boris Cherny's statement, 'Stop writing prompts yourself; let an Agent prompt Claude,' may sound convoluted but essentially means humans no longer dictate every step to the model. Instead, humans design mechanisms that keep the model working continuously.
This is why Loop engineering truly matters to everyday users. The better the Loop engineering, the more the Agent resembles a person capable of taking on tasks: you give it a direction, and it moves forward independently. If it veers off course, it adjusts based on feedback. Once done, it presents the process and results for your review.
Ending Prompts: What Does It Mean for Everyday Users?
The most direct value of Agent Loops for everyday users is lowering the barrier for prompt design.
Using AI in the past was akin to collaborating with a smart but inexperienced intern. You had to instruct it at every step, when to stop, where to look up information, and where not to improvise. The more detailed your instructions, the better it performed. The vaguer your directions, the more likely it was to go astray.
An Agent with well-designed Loops acts more like someone who already knows the basic workflow. You don't need to remind it to 'keep revising if the code errors,' as testing and revising are part of the cycle. You don't even need to cram all context into a single dialog box, as the Agent can gradually gather the necessary information through the file system, search tools, memory, and indexing.
This will transform the relationship between users and AI.
Previously, when writing prompts, users often had to assume the roles of product manager, project manager, test engineer, and teacher. You provided requirements, broke down steps, monitored progress, and corrected errors. In the future, users will more likely set goals and verify results.
For example, if you ask an Agent to plan a trip, you used to write: budget, duration, check flights first, then hotels, consider transportation, provide a table, and summarize. With a well-designed Loop, you only need to say, 'I'm going to Tokyo for 5 days next month with a moderate budget. I want less hassle and more exhibitions.' The Agent should then check schedules, compare prices, arrange routes, resolve conflicts, and present a plan. It can even automatically rearrange if you provide feedback, 'Day 2 is too packed.'
This is the first layer of meaning behind 'ending the prompt race.' Everyday users no longer need to train themselves into prompt engineers; Agent products should absorb complex workflows for them.
On the other hand, software engineering is inherently suited for Loops. Goals can be written as issues, processes can be broken down into file modifications, tools can run tests, and results can be verified using diffs and CI. If an Agent makes a mistake, the system immediately detects the error. If it fixes the issue, the system confirms the success. This feedback loop is clear, verifiable, and accumulative, which is why Claude Code, Codex, ZCode, and MiniMax Code all start with coding scenarios.
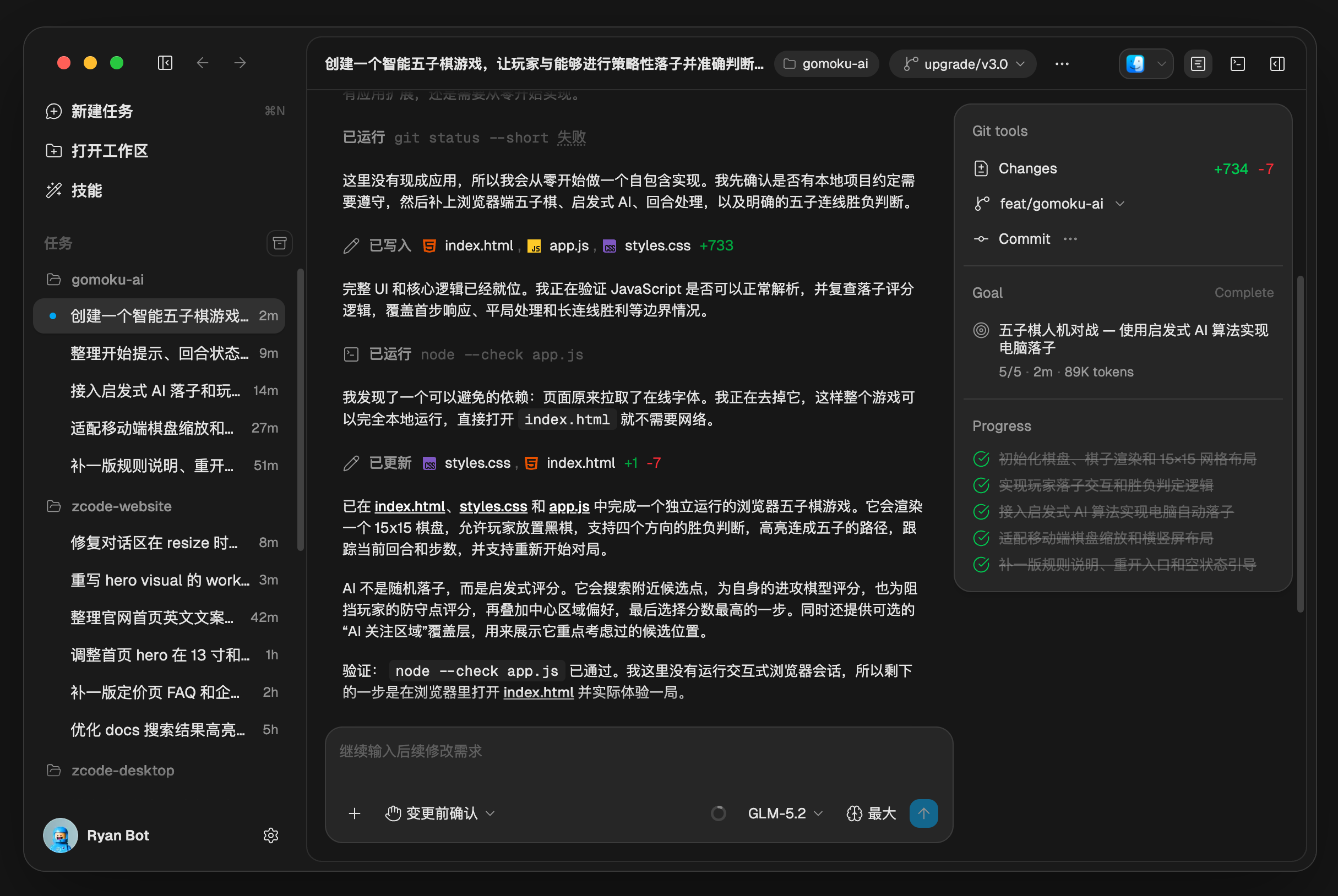
Image Source: Zhipu ZCode
But coding is just the beginning. Research, spreadsheets, PPTs, data analysis, customer service tickets, legal searches, recruitment screening, and operational monitoring all share similar characteristics: tasks cannot be completed in one sentence, but success criteria can be defined, processes can be recorded, and results can be checked.
This is the second layer of value of Loops: boosting productivity in complex tasks. Humans no longer monitor every step but instead set directions, review results, and adjust specifications. Andrew Ng's 'developer feedback loop' refers to how AI can accelerate internal execution cycles, but humans still need to judge the direction at a higher level.
Additionally, poorly designed Agents may initially seem unstable, randomly invoking tools and drifting off course. From an engineering perspective, Loops provide a handle for reliability.
Under Loop engineering design, why an Agent searches a page, modifies a file, invokes a tool, or determines a task is complete can all be recorded. Fixes can become skills, and project rules can be written into AGENTS.md, CLAUDE.md, or similar memory files. The next time the Agent handles a similar task, it won't need to start from scratch.
However, it's crucial to clarify that Loops don't automatically guarantee reliability. In fact, a poorly designed Loop will only cause errors to replicate faster.
In Conclusion
Over the past three years, the way we use AI has undergone several major shifts, but the underlying logic remains the same—humans issue commands, AI executes, and humans judge the results. Humans have always been inside the loop, driving the entire system.
Loop engineering, for the first time, moves humans from the center of the loop to the outside. Humans are no longer drivers but navigators.
The implications of this change are more profound than imagined. For developers, core competitiveness now lies in defining problems and designing acceptance criteria. For products, iteration speeds will accelerate further, forcing product teams to understand users and businesses better, as technology is no longer the bottleneck—judgment is.
Of course, all this rests on one premise: models must continue to improve. How many loops a Loop can spin and how complex a task it can handle ultimately depend on the model's foundational capabilities. If the model veers off course after a few steps, no amount of clever Loop design will help.
Fortunately, based on this year's progress, model improvement hasn't slowed down. GPT-5.5, Claude 5, GLM-5.2, M3, K2.6, DeepSeek V4—every major player has released a new generation in six months, with noticeable advancements in Agent capabilities each time.
As models grow stronger, Loops spin more smoothly, and humans step further back. This trend is already evident.
This may sound like mere efficiency gains, but upon closer inspection, it could be a crucial step for AI to evolve from a 'tool' to a 'collaborator.' A tool requires you to know how to use it and operate it step by step. A collaborator is someone you tell your goal, and it figures out how to achieve it, working with you to get things done.
We may now be standing at this dividing line.
Agent Loop Anthropic AI Prompts
Source: Leikeji
All images in this article are from the 123RF licensed image library. Source: Leikeji
-
![]()
Laifen Seeks to Escape 'Budget Dyson' Label but Falls Short of Dyson's Prestige
-
![]()
Who is Holding Back the Development of Dexterous Hands?
-
![]()
How do Autonomous Driving Physical AI and End-to-End Systems Work Together?
-
![]()
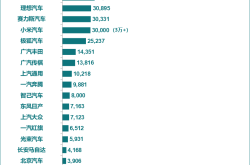
June's New Energy Vehicle Sales Rankings Unveiled! Leapmotor Surpasses Tesla in a Stunning Comeback, Marking the Start of the Automakers' Knockout Phase
-
![]()
Global Agents Embrace 'Loop Engineering': AI's Self-Sufficient Work, Supervision, and Revision
-
Post-90s Straight-A CEO Propels Jihao Technology Toward IPO, Despite Over 90% Revenue Reliance on Smartphones
-
AI 'Dissolves' Visual China's Copyright Moat—What Story Can It Tell to List in Hong Kong?
-
![]()
The AI Industry Chain: A Tale of Fire and Ice - Upstream Thrives, Downstream Struggles