Sino-US LLM "Lunar Expedition Blueprint": Google and Yuezhi'anmian's Journey Over the Past Year
 12/05 2025
12/05 2025
 656
656

Two years ago, confronted with OpenAI's unexpected offensive, Google, which was on the defensive, raised an internal "red alert".
To tackle this crisis that threatened Google's core business—search—the tech giant made a pivotal decision: In April 2023, Google reallocated resources from its two premier research labs, Google Brain and DeepMind, to form a new entity, Google DeepMind.
This newly formed super team placed their bets on a project dubbed "Gemini".
Google's choice of name carries a double meaning. It translates directly to "Gemini", symbolizing the fusion of Google's two top-tier technical teams. In the annals of aerospace history, Gemini also holds significant weight—it served as a vital stepping stone for NASA's renowned Apollo moon landing program.
"The name instantly resonated with me because the immense effort required to train large language models deeply echoes the spirit of rocket launches," explained Oriol Vinyals, Vice President of DeepMind and Co-Technical Lead for Gemini, when discussing the name's origin.
However, the harsh realities of the tech world often outweigh the thrust of even the most powerful rockets.
The Gemini project faced its toughest scrutiny during its infancy. Overshadowed by OpenAI's timed releases of new models, Gemini 1.0's demo video mishap, and its inferior performance compared to rivals, Google struggled to dispel external doubts.
Yet, the allure of the tech industry lies in its promise that as long as genuine investment in technology is made, redemption is always within reach.
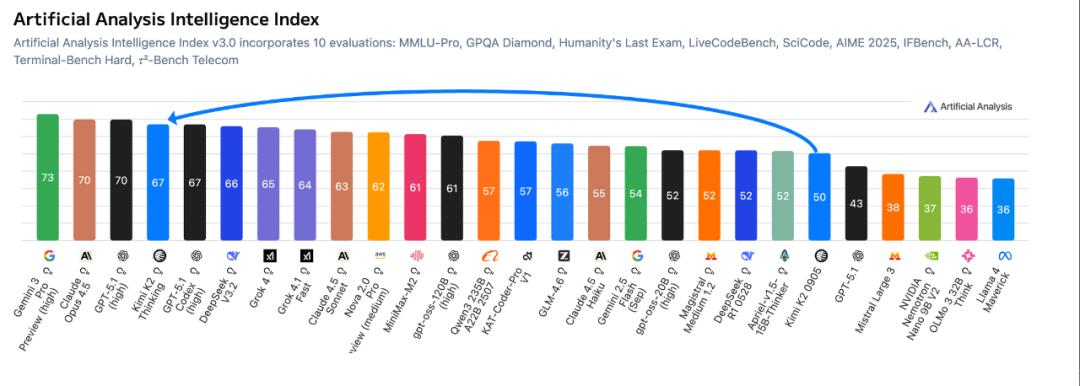
Two years later, with the debut of Gemini 3, which surpassed GPT-5.1 in multiple metrics, Google finally regained its pride.
Recently, it was revealed that Google is exploring a "moonshot" project—building AI data centers in space and launching a series of solar-powered satellites equipped with Google AI chips. This marks the company's latest endeavor to catch up with OpenAI and other competitors.
Google CEO Sundar Pichai also expressed his pride in the moonshot project during an interview.

In the rapid deployment of AI 2.0, Google's story serves as a microcosm of this generation of AI companies. Unlike the AI 1.0 era, where technological advancements quickly plateaued, leading to late-stage competition devolving into a scale war over implementation and funding, AI 2.0 companies still prioritize technological advancement above all else.
In the Sino-US model competition, China's Yuezhi'anmian (Moonshot AI) also unveiled its own "lunar expedition blueprint" early on. As envisioned by founder Yang Zhilin, the company focuses on deep technological development and emphasizes "exploration of the moon's far side."
On November 30, NBC News reported that with the rise of China's open-source ecosystem, top Chinese models like Kimi K2 Thinking are approaching the performance levels of the best in the US.
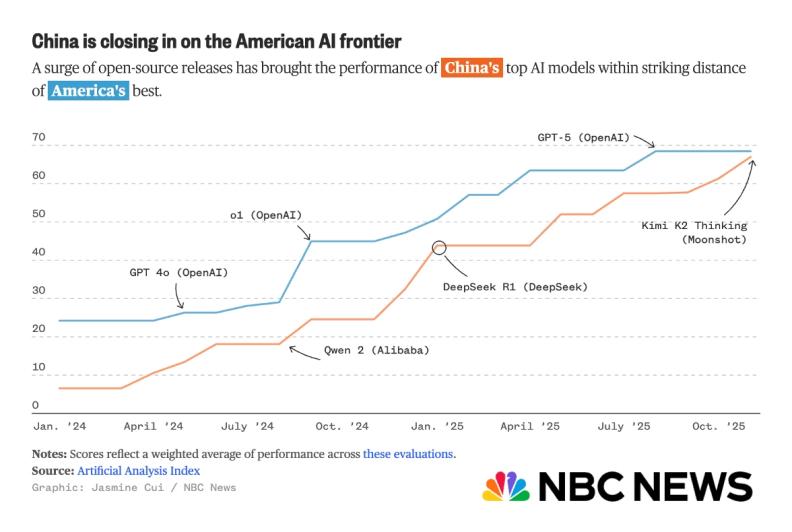
Behind this achievement lies Yuezhi'anmian, which, after six months of silence, made a triumphant return with its "lunar expedition blueprint".
In the latter half of this year, Yuezhi'anmian released two models that solidified its position: Kimi K2 and Kimi K2 Thinking. The former, a non-thinking model, achieved State-of-the-Art (SOTA) performance among open-source models in multiple tests. The latter not only saw significant upgrades in capabilities but also became the only domestic model currently integrated with the renowned AI search engine Perplexity. Simultaneously, it was announced that Gemini3 Pro had recently topped the rankings. The previous Chinese model to receive such acclaim was the highly regarded DeepSeekR1.
The convergence of these two "lunar expedition blueprints" in 2025 once again underscores the importance of technological dividends for a company.
No Permanent Throne: Frequent "Comebacks" in the AI Race
In the grand narrative of tech business history, there has never been a permanent throne.
In the ever-evolving AI landscape, where technological iteration is measured in weeks or even days, the drama of "comebacks" and "being overtaken" unfolds almost daily.
Over the past three years, we've witnessed numerous moments of technological turnaround: OpenAI surpassing major tech giants with ChatGPT, Yuezhi'anmian gaining popularity with its long-text AI assistant Kimi, Claude series models countering OpenAI with programming prowess, DeepSeek going viral, domestic models like Kimi K2 gaining traction overseas, and the recent resurgence of the Gemini series.
The story of old kings being overthrown by new ones is repeating between OpenAI and Google.
According to foreign media outlet The Information, this week, OpenAI CEO Sam Altman sounded the red alert. The entity that has put this AI unicorn on guard is Google, which three years ago also triggered a red alert against OpenAI.
For Google, 2023 to 2024 marked its most vulnerable period. Factual errors during product launches once wiped out billions in market value overnight. Early demo videos of Gemini were criticized for exaggeration. Every attempt to counterattack seemed to be overshadowed by OpenAI's more impressive products.
Reflecting on the efforts of the past two years, Google CEO Sundar Pichai repeatedly emphasized the importance of full-stack capabilities.
"In this process, we significantly increased infrastructure investments—data centers, TPUs, GPUs, etc. The next step is to ensure we can integrate Gemini into all our products," Pichai said. "If you zoom out and look at the framework, it's extremely exciting. Because when you adopt a full-stack methodology, innovations at each level propagate up the entire chain."
Google officially sounded the counterattack's clarion call in March 2025.
At that time, OpenAI had a habit of targeting Google by releasing its products a day before Google's new model launches. This time, Google "returned the favor" by advancing the release of Gemini 2.5 Pro to a day before OpenAI's product launch. Gemini 2.5 Pro lived up to expectations, surpassing O3-mini in multiple indicators and stepping onto the arena of the strongest models.
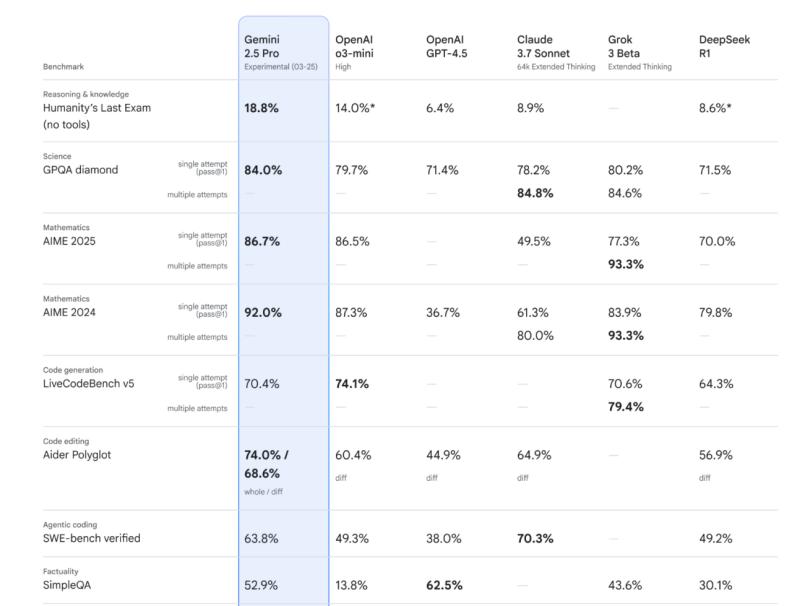
Subsequently, Google, as if opening its arsenal, unveiled a series of groundbreaking products, including the native multimodal model VEO 3 and the image editing model Nano Banana, which outperformed their contemporaneous competitors.
Ultimately, Gemini 3 became the pivotal product that detonated OpenAI. Test results showed that this new model comprehensively surpassed GPT-5.1, excelling in mathematical competitions, reasoning, multimodality, and other capabilities beyond Claude Sonnet 4.5 and GPT-5.1.
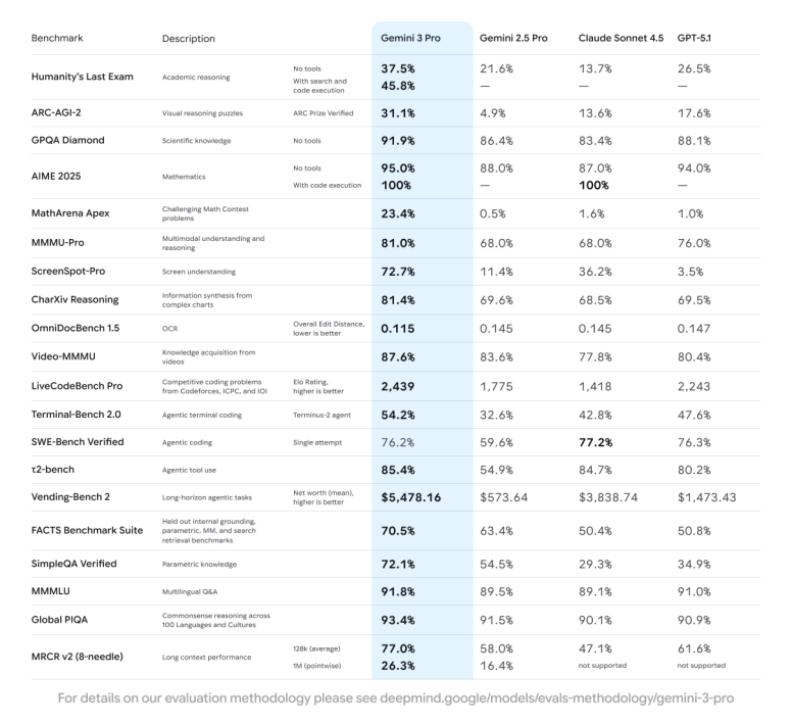
Coincidentally, a similar narrative unfolded with Yuezhi'anmian.
Six months ago, the company was at the center of a media storm. Although Kimi had stood out with its long-text capabilities, the emergence of DeepSeek's groundbreaking reasoning model R1, which gained traction through technology, posed a question to all AI startups: "Why hasn't XX become the next DeepSeek?"
After that, Yuezhi'anmian fell silent for six months.
Upon witnessing DeepSeek's success, Yang Zhilin, the founder of Yuezhi'anmian, made a bold decision in an internal meeting: to halt updates on the K1 series models and concentrate the company's core resources on algorithm development and the next-generation model, K2.
Compared to Google, as a domestic AI startup, Yuezhi'anmian faced a far harsher environment. Without decades of data accumulation or resources comparable to domestic and foreign giants, and with a valuation of less than $4 billion—a stark contrast to the hundreds of billions in valuations of overseas AI startups—this was not just a challenge for Yuezhi'anmian but a common dilemma for domestic large model startups.

Leveraging limited resources, Yuezhi'anmian also staged a comeback six months later.
First, in July of this year, the Kimi K2 model was released. It was one of the few open-source models at the time to reach trillion-parameter scale. As a non-thinking model, it achieved SOTA performance among open-source models in multiple indicators.
Last month, the Kimi K2 Thinking model officially launched, surpassing closed-source models like GPT-5 and Claude Sonnet 4.5 in dimensions such as HLE, reasoning, and Agent capabilities, reclaiming its position at the top of global open-source models.
"Is this another DeepSeek moment?" After the release of the Kimi K2 Thinking model, Thomas Wolf, co-founder of Hugging Face, commented on X.
Behind the model, one can also see Yuezhi'anmian's pursuit of foundational technology.
For instance, it was the first globally to adopt the second-order optimizer Muon in trillion-parameter model pre-training. According to officials, Kimi K2 enhanced training stability and Token usage efficiency, completing 15.5T token smooth training without any Loss Spike (sudden loss increase). It introduced the next-generation Kimi Delta Attention architecture, which, through a hybrid linear attention mechanism, not only improved the model's reasoning performance but also reduced inference costs severalfold.
"You might think we just got lucky with choosing Muon, but behind that choice, dozens of optimizers and architectures failed the test," the Yuezhi'anmian team responded during an AMA (Ask Me Everything) event they initiated.
Google and Yuezhi'anmian are merely microcosms of AI's evolution. Today, the AI industry is far from reaching the end of its comeback journey.
"The current environment is the most fiercely competitive in history. The only thing that truly matters is the speed of progress," said Demis Hassabis, CEO of DeepMind.
Technological Dividends Remain Key in the AI 2.0 Era
In the AI 2.0 era, the "long-distance race" for large model companies continues, with technology still serving as the engine driving enterprises forward, whether they experience a "comeback" or are "overtaken."
This fundamentally differs from the previous AI wave. Looking back to 2016, when AlphaGo ignited the AI 1.0 era, the industry quickly hit a ceiling due to the difficulty in solving technology generalization problems.
Take computer vision (CV) as an example. Back then, the industry faced more daunting challenges, such as heavy reliance on large-scale annotated data, poor technology generalization, and latency issues in real-time processing. Given these technological bottlenecks, competing on resources and ecosystems became crucial for startups.
However, the AI 2.0 era is entirely different. In the era of generative AI, the industry is still far from hitting a ceiling, with numerous unsolved problems across the field.
In the realm of large language models, the slowing down of the Scaling Law has not been effectively addressed. Regarding multimodal large models, both autoregressive and discrete technical routes are still under exploration, without definitive answers. Video generation still has room for improvement in terms of duration, consistency, and learning of physical laws. The deployment of Agents is bottlenecked by model generalization capabilities.
At this stage, if a company prematurely abandons enhancing its foundational model capabilities, it risks being overtaken by latecomers due to an unstable "foundation."
In 2025, a return to technology has become a keyword in the AI industry.
One can observe that both major and minor players are recruiting talent and concentrating resources to achieve model SOTA.
Not just Google and Yuezhi'anmian, recently, domestic giants including ByteDance and Baidu have also undergone organizational restructuring, with the core logic being to elevate the priority of large model R&D.
At the end of last month, Baidu underwent a significant TPG organizational restructuring, splitting its Wenxin business into foundational model and application model departments, with department heads directly reporting to Baidu CEO Robin Li. In April of this year, ByteDance's AI Lab was fully integrated into the Seed team to consolidate AI R&D forces.
Investment in technology remains the critical factor for staying in the top tier. Google's path has provided the best demonstration. After the comeback of Gemini 2.5 Pro, the image editing model Nano Banana (Gemini 2.5 Flash), also belonging to the Gemini family, quickly gained popularity. One could say that without the breakthroughs in language and visual understanding by the powerful, general-purpose Gemini foundation, Google would have struggled to produce a similarly competitive image model in a short time.
When R&D in foundational models achieves breakthroughs, companies can leverage this foundation to gain advantages in more areas through "learning by analogy."
Previously, during an AMA session on overseas social media, the Yuezhi'anmian team, while not specifically predicting the release time of the K3 model, indicated that it would likely utilize their developed KDA (Kernel-Attention Dual Architecture) architecture. A source close to Yuezhi'anmian told Guangzhui Intelligence that trillion-parameter scale could lay a solid foundation for subsequent reasoning models, and K2's multimodality is already underway.
Regardless of scale, volume, and including model performance, there is an objective gap between the two companies, both of which share the ambition of reaching for the moon. It is akin to the gradually narrowing divide in the competition between China and the United States. The technological rivalry between the East and the West, as well as the debate over open-source versus closed-source, are awaiting the arrival of the next singularity.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






