In-Depth Explanation of NeurIPS 2025 Best Papers: Making Them Accessible to All
 12/08 2025
12/08 2025
 773
773
The "Olympics" of the machine learning world, NeurIPS (Conference on Neural Information Processing Systems), has just wrapped up its latest edition. Have you ever pondered which AI breakthroughs truly resonate with researchers as pivotal? NeurIPS stands as the Oscars of AI research, drawing thousands of scholars each December to share their latest cutting-edge discoveries. Having a paper accepted by NeurIPS is a formidable achievement, but clinching a Best Paper Award? That can be a career-defining moment.

NeurIPS has just unveiled the year's top AI research, with this year's seven winners delving into topics as diverse as why AI models sound so similar and how to construct truly deep neural networks.
However, these papers might seem distant and arcane to the layperson. Hence, this article aims to demystify the papers, enabling you to fully grasp the essence of this year's NeurIPS 2025 Best Papers.
1. Winners' Papers:
Champion Paper: Artificial Hivemind Thinking (University of Washington, Carnegie Mellon University, Allen Institute)
Remember the common belief that diverse AI outputs could be achieved simply by altering the question's phrasing or employing multiple models? Well, think again!
This team tested over 70 language models and uncovered a disconcerting trend: they all produced remarkably similar responses.
If you pose the same creative question to ChatGPT, Claude, Gemini, or even domestic models like Deepseek, Doubao, and Qianwen, you'll receive different versions, all revolving around the same theme.
Worse still, individual models tend to repeatedly generate their own outputs. Researchers have termed this the "AI hivemind effect," where AI makes everything sound eerily similar.
Importance: If you've been relying on AI for brainstorming and feel the suggestions are becoming increasingly repetitive, it's not just your imagination. This issue is more complex than anyone imagined, especially when querying DeepSeek. Take a closer look at its chain-of-thought content, and you'll grasp the problem better. Addressing it requires fundamental changes in how models are trained and evaluated.
Gated Attention Mechanism for Large Language Models (from Alibaba's Qwen Team)
Alibaba's Qianwen research team discovered that incorporating a "gate" (akin to an intelligent filter) after the attention mechanism—a seemingly minor tweak—can continuously enhance LLM performance.
They tested over 30 variants, with model parameters reaching up to 15 billion.
The best part? This innovation is already implemented in Qwen3-Next, and the code is open-source.
NeurIPS judges have stated that this will "be widely adopted," or in academic parlance, "everyone will use it."
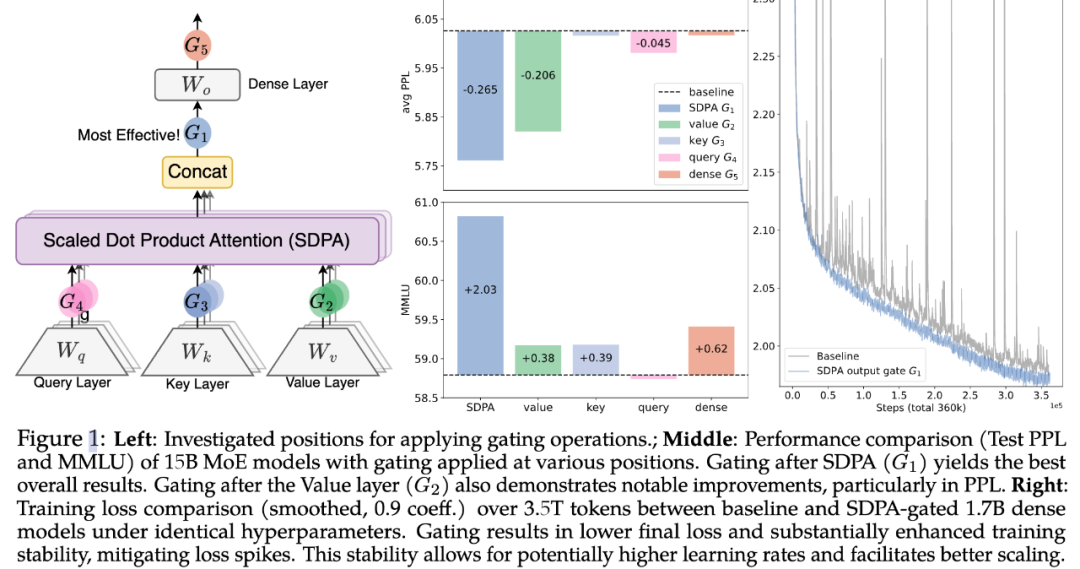
Importance: This technology is expected to be integrated into GPT-5, Gemini 2.0, and other next-generation models within the next 6-12 months. Your AI conversations will become more coherent, especially in longer interactions.
1000-Layer Networks for Self-Supervised Reinforcement Learning (from PSL Research University Paris)
Most reinforcement learning models employ 2-5 layers. These researchers proposed a bold question: What if we delve deeper?
They constructed networks with up to 1024 layers, enabling robots to learn goals without any human guidance.
Results: Performance improved by 2-50 times. It turns out reinforcement learning can scale like language models—you just need the courage to experiment.
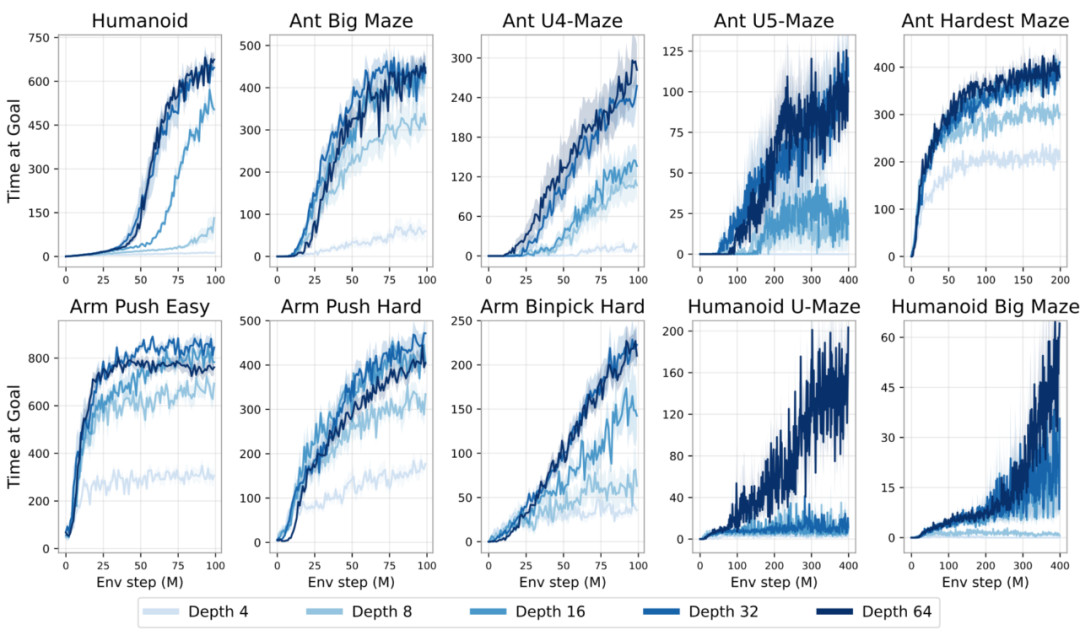
Importance: This paves the way for Physical AI, such as autonomous driving and robotics, to eventually match the capabilities of current language models. We can anticipate more capable robots and AI agents that learn complex tasks without step-by-step human guidance.
Why Diffusion Models Can't Memorize (from Princeton University, Warsaw University of Technology)
AI image generators are trained on millions of images. So why can't they directly generate identical copies? This paper provides a mathematical explanation.
During training, two timescales exist: initially, the model learns to create good images; later, it begins to memorize.
The crux is that the memorization phase grows linearly with dataset size, creating an optimal window to halt training before overfitting occurs.
It's as if the model has a built-in alarm clock saying, "Stop learning before you cheat."
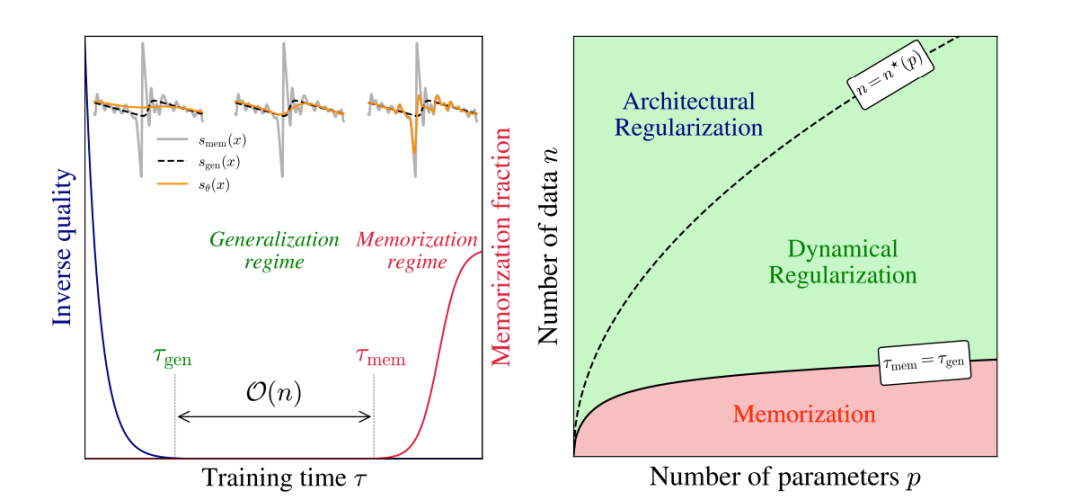
Importance: This explains why Midjourney, DALL-E, and Stable Diffusion generate entirely new images rather than copying training data. Understanding this dynamic will aid in building better, safer generative models.
Runner-Up Papers:
Does Reinforcement Learning Really Incentivize Reasoning? (from Leap Lab, Tsinghua University, Shanghai Jiao Tong University)
Spoiler alert: It doesn't. The team tested whether reinforcement learning training truly fosters new reasoning abilities in logical learning models or merely optimizes paths the base model already knows.
Answer: The base model's ceiling becomes the trained model's ceiling. Reinforcement learning makes models find good answers more efficiently but doesn't expand their fundamental reasoning capabilities.
It's akin to teaching someone test-taking tricks—they'll score better, but they haven't actually learned new knowledge.
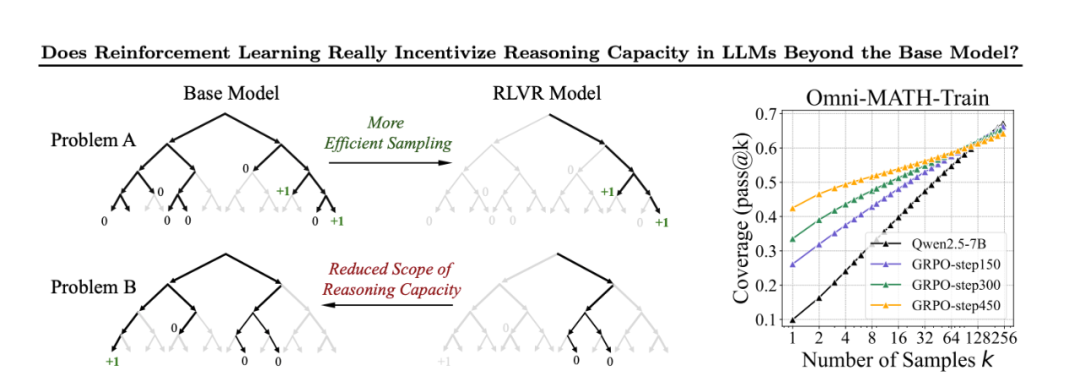
Importance: This challenges the current hype around reinforcement learning for higher-order thinking (RLHF) and reasoning models. If you want truly smarter AI, you need better base models and training data, not just more reinforcement learning on existing models.
Optimal Mistake Bounds for Transductive Online Learning (from Kent, Purdue, Technion, Google)
This paper solves a 30-year-old theoretical problem about how many mistakes a learning algorithm makes when it can access unlabeled data. The math is complex, but the conclusion is groundbreaking: unlabeled data boosts learning speed quadratically (square root improvement). That's a huge theoretical win.
Importance: This provides theoretical justification for using vast amounts of unlabeled data, which powers today's foundational models.
Superposition Yields Robust Neural Scaling (MIT)
This paper finally explains why bigger models work better. The secret lies in "superposition"—the ability to represent more features than their dimensions by cleverly packing information.
When models strongly exhibit this trait, loss scales inversely with data size, applying to nearly any data distribution.
This confirms the Giraffe Scaling Law and explains why the "bigger is better" trend persists.
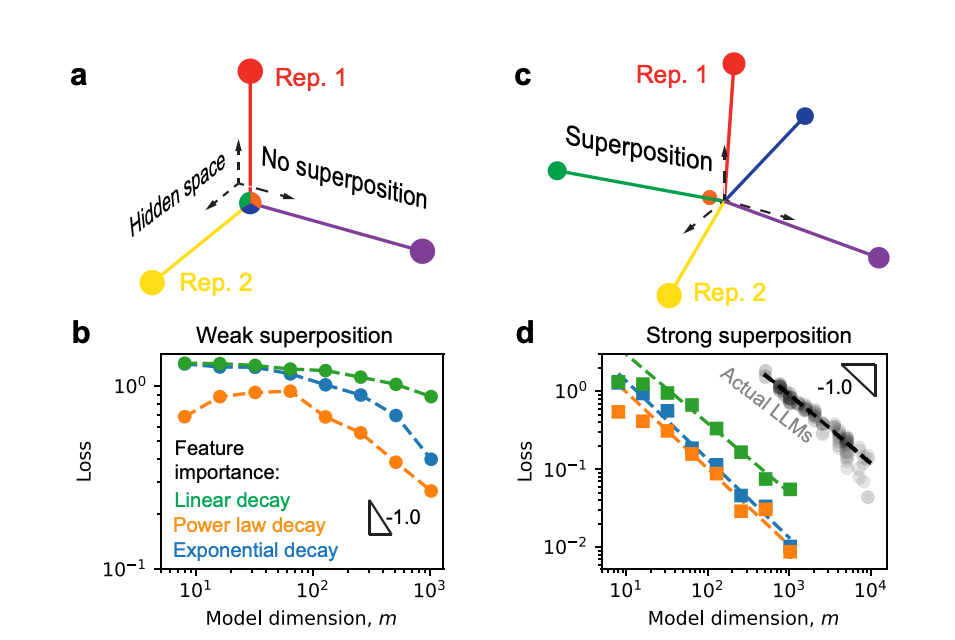
Importance: This explains why companies keep building bigger models and validates the Giraffe Scaling Law. Expect the "bigger is better" trend to continue for the foreseeable future.
2. NeurIPS Also Featured: Google's Memory Breakthrough
While these awards dominated headlines, Google quietly released research that could be game-changing: Titans and MIRAS, two architectures granting AI models true long-term memory.
Existing models hit bottlenecks with context length. Even if you feed Claude or GPT millions of tokens, they struggle to truly remember and effectively use all that information. Consider autonomous driving scenarios—current assisted driving responds instantly but cannot review or reason over longer periods, like 15+ seconds, due to memory and computational demands.
Titans solves this through "surprise measurement"—essentially teaching AI to remember like humans.
Here's how it works: Humans easily forget mundane details but remember surprising events.
Titans does the same. While processing text, it constantly asks itself: "Is this new information surprising compared to what I know?" If highly surprising, store permanently; if not, skip.
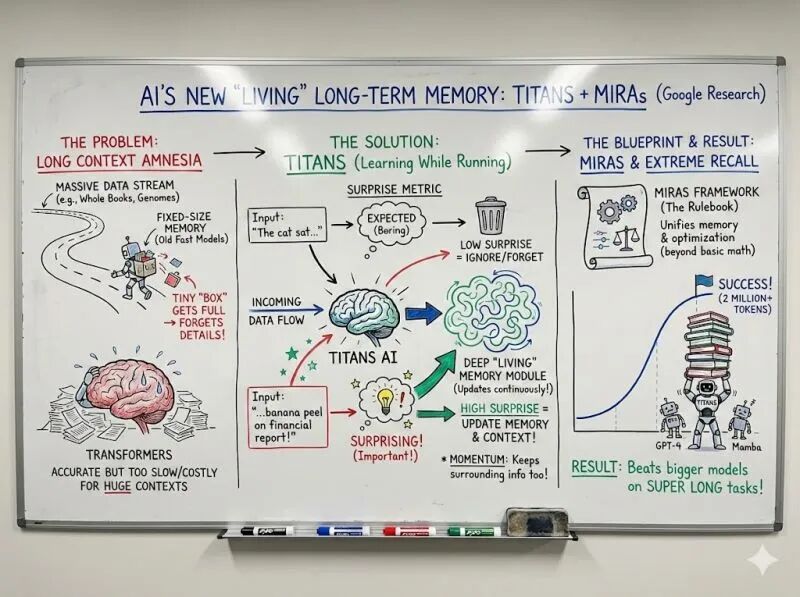
Example: If you're reading a financial report and suddenly see a sentence about banana peels, this massive unexpected signal tells the model "This is weird and important—remember it."
But if the report mentions "quarterly earnings" for the tenth time, the model says "Got it, move on."
The results are astonishing: Titans can handle over 2 million token contexts and perform exceptionally well on ultra-long context tasks with far fewer parameters than GPT-4. It combines the speed of recurrent models with the accuracy of Transformer models.
Importance: Current AI often forgets context. Ask Claude to analyze a 200-page document and cite something from page 5? It'll likely fail. The Titans architecture lets AI truly remember everything you've discussed, every document you've shared, every preference you've mentioned—even across millions of words.
Expect variants of this approach to start appearing in production within the next 6-12 months. Google is already developing "Hope," a version that can self-modify and optimize its own memory.
3. As for the Best Papers...
The gated attention mechanism is already in production. The hivemind problem will drive researchers to develop models that deliberately achieve output diversity. And the deep scaling of reinforcement learning promises a new generation of powerful autonomous driving, robotics, and Physical AI agents.
If you use AI tools daily, keep an eye out for models explicitly promoting output diversity or deeper reasoning capabilities; these papers merely lay the groundwork for what's to come.
References and Images
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond) - UOW /CMU, etc.
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free - Qwen, etc.
1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
Superposition Yields Robust Neural Scaling
Optimal Mistake Bounds for Transductive Online Learning
*Unauthorized reproduction or excerpting is strictly prohibited. To access this article's references: Join our Knowledge Planet to download a wealth of reference materials from our official account, including the above.
>>>>
-
![]()
AIS-3700 Integrated Module | Synchronous Monitoring of PM2.5 and CO₂ for a High-Quality, Healthy Cabin
-
![]()
Alibaba and Google March Together in the Agent Era
-
![]()
"National Shrimp Farming": 50 Days of AI Arbitrage Frenzy and Its Sudden End
-
![]()
NetEase’s Timeless Classics Shine in Q1, Reinforcing Global Expansion
-
From 'Construction' to 'Effective Management': Shenzhen's Innovative Approach Tackles the 'Last Mile' Challenge in Telecom Governance
-
![]()
A New Yardstick in the AI Era Measures the Path of Tech Giants
-
![]()
Daily Earnings of $650 Million Fall Short: What’s Next for NVIDIA’s Growth Trajectory?
-
![]()
Industrial Integration: Kepler Chooses a Smarter Path






