What Impact Does Data Annotation Accuracy Have on Autonomous Driving?
 10/31 2025
10/31 2025
 491
491
When discussing autonomous driving models, the spotlight often falls on the algorithms and architectures they employ. However, the data used to train these models tends to be overlooked. In reality, for a model to attain 'intelligence,' it must be continuously fed with data for learning. Yet, this data isn't ready for use straight away; it first requires 'annotation,' either manually or semi-automatically. This process entails instructing the model on what it needs to learn.
Annotation involves transforming raw information gathered by sensors—such as images, point clouds, radar echoes, or video frames—into labels that the model can comprehend. In a traffic scene dataset, vehicles can be outlined with 3D bounding boxes, lane lines can be delineated with polylines, and the actions of pedestrians (standing, walking, or running) can be marked. Data annotation is, in essence, a process-oriented task. However, if the annotations are inaccurate, inconsistent, or incomplete, even the most exceptional model will be 'fed with confusing information.' This can ultimately directly affect the vehicle's performance in real-world driving conditions and even pose safety hazards.
What Does 'Accuracy' Mean in Annotation?
Data annotation goes beyond simply selecting content within a frame; it actually encompasses multiple dimensions of consideration. At the semantic level, it's crucial to ensure that the labels correctly identify the object categories. For instance, if an electric scooter in an image is mistakenly labeled as a 'bicycle,' it could lead to subsequent misjudgments. At the geometric level, considerations include the precision of the target's position, orientation, and size. A slight offset of a few centimeters in the center point of a 3D bounding box or errors in the boundaries can impact the model's tracking and distance estimation capabilities. Time consistency requirements are evident in videos or continuous point clouds, where the same target must maintain a consistent ID and trajectory across different frames. This is vital for the accuracy of behavior prediction. Boundary precision is reflected in whether semantic segmentation models can accurately identify component details, such as car windows, bodies, and reflective strips. This directly determines the perception module's accuracy in recognizing object contours.

Confirmation of Autonomous Driving Data Annotation Labels. Image Source: Internet
In summary, the 'accuracy' of data annotation refers to the extent to which all dimensions achieve a high, stable, and consistent level of quality. 'Annotation noise,' which denotes errors or uncertainties in the labels, can also infiltrate the training process and hinder the model's learning effectiveness.
What Issues Can Arise in Data Annotation?
One of the most prevalent and subtle issues in the data annotation process is poor annotation consistency. Inconsistencies in data annotation may stem from different annotators' varying interpretations of the standards or from differences in the tools or templates used. Minor deviations during annotation can accumulate across a vast number of training samples, causing the model to learn an 'averaged' annotation style. This can result in poor performance in boundary scenarios. For example, if different annotators handle the bounding boxes of partially occluded vehicles differently, the model is likely to make positioning errors or miss detections when encountering occlusions.
In real-world road data, the distribution of common and rare category scenarios is often imbalanced. Data on ordinary vehicles and pedestrians is abundant, but critical yet rare traffic participants, such as children, disabled individuals with mobility impairments, construction vehicles, and emergency vehicles, are seldom encountered. If the annotation quality for these important but rare categories is low and the sample size is insufficient, the model will struggle to accurately identify them in real-world scenarios. These types of errors often go undetected by overall metrics like accuracy and recall because the model may perform excellently in 99% of scenarios but make misjudgments in the critical 1%, which could be the trigger for serious accidents.
Incorrect time annotations can also prevent the prediction model from learning continuous motion patterns, leading to prediction failures at intersections or in complex scenarios. This, in turn, can cause dangerous decisions by the decision-making module. Geometric annotation deviations are particularly significant for autonomous parking and low-speed precision maneuvers, where errors of just a few centimeters can result in scrapes or an inability to park accurately in a space.

Autonomous Driving Data Annotation. Image Source: Internet
Semantic ambiguity in data annotation is also a noteworthy issue. Certain objects can be challenging to classify in boundary situations, such as folded handcarts, temporarily parked motorcycles, or large items being carried by people. Different annotators may make different judgments in these scenarios. If unified standards are not established for these edge cases, the model will struggle to make reasonable judgments in real-world driving conditions.
What Impact Can Inaccurate Annotations Have on Autonomous Driving Systems?
Object detection and semantic segmentation models heavily rely on accurate spatial and obstacle category information. If systematic biases exist in the positions of 3D bounding boxes during training, the model will learn incorrect localization strategies. This can lead to errors in distance estimation and inaccurate brake point judgments in real-world applications. Incorrect category annotations may cause the model to misjudge dangerous objects as static obstacles and incorrectly predict their behavior. Blurry boundaries in semantic segmentation can result in unstable recognition of lane lines or curbs, thereby affecting vehicle localization and path planning.
If data annotations are inaccurate, the tracking and prediction modules will also be significantly affected. Trackers rely on stable detection results in each frame to maintain target IDs and speed information. If the annotations are inconsistent over time, the model's learned trajectories will appear 'fragmented.' This greatly reduces the accuracy of inferring the target's future motion in dense traffic scenarios. The prediction module relies even more on behavior labels and historical trajectories; annotation errors can hinder the model's ability to learn typical interaction patterns, leading to unreasonable decisions by the vehicle in complex driving conditions.
The planning and control modules can also encounter issues due to inaccurate data annotations. Planners typically formulate the vehicle's next actions based on spatial information and predicted trajectories from perception outputs. If the obstacle positions provided by perception are inaccurate or the predicted speeds are unreliable, the planner may generate overly aggressive or conservative driving trajectories. The control module will then frequently adjust due to unstable reference trajectories, causing the vehicle to exhibit jerky braking or steering maneuvers.

Image Source: Internet
In autonomous driving systems, the model's uncertainty is also considered a key basis for decision-making. If annotation issues cause the model to handle certain scenarios very smoothly during the training stage, it may fail to correctly identify uncertain scenarios in real-world applications. This makes it difficult to trigger necessary safety downgrade mechanisms, such as slowing down or requesting human intervention, thereby posing potential risks.
How Can Annotation Quality Be Improved?
To avoid the issues mentioned above during the data annotation process, the first step is to establish clear and explicit standards. Mature annotation projects require a detailed and operable set of annotation specifications that cover category definitions, boundary handling rules, occlusion processing methods, minimum visible pixel thresholds, and inter-frame ID maintenance rules. After the specifications are established, continuous training and iteration must be conducted to ensure implementation. Annotators need to learn through examples and undergo assessment and retraining mechanisms to ensure a consistent understanding of details.
The use of tools and process optimization are also crucial for improving annotation quality. Efficient annotation tools are the cornerstone of ensuring data quality, as they can reduce human errors by enforcing formats and rules. A human-machine collaborative model of 'automatic pre-annotation + manual correction' can be adopted to improve efficiency, allowing annotators to focus on processing complex samples. Additionally, a series of tool functions and process management measures, such as version control, label review, batch repair, and difference highlighting, are key to enhancing overall annotation quality.
To improve annotation quality, it is also necessary to establish a multi-dimensional quality control mechanism. Improving data annotation quality should not rely solely on individual sample inspections; instead, processes such as cross-review, double-blind verification, and statistical testing should be integrated. Cross-review helps identify subjective differences among annotators; double-blind verification effectively assesses the consistency of annotation results; and statistical testing monitors overall data anomalies. For example, when the annotated sizes of certain objects significantly deviate from historical norms or when an annotator's error rate rises sharply, it automatically triggers a review process.
Data annotation is an ongoing optimization process that requires the construction of a closed-loop data framework from 'annotation' to 'training,' 'validation,' and 'regression.' Technologies such as active learning or uncertainty sampling can be used to screen out the samples that the model is most uncertain about or is most prone to errors, prioritizing them for manual annotation. This efficiently utilizes resources to enhance model performance. All issues discovered during the annotation process should be promptly fed back to the development team and used as important references for iterating the model or updating the annotation specifications.
Effective measurement and monitoring are also key to ensuring annotation quality. Relying solely on overall metrics like mAP (mean Average Precision) or IoU (Intersection over Union) is far from sufficient to assess the impact of annotations on actual safety; fine-grained scenario metrics are necessary. For example, the model's false negative rate in foggy or nighttime conditions or its localization errors during close interactions with pedestrians can be specifically monitored. Incorporating these scenario-based metrics into the system's evaluation and release standards can transform abstract 'annotation quality' into specific, monitorable indicators.
Annotation work for 3D data requires even stricter standards. Point cloud data, with its characteristics of sparsity, varying perspectives, and reflections, poses significant challenges for accurately defining bounding boxes. Therefore, it is essential to strictly calibrate coordinate systems and sensor timestamps and ensure annotation consistency to fundamentally avoid spatial deviations. Additionally, annotations related to lane lines and high-definition maps, which directly serve vehicle localization and map construction, have much higher requirements for geometric accuracy and sampling consistency than ordinary detection tasks and thus require special attention.
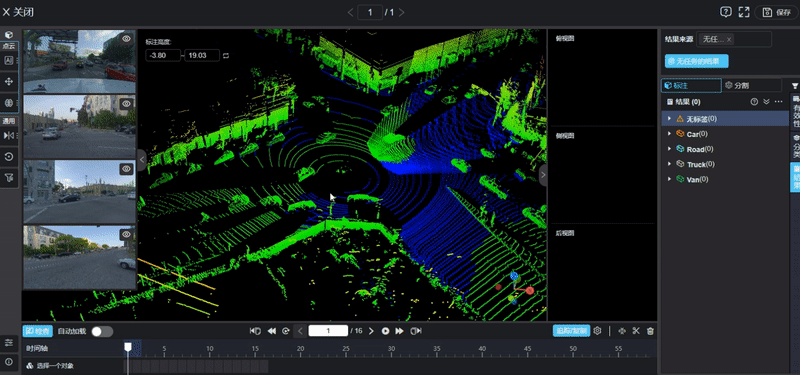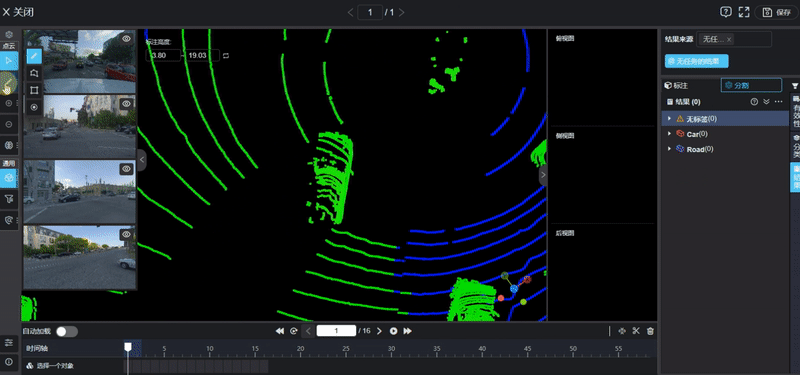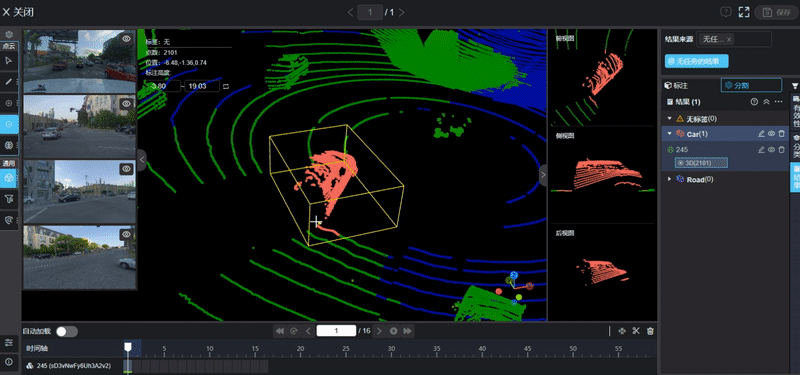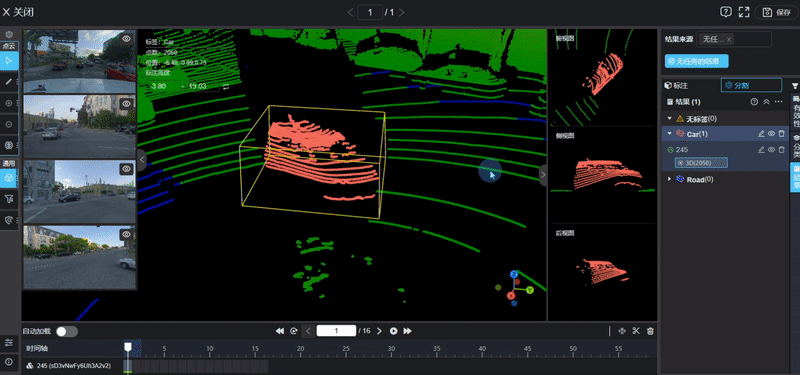
Autonomous Driving 3D Data Annotation. Image Source: Internet
Final Thoughts
Data annotation is not a simple frame selection operation; it is a core task that directly affects the reliability of autonomous driving. Annotation work must be systematized and engineered into a measurable, reproducible, and continuously improvable systematic endeavor. Only in this way can autonomous driving systems acquire the crucial safety foundation needed to navigate complex and ever-changing road conditions.
-- END --
-
![]()
Enflame Tech's IPO Journey: Navigating Over 5.9 Billion Yuan in Losses and Soaring Debt in Q1 This Year
-
![]()
Trillion-Yuan Giant Li Shufu 'Streamlines': Could Levc Be the Casualty?
-
![]()
AI Competes for Electricity and Generates Power in the Gobi Desert
-
![]()
The First Batch of Victims of the AI Bubble: Programmers
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'






