How Does the Pixel Count of Autonomous Driving Cameras Affect Computational Power?
 03/26 2026
03/26 2026
 564
564
Previously, we discussed how the number of laser radar beams affects computational power (related reading: Why Do High-Beam Laser Radars Consume Less Computational Power?). As another critical perception hardware in autonomous driving, does the pixel count of cameras affect computational power consumption?
In fact, from the early 1.2-megapixel (1.2MP) cameras to today's mainstream 8MP cameras, and even higher resolutions, the increase in pixels directly determines how far and how clearly the vehicle can 'see.' Unlike laser radars, the increase in camera pixels imposes stricter requirements on the vehicle's computational power platform. These requirements are not only reflected in the throughput of raw data but also in the complexity of backend neural network inference, the processing pressure on the Image Signal Processor (ISP), and the occupation of memory bandwidth.
The Chain Reaction of Image Signal Processing and Physical Throughput
Cameras are crucial in autonomous driving primarily because of their excellent ability to capture semantic information such as textures, colors, and traffic signs, which is difficult for laser radars and millimeter-wave radars to achieve. As autonomous driving advances from L2 to L4/L5, the system needs to identify smaller objects at greater distances, driving the evolution of cameras from low to high resolution.
The direct advantage of high-pixel cameras is higher pixel density, meaning that within the same field of view, distant objects receive more pixels, thereby improving the accuracy of deep learning models in classifying and detecting these objects.
Besides performance improvements, the increase in pixels also brings significant data throughput pressures. Each frame captured by the image sensor is essentially a collection of massive electrical signals. For example, an 8MP camera operating at 60 frames per second (fps) generates 480 million data points per second. In an autonomous driving perception system, a vehicle may be equipped with 11 or more cameras, meaning that thousands of gigabytes (GB) of raw image signals flood the computing platform every second.
This magnitude of data flow first impacts the Image Signal Processor (ISP). The ISP is responsible for converting the 'raw data' captured by the sensor into a machine-understandable format, involving a series of complex mathematical operations such as denoising, color correction, and dynamic range compression.
The higher the pixel count, the more pixels the ISP must process per unit time. Although the ISP is a highly integrated hardware module, its power consumption and heat generation still increase linearly with processing load. To address this challenge, automotive chip architectures are transitioning from discrete ISPs to integrated System-on-Chips (SoCs). Integrating ISP functions into the main computational chip can significantly reduce the delay and power consumption of image data transmission between different onboard components.
Even so, the 'data movement cost' brought by high resolution remains expensive. Within the autonomous driving computing unit, each migration of data from the interface to memory and then to the processor core consumes microjoules of energy. At the scale of hundreds of millions of pixels, these minor energy consumptions accumulate, forming a significant amount of system auxiliary power consumption.
Memory bandwidth is another critical indicator closely related to pixels. When high-pixel image data is cached into memory for the AI engine to read, it occupies a large amount of high-speed memory resources such as LPDDR5. If the bandwidth is insufficient, image processing may experience frame drops or delays, which is extremely dangerous in high-speed driving scenarios.
From Local Features to Global Attention Computation
What truly makes high-pixel cameras significant consumers of computational power is the backend deep learning inference process. Currently, mainstream autonomous driving perception algorithms are mostly based on Convolutional Neural Networks (CNNs) or Visual Transformers (Transformers). In these models, computational complexity is positively correlated with the resolution of the input image, and in some advanced attention mechanism architectures, the growth in computational load is even a square relationship with the number of pixels.
Under the CNN architecture, the neural network extracts features by sliding 'convolutional kernels' over the image. When the image resolution increases from 2MP to 8MP, the size of the feature map also expands, meaning that the number of convolutional operations increases fourfold.
Although feature maps can be compressed using techniques like stride skipping or pooling, doing so sacrifices the ability to detect small objects brought by high pixels, thereby negating the original intention (original intention) of upgrading the sensor.
For more advanced Transformer architectures, they need to calculate the correlations between different regions of the image. This 'global attention mechanism' generates extremely large correlation matrices when processing images with millions of pixels, imposing significant concurrent pressure on the Arithmetic Logic Units (ALUs) of the computational chips.
The following table compares the computational requirements (measured in FLOPs) of typical visual perception models under different input resolutions:
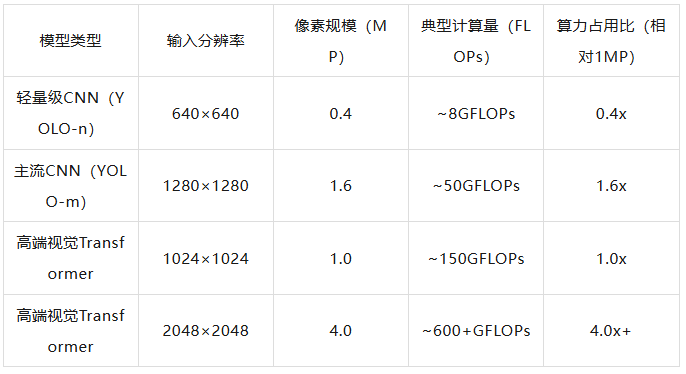
It can be seen that as the resolution increases, the number of floating-point operations that the AI chip needs to perform per second rises rapidly. To achieve this high performance within a limited chip area, chips like NVIDIA Orin or Tesla FSD must integrate thousands of cores, directly leading to an increase in SoC power consumption.
Additionally, to train models capable of processing high pixels, the computational power requirements for cloud training also grow exponentially. If you hope to increase resolution without adding latency, you must find more efficient operators or adopt model quantization techniques, but this essentially uses algorithmic refinement to offset the resource deficit brought by pixel growth.
Autonomous driving perception involves not only detecting obstacles but also semantic segmentation, which means assigning 'attribute labels' (road surface, sidewalk, trees, sky) to every pixel in the image. In high-pixel mode, this pixel-level classification task can trap the computational platform in endless calculations.
Currently, the industry's response strategy is to adopt 'non-uniform sampling' or 'multi-scale fusion,' which means using high resolution for fine recognition in the center of the field of view and low resolution in peripheral or unimportant areas like the sky, thereby balancing accuracy and computational power.
Why Can Laser Radar Reduce the Burden While Cameras Only Increase It?
Laser radar directly obtains three-dimensional spatial coordinates by emitting laser beams and measuring the echo time. The more beams a laser radar has, the denser the point cloud will be. For backend algorithms, a denser point cloud means clearer object contours, and the algorithm no longer needs to expend significant computational power to guess the object's distance or size. It only needs simple clustering and geometric segmentation to complete the perception task. Therefore, to some extent, laser radar uses the expense of hardware and the density of data to simplify perception logic.
The situation with cameras is precisely the opposite. As a passive sensor, a camera captures the projection of the three-dimensional world onto a two-dimensional plane. Even if the pixel count reaches 8MP or higher, it still lacks direct depth information. The perception system must use complex neural networks to infer three-dimensional information based on the object's texture, shadows, overlapping relationships, or binocular disparity.
This means that an increase in camera pixels only provides richer 'guessing material' rather than 'ready-made answers.' To process these richer details, the algorithm requires deeper network layers and more complex logic, thereby driving up overall computational power consumption.
This difference determines the marginal benefits of computational power for the two sensors. The increase in laser radar beams can effectively reduce the difficulty of algorithm blind spot filling and error correction after crossing a certain threshold, and may even reduce the complexity of backend fusion algorithms.
In contrast, the increase in camera pixels is more like an endless 'computational race,' because the more pixels there are, the greater the amount of potentially parsable information, and the system must continuously invest more computational power to dig deeper to avoid wasting this information.
This also explains why companies like Tesla, which adhere to a 'pure vision' route, must continuously upgrade their onboard computers (e.g., from HW3 to HW4, and then to the planned HW5). Because the pure vision scheme places all environmental understanding pressure on neural networks, and higher pixels are the only way to improve perception and recognition distance.
To obtain a longer braking reaction distance, the system must see farther pixels, and to see farther pixels, the system must have a more powerful brain capable of processing this massive data.
How to Solve the Problem?
To address the aforementioned issues, the autonomous driving field is actively exploring more intelligent resource management strategies. One of the most mature schemes is the 'Region of Interest (ROI)' strategy. Similar to how human drivers focus on the rearview mirror and directly ahead while driving, ignoring irrelevant backgrounds, autonomous driving perception algorithms can also dynamically assign computational weights to different regions in the image.
In practical applications, the system can first use a lightweight small model to scan a large image for 'candidate boxes' where vehicles or pedestrians may exist, and then call high-pixel data for fine recognition in these specific regions. This method not only retains the advantage of long-distance recognition brought by high pixels but also avoids redundant operations when processing entire high-pixel images.
Another direction is the application of event-based cameras. Unlike traditional cameras that output images at a fixed frame rate regardless of whether the scene (scene) changes, event-based cameras only output pixels where light intensity changes.
This means that if the scene remains static, the sensor's output is almost zero; when an object quickly passes by, it can capture edge information with microsecond-level response speed. This perception mode based on 'changes' naturally achieves data sparsity, reducing the computational power consumption of backend processors by several orders of magnitude.
Currently, some technical schemes are attempting to fuse traditional high-pixel cameras with high-frame-rate event-based cameras, using the former to provide static semantics and the latter to provide dynamic capture, thereby enhancing system safety in extreme dynamic scenarios without increasing total bandwidth.
The evolution of hardware architectures is also alleviating pixel pressure from the bottom layer. In traditional computing architectures, image data needs to travel a long path from the sensor to the CPU or GPU for processing, resulting in extremely high energy consumption for data movement. Emerging 'perception-memory-computing integration' technologies attempt to integrate computational logic directly into the peripheral circuits of image sensors or even perform basic convolutional operations directly within memory chips.
By filtering out invalid pixels or completing basic denoising and scaling at the source of data generation, the burden on the main SoC can be significantly reduced. This shift from 'brute-force computing' to 'refined perception' also represents the future trend of autonomous driving perception.
Final Words
The increase in camera pixels in autonomous driving indeed has a significant driving effect on computational power consumption. This is not only because of the simple doubling of data volume but also because richer visual information induces more complex algorithmic mining. Although the increase in laser radar beams can somewhat 'simplify' perception logic, the evolution of camera pixels is always accompanied by the extreme exploitation of computational power.
-- END --
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
Why Is Nokia Making a Comeback in the AI Era?