Can Reinforcement Learning Accelerate the Learning Process of Autonomous Driving Models?
 02/06 2026
02/06 2026
 590
590
When it comes to training large autonomous driving models, various technical approaches are employed, with imitation learning and reinforcement learning being two prominent methods. As training techniques for large models, what distinguishes reinforcement learning? What unique characteristics does it possess?
What exactly is reinforcement learning?
Reinforcement learning is a technique that enables machines to learn decision-making through a process of "trial and error." Unlike supervised learning, where a teacher provides correct answers for the model to emulate, reinforcement learning does not disclose the "correct answer" at each step. Instead, it establishes a connection between the environment, actions, and outcomes, allowing the machine to discover which behaviors are more beneficial in the long run and adjust its strategy accordingly.
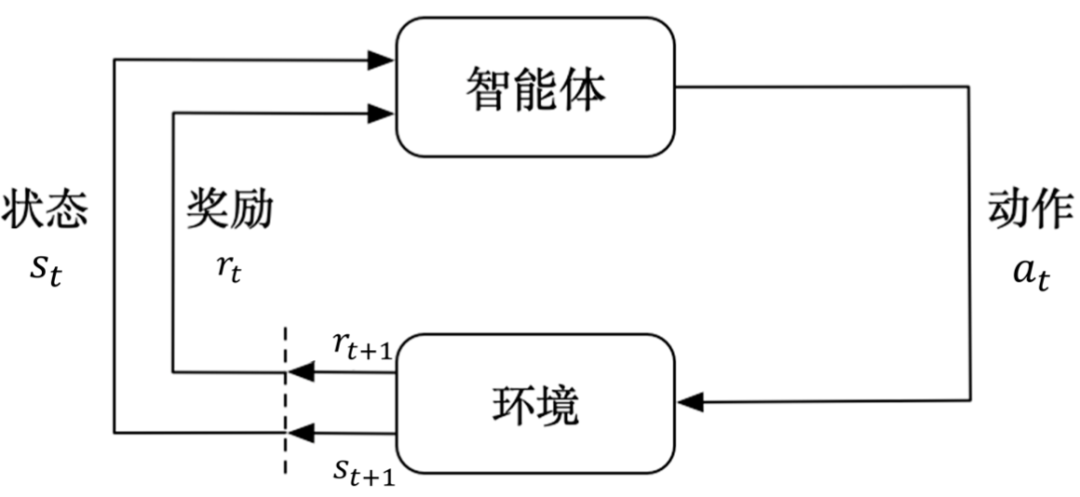
Schematic diagram of reinforcement learning. Image source: Internet
This "benefit" is quantified through a signal known as a reward. Rewards can be positive or negative, and the machine's objective is to maximize the cumulative long-term reward. Abstracting the decision-making process into a mechanism where taking an action in a certain state leads to the next state and a corresponding reward is referred to as a Markov decision process.
Conceptually, this definition may seem abstract and challenging to comprehend, so let's consider a straightforward example. An autonomous driving system operating in a simulation receives a reward for smoothly navigating through an intersection but incurs penalties for hitting the curb or braking abruptly. These rewards and penalties guide the learning algorithm towards driving behaviors that yield more positive outcomes. Reinforcement learning automates the entire "perception-decision-feedback-adjustment" loop, enabling the model to learn a safe driving strategy without explicit step-by-step instructions.
Why is reinforcement learning utilized in autonomous driving?
Autonomous vehicles rely on various sensors to perceive road conditions, but it's not merely about recognizing images from cameras or point clouds from LiDAR. They continuously interact with their environment. Autonomous vehicles must make sequential decisions in complex and dynamic traffic environments, where these decisions impact not only immediate safety but also future traffic conditions.
Reinforcement learning excels at addressing such "sequential decision-making" problems. Unlike traditional methods that encode each scenario as a rule, reinforcement learning maps environmental states (derived from cameras, radars, LiDAR, and vehicle information such as speed and acceleration) into actions (steering, accelerating, braking, etc.) and optimizes strategies through long-term rewards.
This end-to-end or semi-end-to-end learning approach renders the model more adaptable than rule-based systems when confronted with complex interactions and nonlinear scenarios. Many technical solutions integrate reinforcement learning with deep learning to process high-dimensional inputs and generate decisions.
In a safe and controllable simulation environment, reinforcement learning can explore a vast array of edge cases, accumulate experience, and then transfer or fine-tune the model to real vehicles, significantly enhancing training effectiveness.
In essence, when problems involve "sequential decisions, long-term rewards, and immediate feedback," reinforcement learning offers a more flexible approach than rule-based systems.
How is reinforcement learning applied in autonomous driving?
The autonomous driving system can be viewed as a continuous pipeline, with perception at the front end, decision-making and planning in the middle, and execution control at the back end. Reinforcement learning can play a role in multiple stages but is primarily utilized between decision-making and control.
The perception module processes raw data from cameras, radars, and LiDAR into useful representations of road conditions, such as the positions and speeds of surrounding vehicles, lane markings, and traffic signs. The decision-making module utilizes this information to determine actions for the next few seconds.
The advantage of reinforcement learning lies in its treatment of decision-making as an optimization problem, considering not only the immediate effectiveness of current actions but also the cumulative effects of action sequences in the future. Therefore, for tasks like car-following, lane-changing, obstacle avoidance, and navigating complex intersections—which require coherent actions and long-term impact considerations—reinforcement learning can produce smoother and more predictable behaviors than single-step rules.
In many technical solutions, reinforcement learning can function either as a standalone end-to-end controller, learning control commands directly from sensor inputs, or as a component within the decision-making layer, collaborating with traditional planners or constraint optimizers. The former is more concise after training but lacks interpretability and verifiability; the latter incorporates reinforcement learning strategies into existing safety constraints for inspection and correction, balancing flexibility and safety.
Currently, a common practice is to conduct extensive training in simulators to obtain an initial strategy, then use supervised learning for pre-training with human driving data as guidance, and finally fine-tune the model in simulations using reinforcement learning. This hybrid process significantly enhances training efficiency and reduces real-world trial-and-error risks.
What are the challenges associated with reinforcement learning?
While the concept of reinforcement learning appears promising, enabling large models to learn and develop viable driving strategies independently, safely and reliably deploying it in vehicles is no simple task. The primary challenges are safety and robustness.
Discrepancies between simulation and the real world can cause strategies that perform well in simulations to behave unexpectedly in real vehicles. Environmental changes, sensor noise, extreme weather, and unfamiliar traffic patterns all test the model's generalization capabilities. Deep reinforcement learning models are typically black boxes, making it difficult to explain why they make certain decisions at specific moments, posing significant challenges for accountability, accident analysis, and safety verification.
The training cost of reinforcement learning is also a practical concern. Reinforcement learning requires a large and diverse set of samples to cover edge cases. Relying solely on real-world data collection is not only dangerous but also time-consuming, so much training must occur in high-quality simulations. However, high-fidelity simulations themselves are costly and require continuous refinement, further increasing expenses.
Reinforcement learning also faces trade-offs between online and offline learning. Fully online learning on real roads means the system continuously learns through trial and error during operation, inevitably introducing risks. Conversely, prolonged offline training may cause the model to lag behind environmental changes, necessitating periodic transfer learning or continuous integration.
Final Thoughts
The core value of reinforcement learning lies in providing a systematic framework for solving sequential decision-making problems, particularly in handling long-term goals, complex interactions, and high-dimensional perception. However, transforming its algorithmic potential into reliable applications always faces fundamental challenges related to verifiability, safety constraints, and engineering implementation. Currently, reinforcement learning can be viewed as a powerful optimization and decision-making component, integrated architecturally with traditional methods within clear boundaries.
-- END --
-
![]()
Total Investment Hits Nearly 3.28 Billion! Goertek Launches Mass Production of 12-Inch Transparent Substrate Wafer for AR Glasses’ Micro-Nano Optical Components
-
![]()
Why Is This Precision Optical Film Leader Worth Reevaluating with a Tens of Millions Procurement?
-
![]()
AI Costs Plummet by 90% Over Nine Years: Key Insights from Davos You Shouldn’t Miss
-
Doubao, Your Late-Night AI Companion, Now Eyes Profitability
-
![]()
SRC Empowers SEER Intelligence to Reach a Market Cap of Tens of Billions, Yet Fails to Sustain Profitability
-
![]()
China’s Embodied AI Industry Faces Fierce Domestic Competition, Making Overseas Expansion Essential for Survival
-
![]()
32.8 Billion Yuan Investment! Goertek’s 12-Inch AR Glasses Optical Wafer Base in Lingang Begins Operations
-
![]()
How Far is the All-New Li Auto L8 from Being the Best Five-Seat SUV with In-House Full-Stack Development?






