Google's New Architecture Is Mind-Blowing! What Strategies Have the Doubao Models Employed to Equip AI with Long-Term Memory?
 12/09 2025
12/09 2025
 544
544
Long-term memory is transitioning from a makeshift engineering solution to a central pillar of large-model capabilities.
Recently, in its paper titled "Nested Learning: The Illusion of Deep Learning Architectures," Google unveiled a new framework called HOPE, aiming to tackle the long-standing issue of long-term memory in large models.
This architecture has drawn considerable attention because long-term memory has long been a bottleneck impeding the development of large models, even influencing the scope and depth of AI implementation in intelligent agents.
Nowadays, it's relatively straightforward to get AI to produce a polished response. The true challenge lies in enabling it to recall crucial details from a conversation a week earlier, even when the task has shifted, and to continuously update its personalized memory of the user. Only at this juncture do large models truly start to resemble "intelligent agents that are always at work" rather than disposable tools.
It can be argued that while a large model's "short-term capabilities" determine its ability to craft coherent sentences, its long-term memory truly defines whether it deserves to be called an "assistant."
This is precisely why the Titans architecture proposed by Google's research team on the last day of the previous year has been repeatedly revisited and discussed in 2025. This paper doesn't attempt to answer the age-old question of "how much longer can context windows be extended?" Instead, it tackles a more fundamental proposition:
When attention serves only as short-term memory, how can large models genuinely acquire long-term memory?

Image Source: Google
In Titans, the Transformer's self-attention mechanism is explicitly designated as a "short-term system," while an independent neural long-term memory module is tasked with selectively storing and retrieving key information across context windows. This approach essentially redefines the "brain structure" of large models.
Looking back at this year, from Google's Titans to ByteDance's MemAgent, and now to Google's HOPE architecture, significant strides have been made in long-term memory for large models.
Over the past year, whether it's Google's expansion into a multi-timescale memory system or the industry's intensive exploration of ultra-long contexts, intelligent agent (Agent) memory, and external memory platforms, all point to the same trend: long-term memory is evolving from a makeshift engineering solution to a central pillar of large-model capabilities.
Models are no longer just competing on who has a longer context window or more parameters; instead, they are evaluated on who remembers more selectively, stably, and in a "human-like" manner. Long-term memory in large models is no longer just a performance metric in research papers but a critical capability that determines "whether they can be used over the long term and trusted."
From Titans to HOPE: Long-Term Memory Forms the Bedrock for Intelligent Agents
In mid-August of this year, Google rolled out two major updates for Gemini: an "auto-memory" feature based on chat context and a privacy-preserving "temporary chat" mode.
As the names imply, "auto-memory" enables Gemini to learn from a user's past chat history, remembering key details, preferences, long-term project backgrounds, and recurring needs, thereby facilitating proactive and personalized responses in subsequent interactions.
Similar changes are not exclusive to Gemini. Over the past year, from ChatGPT and Doubao to the November launch of iFLYTEK's Spark X1.5, nearly all leading AI assistants have introduced "long-term memory modules" to maintain continuity across sessions and scenarios, enabling AI to update and remember user profiles, historical task states, and key decision-making information.

Image Source: iFLYTEK
However, tracing back further, these product-level changes are not isolated incidents but rather direct outcomes of the underlying technological evolution of large models in 2025.
Firstly, it has been reaffirmed that long contexts are not the ultimate goal for large-model memory.
While ultra-long contexts remain important, they are increasingly viewed as an "amplified form of short-term memory"—costly and unable to determine which information is worth retaining long-term. The significance of Titans lies not in extending context windows further but in clearly distinguishing that attention is merely a short-term system, while long-term memory must be a sustainably updatable component.
In November, Google proposed treating the model training process itself as a layer of memory (Nested Learning) and introduced an upgraded HOPE architecture, beginning to conceptualize "memory" as a continuum across multiple timescales. Short-term context, mid-term states, and long-term experiences are no longer isolated modules but are distributed within the same learning system based on update frequency and stability.
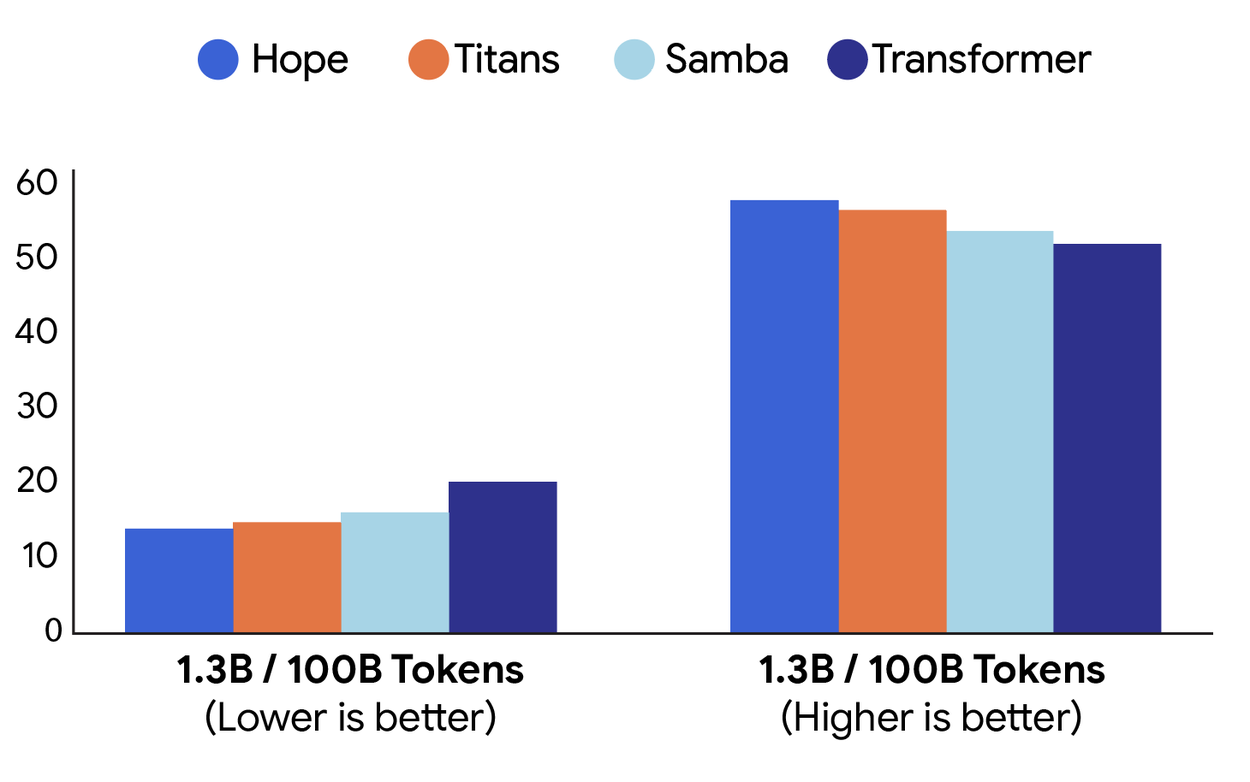
Comparison of Perplexity (Left) and Commonsense Reasoning (Right) in HOPE, Titans, and Transformer Architectures. Image Source: Google
Meanwhile, the focus of long-term memory has shifted from "remembering text" to "remembering experiences." The common practice of using vector databases or knowledge bases for Retrieval-Augmented Generation (RAG) as a model's "external hard drive" is now being reevaluated. Long-term memory is no longer just about retrieving answers but needs to participate in the reasoning process, influencing the model's decisions and behaviors.
Also in November, Google introduced the Evo-Memory benchmark and ReMem framework, explicitly incorporating long-term memory into the workflow of intelligent agents to assess whether models can extract experiences, review strategies, and genuinely apply them in subsequent tasks. Long-term memory no longer serves merely for dialogue but directly determines whether intelligent agents possess the capability for continuous evolution.
In fact, ByteDance and Tsinghua University's jointly proposed MemAgent trains models through reinforcement learning to "learn to prioritize" within ultra-long contexts, enabling models to proactively form long-term memory habits rather than passively stacking text. Although these approaches differ, they all indicate that long-term memory must gradually be internalized as a model capability rather than just an engineering add-on.
China's Approach to Long-Term Memory: How Do MiniMax, Doubao, and DeepSeek Differ?
Earlier this year, MiniMax announced the open-sourcing of its first large model with a linear attention architecture, pointing out that existing intelligent agents' "long-term memory" is mostly just an external RAG tool, which strictly speaking does not qualify as memory.
Indeed, this is true. In early practice, vector databases combined with RAG were almost the default solution: retrieve what needs to be remembered. However, as intelligent agents increasingly undertake multi-step tasks, this "retrieve-and-go" approach to memory has begun to show its limitations.
Recently, Doubao Mobile has sparked industry-wide discussions on AI phones. In fact, Doubao's exploration of long-term memory within its Agent system is also highly representative. Its long-term memory is integrated into the entire workflow, used to preserve user profiles, task states, phased conclusions, and even failed experiences.
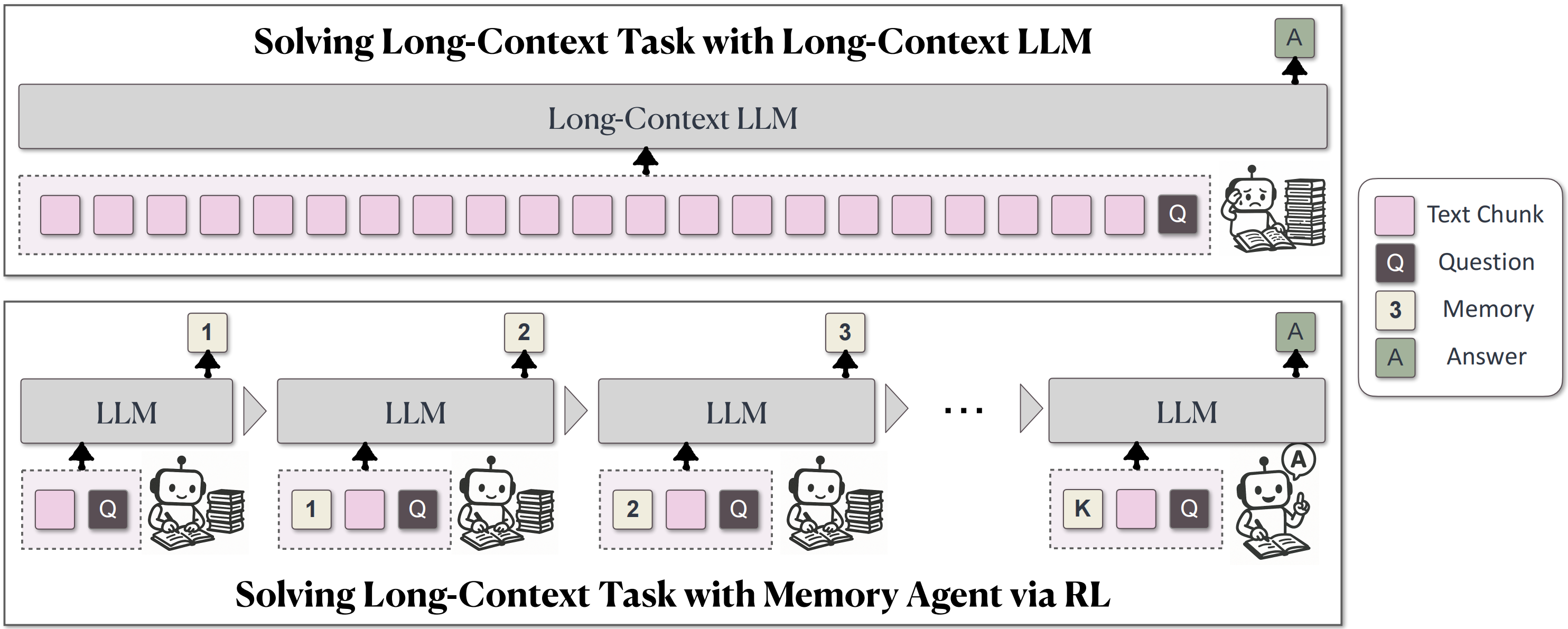
Basic Structure of MemAgent. Image Source: ByteDance
Solutions like MemAgent do not aim to extend context length but rather train models to understand which information influences subsequent decisions. In short, memory is no longer just about retrieving information but participating in judgment.
From this perspective, MemAgent, jointly proposed by ByteDance and Tsinghua University, is not an isolated academic effort. It focuses not on compressing text or expanding capacity but on using reinforcement learning to enable models to "learn to prioritize" within ultra-long contexts and continuous tasks. Models must understand which information is worth retaining, which is only suitable for short-term use, and even which should be actively forgotten.
This reflects a clear judgment: long-term memory, if it cannot alter a model's action strategies, remains essentially just an engineering cache.
As mentioned earlier, both industry practices and various system designs centered around intelligent agents emphasize the retention of "process information." This explains why reinforcement learning is beginning to be used for training "memory behaviors" rather than simply expanding knowledge bases.
In contrast, MiniMax pushed the model's context window to millions or even tens of millions of tokens early this year through architectural innovations like linear attention.
This was not merely to set new benchmarks but to attempt system simplification through capacity expansion. When a model can stably "see" more content at once, some external memory that previously required frequent scheduling and repeated retrieval can temporarily be brought into the context's field of view.
However, MiniMax's practice did not stop at "ultra-long context windows."

Image Source: MiniMax
Instead, they introduced an independent memory layer to manage long-term knowledge and experiences. First, solve "whether it can fit," then discuss "whether it should stay." Under this framework, long-term memory no longer relies entirely on frequent RAG calls but reduces overall complexity through a larger in-model field of view and fewer system switches.
DeepSeek's strategy, on the other hand, provides an interesting contrast. DeepSeek does not bet on complex long-term memory mechanisms within the model but explicitly externalizes them, relying on RAG, vector libraries, or various memory components. This is not about avoiding the issue but is based on a more restrained judgment:
Long-term memory is highly dependent on specific scenarios, with vastly different memory forms required for different applications. Rather than implementing a one-size-fits-all solution within the model, it is better to provide a high-quality reasoning core and let developers combine memory solutions as needed.
In Conclusion
In 2025, the true transformation of long-term memory in large models lies not in the refreshment of individual metrics but in the complete redefinition of its role. From early reliance on RAG as an "external hard drive" to its gradual integration into model structures and intelligent agent workflows, long-term memory has begun to influence decision-making and shape behavior, rather than just serving as a passive information container.
Perhaps it can be said that the true future differentiation among large models will no longer lie solely in model size or inference speed but also in a mature, controllable, and sustainably evolving memory mechanism. Because only when a model can truly remember and manage information effectively can it be used over the long term, relied upon repeatedly, and even entrusted with greater decision-making authority.
Gemini, Doubao, MiniMax, Large Models, Intelligent Agents
Source: Leikeji
Images in this article are from the 123RF licensed image library.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






