The Live Streaming Revolution is Here! StreamDiffusionV2: 14 Billion Parameters Real-Time Video Soars to 58FPS! Berkeley & Han Song's Team, etc.
 11/12 2025
11/12 2025
 513
513
Interpretation: The AI-Generated Future 

Key Highlights
StreamDiffusionV2 is a training-free streaming system designed specifically for video diffusion models, enabling dynamic, interactive video generation.
It ingeniously integrates innovative components such as an SLO-aware batch scheduler, block scheduler, sink-token-guided rolling KV cache, and a motion-aware noise controller, while introducing a scalable pipeline orchestration mechanism.
This system achieves, for the first time, efficient generation under real-time SLO constraints in a multi-GPU environment, supporting widespread applications from individual creators to enterprise-level platforms. It significantly enhances the timeliness and quality stability of video generation, driving AI-powered live streaming media towards the next generation.
Figure 1. Comparison between batch video generation and streaming video generation. Unlike generating large batches of videos, the goal of real-time streaming video generation is to shorten the "time to first frame" and generate continuous outputs with low latency.
Overview
Effect Demonstration
Note: From top-left to bottom-right: Reference video, StreamDiffusion, Causvid, StreamDiffusionV2
Problems Addressed
While existing video diffusion models excel in offline generation, they struggle to meet the stringent requirements of real-time live streaming media. Specifically, there are four major challenges:
1. Inability to meet real-time SLOs (e.g., minimizing first-frame time and per-frame deadlines);
2. Drift occurring during long-sequence generation, leading to decreased visual consistency;
3. Motion tearing and blurring in high-speed dynamic scenes;
4. Poor multi-GPU scalability, failing to achieve linear FPS improvements in heterogeneous environments.
These issues stem from the bias of existing systems towards offline batch processing optimization, neglecting the infinite input and low-jitter demands of online streaming media. This work fills the gap through system-level optimization.
Proposed Solution
StreamDiffusionV2 is an end-to-end, training-free pipeline that transforms efficient video diffusion models into real-time interactive applications. Its core lies in two layers of optimization: First, real-time scheduling and quality control, including an SLO-aware batch scheduler (dynamically adjusting batch size to meet deadlines), adaptive sink and RoPE refresh (preventing long-sequence drift), and a motion-aware noise scheduler (adapting denoising paths based on motion magnitude); Second, scalable pipeline orchestration, achieving near-linear acceleration across GPUs by parallelizing denoising steps and network stages. Additionally, the system incorporates lightweight optimizations such as DiT block scheduling, Stream-VAE, and asynchronous communication overlap to ensure high utilization and stability in long-sequence streaming.
Applied Technologies
The implementation of StreamDiffusionV2 integrates the following key technologies:
SLO-aware batching scheduler: To maximize GPU utilization while meeting SLOs, the scheduler dynamically adjusts batch size based on the target frame rate and current hardware load. By adjusting the batch size, the system's operating point approaches the "knee point" of the hardware roofline model, maximizing throughput.
Adaptive sink and RoPE refresh: To address drift, the system decides whether to update sink tokens based on the cosine similarity between new block embeddings and the old sink set. Meanwhile, when the frame index exceeds a preset threshold, the RoPE phase is periodically reset to eliminate accumulated positional errors.
Motion-aware noise scheduler: By calculating the L2 norm between consecutive latent frames to estimate motion intensity, the system then uses an exponential moving average (EMA) to smoothly update the noise rate for the current frame based on the normalized motion intensity. This allows for more conservative denoising in high-motion regions and finer denoising in low-motion regions.
Scalable pipeline orchestration: The DiT module is divided across GPUs, with each GPU processing its input as a micro-step and passing the results to the next GPU in a ring structure. This allows multiple stages to execute concurrently, achieving near-linear throughput acceleration.
System-level co-design: It also includes a dynamic DiT block scheduler (dynamically reallocating modules based on real-time latency to balance load), Stream-VAE (a low-latency VAE variant optimized for streaming), and asynchronous communication overlap (using independent CUDA streams to hide inter-GPU communication latency).
Achieved Results
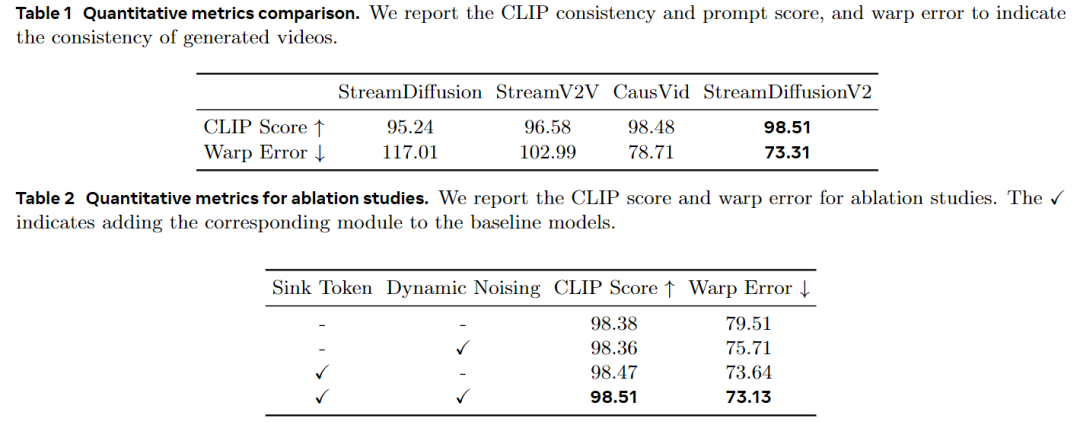
Without TensorRT or quantization, StreamDiffusionV2 achieves first-frame rendering within 0.5 seconds and reaches 58.28 FPS with a 14B parameter model and 64.52 FPS with a 1.3B parameter model on 4 H100 GPUs. Even with increased denoising steps to enhance quality, it maintains 31.62 FPS (14B) and 61.57 FPS (1.3B). The system performs well across different resolutions, denoising steps, and GPU scales, supporting flexible trade-offs between low latency and high quality. It surpasses baselines in metrics such as CLIP score (98.51) and Warp Error (73.31), significantly improving long-sequence consistency and motion handling capabilities.
Methodology
StreamDiffusionV2 is a training-free streaming system that simultaneously achieves real-time efficiency and long-sequence visual stability. From a high-level perspective, the design of this work is based on two key optimization layers:
(1) Real-time scheduling and quality control, which synergistically integrates service-level objective (SLO)-aware batching, adaptive sink and RoPE refresh, and motion-aware noise scheduling to meet per-frame deadlines while maintaining long-sequence temporal coherence and visual fidelity;
(2) Scalable pipeline orchestration, which achieves near-linear FPS scaling without violating latency guarantees by parallelizing across denoising steps and network stages. Additionally, several lightweight system-level optimizations are explored, including DiT block scheduling, Stream-VAE, and asynchronous communication overlap, which further enhance the throughput and stability of long-running live streams.
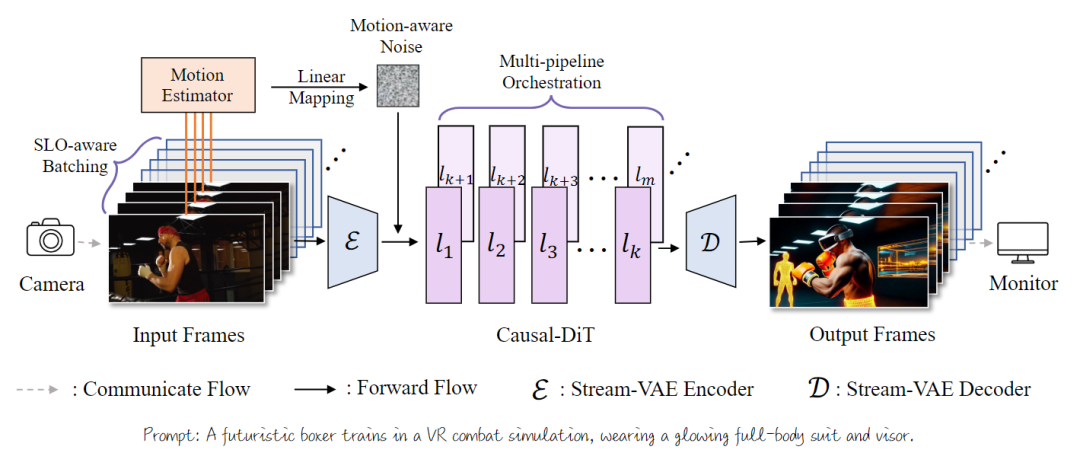
Figure 6. Pipeline overview of StreamDiffusionV2. (1) Efficiency. We pair the SLO-aware batch scheduler (controlling input size) with pipeline coordination to balance latency and FPS, ensuring each frame meets its deadline and TTFF under strict service constraints. (2) Quality. We deploy a motion-aware noise controller to mitigate high-speed tearing and combine adaptive sink tokens with RoPE refresh to provide high-quality user interaction and hours-long streaming stability.
Real-Time Scheduling and Quality Control
As shown in Figure 6, StreamDiffusionV2 achieves real-time video generation through three key components:
(1) An SLO-aware batch scheduler that dynamically adjusts stream batch sizes to meet per-frame deadlines while maximizing GPU utilization;
(2) An adaptive sink and RoPE refresh mechanism that alleviates long-sequence drift by periodically resetting temporal anchors and positional offsets;
(3) A motion-aware noise scheduler that adjusts denoising trajectories based on motion magnitude, ensuring clarity and temporal stability across diverse motion states.
SLO-aware batching scheduler. To maximize GPU utilization while meeting service-level objectives (SLOs), this paper proposes an SLO-aware batch scheduler that dynamically adjusts batch size. Given a target frame rate, the system processes frames per iteration, with overall inference latency depending on block size T and batch size B, denoted as L(T,B). To ensure real-time processing, the product B.T cannot exceed the number of frames collected from the input stream. As analyzed in Section 3, the model operates in a memory-bound region, and inference latency can be approximated as:
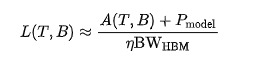
where A(T,B) represents activation memory occupancy, Pmodel denotes the memory volume of model parameters, and BWmm is the effective memory bandwidth with a utilization factor (0 < η ≤ 1). When using FlashAttention, activations A(T,B) scale linearly with O(BT), causing latency L(T,B) to grow proportionally. Thus, the achieved processing frequency can be expressed as f = BT/L(T,B), increasing with batch size as GPU utilization improves. As the system approaches the knee point of the roofline model (Figure 4), marking the transition from memory-bound to compute-bound, the scheduler adaptively converges to an optimal batch size, maximizing throughput efficiency.
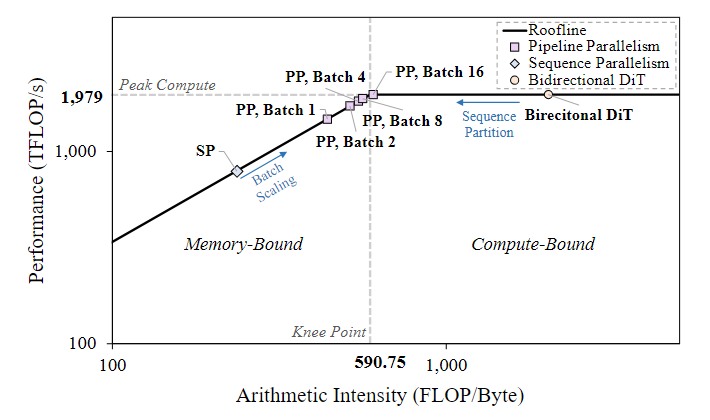 Figure 4. Roofline analysis of sequence parallelism and pipeline orchestration.
Figure 4. Roofline analysis of sequence parallelism and pipeline orchestration.
Adaptive sink and RoPE refresh. To address the drift issue discussed in Section 3, this paper introduces an adaptive sink token update and RoPE refresh strategy that jointly maintains long-sequence stability during continuous video generation. Unlike previous methods such as Self-Forcing, StreamDiffusionV2 dynamically updates sink tokens based on evolving prompt semantics. Let denote the sink set at block . Given a new block embedding , the system calculates a similarity score and refreshes the least similar sink: if , then , otherwise , where is a similarity threshold. In practice, this paper finds that should be set relatively large to ensure continuous alignment with evolving text. To prevent positional drift caused by accumulated RoPE offsets in long sequences, this paper periodically resets the RoPE phase when the current frame index exceeds a threshold , i.e., if , then , otherwise .
Motion-aware noise scheduler. To handle diverse motion dynamics in live streaming videos, this paper proposes a motion-aware noise scheduler that adaptively adjusts the denoising noise rate based on the estimated motion magnitude of recent frames.
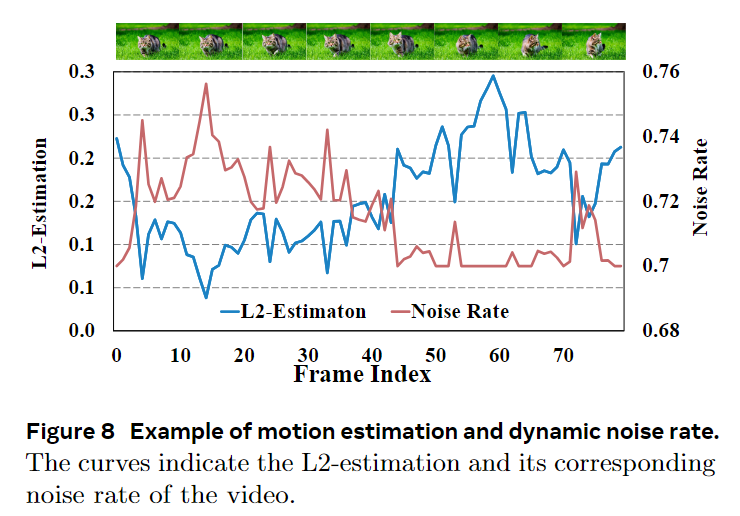
As shown in Figure 8, this paper uses an inter-frame difference metric to estimate motion magnitude between consecutive frames. Given consecutive latent frames , the motion intensity is:
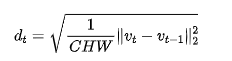
To stabilize this measurement over a short time window (k frames), this paper normalizes it by a statistical scaling factor and clips it to the [0, 1] interval:
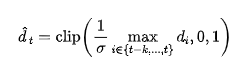
The normalized determines the intensity with which the system should denoise the current block. A higher (rapid motion) corresponds to a more conservative denoising plan, while a lower (slow or static motion) allows for stronger refinement to achieve sharper details. Finally, this paper uses an exponential moving average (EMA) to smooth the noise rate , ensuring gradual temporal transitions:
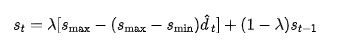
Among them, 0<λ<1 controls the update rate, while Smax and Smin represent the upper and lower bounds of the noise rate, respectively.
Scalable Pipeline Orchestration
Multi-pipeline orchestration extension. To enhance system throughput on multi-GPU platforms, this paper proposes a scalable pipeline orchestration scheme for parallel inference. Specifically, the modules of DiT are partitioned across different devices. As illustrated in Figure 7, each device processes its input sequence as a micro-step and transmits the results to the next stage within a ring structure. This enables consecutive stages of the model to run concurrently in a pipeline-parallel manner, achieving near-linear acceleration in DiT's throughput.
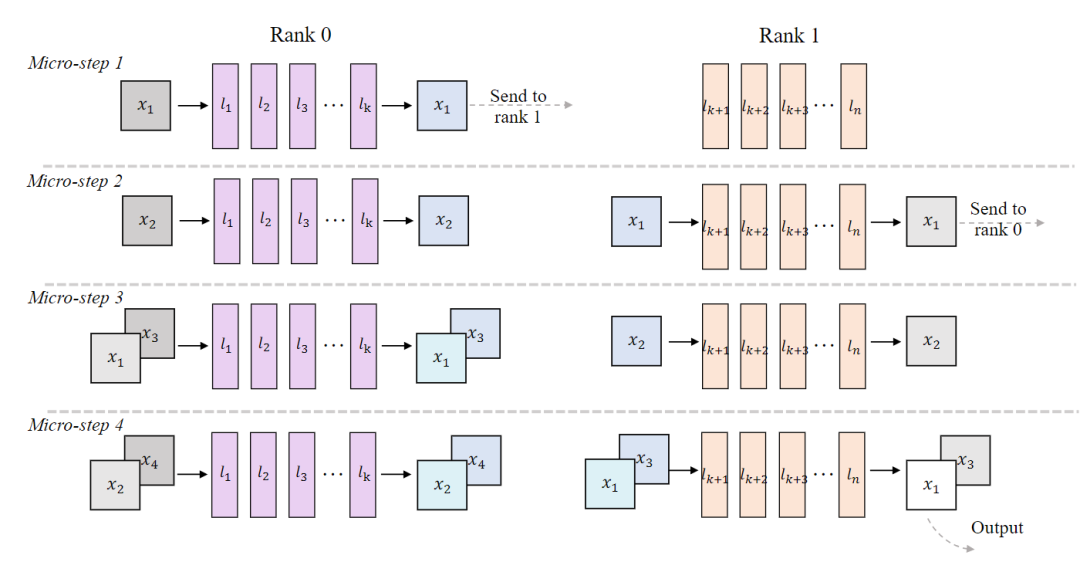
Figure 7. Detailed design of our pipeline-parallel stream-batching architecture. The DiT modules are distributed across multiple devices for pipeline parallelism, while the Stream-Batch strategy is applied at each stage. Different colors represent distinct latent streams, illustrating the communication structure, and depth indicates the corresponding noise level. Our implementation ensures that each micro-step in the inference process generates clean latent variables.
It is noteworthy that pipeline-parallel inference increases inter-stage communication, which, along with activation traffic, keeps the workload memory-bound. To address this while still meeting real-time constraints, we extend the SLO-aware batching mechanism to a multi-pipeline setting and combine it with the batch-denoising strategy. Specifically, our approach generates a finely denoised output at each micro-step (Figure 7), while treating n denoising steps as an effective batch multiplier, resulting in a refined latency model. The scheduler continuously adjusts B based on observed end-to-end latency to ensure that each stream's rate satisfies , while the aggregated throughput approaches the bandwidth roofline.
Efficient System-Algorithm Co-Design
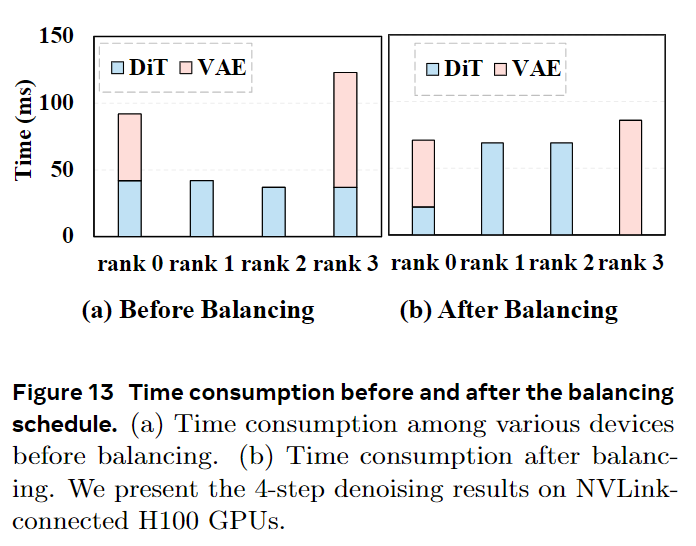
DiT Block Scheduler. Static partitioning often leads to imbalanced workloads because the first and last ranks, in addition to processing DiT blocks, also handle VAE encoding and decoding, as shown in Figure 13(a). This imbalance can cause pipeline stalls and reduced utilization. We introduce a lightweight, runtime DiT block scheduler that dynamically redistributes modules among devices based on measured execution times. The scheduler searches for an optimal partitioning scheme to minimize per-stage latency, as depicted in Figure 13(b), significantly reducing overall pipeline bubbles.
Stream-VAE. StreamDiffusionV2 integrates a low-latency Video-VAE variant designed for streaming inference. Instead of encoding long sequences, Stream-VAE processes short video chunks (e.g., 4 frames) and caches intermediate features within each 3D convolution to maintain temporal coherence.
Asynchronous Communication Overlap. To further reduce synchronization stalls, each GPU maintains two CUDA streams: a computation stream and a communication stream. Inter-GPU transfers are executed asynchronously, overlapping with local computation to hide communication latency. This dual-stream design aligns each device's computation rhythm with its communication bandwidth, effectively mitigating residual bubbles and maintaining high utilization in multi-GPU pipelines.
Experiments
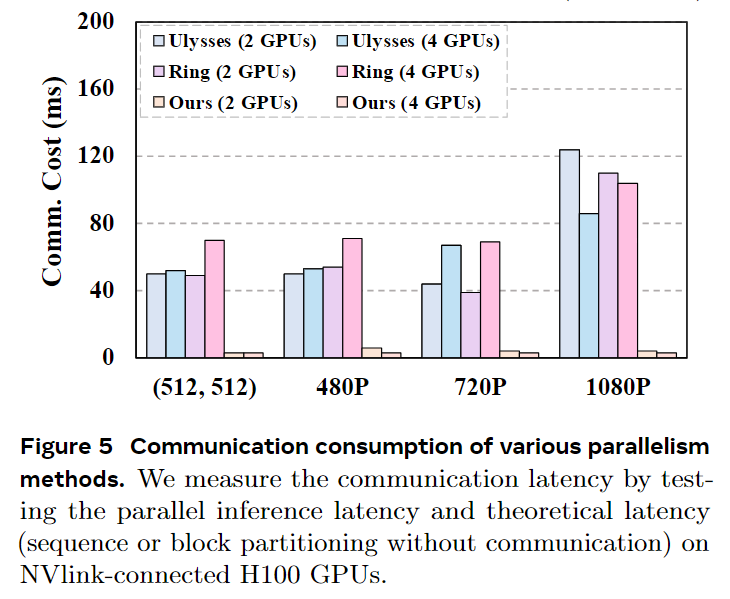
The experimental setup includes models based on Wan 2.1 and CausVid (training-free), with evaluation metrics covering efficiency (FPS, TTFF, acceleration rate) and quality (CLIP score, Warp Error). Baselines include Ring-Attention, DeepSpeed-Ulysses, StreamDiffusion, StreamV2V, and CausVid variants. Implementation details: Tested on H100 and RTX 4090 GPUs using bf16, without TensorRT or quantization, supporting 1-4 denoising steps and various resolutions.
Efficiency Evaluation: StreamDiffusionV2 significantly outperforms baselines in TTFF (e.g., 0.37s at 30 FPS, 18× higher than CausVid, 280× higher than Wan2.1-1.3B). FPS results: On 4 H100 GPUs, the 1.3B model achieves 64.52 FPS (512×512) and 42.26 FPS (480p); the 14B model achieves 58.28 FPS (512×512) and 39.24 FPS (480p). Performance remains stable even with increased steps.
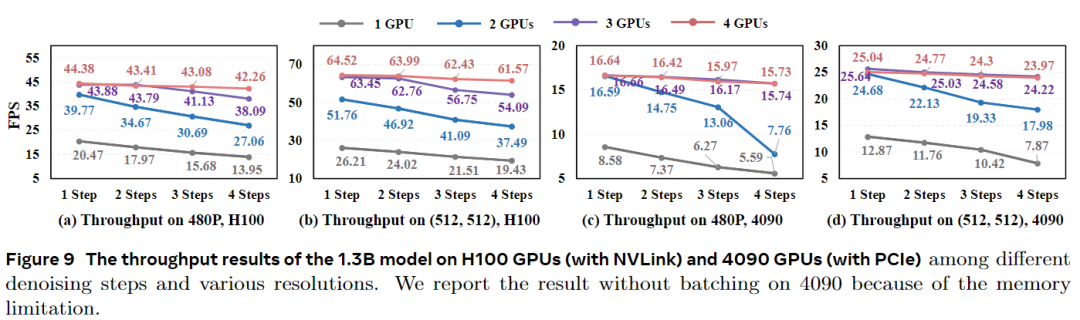
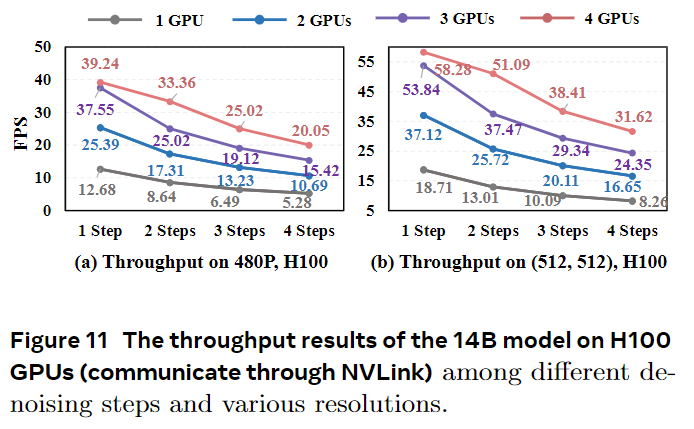
Generation Quality Evaluation: Our system leads baselines in CLIP score (98.51) and Warp Error (73.31), with visual comparisons showing better consistency and motion handling. Ablation studies confirm that the sink token and motion-aware noise controller enhance temporal alignment. Further analysis validates that the dynamic DiT block scheduler balances loads, pipeline orchestration outperforms sequential parallelism in communication and performance binding, and Stream Batch significantly improves throughput, especially under multiple steps.

Conclusion
StreamDiffusionV2 bridges the gap between offline video diffusion and live streaming media constrained by real-time SLOs. This training-free system combines SLO-aware batching/block scheduling with sink-token-guided rolling KV caching, motion-aware noise control, and pipeline orchestration, the latter achieving near-linear FPS scaling through parallel denoising steps and model layers without violating latency requirements. It operates on heterogeneous GPUs, supports flexible step counts, achieves 0.5 s TTFF, and reaches 58.28 FPS (14B)/64.52 FPS (1.3B) on 4×H100, maintaining high FPS even with increased steps. These results make state-of-the-art generative live streaming practical for both individual creators and enterprise platforms.
References
[1] StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






