What Is Offline Reinforcement Learning Often Mentioned in Autonomous Driving?
 02/09 2026
02/09 2026
 533
533
Previously, when discussing the training of autonomous driving models, we explored the pivotal role of reinforcement learning. This approach allows large models to acquire strategies through interaction, unconstrained by fixed rules, thereby opening up more possibilities for realizing autonomous driving.
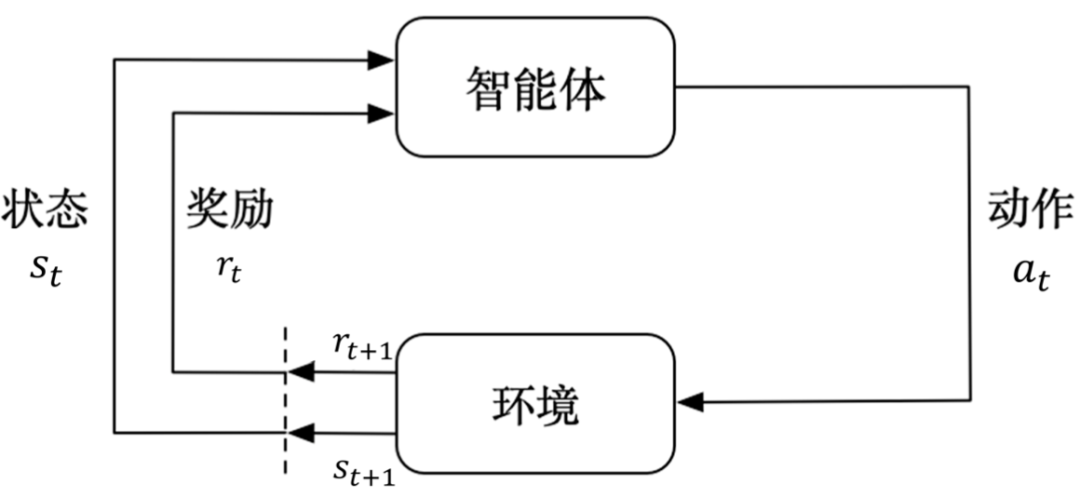
Schematic Diagram of Reinforcement Learning. Image Source: Internet
However, reinforcement learning inherently involves continuous trial and error. If this method were applied on real roads with constant experimentation, it would inevitably lead to uncontrollable accidents. This raised a conjecture: Could we utilize the vast existing driving logs, simulation records, and human driving data to train a reliable decision-making module without any real-world interaction during the training process?
Offline reinforcement learning emerged as a proposed solution based on this idea. It involves collecting a substantial amount of past experiences (including states, actions, consequences/rewards, etc.) and using them as training materials. This allows the model to learn strategies in an offline state, rather than through trial and error in real-world traffic scenarios. The advantages of this approach include enhanced safety, cost-effectiveness, and the ability to reuse existing data. However, it also presents numerous challenges, which we will delve into later.
Technical Challenges of Offline Reinforcement Learning
Offline reinforcement learning is constrained to a fixed dataset during the training phase, which comprises records generated from past interactions. The training algorithm can no longer interact with the environment to collect new samples. This limitation introduces issues such as distribution coverage problems, estimation bias, and evaluation difficulties.
When training large models with offline reinforcement learning, the historical data often stems from existing behavioral strategies or human driving habits. Consequently, certain state-action pairs may be entirely absent from the data. If the trained strategy selects actions that are rarely or never covered in the data during deployment, the algorithm's value estimates for these actions will be highly unreliable.
In offline data, some actions may occur very infrequently or not at all. Logically, the model should exercise caution with these actions. However, reinforcement learning algorithms may overestimate these actions due to a lack of real data support when estimating action values (Q-values). As a result, the model may perceive these actions as highly beneficial, leading to a bias in the learned strategy toward behaviors that are unsafe or even infeasible in reality.
Moreover, offline reinforcement learning cannot validate strategies in real-world traffic environments during training and must rely on offline estimation methods or simulations. This complicates the verification of the reliability of the learned strategies. To mitigate distribution bias and estimation issues, offline reinforcement learning algorithms must incorporate conservative terms, uncertainty estimates, behavioral constraints, etc. All these factors increase implementation difficulty and tuning costs.
Mainstream Approaches to Offline Reinforcement Learning
Currently, a prevalent implementation method in offline reinforcement learning is behavior cloning. This approach transforms the problem into supervised learning by using historical states to predict historical actions, thereby learning to "imitate human driving." Behavior cloning is straightforward to implement and stable during training. However, its upper limit is constrained by the quality of human driving in the data, and it struggles to handle new scenarios not covered in the data.
To address the limitations of behavior cloning, offline reinforcement learning algorithms centered on value estimation but with conservatism constraints have emerged. These primarily employ two strategies: "behavioral constraints" and "conservative estimation." Behavioral constraints directly limit how much the new strategy can deviate from the existing data during optimization. Conservative estimation strategies deliberately penalize actions not present in the data when estimating action values. These approaches aim to suppress unrealistically optimistic estimates and make the learning process more reliable.
Another approach involves initially learning an environmental dynamics model and then performing planning or strategy optimization within this model. The crux of this method lies in how to incorporate penalties or distrust discounts in regions of uncertainty or unreliable predictions to avoid dangerous actions caused by model errors.
Additionally, techniques such as ensemble uncertainty estimation, using confidence intervals to control decision-making, or employing offline learning as a pre-training foundation followed by limited online fine-tuning in controlled simulations or sandboxes are also utilized for model learning.
In practical applications, these methods are often combined. Behavior cloning can serve as a stable initial strategy. Conservative Q-learning or batch constraint methods can further enhance strategy performance. Meanwhile, model-based planning and uncertainty estimation act as supplements for risk control. It is crucial to emphasize that, regardless of the method employed, the diversity and quality of the data fundamentally determine the effectiveness. If certain scenarios are not covered, it is challenging for any algorithm to achieve safe and reliable generalization.
How Can Autonomous Driving Effectively Utilize Offline Reinforcement Learning?
To effectively leverage offline reinforcement learning in autonomous driving, the first step is to establish a robust data collection system. In addition to daily driving logs, it is essential to proactively synthesize and collect samples of edge cases, such as nighttime driving, backlighting, heavy rain, fog, temporary construction scenes, and abnormal pedestrian behavior. Simulation plays a pivotal role here, as it can compensate for scarce data in real-world scenarios but must be integrated with real data.
Next, a phased training process should be implemented. Throughout the entire learning pipeline for large models, offline reinforcement learning can serve as a pre-training method. Initially, a "robust baseline" can be trained on large-scale historical data. Subsequently, the strategy can undergo more comprehensive scenario coverage testing in high-fidelity simulations. Finally, a controlled deployment can be conducted (e.g., initially operating in specific areas, at low speeds, and under human supervision). During actual operation, discrepancies between the strategy's decisions and the actions of real drivers can be continuously recorded in "shadow mode," and new data can be collected for subsequent offline fine-tuning.
When deploying large models, mandatory safety layers and fallback mechanisms must be in place. Regardless of the sophistication of the strategy, independent safety monitoring is indispensable. When the perception or decision-making module detects high uncertainty, model violations, or risks that may cause harm to personnel, the system should downgrade to a more conservative control logic or directly hand over control to a human operator.
The evaluation and metric systems must also be more rigorous. Relying solely on "average reward" during training or offline estimates is insufficient to judge deployment safety. Multi-dimensional metrics are required, including uncertainty distributions, worst-k% scenarios, OPE (Offline Policy Evaluation) methods, and metrics obtained through simulation and small-scale deployment verification.
For autonomous driving, regulatory and liability frameworks must be designed in advance. In real-world traffic environments, any erroneous decision will involve liability determination, remediation, and compliance reviews. The training logs and decision explanations from offline reinforcement learning will serve as crucial evidence. Therefore, it is essential to ensure data traceability, strategy version rollback capabilities, and comprehensive audit records.
Final Remarks
Although offline reinforcement learning faces challenges such as "data determining the upper limit" and "difficulty in out-of-distribution generalization," it provides a highly valuable implementation path for real-world applications, especially for safety-sensitive tasks like autonomous driving. It alleviates the contradiction between "the potential of reinforcement learning" and "the safety constraints of the real world," enabling us to leverage vast amounts of historical experience to train intelligent strategies.
-- END --
-
'Computing Power Leather' Surges 77% in 9 Days, NIO Supplier Also Chases the 'Light'
-
![]()
Storage and Computing Power Becoming Scarcer: Google Initiates Exploration of Using Old Smartphones to Build AI Servers
-
![]()
Storage Computing Power Grows Scarcer: Google Explores Using Old Smartphones for AI Servers
-
![]()
Huawei Imposes a $0.5 Patent Fee Per Device: Is It Time for Huawei to Reap Global Patent Royalties?
-
![]()
Geely Invests 1.8 Billion Yuan Post-Acquisition: The Launch of Flyme Auto 3.0 Sparks Questions on Meizu’s Enduring Influence
-
![]()
MBBF 2026 on the Bund in Shanghai: Deciphering Mobile AI's Future Trajectory
-
![]()
Commercialization of ASIC: The Turning Point Has Arrived
-
![]()
Doubao Charges Fees: Zhang Yiming Helps Zhang Xiaolong Explore the Path