Hot Topic | DeepSeek V3.2 Major Update: Shifting Focus from Model Layer to System Layer
 12/08 2025
12/08 2025
 668
668
Preface:
Recently, DeepSeek surprised the tech world with a significant update, introducing two fully developed models: DeepSeek-V3.2 and DeepSeek-V3.2-Speciale. Renowned for their code generation and robust reasoning capabilities, these models are the [top picks for tech enthusiasts].
These models not only match the reasoning prowess of GPT-5 and compete head-to-head with Gemini 3.0 Pro, but they also shatter the industry myth that [open-source models always trail closed-source models by 8 months] through a fully open-source approach. This move has accelerated the arrival of the 2026 AI Agent era, breaking through the smokescreen.
Image Source | Network

Technological Breakthroughs: Three Major Innovations Redefine AI Capabilities
The two models launched by DeepSeek are like [twin stars], precisely targeting different domains and are supported by a robust technological framework validated through real-world applications.
V3.2 emphasizes [balanced practicality], making it suitable for daily Q&A, general Agent tasks, and tool invocation. Its reasoning capabilities are on par with GPT-5.
The Speciale version, on the other hand, is designed for [ultimate reasoning]. It integrates the theorem-proving capabilities of DeepSeek-Math-V2, matching Gemini 3.0 Pro in mainstream reasoning benchmark tests. This version excels in complex mathematical reasoning, programming competitions, and academic research, earning it the title of [gold medal harvester].
For a considerable period, the attention mechanism in traditional large models has been stuck in a deadlock, where computational complexity grows exponentially with long sequences. The O(L²) algorithm logic makes 128K context inference a [costly luxury].
The DeepSeek team's innovative DSA (DeepSeek Sparse Attention) mechanism has completely overturned this status quo.
DSA reduces computational complexity from O(L²) to O(L·k) (where k is significantly smaller than L) through two core components: the [Lightning Indexer] and [Fine-Grained Token Selection].
Simply put, while traditional models process long texts as if reading an entire encyclopedia word by word, DSA functions more like an intelligent search engine, quickly scanning to build an index and then precisely locating key information.
In H800 cluster tests, the cost per million tokens during the prefilling phase of 128K sequences dropped from $0.7 to $0.2. During the decoding phase, it fell from $2.4 to $0.8. Inference speed increased by 3.5 times, and memory usage decreased by 70%, with no significant loss in performance.
The significance of this efficiency revolution is profound. When the cost of long-text inference becomes negligible, AI's ability to process entire books and complete project code will become widespread, clearing the biggest obstacle for implementing subsequent complex Agent tasks.
The gap between open-source and closed-source models often lies in the resource investment in [post-training].
The DeepSeek team discovered that one of the core reasons for the weakness of open-source models in complex tasks was the insufficient computational resources allocated during the post-training phase.
To address this, they broke industry norms by increasing the computational budget for reinforcement learning (RL) to over 10% of the pre-training cost, which is extremely rare for open-source models.
To ensure stable large-scale RL training, the team made triple optimizations to the GRPO algorithm. They corrected systematic errors through unbiased KL estimation, filtered overly deviated negative samples with an offline sequence masking strategy, and designed Keep Routing operations for MoE models to ensure parameter optimization consistency.
More critically, they adopted an [expert distillation] strategy. They first trained dedicated models for six domains, including mathematics, programming, and general reasoning. Then, they used these expert models to generate high-quality data for training the final model, enabling V3.2 to achieve a qualitative leap in hardcore tasks.
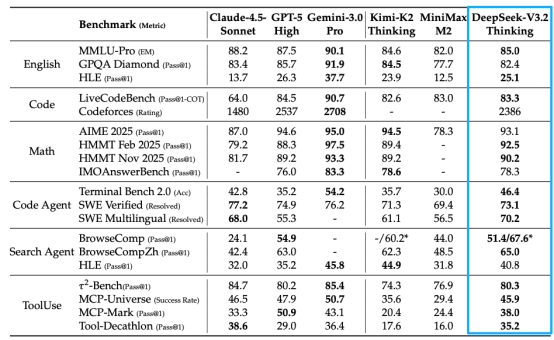
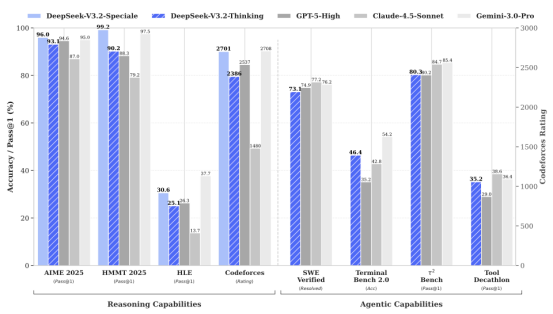
Empirical data confirms the effectiveness of this strategy. In the SWE-Verified code repair benchmark, V3.2 achieved a resolution rate of 73.1%, nearly on par with GPT-5 High's 74.9%.
In the Terminal Bench 2.0 complex coding task, its 46.4% accuracy rate significantly surpassed GPT-5 High's 35.2%.
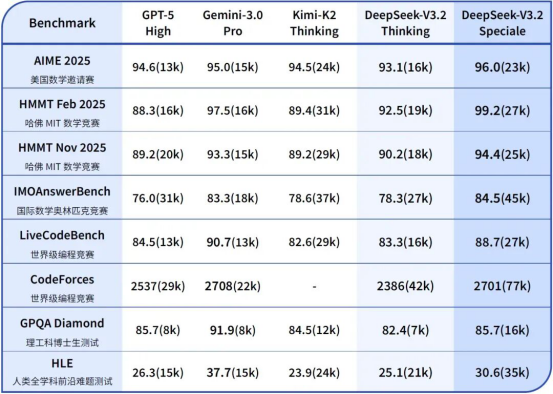
The Speciale version even exceeded GPT-5 High's 94.6% and Gemini 3.0 Pro's 95.0% in the AIME 2025 math competition with a 96.0% pass rate, demonstrating the ultimate potential of open-source models.
If DSA addresses [efficiency issues], then the mechanism of [integrating thinking into tool invocation] resolves the [core pain point] of state drift in AI Agents.
Traditional agents tend to [lose sight of their original purpose] during multi-round tool invocations, such as suddenly recommending high-intensity hiking when planning a trip for the elderly. This is essentially a disconnect between the reasoning process and tool execution.
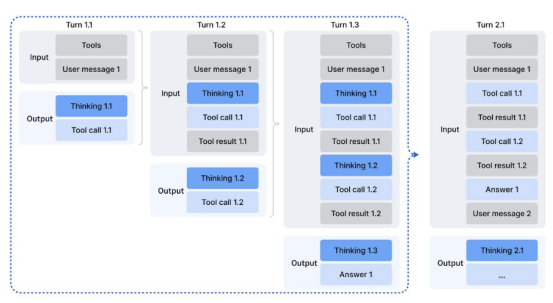
DeepSeek V3.2 innovatively introduces a [thinking retention] mode, becoming the first open-source model to support tool invocation in [thinking mode].
Its core logic is that historical reasoning content is only discarded when new user messages are introduced. If only tool-related messages are added, the reasoning process is continuously retained.
This design is akin to installing a [hippocampus] in AI, allowing the model to remember [why it took certain actions] when invoking tools. It continuously optimizes decisions based on historical execution results without restarting the reasoning process.
To hone this capability, DeepSeek built a large-scale Agent task synthesis pipeline, generating 1,827 task-oriented environments and 85,000 complex instructions.
Beyond Technological Showmanship: Entering the Application Competition Phase
Over the past two years, the ChatBot model has allowed users to experience the novelty of AI. However, the limitation of [only being able to converse but not take action] has gradually become apparent.
Users are tired of copying and pasting across different windows, and businesses complain that AI cannot solve problems in a closed loop. This diminishing marginal effect model is destined to have a low commercial value ceiling.
DeepSeek clearly recognizes this, and the V3.2 version emphasizes [general Agent task scenarios], essentially declaring its strategic shift.
Behind this AI transformation lies a deeper technological rivalry between China and the United States.
Over the past three years, the United States has attempted to stifle the evolution of Chinese AI through high-end chip bans, hoping that physical-level blockades would keep Chinese AI at a second-rate level indefinitely.
However, the iterations of DeepSeek V3 and other leading domestic models have already proven the [temporary ineffectiveness] of such blockades.
Chinese vendors have forged a unique path of [application-driven underlying technology], compensating for the unavailability of top-tier single cards through algorithmic optimizations. They enhance parameter utilization through MoE architecture innovations when compute cluster interconnections are limited and squeeze efficiency through software-hardware collaboration despite hardware shortcomings.

Under such harsh conditions, Chinese AI has not only trained models comparable to GPT-4.5 and even GPT-5 levels but has also formed unique advantages in application implementation.
The focus of the rivalry is shifting from hardware blockades to ecological barriers.
Silicon Valley giants adopt an aggressive approach. OpenAI uses Sora to dominate short video content production, and Google attempts to establish a [global AI operating system] defined by itself. If successful, all enterprises dependent on the APP ecosystem will face a significant competitive disadvantage.
Chinese vendors, on the other hand, are building a local ecosystem together. From Alibaba's QianWen and Ant Group's LingGuang to ByteDance's DouBao and DeepSeek, although the paths differ, the goals align.
They aim to establish Chinese standards in the system-level Agent track, transforming AI from an [explicit conversationalist] to an [implicit controller], and penetrating into all scenarios such as shopping, payment, logistics, and social media.
The release of DeepSeek V3.2 is a microcosm of the cost reduction and practicality surge of high-performance models. When inference costs become negligible and model contexts can accommodate entire books, quantitative changes finally trigger qualitative changes.
The essential difference between Agents and ChatBots lies in their ability to reconstruct the physical world.
At the software level, AI will completely disrupt existing workflows. In the past, we purchased CRM systems to manually enter customer information; in the future, we will hire [sales Agents] to automate the entire process.
In the past, we relied on SaaS software to handle transactions; in the future, we will enter the [Service as a Software] era, where the service itself is the software.
DeepSeek V3.2's balanced reasoning capabilities are tailor-made for such long-chain complex decision-making.
Breaking Monopolies: AI Enters the [Free Top-Tier] Era
The most subversive move of DeepSeek V3.2 is not its technological parameter breakthroughs but its choice of complete open sourcing.
Model weights, chat templates, and local operation guides are fully open on Hugging Face, allowing small and medium-sized enterprises and even individual developers to use capabilities comparable to GPT-5 at zero cost.
This combination of [top-tier performance + free open source] is reshaping the global AI power structure.
For a long time, closed-source models have dominated complex tasks by leveraging massive computational investments and data advantages. However, the release of DeepSeek V3.2 has ended the myth that [open-source models always lag behind].
In reasoning benchmark tests, V3.2 competes neck and neck with GPT-5, only slightly inferior to Gemini 3.0 Pro.
In Agent evaluations, it scores higher than fellow open-source models Kimi-K2-Thinking and MiniMax M2.
The Speciale version even surpasses some closed-source models in international competitions, proving that open-source models are fully capable of ranking among the first tier.
The core logic of this breakthrough lies in DeepSeek's discovery of the [correct approach to post-training].
The bottleneck of post-training is overcome through optimization methods and data rather than waiting for a stronger foundational model.
Through DSA architecture innovation, over-allocated reinforcement learning resources, and large-scale Agent task synthesis, open-source models have finally freed themselves from dependence on [brute-force computational power] and forged a more efficient and lower-cost evolutionary path.
The cost reduction brought by the DSA mechanism has far-reaching implications beyond imagination. This cost advantage will accelerate the trend of [AI tools replacing traditional software].
When AI can help ordinary people plan trips, handle work, and solve professional problems at extremely low costs, AI will truly penetrate into the operating system level, becoming a fundamental service like water and electricity.
Conclusion:
As Google's Gemini 3.0 Pro sweeps multimodal evaluations, OpenAI's Sora downloads continue to climb, and Chinese and American tech giants collectively bet on Agents, a definitive trend has emerged.
With open-source models breaking closed-source monopolies, Agent technology reconstructing the physical world, and Chinese and American vendors engaging in deep rivalry at the system level, the 2026 AI battlefield is destined to be spectacular.
Partial references: Jiedian Finance: 'Behind Deepseek's Major Update: The AI War is Imminent, It's Time to Act', Quantumbit: 'DeepSeek-V3.2 Series Goes Open Source, Performance Directly Comparable to Gemini-3.0-Pro', Lei Technology: 'Powerful and Affordable! DeepSeek V3.2 Will Make Google and OpenAI Panic Again', NetEase Technology: 'Directly Competing with Gemini 3.0 Pro! DeepSeek V3.2's Actual Performance is Indeed Strong, but These Three [Flaws] Must Be Guarded Against', Machine Heart: 'From MiniMax to DeepSeek: Why Are Leading Large Models Betting on [Interleaved Thinking]?'
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






