Tesla Stirs the Pot: How Will the 'World Model' Revolutionize Autonomous Driving?
 12/02 2025
12/02 2025
 749
749
Author | Sean
Editor | Dexin
The biennial International Conference on Computer Vision (ICCV) wrapped up in Honolulu, USA, in October. This year, the Best Paper Award was bestowed upon the team from Carnegie Mellon University for their work on BrickGPT. This model stands out for its ability to directly generate physically stable and constructible block structures from mere textual descriptions, underscoring the immense potential of generative AI in real-world physical applications.
For professionals in the autonomous driving field, an even more significant announcement came from the conference. Ashok Elluswamy, the Vice President of Tesla's AI department, shared the latest advancements in Tesla's Full Self-Driving (FSD) system during the 'Distillation of Foundation Models and Autonomous Driving' forum.
Since unveiling its occupancy grid network at the AI Day in 2022, Tesla has been tight-lipped about the specifics of FSD, especially after transitioning to an end-to-end architecture. Despite witnessing rapid performance enhancements in FSD, Tesla has kept the underlying technology under wraps.
Elluswamy's presentation shed light on crucial details: the system leverages video-based multimodal inputs within an end-to-end model framework, directly outputting control commands. The processes of perception, prediction, decision-making, and control are seamlessly integrated and backpropagated within the same neural network. This setup closely mirrors the recently discussed 'World Model' concept. Additionally, on the simulation front, the World Model is utilized to create adversarial scenarios for closed-loop evaluation and iterative refinement.
Prior to this revelation, debates raged over the VLA (Vision-Language-Action) and World Model approaches. Tesla's latest stance has only intensified these discussions. Regardless of the eventual paradigm that prevails, the World Model's capacity to 'envision the future' is poised to become a pivotal factor in the evolution of autonomous driving technology.
I. Tesla FSD: Merging End-to-End Foundation Models with the World Model
Under the theme 'Building the Future of Automation,' Elluswamy delved into recent FSD advancements, including the launch of Robotaxi and the achievement of full autonomous driving capabilities from the factory to the delivery center.
He then introduced Tesla's end-to-end architecture, where inputs from multiple cameras, navigation maps, vehicle motion data, and audio signals are funneled into a single end-to-end neural network. Trained on vast datasets, this model supports long-sequence inputs and directly generates control signals.
This approach aligns closely with technical directions pursued domestically, with the notable exception of incorporating audio signal inputs.
Why opt for an end-to-end architecture? Elluswamy cited several reasons:
- Human driving behavior is complex and challenging to encapsulate with functions; rule-based algorithms often struggle to balance competing priorities.
- Traditional perception-planning-control structures suffer from significant information loss.
- End-to-end systems are more scalable and better equipped to handle long-tail problems.
- They offer stable latency.
- They rely on computing power and data rather than human experience.
What challenges arise when constructing an exceptional end-to-end system? Elluswamy identified three major hurdles:
The Curse of Dimensionality
FSD must process high-frame-rate, high-resolution, long-context multimodal inputs. Assuming '5×5 pixel blocks' as input tokens, vision alone equates to a staggering 7 cameras × 36 FPS × 5 million pixels × 30 seconds, combined with navigational maps, future path predictions, kinematic data (100 Hz speed/IMU/odometry), and 48 kHz audio data. This totals approximately 2 billion tokens. Directly inputting these into a Transformer would cause token explosion within the time window, failing to meet vehicle-side latency requirements.
Tesla's solution leverages massive fleet data to summarize 'key tokens,' retaining the most useful information through sparsification and aggregation. This significantly reduces inference latency without compromising accuracy.
Simultaneously, Tesla employs a data engine to extract high-quality data samples for training, enabling the system to achieve excellent generalization in extreme or rare scenarios.
Explainability and Safety Verification
To avoid 'black box' AI, Tesla incorporates explainable intermediate outputs in vehicle-side models, including panoramic segmentation, 3D occupancy networks, scene reconstruction based on 3D Gaussian rendering, and linguistic outputs. These assist engineers in reviewing the reasoning process.
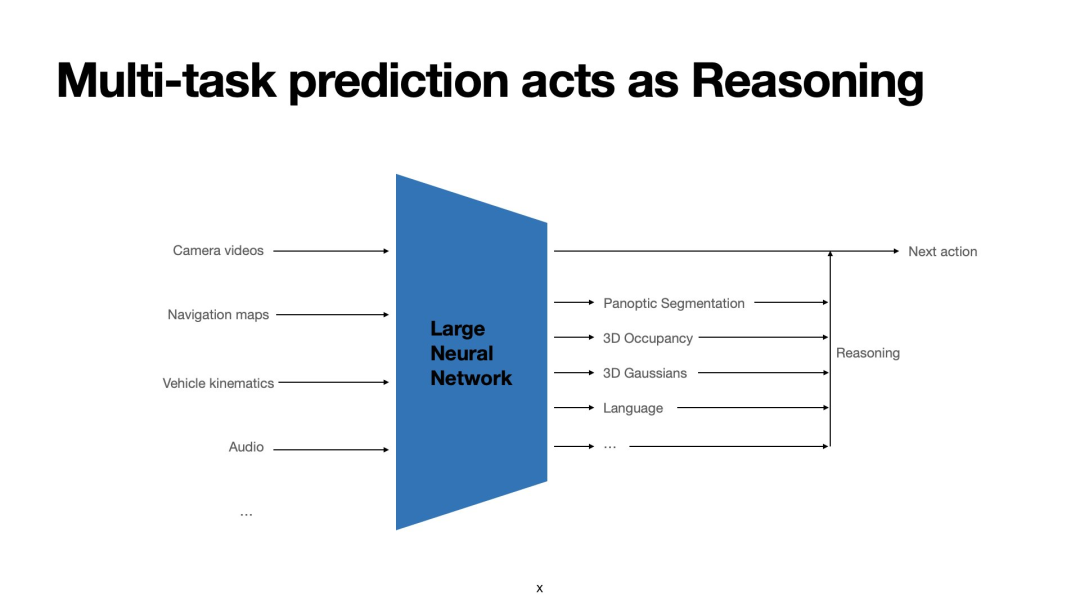 Image Source: Tesla
Image Source: Tesla
Elluswamy highlighted Tesla's Generative Gaussian Splatting (GGS). Compared to traditional Gaussian Splatting, Tesla's GGS offers stronger generalization capabilities, generating scenes in just 220 milliseconds without initialization, modeling dynamic objects, and enabling joint training with end-to-end AI models.
Closed-Loop Evaluation and Simulation
The final and most challenging step is model evaluation.
Even with high-quality datasets, a decline in open-loop prediction loss functions does not necessarily guarantee good real-world performance. The evaluation system must be diverse and cover different modes to support rapid development iterations.
To address this, Tesla developed a Neural World Simulator. Trained on Tesla's proprietary massive datasets, this simulator differs from conventional models. Instead of predicting actions, it generates future states based on current states and next actions, forming a closed loop with the vehicle-side end-to-end foundation model for real-world effect evaluation.
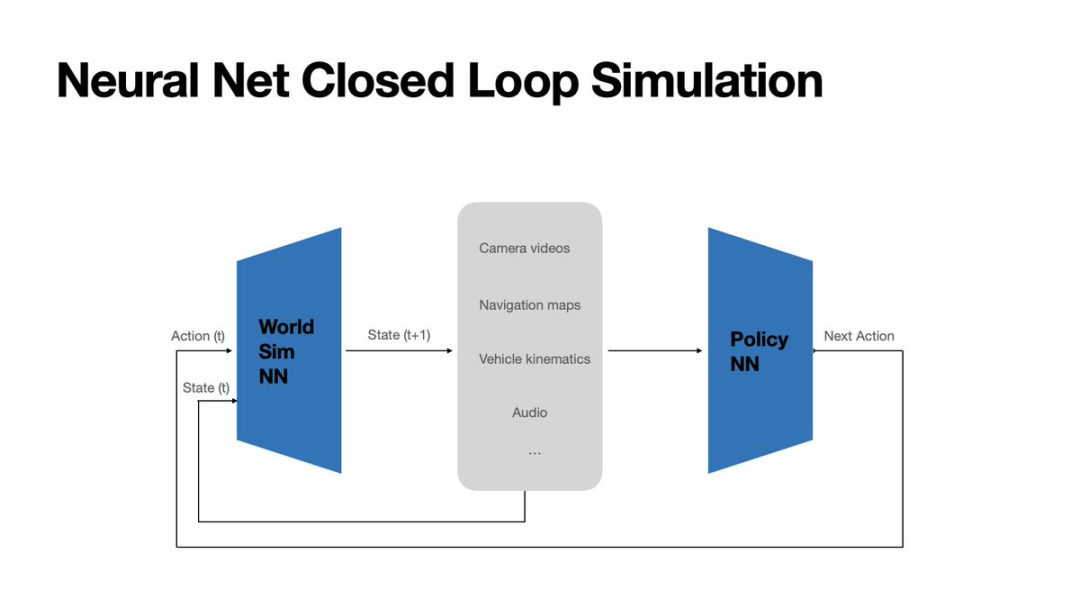 Image Source: Tesla
Image Source: Tesla
Under the guidance of driving strategies, the Neural World Simulator generates interactable futures based on causality. It can not only replay and validate new driving models based on historical data but also systematically synthesize adversarial/extreme scenarios for long-tail coverage and safety boundary testing.
In engineering implementation, Tesla emphasizes that the simulator can generate high-resolution, causally consistent responses in real-time or near-real-time for rapid validation during research and development. Additionally, this video generation capability enables large-scale reinforcement learning in closed-loop environments, achieving performance beyond human levels.
 Image Source: Tesla
Image Source: Tesla
Although Tesla did not explicitly use the term 'World Model' in its presentation, the capabilities and usage of its Neural World Simulator essentially make it an extremely powerful World Model.
Unlike traditional cloud-based World Models, Tesla's system not only generates high-fidelity scenes but also predicts world evolution over the next few seconds given candidate actions, enabling decision foresight and safety verification.
The model is no longer just a 'generator of environments' but a causal prediction system capable of 'imagining and evaluating the consequences of actions.'
Given Tesla's focus on 'predicting world evolution over the next few seconds' as the core of decision foresight, the vehicle-side foundation model likely follows a World Model route: real-time action-conditioned future prediction on the vehicle side and large-scale scenario reproduction and regression verification in the cloud using the Neural World Simulator. Both are highly aligned in objectives and representations, forming an integrated closed loop for training-evaluation-deployment.
II. What Is a World Model?
The end-to-end architecture can bring higher ceilings to autonomous driving, a consensus in the industry. However, there is no clear direction on how to achieve or surpass human driving levels within this framework to realize true driverless operation. Among various technical routes, the World Model is undoubtedly a prominent contender.
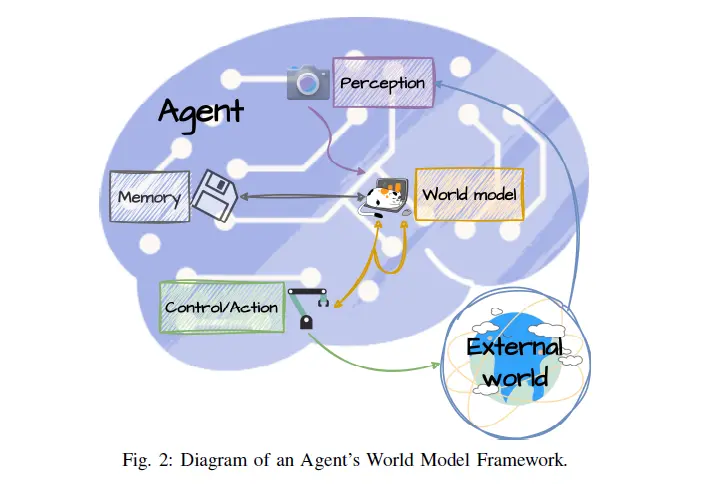 Image Source: World Models for Autonomous Driving: An Initial Survey
Image Source: World Models for Autonomous Driving: An Initial Survey
While there is no standard definition of a World Model, the industry has gradually formed a consensus. A World Model is a generative spatiotemporal neural system that compresses multimodal inputs from cameras, LiDAR, radar, and navigation maps into a latent state. This state encodes not only geometric and semantic information but also causal context.
The World Model can simulate future environmental states within the latent space and allow agents to 'rehearse' entire trajectories before executing actions. For this reason, some refer to the World Model as a model capable of 'imagining the future' in its mind.
World Models typically cover three types of tasks:
- Future Physical World Generation: Based on sensor data and vehicle history, generate future scene evolutions (including object motion, occupancy probabilities, point clouds, or image-level videos).
- Behavior Planning and Decision-Making: Combine prediction results to generate trajectories or action suggestions for the ego vehicle, enabling decision-making and control.
- Joint Prediction and Planning: Simultaneously model multi-agent interactions within the latent space, using generated futures to evaluate candidate actions and achieve closed-loop behavior optimization.
It is not merely a simple stack of perception or prediction modules but a unified 'brain': it compresses the real world into an evolvable internal representation and supports planning and decision-making through generative simulations. It requires the following core capabilities:
Latent Spatiotemporal Representation
A World Model must first map high-dimensional, multimodal perception inputs into a low-dimensional latent state. This latent representation should contain both geometric and semantic information from the environment and update over time, enabling the model to capture environmental state transitions within this space. This capability means the model no longer relies on explicit BEV (Bird's Eye View) or occupancy grids but represents the 'world' in a more abstract yet semantically rich form.
Action-Conditioned Future Simulation
After obtaining the latent state, a World Model must generate multi-step future scenarios given candidate actions (acceleration, braking, lane changes, etc.). This generation is not merely temporal extrapolation but causal reasoning about 'how other road participants will react and how the scene will change if I take this action.' In other words, it predicts not just 'what will happen' but also 'what will happen if I do this.'
Closed-Loop Coupling with Planning and Control
A key feature of the World Model is the deep coupling between prediction and planning. The future scenarios generated by the model do not merely serve as references but are directly used to evaluate the risks and benefits of different actions, enabling comparison-selection-decision-making of candidate actions within the latent space. This closed-loop capability allows the World Model to directly output control signals within an end-to-end framework, like Tesla's 'Neural World Simulator,' which evaluates new models in closed-loop simulations, generates adversarial scenarios, and conducts large-scale reinforcement learning to achieve superhuman performance.
Multi-Agent Interaction and Uncertainty Modeling
Real roads contain not only the ego vehicle but also other vehicles and pedestrians whose motion states mutually influence each other. A World Model must represent the positions, speeds, and intentions of these participants within its 'mental state space' and track their interactions over time.
Meanwhile, the future in reality is not uniquely determined: the vehicle ahead may change lanes or slow down. Thus, the model should not provide just a single 'most likely trajectory' but a set of possible futures, allowing the system to balance safety, efficiency, and comfort.
Long-Term Memory and Self-Evolution
A World Model should possess long-term memory and self-evolution capabilities—able to accumulate driving experience, continuously expand its internal world, and transfer knowledge across different tasks and scenarios. This enables it to generalize beyond specific routes or conditions to various settings.
The World Model's powerful capabilities have made it one of the hottest research directions in autonomous driving today. Many believe it holds the key to achieving Level 3 and Level 4 autonomous driving.
III. China's Path with World Models
As the country with the most widespread applications of autonomous driving technology, China has seen the World Model take root and flourish. Technical companies like SenseTime focus on cloud-based synthetic data supplementation for autonomous driving, while automakers such as NIO and Huawei are determined to implement World Models in vehicles. In China, the World Model is playing an increasingly important role.
NIO's NWM World Model
NIO was one of the first companies to publicly adopt the World Model as a core technical route. At the 2024 'NIO IN' event, NIO announced China's first driving World Model, the 'NWM (Nio World Model),' which it defines as 'a multivariate autoregressive generative model capable of fully understanding multimodal information, generating new scenarios, and predicting the future.'
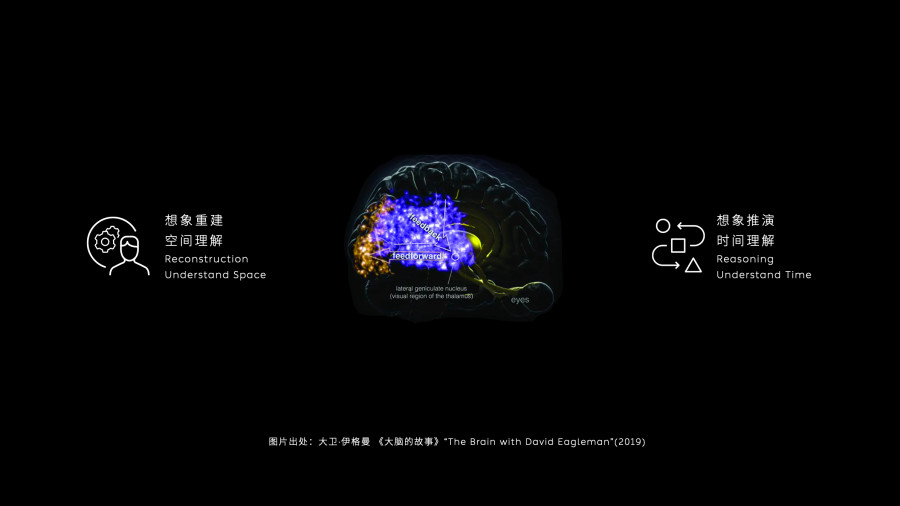 Image Source: NIO
Image Source: NIO
It accomplishes 'imaginative reconstruction' in space (realistically rebuilding the perceived physical world into an editable virtual world) and 'imaginative simulation' in time (rolling out different futures in internal spacetime) to output executable trajectories and actions. NIO demonstrated its vehicle-side application, where NWM can reason through 216 possible driving scenarios within 100 milliseconds and select the optimal decision. NIO stated that the model can generate up to 20-second future videos using 3-second historical video prompts. The World Model forms 'parallel worlds' through generative simulations, evaluating the consequences of different actions in these imagined futures. Beyond pure visual inputs, NWM integrates LiDAR, maps, and ego vehicle motion information while understanding driver language instructions.
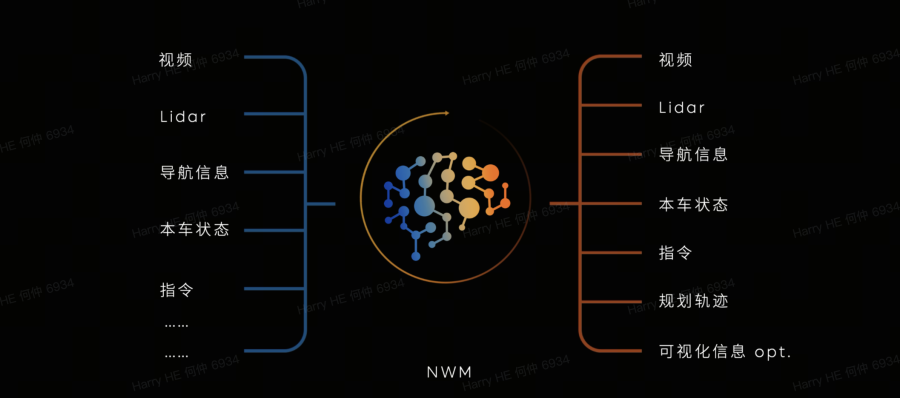 Image Source: NIO
Image Source: NIO
NIO has developed NSim, a generative neural simulator operating in the cloud. After performing 3D reconstruction from real-world videos, the NIO World Model (NWM) is integrated into NSim for editable scene decomposition, depth and normal vector verification, and the ability to switch between arbitrary viewpoints. The simulated trajectories produced by NWM are aligned and compared with NSim’s simulation results, enabling a shift from 'playback evaluation of a single true trajectory' to 'comparative evaluation across massive parallel worlds.' This creates a closed data loop and facilitates the generation of targeted adversarial scenarios. Combined with NIO’s 'Swarm Intelligence,' which continuously gathers long-tail scenarios from the real world, this dual-wheel approach accelerates model iteration.
The first iteration of NWM was launched in June this year, introducing three new active safety features:
Driver Incapacitation Handling
In highway or expressway scenarios, upon detecting an unconscious driver, the vehicle gradually decelerates and moves to the rightmost emergency lane, activating hazard lights and SOS signals for active intervention. This marks an upgrade from 'in-lane safe stopping' to 'autonomous safe pull-over,' significantly reducing the risk of rear-end collisions caused by stopping in the lane.
Rear-End Collision Prevention and Protection (First-time application of large models to rear-end collision scenarios)
The system alerts drivers to potential rear collisions within the speed range of 0–150 km/h. When a collision is unavoidable, it completes perception, decision-making, and brake pressure buildup within 500 ms, reducing passive forward movement by up to 93% and minimizing the risk of secondary accidents.
Enhanced General Obstacle Warning
This feature responds to various obstacle types, including lifting barriers, guard walls, isolation fences, and curbs, during maneuvers such as turning, lane changing, and parking. It reduces common low-speed side-scrape accidents and collisions during garage maneuvers.
The Highway Navigation Pilot now includes intelligent passage through Electronic Toll Collection (ETC) scenes and a 'Smart Driving Enjoyment Mode,' which offers a more stable driving style, smoother following and lane-changing, stronger defensive driving, and autonomous flashing/honking to alert surrounding vehicles when necessary.
The Urban Point-to-Point Navigation Pilot introduces two major enhancements:
Parking Spot Collection: After parking, users can save marked parking spots for seamless full-domain navigation during their next departure or entry. If the spot is occupied, the system automatically locates a nearby vacant spot for temporary parking.
Parking Lot Autonomous Routing: Without relying on maps, navigation, or route memory, this feature understands natural language commands, recognizes signs and text, and enables cross-zone/cross-floor navigation to exits or building entrances. This represents a symbolic implementation of NWM’s cognitive-understanding-reasoning capabilities in complex microstructured spaces.
Smart Parking Assist has been upgraded to a full model-based system, featuring 360° omnidirectional parking spot recognition, a quadrupled parking spot display range, and the ability to initiate parking commands from any position for long-distance roaming parking. It automatically switches between different spots and, as long as not completely blocked by walls, achieves 'visible, selectable, and parkable' functionality.
The successful mass production of NWM and comprehensive upgrades to intelligent driving functions demonstrate the immense potential of world models in automotive applications.
Huawei WEWA Architecture
Amid ongoing debates over technical routes for world models, Huawei, a leader in China’s intelligent driving sector, proposes 'WA (WorldAction)'—a world model approach emphasizing direct perception-to-control mapping.
 Image Source: Huawei
Image Source: Huawei
Jin Yuzhi, President of Huawei’s Intelligent Automotive Solutions BU, publicly stated that the company will not follow the Vision-Language-Action (VLA) trend but will instead adhere to a world action model driven directly by sensor signals.
From Huawei’s perspective, VLA models convert videos into 'language tokens' using large language models before generating control commands—a seemingly shortcut approach that fails to provide true autonomy. Only by bypassing the language layer and directly generating driving instructions from multimodal sensory data (visual, auditory, etc.) can advanced autonomous driving requirements for spatial perception and real-time performance be met.
Huawei’s ADS 4 platform has evolved into the WEWA (World Engine + World Action) architecture based on WA principles:
The World Engine (cloud-based) trains world models in the cloud using massive simulation and real-vehicle data, generating model parameters for upgrades. The World Action (vehicle-end) operates on the vehicle side, directly mapping sensory data to control actions while skipping language parsing.
WEWA eliminates the language layer to avoid abstraction losses and uses multiple LiDARs and high-performance hardware to ensure the model receives as complete environmental information as possible. Although this increases hardware costs, Jin Yuzhi believes it is the only path to safe and reliable autonomous driving.
Huawei emphasizes that true world models extend beyond simulation to serve as the core for real-time vehicle decision-making. In the WEWA architecture, the cloud-based World Engine conducts 'dream training' using extensive simulation and real-vehicle data to learn environmental evolution patterns and generate optimized parameters. These parameters are then distributed via Over-the-Air (OTA) updates to the vehicle-end World Action model, enabling direct planning and control within a physically consistent 'world representation.' To achieve comprehensive environmental perception, Huawei employs multiple LiDARs and high-performance hardware on the vehicle side, with four-LiDAR configurations already implemented in the latest AITO M9 and Luxgen S800 models.
Jin Yuzhi stresses that while this route incurs higher costs, it delivers stronger spatial understanding and decision-making reliability, representing Huawei’s sole path to advanced autonomous driving.
SenseTime JueYing: 'Enlightenment' World Model and Generative Simulation Platform
SenseTime’s autonomous driving brand, JueYing Intelligent Driving, introduced the world model 'Enlightenment' for large-scale simulation data generation. At the 2025 World Artificial Intelligence Conference (WAIC), JueYing unveiled an upgraded interactive world model product platform and the industry’s largest-scale generative driving dataset, WorldSimDrive. Built on advanced world model technology, this platform offers physical understanding and scene element control capabilities, serving as an interactive product available for trial use by automakers and developers.
 Image Source: SenseTime JueYing
Image Source: SenseTime JueYing
Unlike NIO’s vehicle-end world model, JueYing’s 'Enlightenment' primarily generates high-fidelity simulation data. It produces spatially and temporally consistent videos from 11 camera perspectives in simulation scenarios, lasting up to 150 seconds with professional-grade 1080p resolution. Users can freely edit scene elements like road layouts, participants, weather, and lighting on the platform, generating high-risk scenarios or diverse combinations with one click. Currently, JueYing is collaborating with SAIC’s IM Motors to build an end-to-end data factory using this platform, mass-generating training data for high-value scenarios like cut-ins and rear-end collisions, with plans to release a scenario library covering millions of synthetic clips.
In terms of data scale and efficiency, the WorldSimDrive dataset contains over 1 million generative driving clips, covering 50+ weather and lighting conditions, 200 traffic sign categories, and 300 road connection scenarios—one of the largest autonomous driving generative datasets to date. These synthetic data maintain multi-view spatial-temporal consistency for minutes, with image quality matching real-world data. Enlightenment’s daily production capacity, using just one A100 GPU, equals the data collection capability of 10 real vehicles or 100 road test vehicles. Currently, 20% of JueYing’s training data comes from world model generation.
Through the 'Enlightenment' world model, SenseTime JueYing bridges the digital and physical worlds: on one hand, it supports rapid scene generation via text or image prompts on the simulation platform; on the other, it collaborates with automakers to build closed-loop data factories, using synthetic data to address long-tail scenario deficiencies.
Enlightenment’s success demonstrates the power of world models in simulation data generation, reducing data collection costs while enabling customized training for high-risk scenarios, providing a reliable and safe testing and training environment for autonomous driving.
IV. World Model vs. VLA: The Ultimate Route Debate in Autonomous Driving
With the advent of large models, Vision-Language-Action (VLA) models centered around large language models (LLMs) have emerged in autonomous driving. Ideal, Xiaomi, and YuanRon are staunch advocates of the VLA route, with Ideal leading the way by deploying a mass-produced VLA version in July.
VLA advocates integrating visual input, natural language understanding, and action generation into a single large model, enhancing situational understanding and reasoning through language. Key differences from world models include:
Structure and Representation
World models employ latent spatiotemporal representations, functioning as physical world simulators that evolve over time. They encode perceptual data into latent states via self-supervised compression and rely on generative prediction modules to evolve future states. VLA models feature a unified vision-language-action architecture, using large language models as the 'brain' to map high-dimensional visual perceptions into natural language descriptions and leverage chain-of-thought reasoning to generate decisions or action commands. VLA models enable language-level reasoning and explanation before vehicle control, creating a dual-system approach combining fast reflexes and slow thinking.
Reasoning Pathways
World models rely on action-conditioned internal simulations: they inject candidate actions into the latent world, generate different future scenarios, and select optimal actions using cost functions or risk assessments. This reasoning method resembles mental experimentation, making it well-suited for adversarial and long-term evaluations in the physical world. VLA reasoning depends on language chains: VLA models utilize the common sense and logical reasoning capabilities of large language models to interpret observed scenes, formulate rules, and output control signals through natural language. This grants the system stronger interpretability, though physical reasoning often relies on external modules.
Capabilities and Applications
World models focus on long-term horizons, multi-agent interactions, and physical consistency. They generate long-term evolutions of complex environments, capturing rare events, interactions with other vehicles, and road condition changes while forming realistic action feedback in latent spaces. Due to this closed-loop nature, world models serve as the core for evaluating and optimizing autonomous driving strategies, such as Tesla’s Neural World Simulator, which generates adversarial scenarios through closed-loop simulations for reinforcement learning training. VLA models emphasize semantic reasoning and high-level interactions. They understand natural language commands, traffic rules, and scene descriptions through language interfaces, enabling chain-of-thought reasoning. VLA models leverage internet-scale language data to inject common sense, supporting complex reasoning and explanations.
The debate between 'World Model vs. VLA' will continue. World models align more closely with the physical essence of autonomous driving, while VLA models offer advantages in long-tail scenarios through general knowledge capabilities. The ultimate industry solution may emerge from the complementarity and integration of both approaches.
Recently, AI pioneer Fei-Fei Li published a lengthy article discussing spatial intelligence. She argues that while today’s large language models excel at abstract knowledge processing, they remain like 'wordsmiths in the dark' regarding the physical world, lacking a solid understanding of three-dimensional environments, causality, and dynamics—making it difficult to act safely in the real world. Understanding the world through imagination, reasoning, creation, and interaction, rather than relying solely on language descriptions, embodies the power of spatial intelligence.
The answer to achieving spatial intelligence lies in 'world models,' which enable understanding, reasoning, generation, and interaction within complex worlds (virtual or real) across semantic, physical, geometric, and dynamic dimensions.
Her perspective once again places world models at the forefront of AI research. Regardless of the final technical path to autonomous driving, world models will undoubtedly leave a profound mark on the journey toward that goal.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






