Is a Real-World Version of 'The Matrix' on the Horizon? Tencent Crafts a 'Dialogue-Driven Game Universe' with Real-Time Creation and Unrestricted Interaction, Where the Environment Adapts to You!
 12/02 2025
12/02 2025
 585
585
Analysis: The AI-Generated Future 

Hunyuan-GameCraft-2 takes the generative game world model to the next level, transitioning from static game scene video synthesis to open-ended, instruction-responsive interactive simulations.
Showcasing the Synthetic Interactive Video Pipeline 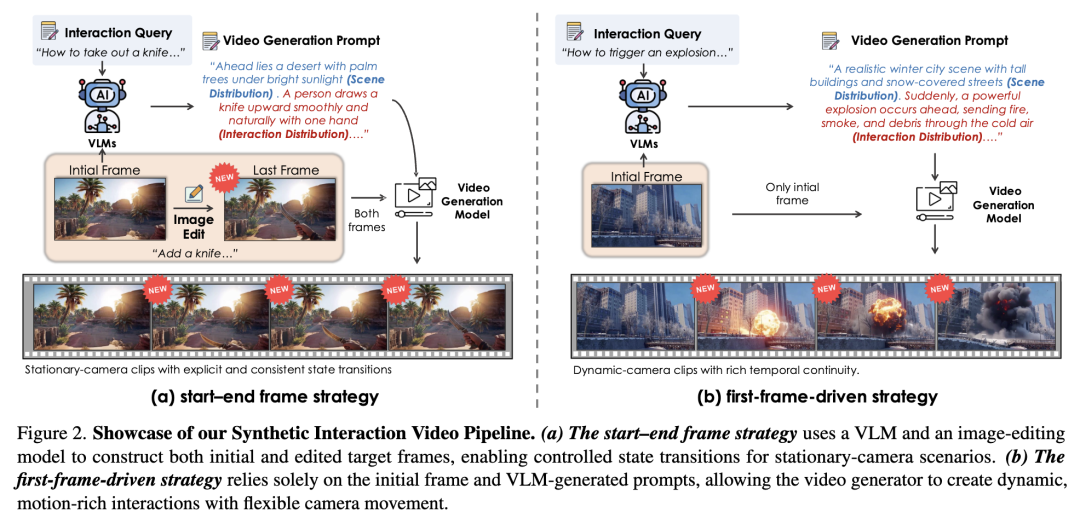
Pipeline of the Data Curation System  Pipeline of the Caption Generation System
Pipeline of the Caption Generation System
Key Highlights
Introduced a unified and controllable video generation framework that combines text, keyboard, and mouse inputs for semantic-based interactive operations.
Leveraged autoregressive distillation and randomized long video fine-tuning techniques to ensure efficient and stable generation of extended video sequences. Achieved real-time performance at 16 frames per second through multi-round inference optimization using KV cache recomputation and combined engineering optimizations.
Comprehensively validated the framework's effectiveness through extensive quantitative and qualitative experiments. Results demonstrated superior performance in generating interactive videos that faithfully respond to user instructions while maintaining visual quality and temporal coherence.
Summary Overview
Challenges Addressed
While existing generative world models have made strides in creating open-ended game environments, they still face several limitations:
Rigid action schemas and high annotation costs: Current methods rely on predefined action patterns, such as keyboard inputs, and require substantial amounts of annotated data, limiting their ability to model diverse in-game interactions and player-driven dynamics.
Lack of formalized interaction definitions and scalable construction pipelines: In the realm of world models, there is a dearth of clear definitions for 'interaction' and efficient, scalable pipelines for converting large-scale unstructured text-video pairs into interactive datasets.
Long-term consistency in multi-round interactions: Difficulties in maintaining video quality and interaction accuracy when generating extended video sequences, as well as the issue of error accumulation.
Proposed Solution
The article introduces Hunyuan-GameCraft-2, a groundbreaking paradigm for instruction-driven interactive generative game world modeling.
Instruction-driven flexible control: Enables users to manipulate game video content through natural language prompts, keyboard, or mouse inputs, fostering flexible and semantically rich interactions.
Formal definition of Interactive Video Data: Defines interaction in world models as 'actions performed by a clear agent that trigger state transitions in the environment with clear causality and physical or logical validity'.
Automated interactive data construction pipelines: Developed two automated pipelines capable of transforming large-scale, unstructured text-video pairs into open-domain interactive datasets enriched with implicit causal labels.
Unified control mechanism: Integrates text-based instructions and keyboard/mouse action signals into a unified, controllable video generator.
New evaluation benchmark: Introduces InterBench, an interaction-centric benchmark for systematically assessing key dimensions of interactive performance (e.g., interaction integrity, action effectiveness, causal coherence, and physical plausibility).
Applied Technologies
The Hunyuan-GameCraft-2 model is built upon the following cutting-edge technologies:
14B Image-to-Video Mixture-of-Experts (MoE) Foundation Model: Serves as the foundational architecture of the model.
Text-Driven Interaction Injection Mechanism: Facilitates fine-grained control of camera motion, character behavior, and environmental dynamics.
Autoregressive Distillation Strategy: Transforms a bidirectional video generator into a causal autoregressive model to support efficient generation of extended video sequences.
Randomized Image-to-Long-Video Extension Tuning Scheme: Mitigates error accumulation in long-duration inference and ensures stable and coherent long video generation.
KV-Recache Mechanism (Reference: LongLive): Enhances accuracy and stability in multi-round interactions for autoregressive long video generation.
Engineering Acceleration Optimizations: Improves the model's inference speed.
Achieved Effects
Through extensive experiments and evaluations on InterBench, Hunyuan-GameCraft-2 achieved the following remarkable effects:
Leading Generation Performance: Attained state-of-the-art (SOTA) performance on InterBench and general video quality metrics.
High Quality and Consistency: Capable of generating temporally coherent and causally grounded interactive game videos.
Faithful Response to Instructions: Able to accurately respond to diverse and free-form user instructions, such as 'open the door,' 'draw a torch,' or 'trigger an explosion'.
Real-Time Interaction Capability: Increased model inference speed to 16 FPS, enabling real-time interactive video generation.
Methodology
This paper introduces Hunyuan-GameCraft-2, an interactive game video model focused on free-form instruction control. The overall framework is illustrated in Figure 5 below. Specifically, this work integrates natural action injection into a causal architecture, image-conditioned autoregressive long video generation, and diverse multi-prompt interactions within a cohesive framework. This section will delve into the model architecture, training process, and inference process.
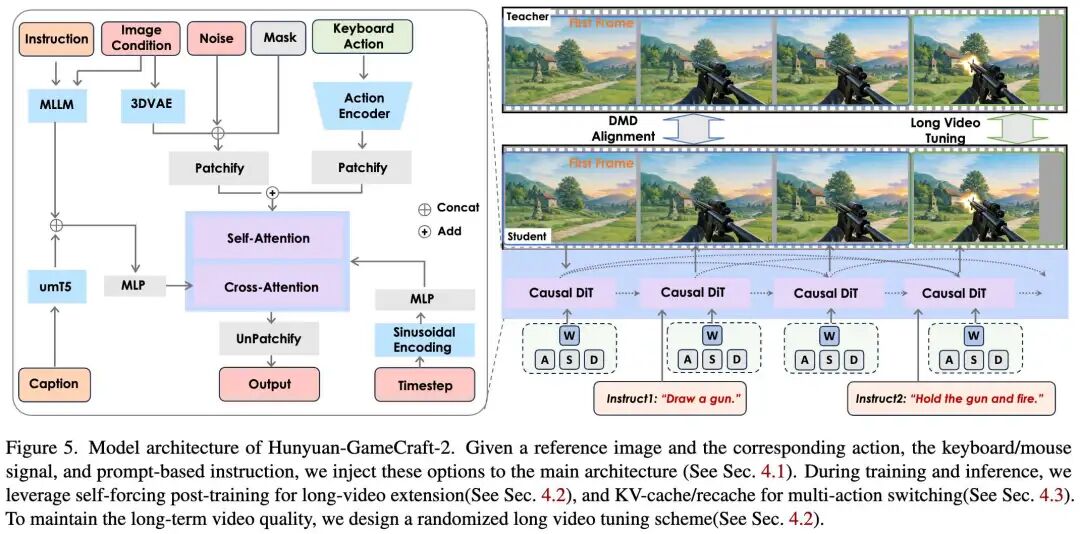
Model Architecture
The core architecture of this model is based on a 14B-parameter image-to-video Mixture-of-Experts (MoE) foundational video generation model. The objective is to extend this image-to-video diffusion model into an action-controllable generator. The action space encompasses keyboard inputs and free-form text prompts.
For keyboard and mouse signal injection (W, A, S, D, Space, etc.), this work adopts the methodology from GameCraft-1, mapping these discrete action signals into continuous camera control parameters. During training, annotated camera parameters are encoded as Plücker embeddings and integrated into the model through token addition. At inference time, user inputs are converted into camera trajectories to derive these parameters.
Regarding prompt-based interaction injection, this paper notes that the foundational model struggles to accurately express certain interactive verbs due to the higher semantic and spatial complexity of interactive text compared to scene descriptions. Such text is often closely tied to specific visual regions or object instances. To address this, the work leverages a multimodal large language model (MLLM) to extract, reason about, and inject interaction information into the main model. This enriches text guidance related to interactions and enhances the model's ability to distinguish between general text instructions and fine-grained interactive behaviors during training. This combination of camera-conditioned control and text-based scene and interaction inputs forms a unified mechanism, enabling Hunyuan-GameCraft-2 to navigate and interact seamlessly within the environment.
As depicted in Figure 5 above, given a reference image and corresponding actions, keyboard/mouse signals, and prompt-based instructions, this work injects these options into the main architecture. During training and inference, long video extension is performed using Self-Forcing post-training, and multi-action switching is facilitated through KV-cache/recache. To maintain long video quality, a randomized long video fine-tuning scheme is designed.
Training Process
To achieve long-duration and real-time interactive video generation, it is essential to distill the foundational bidirectional model into a low-step-count causal generator. In this work, we extend the comprehensive autoregressive distillation technique, Self-Forcing, to the 14B MoE image-to-video model. This scheme is tailored to enhance the quality and efficiency of long video generation, which typically involves significant and rapid scene changes. We introduce random extension tuning to mitigate error accumulation. The training process is divided into four stages: (1) Action Injection Training, (2) Instruction-Guided Supervised Fine-Tuning (SFT), (3) Autoregressive Generator Distillation, and (4) Randomized Long Video Extension Tuning.
Action Injection Training
The primary objective of this stage is to establish a fundamental understanding of 3D scene dynamics, lighting, and physics. We load pre-trained weights and fine-tune the model using a flow-matching objective to adapt to architectural adjustments. To improve long-term consistency, a curriculum learning strategy is employed. Specifically, training is divided into three stages, sequentially exposing the model to video data with 45, 81, and 149 frames at 480p resolution. This staggered approach allows the model to first consolidate its understanding of short-term motion dynamics before gradually adjusting its attention mechanisms to handle the complex dependencies required for longer-duration coherence. Additionally, during training, long and short captions are randomly selected, and interactive captions are concatenated for interactive learning. This option aids the model in developing an initial perception of interaction information injection.
Instruction-Guided Supervised Fine-Tuning
To enhance the model's interactive capabilities, we construct a dataset comprising 150K samples by augmenting real-world footage with procedurally generated synthetic videos. These synthetic sequences provide high-fidelity supervisory signals across various interaction types (e.g., state transitions, agent interactions), establishing tight correspondences between actions and their visual outcomes. In subsequent stages, the parameters of the camera encoder are frozen, and only the MoE expert layers are fine-tuned. This process aims to optimize the model's alignment with semantic control cues.
Autoregressive Generator Distillation
For interactive world models, extending fixed-length video generators to high-quality autoregressive long video generation is crucial. Prior work has made initial attempts in long video generation. Building upon high-noise and low-noise MoE architectures with camera parameter injection, we make targeted adjustments to the attention mechanism and distillation protocol. These modifications are specifically designed to optimize performance during autoregressive distillation.
Sink Token and Block Sparse Attention: Previous techniques employed direct sliding window methods to update the KV cache for causal attention. However, this could lead to a decline in generation quality over time, as subsequent steps cannot reference initial condition frames, resulting in drift. In this work, the initial frame is designated as the Sink Token (anchor token) and is always retained in the KV cache. This modification serves two key purposes: first, it improves and stabilizes generation quality. Second, in our specific task, the Sink Token provides information about the origin of the coordinate system. This ensures that camera parameters injected during the autoregressive process remain aligned with the initial frame, avoiding the need for recaching at each autoregressive step due to coordinate origin shifts. Additionally, we employ block sparse attention for local attention computation, which is more suitable for autoregressive, block-based generation. Specifically, the target block being generated can attend to a set of preceding blocks. This local attention, combined with the aforementioned Sink attention, forms the complete KV cache, improving generation quality while accelerating the process.
Distillation Schedule: Due to the unique nature of the MoE architecture, high-noise experts face greater challenges in training and convergence compared to low-noise experts, particularly during SFT or distillation. To address this, we assign different learning rates to each expert. Simultaneously, based on the noise level boundary separating the two experts, we redefine the list of denoising time step targets used for distillation. This ensures consistency between the teacher and student models when selecting high-noise or low-noise experts during distillation (as shown in Figure 6 below).
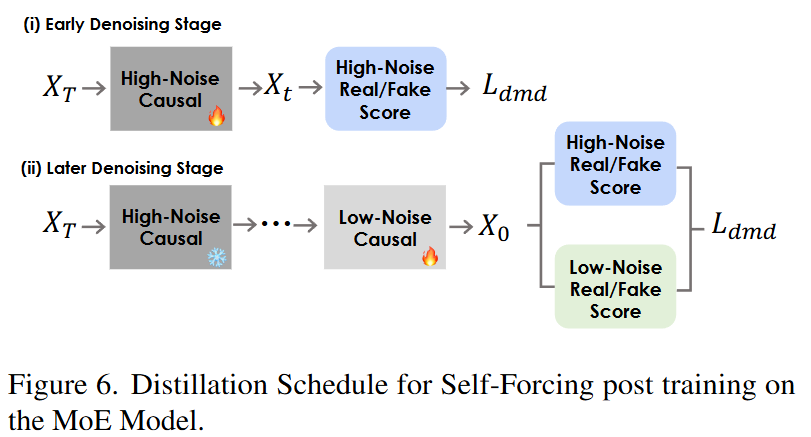
Randomized Long Video Extension Tuning
Our approach to long video generation is inspired by an observation: although the foundational model is pre-trained on short clips, it implicitly captures the global visual data distribution. Previous methods unfold long video sequences from causal generators and apply Distribution Moment Distance (DMD) alignment on extended frames. This strategy effectively mitigates error accumulation during autoregressive generation.

Based on this insight, this work adopts a randomized extended fine-tuning strategy, utilizing a dataset of long-duration game videos exceeding 10 seconds. During this phase, the model unfolds frames autoregressively and uniformly samples consecutive frame windows to align the predicted distribution with the target distribution (real values or teacher priors). Additionally, we randomly extend the predicted video to different lengths from the causal generator to enhance robustness across varying time scales. In practice, when unfolding within a window, the student generator uses Sink Tokens and KV caches to autoregressively extend long videos, while the Fake Score teacher model uses the last frame from the previous clean prediction block as an image condition; Real Score uses the actual frame from the original video.
To alleviate the issue of interactive capabilities being eroded, which is an inherent problem in few-step distillation, this study adopts a training approach that alternates between Self-forcing and Teacher-forcing. The underlying principle of this method is to force the model to become proficient in state recovery and maintain temporal stability. Crucially, this is accomplished by exposing the model to various states at random points within the generated trajectory, rather than restricting such corrective training to only the initial stage.
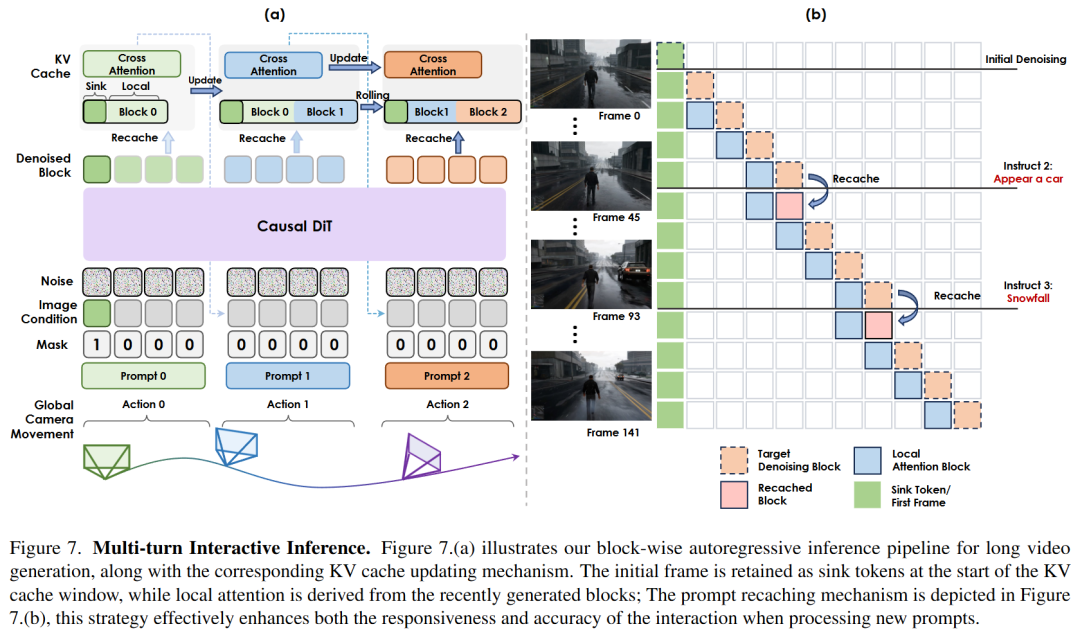
Multi-round Interactive Inference
Self-attention KV Cache: To ensure alignment with the training strategy, the inference process utilizes a self-attention KV cache of fixed length, which is updated in a rolling manner to support efficient autoregressive generation, as depicted in Figure 7 below. Specifically, the Sink Token is permanently positioned at the start of the cache window. The following section functions as a local attention window, preserving frames that precede the target denoising block throughout multiple rounds of interactions. The entire KV cache is composed of these Sink Tokens and local attention components, implemented through block-sparse attention. This design not only boosts the efficiency of autoregressive generation but also effectively prevents a decline in quality.
[ ]
]
ReCache Mechanism: This study introduces a Recache mechanism to improve the accuracy and stability of multi-round interactions in autoregressive long video generation. When new interactive prompts are received, the model extracts the corresponding interactive embeddings to recompute the last autoregressive block and updates both the self-attention and cross-attention KV caches. This strategy provides precise historical context for subsequent target blocks with minimal computational overhead, ensuring accurate and prompt feedback for a smoother user experience.
Real-time Interaction Acceleration
To further speed up inference and reduce latency, this study incorporates several system-level optimizations:
FP8 Quantization: Reduces memory bandwidth and takes advantage of GPU acceleration while maintaining visual quality;
Parallelized VAE Decoding: Enables the synchronous reconstruction of latent frames, easing bottlenecks in long-sequence decoding;
SageAttention: Replaces FlashAttention with optimized quantized attention kernels to accelerate Transformer computations;
Sequence Parallelism: Distributes video tokens across multiple GPUs, facilitating efficient long-context generation.
By integrating these techniques, the inference speed is increased to 16 FPS, enabling real-time interactive video generation with stable quality and low latency.
Experiment
Model and Dataset Configuration
The experiment compares Hunyuan-GameCraft-2 with several state-of-the-art (SOTA) image-to-video foundational models, including HunyuanVideo, Wan2.2 A14B, and LongCatVideo. All baseline models are operated under their officially recommended configurations. To conduct the evaluation, a test suite covering three core interaction dimensions was created: (1) environmental interaction, (2) character actions, and (3) entity and object emergence. The test set consists of 100 images representing a variety of scenes and styles, with all models uniformly generating videos at a resolution of [specific resolution] and a length of 93 frames.
Evaluation Metrics
Two categories of metrics were used for assessment:
General Metrics: Include Fréchet Video Distance (FVD, for video realism), image quality and aesthetic scores, temporal consistency, and dynamic averages (optical flow magnitude). Additionally, Relative Pose Error (RPE) was employed to evaluate camera control accuracy.
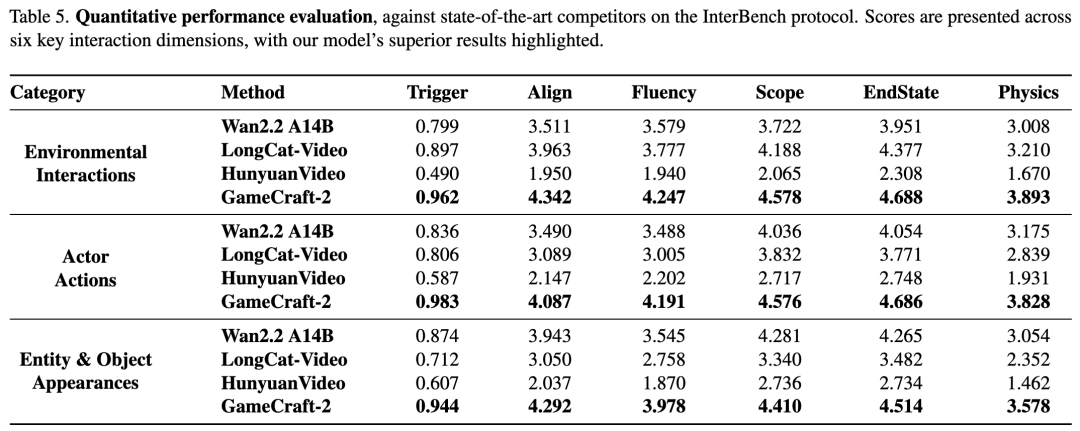
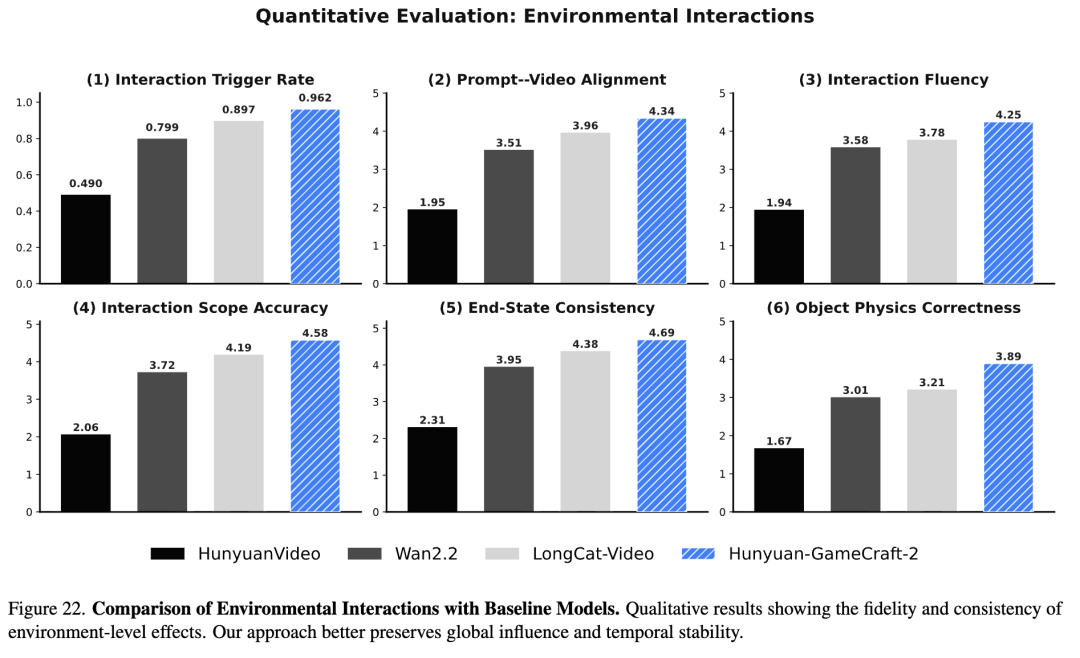
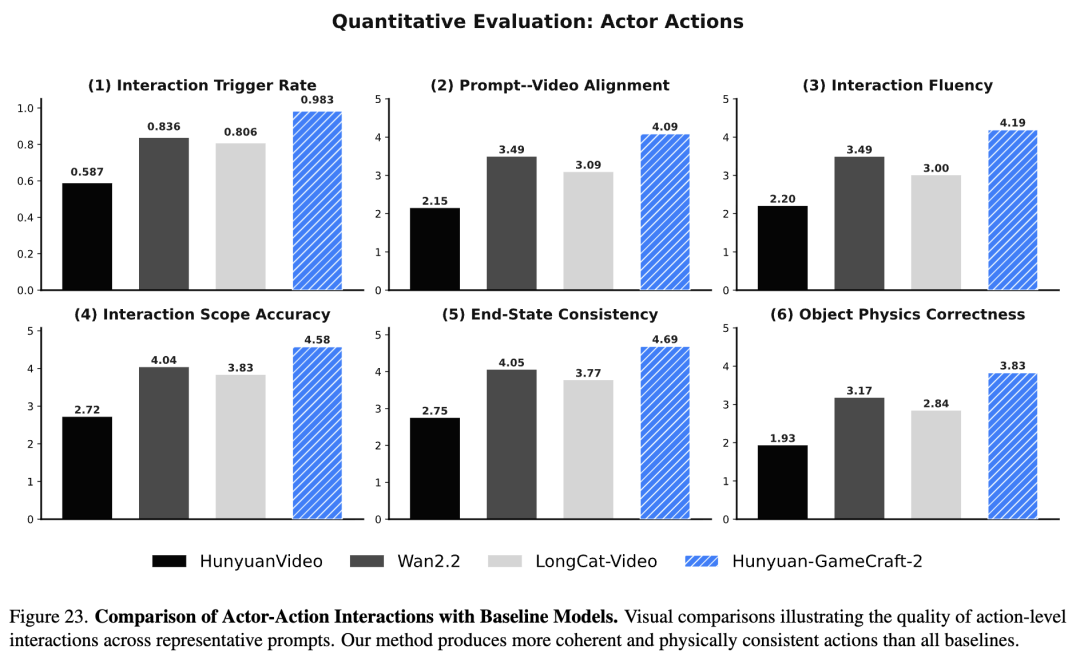
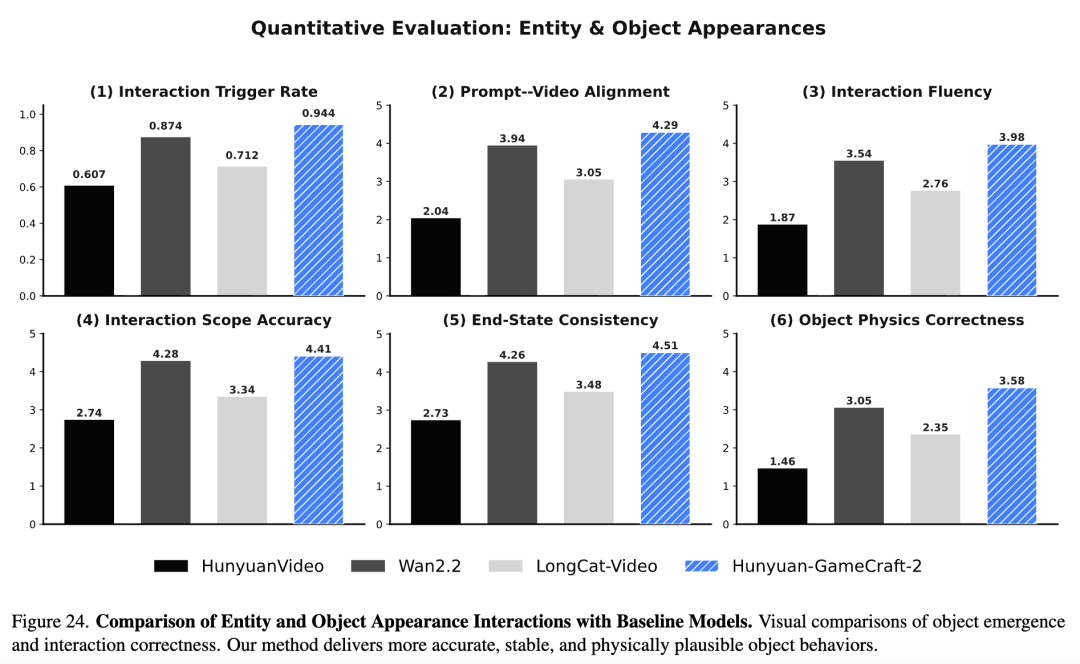
InterBench (Interactive Benchmark): A six-dimensional evaluation protocol proposed in this paper for action-level interaction. Using a Vision-Language Model (VLM) as an automatic evaluator, it covers the following aspects: interaction trigger rate (whether the action occurred), prompt-video alignment (semantic fidelity), interaction fluency (temporal naturalness), interaction range accuracy (spatial impact rationality), final state consistency (stability of the end state), and object physical correctness (structural integrity and kinematics). Interaction Evaluation Results
Quantitative Results: As shown in Table 5 below, GameCraft-2 significantly outperforms the baseline models across all interaction categories (environment, character actions, entity emergence) on all metrics.
Trigger Rate: GameCraft-2 achieves an extremely high interaction trigger rate (0.962 for environmental interaction, 0.983 for character actions), far exceeding that of other models. Physics and Consistency: It scores 0.52 - 0.68 points higher than the next-best model in terms of physical correctness, while also showing substantial improvements in fluency and final state consistency. Comprehensive Performance: As shown in Table 4 below, GameCraft-2 also attains the optimal balance in terms of general video quality metrics (FVD, image quality, etc.) and real-time performance (16 FPS). [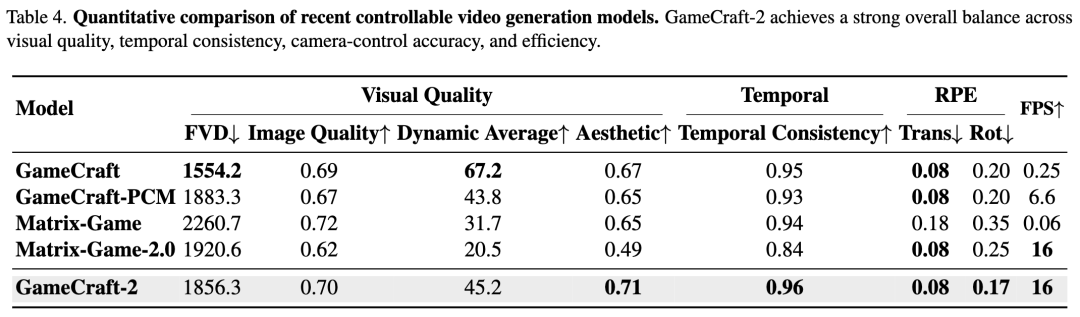 ][
][ ]
]
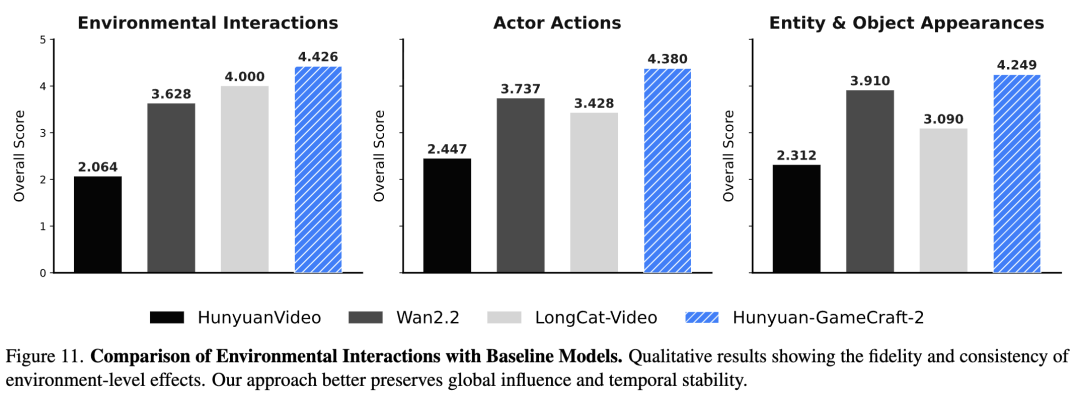
Qualitative Analysis: Through visual comparisons (Figures 10, 11, 12, 13, 22 - 24 in the paper), GameCraft-2 demonstrates higher fidelity:
Environmental Interaction: For example, when simulating "snowfall," GameCraft-2 achieves global coverage and dynamic snow accumulation, whereas baseline models often lack dynamic evolution. Character Actions: Generated actions (e.g., "shooting with a gun") are more coherent, with accurate hand-object contact and stable end states. Object Emergence: Newly generated entities (e.g., "dragons" or "vehicles") maintain structural integrity and identity consistency. [ ][
][ ][
][ ][
][ ][
][ ][
][ ][
][ ]
]
Generalization Capability: The model shows the ability to generalize beyond the training distribution. For instance, even though the training data does not include specific scenarios like "a person suddenly appearing" or "a dragon appearing," the model can still handle these unseen interactions, generating physically plausible state transitions (Figure 15).
[ ]
]
Ablation Study
An ablation study was carried out on long video fine-tuning and KV-Cache settings (Figure 16 in the paper):
Long Video Fine-tuning: Introducing randomized extended long video fine-tuning significantly improves video fidelity and motion consistency for videos beyond 450 frames.
Cache Settings: Increasing the size of Sink Tokens and local attention can enhance details but may also introduce artifacts. [ ]
]
Conclusion
Hunyuan-GameCraft-2, an interactive game world model, is capable of generating high-fidelity, controllable videos in response to free-form text instructions and keyboard/mouse actions. This work formally defines interactive video data and proposes an automated pipeline for its curation and synthesis, effectively addressing the data bottleneck that has impeded progress in this field.
The model integrates multimodal control signals within a robust training framework, utilizing a novel randomized long video fine-tuning scheme and efficient inference mechanisms (such as KV-recache) to achieve stable, long-duration, and real-time interactive generation. To rigorously evaluate the contributions of this work, InterBench was introduced—a new benchmark specifically designed to assess action-level interaction quality. Extensive experiments demonstrate that GameCraft-2 significantly outperforms existing state-of-the-art models across all dimensions of interaction fidelity, visual quality, and temporal consistency. By advancing cutting-edge techniques from passive video synthesis to proactive, user-driven world generation, this work represents a significant step toward creating truly playable and immersive AI-generated virtual experiences.
References
[1] Hunyuan-GameCraft-2: Instruction-following Interactive Game World Model
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






