NVIDIA Alpamayo: A Comprehensive Analysis of Inference-Based Autonomous Driving Large Model Design and Mass Production Deployment
 03/26 2026
03/26 2026
 601
601
At GTC 2026, NVIDIA further elaborated on its open-source Alpamayo VLA model. Marco Pavone, representing NVIDIA's research team, shared insights into Alpamayo's model design and the latest causal chains. Patrick Liu, a former subordinate of Xinzhou Wu at Xpeng who later joined NVIDIA, represented the mass production side and shared some experience and methods for deploying Alpamayo in mass production.
Based on the speech content (Note: ' speech content ' is kept as is since it seems to be a reference to the actual content of the speeches and may not have a direct English equivalent; in context, it could be translated as 'content of the speeches' but is left here for clarity) of the two speakers, this article summarizes and shares Alpamayo's model design and mass production experience.
In our previous article, 'The Battle for Intelligent Driving Standardization: Understanding the Underlying Logic and Architectural Evolution of 'End-to-End' Autonomous Driving,' we also shared how, in the development of autonomous driving, enabling AI not only to 'see' and 'drive' but also to 'think' and 'explain' like humans represents the second breakthrough point after the widespread adoption of end-to-end algorithms.
The highlight of NVIDIA's Alpamayo is its reasoning capability. During the presentation, Marco Pavone stated that Alpamayo is a 10 billion (10B) parameter end-to-end, inference-based Vision-Language-Action (VLA) model built upon NVIDIA's foundational model, Cosmos Reason.

Part 1: Model Design - Enabling AI to Learn 'Causal Reasoning' and 'Alignment of Knowledge and Action'
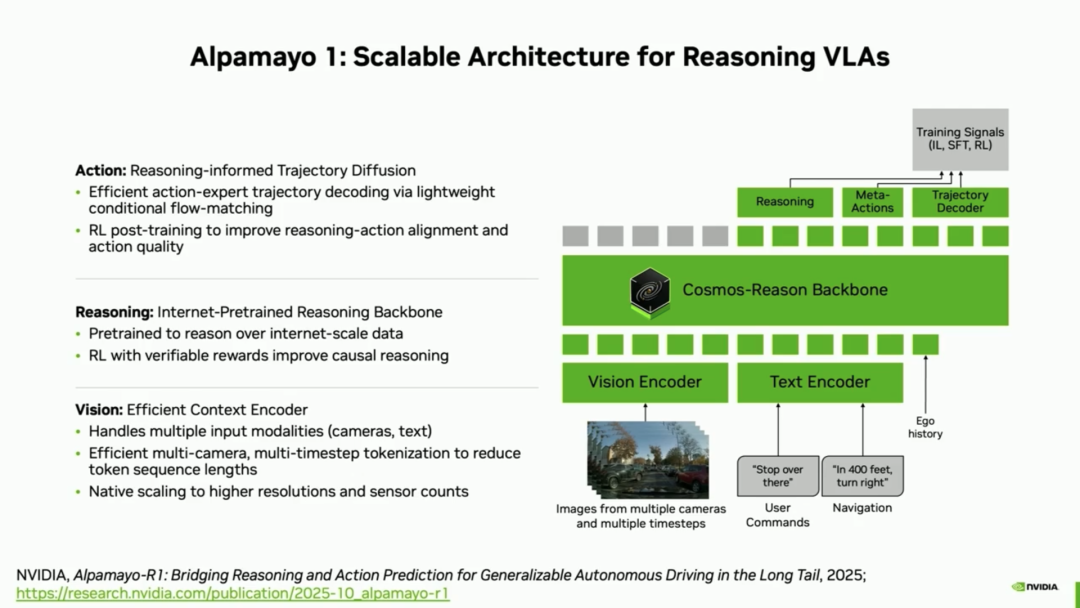
Similar to all VLA models, Alpamayo 1 receives multi-camera images, user commands, and navigation guidance, and outputs three key results: reasoning trajectories, meta-actions, and driving trajectories.
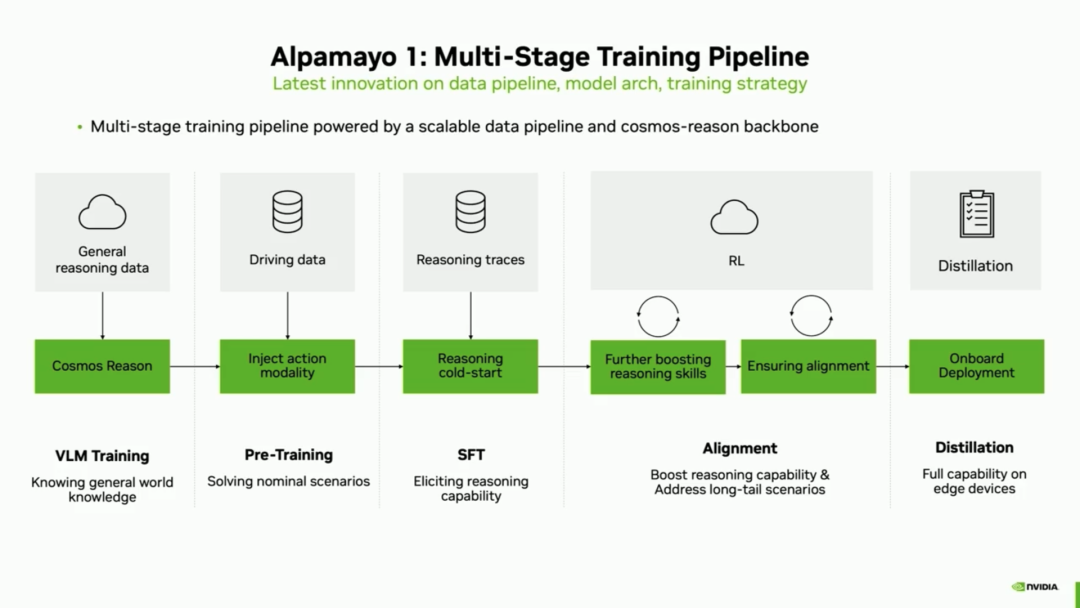
The first major highlight of this model's algorithm is 'concrete reasoning'—generating trajectories similar to human reasoning by linking spatial understanding and common-sense reasoning with physical actions. To build this 'concrete reasoning' capability, NVIDIA's Alpamayo adopts a multi-stage training pipeline:
General Reasoning: Starting with Cosmos Reason, general reasoning capabilities are trained using internet-scale data. This falls under the category of foundational model training.
Trajectory Pre-training: Pre-training on massive driving data endows the model with trajectory generation capabilities for autonomous driving. Generally, the first step in training from a general foundational model to a specialized autonomous driving model involves dedicated driving data training.
Supervised Fine-Tuning (SFT): Fine-tuning is performed using automatically annotated driving-related reasoning trajectories to elicit explicit reasoning capabilities. This step primarily imparts the VLA model's ability for language-based explicit reasoning.
Reinforcement Learning (RL): Based on RL in scenarios produced and modified by Cosmos, reasoning in highly challenging situations is improved, and alignment between various output modalities is facilitated.
After these steps, a VLA large model is essentially complete, as detailed in our previous article, 'Xinzhou Wu Leads NVIDIA's Charge Towards L4 Autonomous Driving with VLA Large Model Algorithms.'
Finally, knowledge distillation is employed for model deployment in vehicles: compressing vast capabilities into a model suitable for on-vehicle deployment.
The entire training process presents the following challenges:
1. Overcoming the Limitations of Pure Text Chain-of-Thought (COT) Automatic Annotation: Automatic annotation of causal chains in the SFT stage faces the significant challenge of generating high-quality reasoning labels on a large scale. Traditional text chain-of-thought (COT) automatic annotation suffers from three fatal flaws:
- Causal confusion: Reasoning trajectories may leak future information, such as prematurely stating, 'The silver SUV will cut in later.'
- Vague behavioral descriptions: Unable to provide specific driving operations.
- Superficial reasoning: Descriptions lack context directly causally linked to the vehicle's behavior.
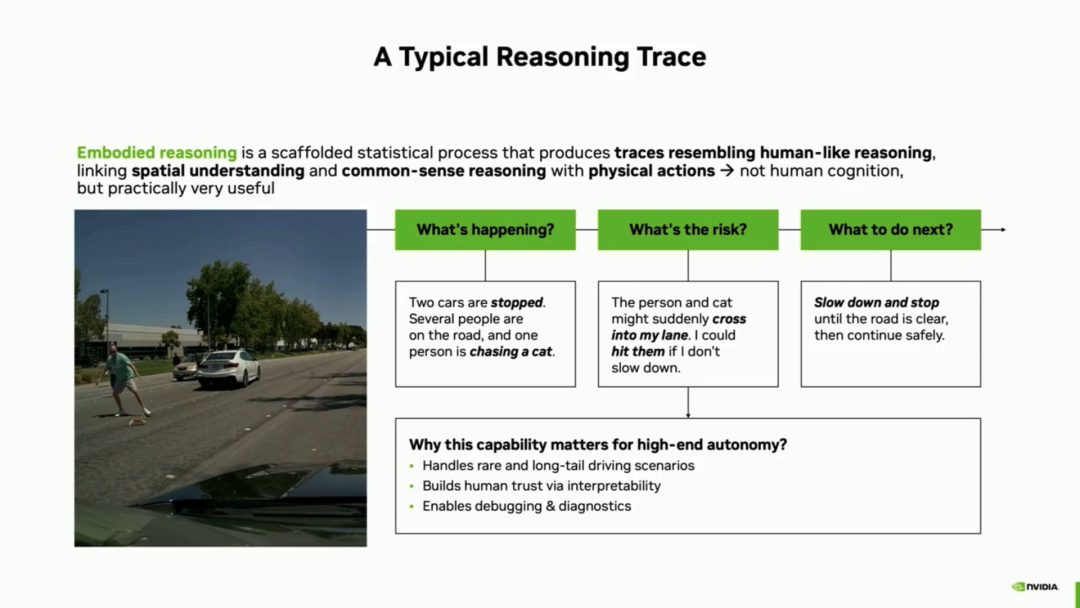

To address these issues, NVIDIA adopts a 'causal chain automatic annotation pipeline' to overcome this pain point:
- Anchoring Key Frames: Reasoning generation is strictly anchored at critical decision-making moments (e.g., the instant a traffic light turns green), ensuring the reasoning process only includes factors preceding the key frame and eliminate (Note: ' eliminate ' means 'prevents'; here it is translated as 'prevents' to convey the meaning) future information leakage.
- Closed Decision Vocabulary: Decisions are categorized into longitudinal and lateral types, and a clear vocabulary is established to ensure precise terminology describes behaviors, eliminating ambiguity.
- Causal Chain Templates: Models are guided to ensure each statement conforms to causal chain logic, preventing superficial reasoning.
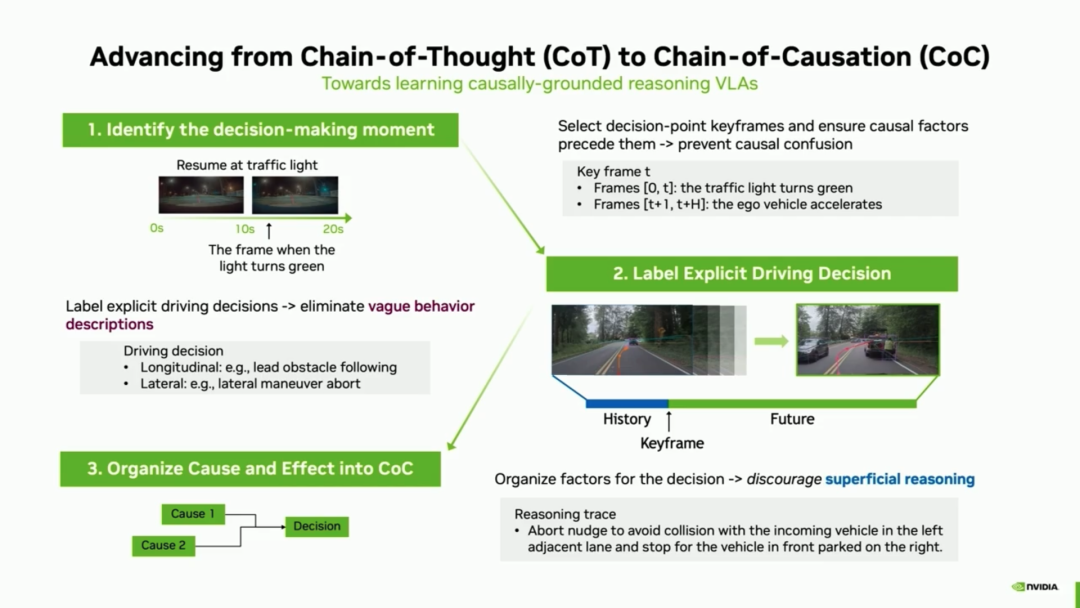
NVIDIA's Marco Pavone stated that by switching from unstructured chain-of-thought to structured causal chains, explicit reasoning achieved a staggering 121% improvement in accuracy. When handling 'long-tail scenarios' capturing complex motion behaviors and out-of-distribution visual contexts, the model reduced trajectory displacement (average ADE) by approximately 12%, demonstrating significant benefits of reasoning in complex edge scenarios.
2. Eliminating 'Embodiment Inconsistency': After reinforcement learning post-training alignment, the model can reason, but what if 'it thinks left but drives right'? This potential discrepancy between chain-of-thought reasoning and the model's directly outputted actions is known as 'embodiment inconsistency' (since action generation often merely mimics training data without truly understanding the underlying reasons).
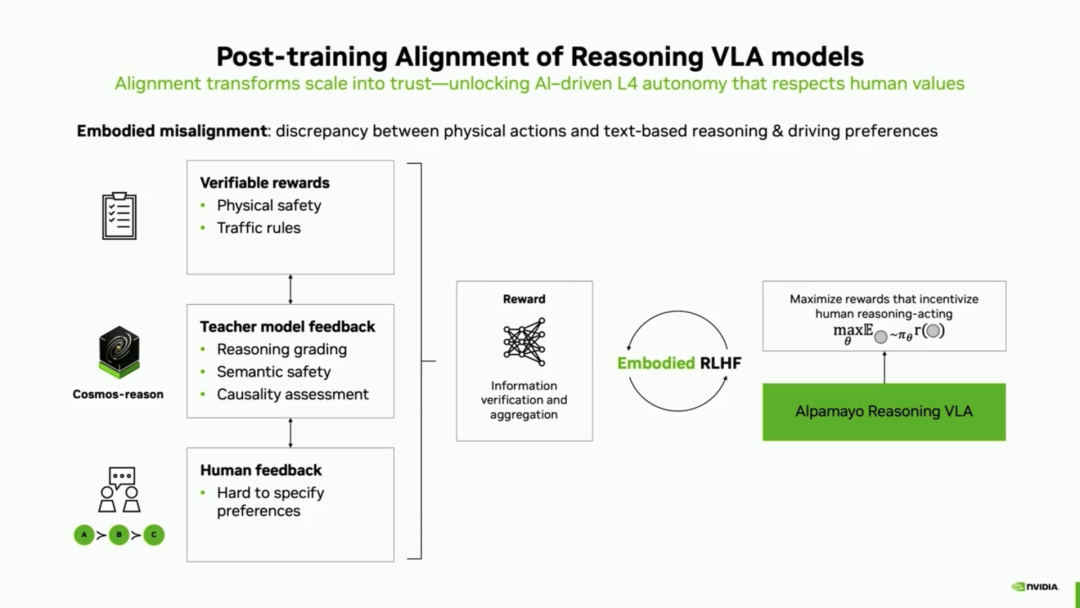
To address this, the team introduced reinforcement learning (RL), integrating verifiable safety rewards, teacher model feedback, and human preference aggregation into a unified reward model. After alignment, the model's generated actions became more consistent with the corresponding reasoning trajectories, reducing unfaithful actions by nearly 60%. For example, when the model inferred the need to decelerate, stop, and then accelerate, the aligned model strictly followed the complete causal sequence while significantly reducing near-collision rates. 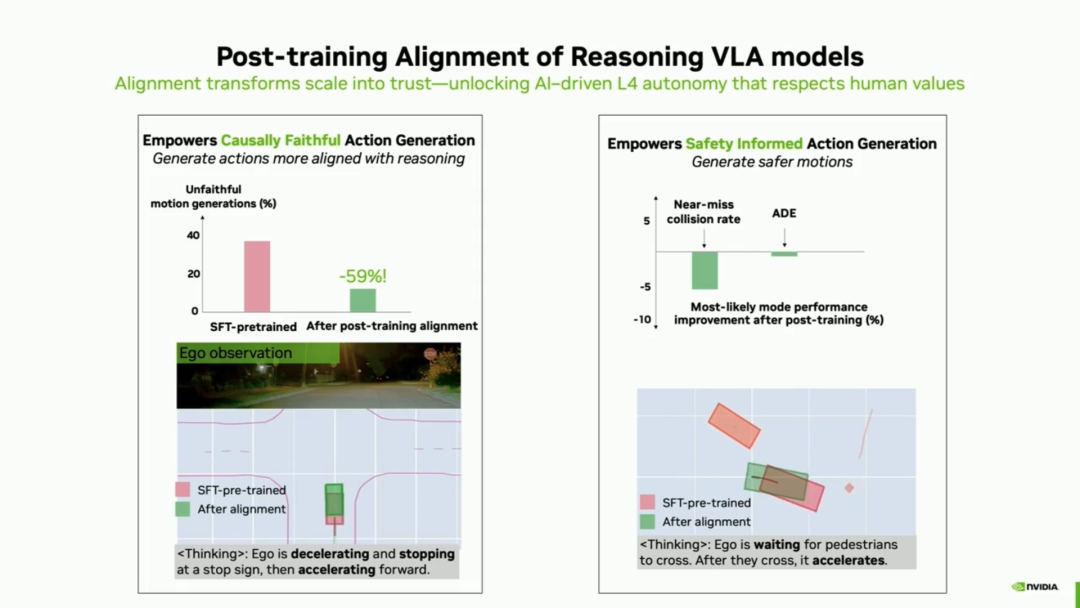
3. Cutting-Edge Exploration: From Text Reasoning to 'Latent Space Reasoning' While language text is easy to interpret, it is not the most efficient representation in terms of token count and reasoning time. Here, it is pointed out that the 'L' in VLA is truly token-intensive, posing a challenge for real-world engineering deployment of VLA models. NVIDIA is exploring reasoning in continuous latent spaces. This not only brings 2 to 4 times reasoning acceleration but also makes post-training optimization smoother. In complex partially observable scenarios (e.g., responding to pedestrians who may cross the road at any time), the model even demonstrates counterfactual reasoning and self-regulating 'thinking rate' capabilities—the harder the scenario, the more time it spends deducing and updating, achieving better driving performance. 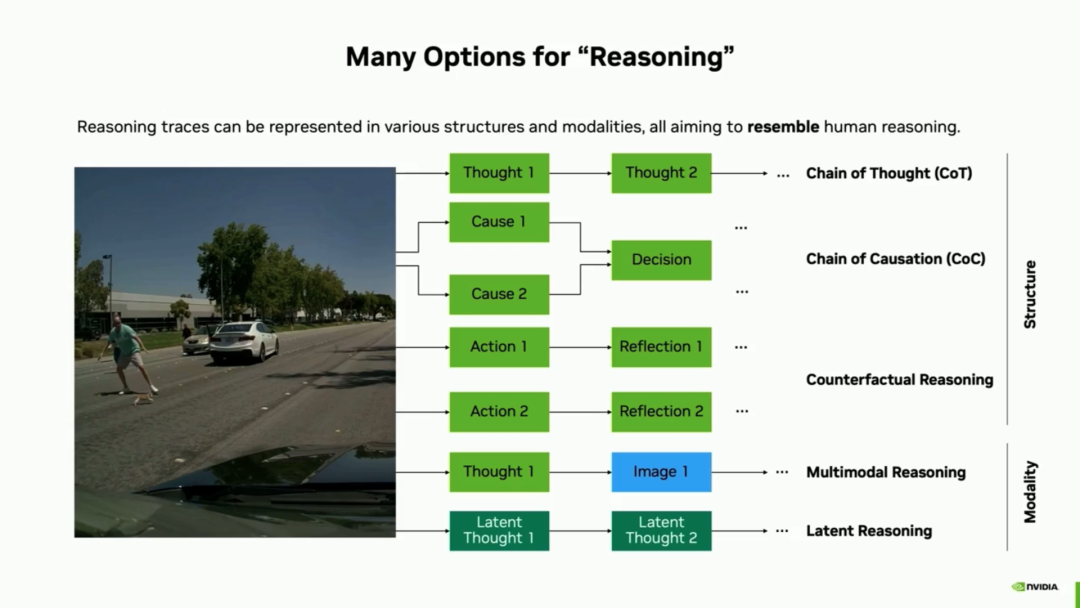
This represents an implicit reasoning method, sometimes referred to as a world model. Li Auto also shared in their GTC 2026 presentation that their next-generation MindVLA will adopt this approach, as detailed in our article, 'Analysis of the Architecture and Algorithm Applications of Li Auto's Next-Generation Foundational Model, Mind VLA-o1.'
Part 2: Mass Production Deployment - Overcoming Physical Bottlenecks in Interaction and Real-Time Computing
In reality, deploying such a powerful research-grade reasoning model into actual vehicle production requires overcoming three pillar challenges: system interaction, data quality, and extremely high real-time requirements, given the computational constraints at the vehicle end.
How to address these challenges in mass production? NVIDIA's Patrick Liu provided their answers to these questions:
1. Multi-Task Product Functionality and 'Mode Expert' Architecture To achieve an L4-level experience that combines autonomous driving with interactivity and explainability, the mass production model introduces two additional modes beyond autonomous reasoning:
User Q&A Mode: Adds a natural language interface to the black-box neural network, allowing users to ask questions like 'What are you doing?' or 'Why are you slowing down?', greatly enhancing trust.
User Control Mode: Users can directly issue commands such as 'Pull over,' 'Take the next exit,' or 'Speed up a bit.'
To support these three modes, a core module—the Mode Expert—is introduced at the system level. It undertakes two major responsibilities:
- Protective Interception: If a user issues a harmful command (e.g., 'Hit that trash can'), the Mode Expert proactively rejects it without passing it to the model.
- Seamless Routing: It encodes the decision on which mode to execute as an 'extremely tiny single-modality token' forcibly input to the model.
This MOE design avoids delays caused by generating additional tokens and allows the model to override the original navigation route if necessary to comply with user control commands. The MOE approach has proven its efficiency under equivalent computational power over the past two years, as demonstrated by Deepseek.

2. Production-Grade Data Pipeline To generate high-quality, highly consistent 'C datasets,' the R&D team spent over 100 iterations balancing complex data hybrid structures between the cloud and vehicle ends. In addition to relying on Vision-Language Models (VLMs) and classical behavioral planning stacks for automatic labeling and using rule filters to clean data, the entire pipeline must incorporate 'Human-in-the-loop QA' to rigorously verify the accuracy and authenticity of all labels.
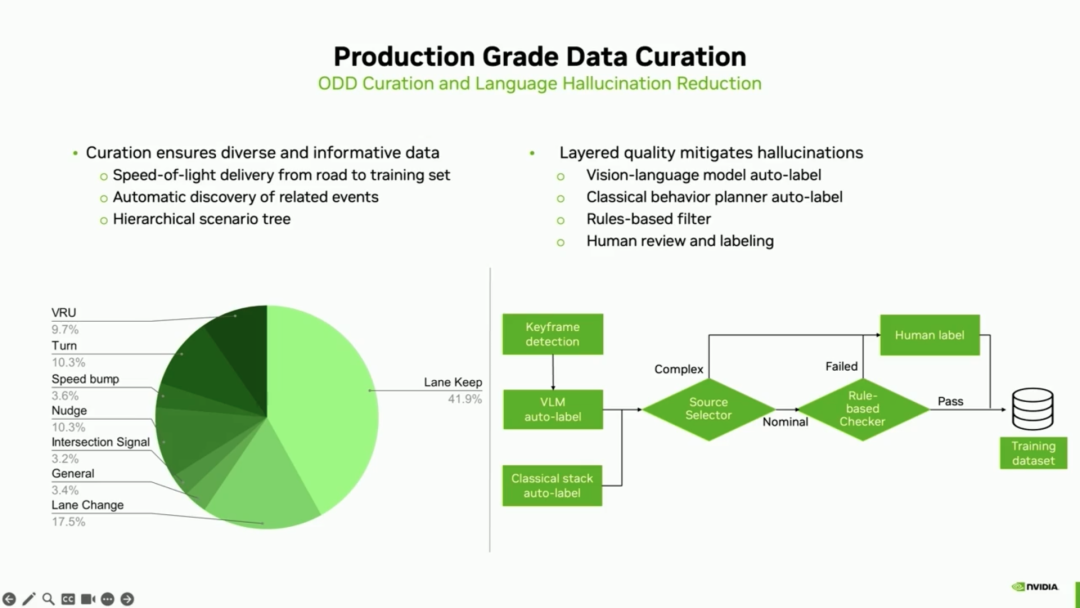
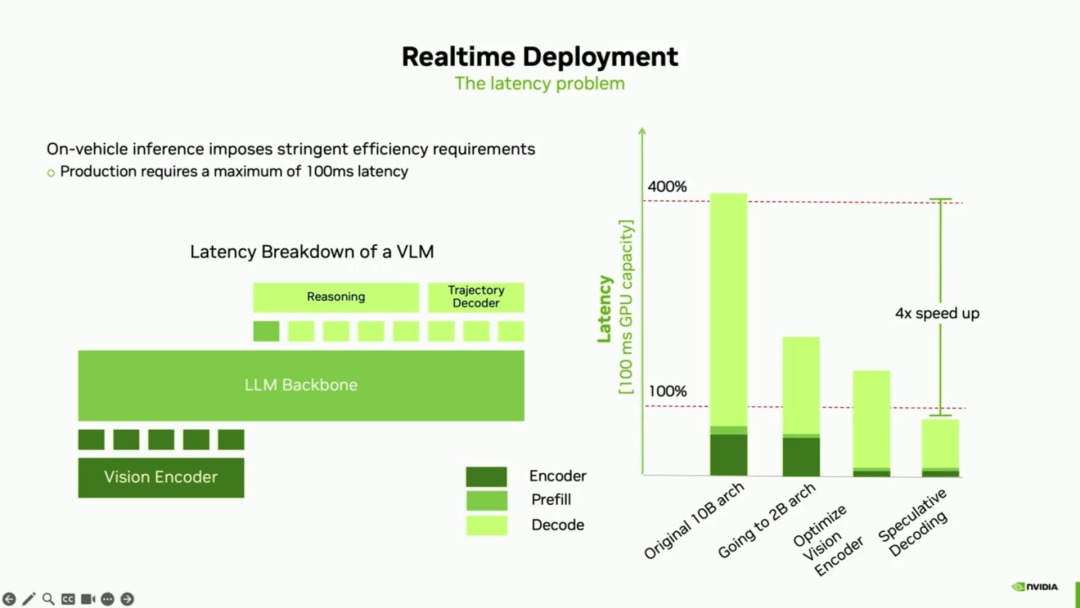
3. Real-Time Deployment: Hardcore 4x Real-Time Acceleration Technology This is the most critical aspect of mass production. The replanning budget at the vehicle end is 100 milliseconds (i.e., 10 fps), while the original unoptimized model latency exceeded the budget by approximately 4 times. To generate all reasoning and trajectory tokens within the stringent budget, the team adopted a dual-pronged technical breakthrough:
Language Side (Speculative Decoding): Speculative decoding technology is applied to large language models. A small 'draft model' quickly generates possible tokens, which are then validated in parallel by the main model. Since validating parallel tokens is much faster than direct generation, this achieves 2 to 4 times acceleration.
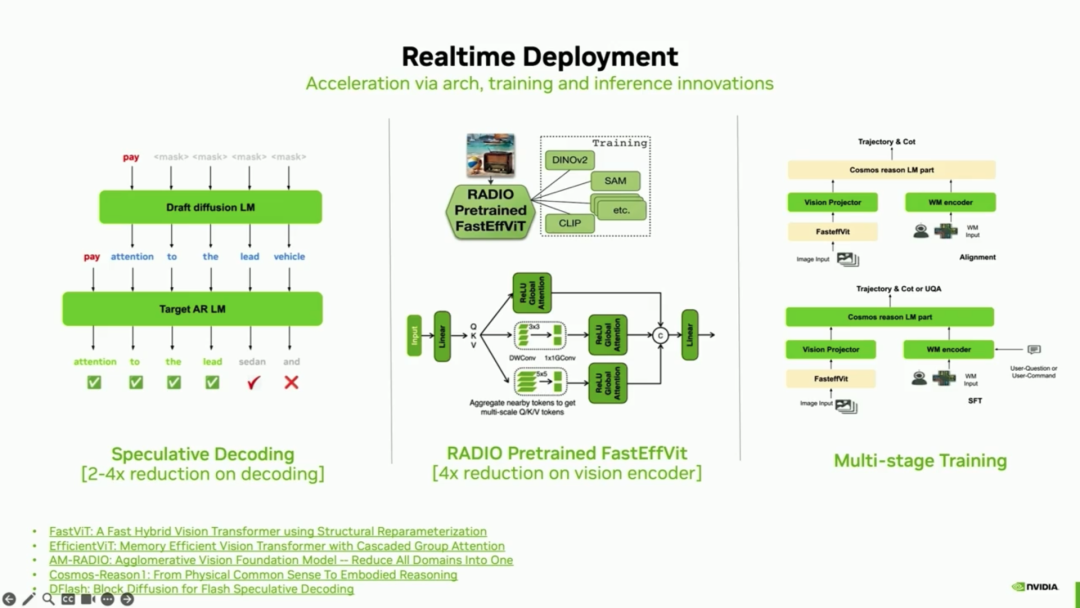
Vision Side (Sparse Attention and Custom Pre-training): Dense attention mechanisms are decomposed into multi-layer sparse attention, achieving approximately four times acceleration in visual processing. However, this architectural change prevents direct use of pre-trained dense models like Dinov2. The team used a custom pre-training pipeline (e.g., Nvidia's Radio) to train fast visual models specifically adapted to the new architecture.",
Combining the aforementioned foundational restructuring for model design and extreme engineering optimizations for mass production deployment, NVIDIA has successfully brought Alpamayo 1 from cutting-edge research into real-world automotive production deployment.
Finally, NVIDIA announced the release of the new Alpamayo 1.5 model at GTC 2026.

The newly released Alpamayo 1.5 model, while maintaining its original scale of 10 billion parameters, primarily adds new functionalities where navigation and language dialogue can control assisted driving. This is quite a challenging feat. In addition to these enhancements, the publicly available model also includes specialized virtual simulation suites and the aforementioned datasets such as CoC auto-labeling and inference labels.
The integration of these new features further enhances the model's flexibility and controllability in practical applications, making it akin to a public L4 Android software. It can assist many traditional OEMs in initiating self-research modes, similar to how many internet companies have embarked on their journeys.
Finally, while algorithms are crucial tools for autonomous driving, autonomous driving products are where the deepest interaction with application scenarios occurs. Friends interested in autonomous driving products can click on the book Autonomous Driving Product Manager, co-published by Vehicle and Mechanical Industry Press, which provides a detailed introduction to the entire process of autonomous driving products and operations.
References and Images
From Research to Production: How Alpamayo Accelerates Autonomous Vehicle Development - NVIDIA *Reproduction or excerpting without permission is strictly prohibited-
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
Why Is Nokia Making a Comeback in the AI Era?