How do Autonomous Driving Physical AI and End-to-End Systems Work Together?
 07/03 2026
07/03 2026
 489
489
The technological approach to autonomous driving is constantly evolving. Over the past two years, end-to-end autonomous driving has transitioned from concept to mass production. Segmented end-to-end systems achieved large-scale implementation between 2024 and 2025, while unified end-to-end and VLA technologies were widely adopted in vehicles between 2025 and 2026. Now, Physical AI has been thrust into the forefront (Related reading: What are the large Physical AI models released by various automakers? What are their advantages?). Data shows that over $10 billion has poured into the Physical AI sector in the last 18 months, with the market expected to reach $82.8 billion globally by 2035. With such a massive market size, does this mean Physical AI will replace end-to-end systems? How do Physical AI and end-to-end systems work together?
What Problems Does Physical AI Aim to Solve After End-to-End?
The core logic of end-to-end systems is to replace independent modular architectures for perception, prediction, and planning with a single neural network. Sensor data can be directly input into the network, which then outputs control commands. This operational logic enables faster reactions in autonomous driving but has a fundamental issue: end-to-end systems essentially perform behavior cloning, training models on vast amounts of human driving data to mimic human driving. While the model can imitate well, it does not truly understand the physical consequences of each action, such as whether adjacent vehicles will accelerate during a lane change or the reaction space available if the vehicle ahead suddenly brakes. Judgments involving physical laws and causal relationships are difficult to cover through behavior imitation alone.

Image source: Internet
Physical AI addresses precisely this issue. It enables machines to understand physical laws such as gravity, inertia, and causality, allowing them to truly participate in the operation of the real world. 2026 has been frequently referred to as the first year of Physical AI. As seen at CVPR 2026, the technical narrative in intelligent driving is shifting from end-to-end systems to Physical AI foundation models. Strategy& consulting predicts that the global Physical AI market will reach €430 billion by 2030, with autonomous driving being a core application. Data from Acumen Research shows that the global Physical AI market is expected to reach approximately $6.44 billion in 2026 and grow to $82.79 billion by 2035.
At this stage, a consensus is forming in the autonomous driving industry that the next phase of large intelligent driving models will be foundation models for the physical world. The relationship between Physical AI and end-to-end systems is not one of replacement; rather, Physical AI fills in the missing piece of end-to-end systems, enabling autonomous driving systems to evolve from knowing how to drive to understanding how to drive.
What Capability Modules Does Physical AI Include in Vehicle Deployment?
Before discussing how Physical AI and end-to-end systems work together, it's essential to understand what Physical AI includes in vehicle deployment. Physical AI is not a single model but a capability system.
The world model serves as the underlying foundation of Physical AI, tasked with predicting the future state and interaction logic of the physical world. Analogous to how large language models rely on word-by-word prediction to compress common sense about the digital world, world models use the same logic to understand the physical properties of objects, the causal relationships of motion, and potential interactions. However, instead of predicting the next word, they predict what the physical world will look like next. Xpeng's X-World is a typical example, a controllable multi-camera generative world model. When historical multi-view videos and future self-vehicle actions are input, it does not output a synthetic road-like image but directly answers questions about what the surrounding world would look like if the vehicle executes a certain action next.

Image source: Internet
VLA (Vision-Language-Action model) is the cognitive and decision-making module of Physical AI, regarded by the industry as an intelligent enhanced version of end-to-end solutions. VLA unifies vision, language, and actions within a single model framework, enabling the system to generate driving actions directly from inputs such as video streams and navigation instructions. NVIDIA's Alpamayo 2 Super is a 32-billion-parameter inferential VLA model used to advance the development of L4 autonomous taxis.
Reinforcement learning serves as the strategy optimization module of Physical AI (Related reading: What is 'reinforcement learning' often mentioned in autonomous driving?). Traditional intelligent driving systems essentially operate based on recognition, matching, and execution logic, prone to errors when encountering long-tail scenarios not present in the database. Reinforcement learning relies on reward mechanisms to iteratively optimize strategies in simulation spaces, allowing AI to autonomously explore how to drive in countless virtual simulations as if it were part of the scenario.
The world model, VLA, and reinforcement learning modules together constitute the core capabilities of Physical AI, with the end-to-end model serving as their execution outlet.
How Do the Modules of Physical AI Work with End-to-End Systems?
At this stage, the cooperation between Physical AI and end-to-end systems can be summarized into several typical fusion models.
The first model combines unified end-to-end systems with world models and reinforcement learning, represented by companies such as WeRide, Bosch, and Momenta. The unified end-to-end system, as the core neural network, directly connects sensor inputs with driving outputs, ensuring zero information loss and high performance limits. The world model is responsible for future scenario simulations, generating a vast number of long-tail scenarios at low cost for simulation training. Reinforcement learning iteratively optimizes strategies in simulation spaces based on reward mechanisms. Together, they form a closed loop of data generation (world model) → strategy training (reinforcement learning) → decision execution (end-to-end model). Momenta announced in April 2026 that its R7 reinforcement learning world model achieved mass production, refining data from over 12 billion kilometers of real driving mileage and compressing real-world common sense into the model through video prediction and causal learning (Related reading: What is unique about Momenta's R7 world model technology?).

Image source: Internet
The second architecture combines end-to-end systems with VLA, reinforcement learning, and world models, represented by companies such as Horizon Robotics and Qianli Technology. In this setup, VLA or VLM (Vision-Language Model) acts as the brain, responsible for cognitive reasoning and semantic understanding of complex long-term scenarios, while the end-to-end model serves as the cerebellum, responsible for rapid execution. Horizon Robotics adopts a dual-track architecture of fast and slow thinking, with reinforcement learning as the Central (central hub). On one side, it empowers the end-to-end intuitive model to handle millisecond-level responses through world models and simulation training. On the other side, it empowers the VLM cognitive model to handle complex long-term scenarios through inferential reinforcement. Qianli Technology uses a 32B-parameter large model for multimodal pre-training, which is then distilled into a 7B lightweight model for vehicle deployment.
The third model involves the cooperation of VLA and world models, represented by companies such as Zoyu Technology and Xpeng. VLA is responsible for perceiving the current environment, learning historical driving patterns, and deciding the next action, while the world model is responsible for simulating how each target on the road will interact in the next 5 to 10 seconds. Xpeng's physical world foundation model includes both the second-generation VLA and world model. Liu Xianming explicitly stated in his CVPR 2026 speech that these two are not a route dispute; VLA learns how to act, while the world model learns how the world changes after action. Zoyu Technology released the industry's first native multimodal foundation model at the Beijing Auto Show in 2026, marking its technical path's official shift from end-to-end solutions to mobile Physical AI.

Image source: Internet
From these fusion models, it can be seen that the cooperation between Physical AI and end-to-end systems is not a simple A+B but involves parallel collaboration of multiple modules. The end-to-end system is responsible for the rapid mapping from perception to execution, the world model provides simulations of the future physical world, VLA provides cognitive-level reasoning, and reinforcement learning continuously optimizes strategies in simulation spaces.

What Challenges Does Vehicle Deployment Face?
While the above cooperation models are theoretically sound, significant challenges remain for actual vehicle deployment.
Computational power and latency are the first issues. Vehicle chips' computational power pales in comparison to cloud training clusters, and reasoning latency must be controlled within a hundred milliseconds. This means that no matter how well large models perform in the cloud, they must be streamlined before deployment in vehicles. Many technical solutions adopt distillation and quantization methods during deployment, using large-parameter models for training and simulation in the cloud while deploying lightweight versions in vehicles. NVIDIA's DRIVE AGX Thor chip can deliver up to 2000 TFLOPS of computational power at FP4 precision, with large language model reasoning performance more than 20 times higher than the previous generation Orin chip at specific precisions. However, even this falls short of the cloud training clusters' computational power by orders of magnitude.

Image source: Internet
Besides computational power, the length of the reasoning chain is equally challenging. If the end-to-end model must first go through VLA reasoning and then world model simulations before outputting actions, the entire chain would take too long. On highways, if the vehicle ahead brakes suddenly, the system cannot afford to spend several hundred milliseconds thinking before acting. Therefore, vehicle cooperation is not sequential (think first, then act) but parallel (think while acting). The fast system continuously outputs basic control commands to ensure response speed, while the slow system performs long-term assessments and corrections in the background, operating independently without blocking each other.
Another unavoidable issue is the data feedback loop. Training end-to-end models and Physical AI modules relies on vast amounts of data, but long-tail scenarios collected from real roads are extremely scarce. Relying solely on road data collection is neither cost-effective nor practical. Currently, the industry is shifting towards a continuous loop of collection, reconstruction, generation, training, validation, and retraining. In NVIDIA's Physical AI agent skills, neural reconstruction technology allows developers to rebuild real-world fleet data into realistic 3D scenes. 51Sim's SimOne4.0 has completed product-level adaptation for NVIDIA Cosmos 3 and Alpamayo 1.5, allowing users to call them directly without building their own world model reasoning stacks. The maturity of this closed loop directly determines the pace of Physical AI's transition from the cloud to vehicles.
Final Thoughts
From the trajectory of technological evolution, end-to-end systems have solved the mapping problem from perception to action, while Physical AI, through the combination of world models, VLA, and reinforcement learning, addresses issues such as future simulations, language-based understanding and reasoning, and strategy optimization in simulations. These four components operate in parallel within the limited computational budget of vehicles, forming a driving decision system that is both fast and stable. It is foreseeable that the implementation of Physical AI will not replace end-to-end systems but will integrate them into a more complete system, enabling vehicles to evolve from knowing how to drive to understanding how to drive.
-- END --
-
![]()
Laifen Seeks to Escape 'Budget Dyson' Label but Falls Short of Dyson's Prestige
-
![]()
Who is Holding Back the Development of Dexterous Hands?
-
![]()
How do Autonomous Driving Physical AI and End-to-End Systems Work Together?
-
![]()
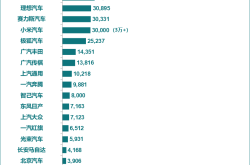
June's New Energy Vehicle Sales Rankings Unveiled! Leapmotor Surpasses Tesla in a Stunning Comeback, Marking the Start of the Automakers' Knockout Phase
-
![]()
Global Agents Embrace 'Loop Engineering': AI's Self-Sufficient Work, Supervision, and Revision
-
Post-90s Straight-A CEO Propels Jihao Technology Toward IPO, Despite Over 90% Revenue Reliance on Smartphones
-
AI 'Dissolves' Visual China's Copyright Moat—What Story Can It Tell to List in Hong Kong?
-
![]()
The AI Industry Chain: A Tale of Fire and Ice - Upstream Thrives, Downstream Struggles