Is the language model a must-have for autonomous driving?
 11/14 2025
11/14 2025
 618
618
The development of autonomous driving is not static. Traditional autonomous driving systems typically adopt a hierarchical architecture. The lowest layer is the perception layer, responsible for converting sensor data from cameras, radars, and LiDAR into environmental information that the vehicle can "perceive." Above it is the tracking and state estimation layer, which associates perception results over time to infer the speed and motion trends of targets. The prediction layer estimates the future possible trajectories of other road users based on the current state. The decision-making and path planning layer integrates all information to generate action strategies for the vehicle to execute. Finally, the control layer translates the planning results into specific throttle, brake, and steering commands.
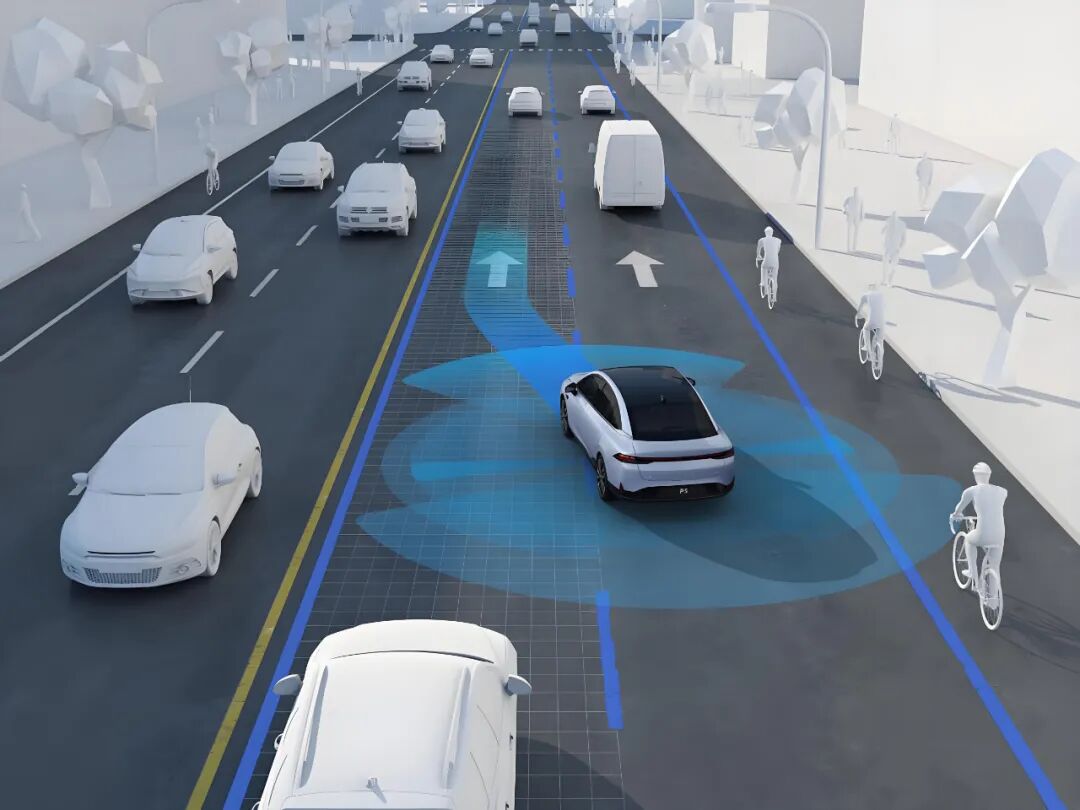
Image source: Internet
This structured design offers significant advantages. Each layer has different requirements for latency, reliability, and verification methods. The hierarchical structure allows modules to be independently optimized and facilitates problem localization. For example, sensor anomalies can be traced back to the perception layer for troubleshooting, while unstable control loops can undergo standalone stress testing for the controller. Modularity also enables the use of strictly verified algorithms in critical closed loops, while delegating tasks relying on common-sense reasoning to more flexible models. This approach balances the safety of real-time control with intelligent judgments at the semantic level.
In addition to the structured architecture, the concept of end-to-end is increasingly favored by many companies. End-to-end refers to using large models to learn everything from perception to control as much as possible. Theoretically, end-to-end can reduce error accumulation between modules, resulting in more coherent and "natural" behaviors. However, this approach also presents obvious issues, such as poor interpretability, difficult verification, and the need for extremely large and diverse datasets to cover various rare scenarios. Therefore, in practical technical solutions, traditional verifiable methods are retained in areas requiring the highest certainty, while more flexible models are introduced in areas requiring semantic understanding or extensive reasoning.
What is the role of language models in autonomous driving?
Language models excel at processing and generating language, performing reasoning based on large-scale corpora, and completing common-sense knowledge. When applied to autonomous driving, they are mostly used in the semantic and generation/interpretation layers rather than directly replacing perception or control tasks that require precise geometric calculations.

Vehicle trajectory prediction. Image source: Internet
In some traffic scenarios, the perception module informs the system of the presence of several objects ahead. However, elevating these objects into semantic information that can drive decision-making often requires combining perception results with background information such as road rules, construction notices, and temporary traffic signs. Language models excel at linking structured perception results with textual knowledge, producing descriptions closer to human understanding. In other words, they can transform "perceived points" into "comprehensible semantics," which is highly beneficial for handling temporary road conditions, complex signage, or human language instructions.
Language models also play a significant role in high-level strategy descriptions. In scenarios involving complex interactions among traffic participants, the system not only needs to provide an executable trajectory but sometimes also explain why it chose that trajectory, what alternative options exist, and the semantic reasoning behind those options. Language models can list these reasons or alternatives in natural language or predefined templates, facilitating review by operation and maintenance personnel or serving as explanations for human-machine interaction. The key here is that the model outputs "explanations" and "alternatives" rather than using explanations as directly executable instructions.
Language models also demonstrate significant value in the data and simulation domains of autonomous driving. To build more robust autonomous driving systems, especially in covering rare long-tail scenarios, simulation and synthetic data are indispensable. Language models can automatically generate diverse scenario descriptions, dialogue scripts, and test cases, converting these semantic contents into executable simulation environments through scenario generators. Leveraging this capability, the system can efficiently reproduce extreme situations difficult to collect in reality within virtual environments, significantly expanding the coverage of training and verification.
Furthermore, language models excel at transforming complex technical content into natural language. Whether for in-vehicle voice interaction, natural language interfaces with external management systems, or compiling post-event fault logs into easily understandable reports, language models play a crucial role. For ordinary passengers or maintenance teams, converting complex sensor data and decision-making processes into clear and concise explanations is far more practical than presenting raw data directly.
Why can't language models directly replace core driving technologies?
After clarifying what language models can do, it is essential to explain what they cannot do. The nature of language models determines that they cannot fully replace tasks requiring precise numerical calculations, real-time closed-loop control, and provable guarantees.
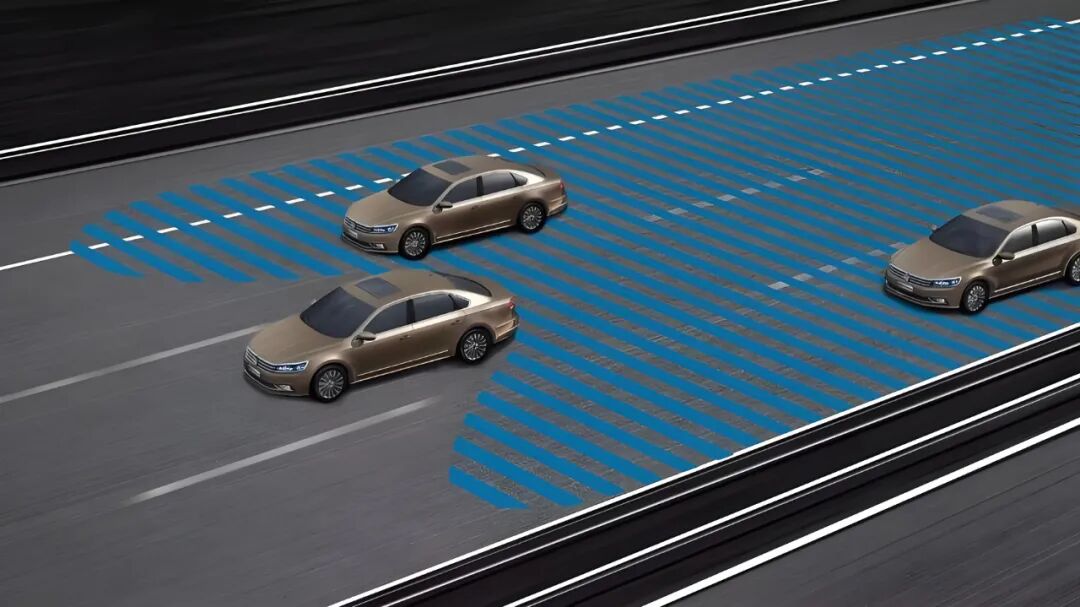
Image source: Internet
The probabilistic nature of language model outputs means that while their content is usually coherent and reasonable, it may not fully comply with physical facts. Especially when information is incomplete or conflicting, the model may generate seemingly reasonable but actually incorrect conclusions. Since autonomous driving systems have extremely low tolerance for judgment errors, any inaccurate output can lead to severe consequences. Therefore, directly using the freely generated results of language models for safety-critical decisions poses a high risk.
Real-time performance and computational constraints are another significant limitation. Vehicles typically need to complete decision-making and control within tens to hundreds of milliseconds in dynamic road environments. However, the inference process of current large-scale language models still demands substantial computational resources, making it difficult to achieve real-time responses with full-sized models directly on the vehicle. Although optimization methods such as model compression, knowledge distillation, or dedicated hardware can be employed, these approaches often come with performance losses or introduce more complex engineering deployment issues.
The model's "grounding" capability is also crucial, meaning that outputs must strictly rely on current sensor data and physical constraints. The knowledge of language models primarily comes from offline training corpora, while driving decisions heavily depend on real-time perception information such as geometric relationships, speed, and dynamic states. To align semantic reasoning with perception facts, a reliable multimodal input mechanism must be established to transmit perception data like images and point clouds to the model with minimal loss and ensure that outputs do not deviate from actual observations. Implementing such multimodal grounding mechanisms is engineeringly challenging and prone to inconsistencies between semantic inferences and physical realities.
At the regulatory and system verification level, autonomous driving must meet stringent testing and compliance requirements, demonstrating that the system's behavior is controllable and measurable in various scenarios. The black-box nature of language models makes it difficult to provide formal, mathematical safety guarantees. Therefore, in current engineering practices, the highest-risk closed-loop control tasks are typically handled by verifiable small-scale modules, while language model outputs are mostly used as auxiliary information or explanatory content. This approach ensures the overall system's safety and certifiability while leveraging the intelligent advantages of language models.
What are the seemingly insignificant but critical details in system integration?
When integrating language models as system components, a series of engineering details must be carefully considered. Although these details may seem trivial, they directly impact the system's safe and stable operation.

Image source: Internet
Interface design requires clear constraints. The system must predefine the format and semantic scope of language model outputs to prevent the model from generating unparsable text arbitrarily. A common practice is to limit the model's responses to a predefined set of templates or label collections, which are then converted into executable instructions for the lower layers by a verification module. The goal is to transform probabilistic language outputs into engineeringly controllable signals, preventing upper-layer free-form generation from directly affecting the safety boundaries of the control layer.
How to supply multimodal data to the model also requires careful consideration. The information produced by perception modules is diverse, including dense images, sparse point clouds, and time-series trajectories. To effectively transmit this heterogeneous data to a text-based model, some teams symbolize structured information into short text descriptions before feeding it to the model. Although simple, this approach may lose details. Others employ multimodal encoders to map images or point clouds into embedding spaces compatible with language, preserving information better but increasing implementation and deployment complexity.
Additionally, mechanisms for verifying model outputs are indispensable. Verification can be rule-driven or performed using small discriminative models. Regardless of the approach, the goal is to assess the executability, safety, and consistency with current perception facts of language model suggestions before passing them to lower-level actuators. In practical design, this verifier is often implemented as an independent module, and only outputs passing verification are converted into constraints or instructions acceptable to the planner.
The evaluation system must be expanded beyond traditional metrics. After introducing language models, evaluation no longer focuses solely on perception accuracy or trajectory deviation but also considers semantic stability, output consistency, and alignment with perception facts. Evaluation cases should be deliberately designed to induce scenarios where the model "fabricates stories," observing whether the model produces illogical conclusions under incomplete information, conflicting data, or extreme perturbations. Additionally, conducting stress testing of the model in closed-loop simulation environments is crucial. Only by passing inspections under numerous perturbations and boundary conditions can the overall system demonstrate robustness in these dimensions.
The trade-offs in deployment architecture often determine the overall success or failure. Placing large models in the cloud leverages strong computational power but introduces network latency and connectivity risks. Deploying models on the vehicle reduces latency but is constrained by hardware and energy consumption. Adopting edge-cloud collaboration balances both but increases system complexity. Therefore, decisions must be made based on the real-time performance and safety levels of different functions, determining which logic can involve the cloud and which must remain on the vehicle. Additionally, fallback strategies must be designed for various network and hardware failures.

Final Thoughts
Language models are tools proficient in semantic understanding, text generation, and common-sense reasoning. When applied to autonomous driving, they can significantly contribute to many non-real-time or semantically intensive tasks. Typical application scenarios include converting perception results into semantic descriptions, providing readable strategy explanations for complex interaction scenarios, expanding long-tail samples in simulation and data generation, and presenting complex technical information in human-readable ways to passengers or operation and maintenance personnel.

Image source: Internet
It is also important to recognize that language models are unsuitable for replacing control loops that demand strict real-time performance, precise geometric reasoning, or mathematical proofs. Their probabilistic nature may lead to inaccurate conclusions when information is insufficient. They are sensitive to computational power and latency, making full-sized onboard inference impractical. Their grounding work with actual perceptions is engineeringly intensive, requiring specialized interfaces and verification mechanisms. Regulatory and verification requirements further restrict the use of language models as black boxes for safety-critical roles.
Regarding whether language models should be a mandatory component of autonomous driving, the key lies in clarifying their specific applicable scenarios, usage methods, and corresponding risk control mechanisms. We should view language models as tools, clearly defining their boundaries in engineering practice. High-risk real-time control loops should be reserved for verifiable traditional modules, while language model outputs should be positioned as explanatory information, auxiliary prompts, or non-real-time decision support. This division of labor aligns with system safety requirements and embodies a pragmatic approach to engineering implementation.
-- END --
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






