Offer QWen3 an 'Objective Assessment' - A Horizontal Evaluation of Large Models with QWen3 as the Focal Point
 11/20 2025
11/20 2025
 685
685

Introduction: The Qwen3 flagship model has made its mark in the global top echelon and ranks among the top 2 - 3 models domestically. Its overall capability is marginally lower than that of Gemini3, GPT - 5.1, and Kimi K2 Thinking, but it is on a par with Grok 4.1 and Claude Opus 4.1.
The recently launched Qianwen App by Alibaba has drawn external attention. How does the performance of its underlying Qwen3 large model stack up against several major international and domestic models? And how should users select different large models for various tasks? Today, we'll provide a comparative analysis and summary.
01 Fundamentals of Qwen3
The third - generation large model Qwen3, introduced by Alibaba this year, serves as the core foundation of the Qianwen App. It boasts several key features:
I. Size and Architecture
- Dense Model: Ranging from 0.6B to 32B;
- MoE Flagship: Qwen3 - 235B - A22B (with a total of 235B parameters and 22B active parameters), akin to a 'parameter behemoth + energy - efficient computing'.
II. Training Scale
The training data comprises approximately 36 trillion tokens, covering 119 languages/dialects. Additional reinforcement has been carried out for mathematics, coding, and STEM reasoning. It offers a 'Thinking Mode', similar to the explicit reasoning versions of GPT - o1/DeepSeek - R1.
III. Application Forms
It encompasses text dialogue, writing, coding, and multimodal (image/document/table) capabilities. The long - context version can support millions of tokens, making it highly suitable for long - document scenarios.
Since the Qianwen App is targeted at consumer - end users, it typically employs a combination similar to 'Qwen3 - Max/Qwen3 - 235B Flagship + Thinking Version'.
02 What 'Yardstick' to Use for Measuring Qwen3?
The following metrics are employed to evaluate the performance of Qwen3:
Artificial Analysis Intelligence Index (AA Index)
The AA Index integrates over a dozen high - value benchmarks such as MMLU - Pro, GPQA, HLE, LiveCodeBench, and SciCode, ultimately providing each model with a comprehensive 'intelligence score' ranging from 0 - 100. This score is currently one of the most frequently cited 'overall scores' for large models on the international stage.
LMArena/Text Arena (Human Blind Evaluation Elo Rankings)
This method involves a large number of real users voting on which answer is better without knowing the model names, using Elo scores for ranking. It places more emphasis on the 'real - world usage experience' dimension.
In addition, some single - item benchmarks are also used for evaluation:
- AIME2025: Competition - level mathematics;
- HLE (Humanity’s Last Exam): An extremely difficult comprehensive exam;
- LiveCodeBench/SciCode: Practical - oriented software engineering and scientific coding; as well as other classic benchmarks like MMLU, GSM8K, and HumanEval.
This evaluation mainly centers around the AA Rankings + Human Blind Evaluation Rankings, supplemented by a small number of specialized benchmarks, aiming for as much objectivity and fairness as possible.
Entering the 'Top Tier', but Still with a Ceiling.
AA Index: According to the currently available public information, the AA Index scores of various mainstream large models are presented in the table below:
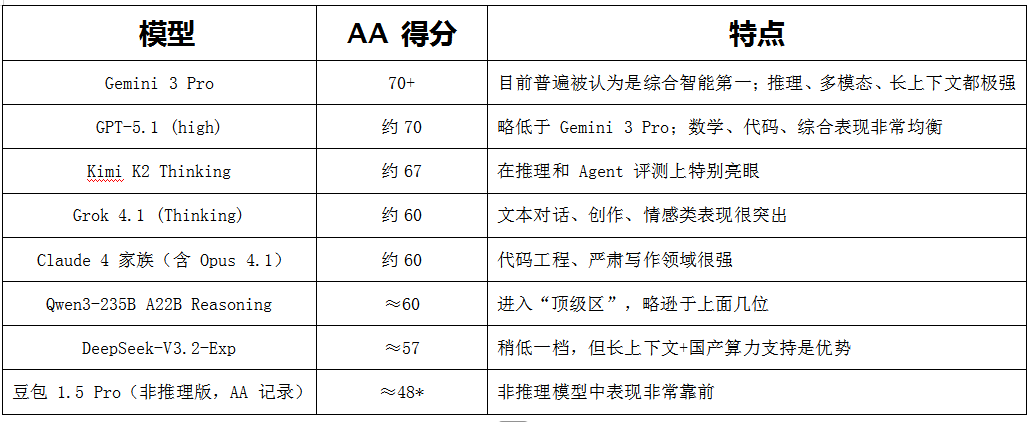
Note: It is listed as one of the 'Best Non - Reasoning LLMs' in AA's 'State of AI: China Q2 2025'. Scores marked with an asterisk indicate partial estimation based on manufacturer data.
Based on the above scores, the flagship version of Qwen3 stands shoulder to shoulder with Grok 4.1 and Claude 4.1, but there is a gap of about 7 - 10 points compared to Gemini3 Pro, GPT - 5.1, and K2 Thinking—a gap that is still noticeable among top - tier models.
Human Blind Evaluation Elo Rankings: The evaluation results reveal that Gemini3 Pro and Grok4.1 (Thinking) take turns occupying the top spots. GPT - 5.1 and the Claude 4 family also consistently rank at the top. Although the score of the Qwen3 flagship is slightly lower than these 'top performers', it has indeed made its way into the front ranks of the first tier, competing on the same ranking list.
A more intuitive way to put it is: When overseas developers and researchers actually vote, users can already perceive that 'Qwen3 is a strong model, and when compared to first - tier models like GPT - 5/Gemini3, there is no significant gap in experience.'
Now, let's examine a few single - item evaluations:
AIME 2025: Competition Mathematics
The approximate ranking of test results is: GPT - 5 Codex (high) ≈ GPT - 5.1 > Kimi K2 Thinking > Grok 4 > Qwen3 235B > Gemini 2.5/Claude 4 series.
This implies that Qwen3 is in the first tier for high - difficulty mathematics, but in scenarios of 'competition mathematics + reasoning specialization', 'math powerhouses' like GPT - 5.1/K2/Grok 4 are stronger.
HLE: Extremely Difficult Comprehensive Reasoning
In this test, Kimi K2 Thinking and the GPT - 5 family stand out the most in HLE. Qwen3 is on a par with the GPT - 4.1/Grok - 3/Gemini - 2.5 Pro generation, with slight improvements. The test results suggest that Qwen3 does not fall short in extreme comprehensive reasoning but is not the one taking the lead either.
LiveCodeBench/SciCode: Engineering Code & Scientific Code
In terms of engineering code, GPT - 5.1, K2 Thinking, Grok4 ≈ Gemini2.5Pro > Qwen3 ≈ DeepSeek - V3.2. In scientific code (SciCode) testing, the gap narrows further, with all models clustered in the slightly over 40% range.
In other words, if you use Qianwen for coding, its level is roughly 'slightly weaker than GPT - 5.1/K2/Grok4', but it is definitely not noticeably lagging like the previous generation.
03 Comparison Among China's Top Four: Kimi, Qwen3, DeepSeek, Doubao
Kimi K2 Thinking has a comprehensive intelligence score of around 67 points, directly breaking into the global top five on the AA Rankings. Since the model emphasizes browsing, tool invocation, and agent tasks, it performs particularly well on benchmarks like HLE and BrowseComp that lean towards 'agency'.
Qwen3 has a comprehensive intelligence score of around 60 points, with relatively balanced performance across all aspects. DeepSeek - V3.2 - Exp has a comprehensive intelligence score of about 57 points, with characteristics optimized for domestic chip compatibility, long - context performance, and reasoning energy efficiency, tailored for China's computing environment.
Doubao 1.5 Pro (non - reasoning version) has an intelligence index of about 48* in the AA China Q2 report, ranking among the top non - reasoning large models and listed as one of the 'Best Non - Reasoning Large Models'; however, its reasoning version (Thinking) currently does not have a complete AA comprehensive score publicly available.
In terms of comprehensive scores: K2 Thinking > Qwen3 > DeepSeek - V3.2 > Doubao 1.5Pro. However, when considering 'computing cost + domestic chip environment', DeepSeek holds a unique position, while Qwen3 is more balanced in terms of 'ecosystem + robust general capabilities'.

04 User Perspective
Daily Q&A, Writing, and Knowledge Retrieval
For daily use in Chinese/Chinese - English mixed contexts, Qwen3 + Qianwen App already offers a world - class experience. Response speed, knowledge coverage, context memory, and writing style are all well - developed. Compared to GPT - 5.1/Gemini 3 Pro, the main gaps lie in extreme long - chain reasoning and some specific professional English domains. Doubao, on the other hand, provides a more natural style in natural Chinese expression, colloquial dialogue, and social media contexts, making it suitable for chatting, lightweight Q&A, and content creation.
Mathematics & Competition - Level Problems
If the user's scenario involves competition mathematics, advanced logic problems, extremely complex chained reasoning, etc., GPT - 5.1, Gemini 3 Pro, Kimi K2 Thinking, and Grok 4.1 are still slightly stronger.
Code Development
Qwen3's performance on benchmarks like LiveCodeBench/SciCode has already reached a first - tier level of 'engineering usability'. When it comes to large - scale code refactoring and complex debugging, GPT - 5.1, K2 Thinking, and Grok4 have slight advantages in some data, but Qwen3 + good toolchains (IDE plugins, CI integration) are sufficient to support the daily development work of most teams.
Multimodal, Documents, and Tables
This is one of the strong suits of the Qwen family: Qwen2.5 - VL and Qwen3 - Omni frequently score high in papers and evaluations for image understanding, PDF/document parsing, and table/chart tasks. For users, this means that when you present PPTs, PDFs, scanned documents, or complex reports to Qianwen, it can generally understand them quite well.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






