Beihang University & Meituan and Others Unveil Latest EditThinker: Equipping AI Image Editing with a 'Brain', Boosting Intelligence of Flux and OmniGen2 Instantly!
 12/09 2025
12/09 2025
 699
699
Interpretation: The Future of AI-Generated Content
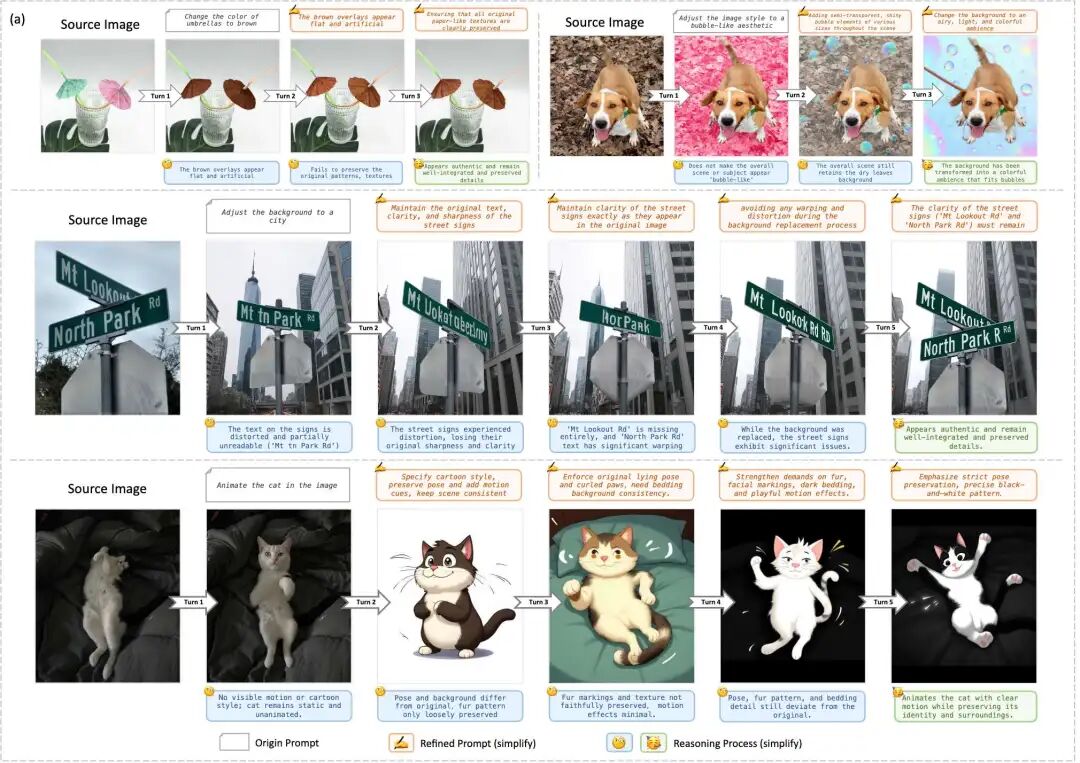
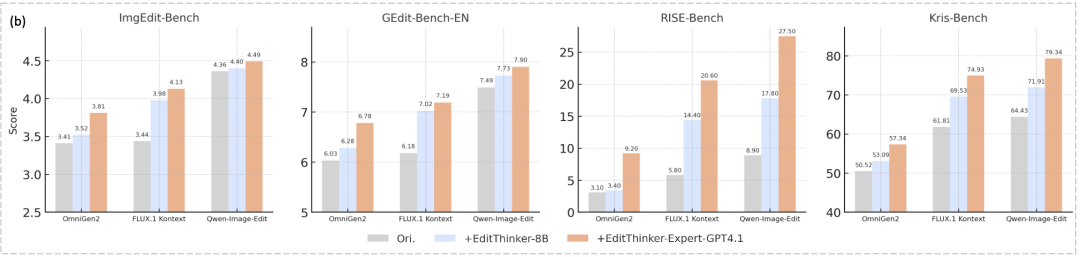
Figure 1. Overview of EditThinker. Subfigure (a) illustrates the multi-round thinking-editing process, which iteratively critiques, refines, and repeats editing instructions. Subfigure (b) reports results from four image editing benchmark tests, demonstrating significant improvements in three existing editing methods. We utilized FLUX.1 Kontext Development Edition (labeled as FLUX.1 Kontext in the figure).
Key Highlights
Breakthrough in Single-Round Instruction Paradigm: Addressing the limitations of existing single-round instruction-following models, we innovatively propose a new paradigm of 'Thinking While Editing,' reconstructing image editing tasks as an iterative reasoning process.
Construction of Reasoning-Driven Model: EditThinker, a reasoning-driven multimodal large language model trained through joint supervised fine-tuning and reinforcement learning, capable of iteratively critiquing, refining, and replanning editing instructions.
Creation of Large-Scale Dataset: Introducing THINKEDIT-140k, a multi-round dialogue dataset comprising 140,000 samples. This dataset provides unified instruction optimization supervision signals, specifically designed for reasoning-based training processes.
Verification of Broad Applicability: Extensive experiments conducted on four widely used benchmarks demonstrate the method's exceptional effectiveness across diverse editing scenarios and different editing models.
Summary Overview
Problem Addressed
Existing instruction-based image editing methods are constrained by a single-round execution paradigm, struggling to effectively address inherent model randomness and lack of reasoning mechanisms. This results in low instruction-following accuracy and deviations between editing results and user intent, particularly inadequate in complex or multi-step editing tasks.
Proposed Solution
We introduce an iterative reasoning framework called 'Think While Edit' (Think-while-Edit), reconstructing image editing as a cognitively optimizable loop: automatically evaluating results, critiquing deficiencies, refining original instructions, and regenerating after each editing round until user requirements are met. The framework centers around a unified reasoning engine, EditThinker, enabling dynamic instruction refinement and re-execution.
Technologies Applied
Construction and training of a multimodal large language model (MLLM), EditThinker, jointly outputting critique scores, natural language reasoning processes, and refined editing instructions.
Adoption of a training strategy combining supervised fine-tuning and reinforcement learning to align the model's 'thinking' (reasoning and critique) with 'editing' behaviors.
Release of the THINKEDIT-140k multi-round dialogue dataset (containing 140,000 samples), providing structured multi-round instruction optimization supervision signals to support reasoning-driven model training.
Achieved Results
Extensive experiments on four mainstream image editing benchmarks demonstrate that our method significantly and substantially enhances the instruction-following capabilities of various image editing models. Regardless of editing task complexity or underlying model architecture, it exhibits strong generalization and broad applicability, offering a new paradigm for high-fidelity, semantically aligned instructional image editing.
Thinking as Editing
To overcome inherent limitations of current editing models in single-round instruction following, this paper proposes the 'Thinking as Editing' framework, mimicking the human cognitive process of 'critique, reflection, and editing' during creative tasks.
Overall Framework
Previous methods primarily operate in a single-round manner: given a source image and original instruction, the editing model directly generates the final edited image. This process lacks the ability to iteratively refine outputs or recover from failed edits.
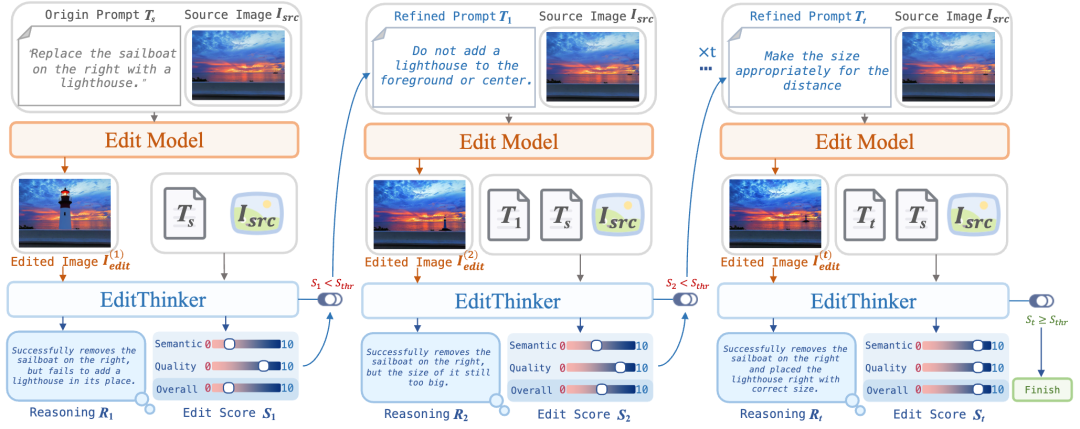
Figure 2. The 'Think While Edit' process. EditThinker is a multi-round instruction iterative optimization framework. In the first round, the original image Isrc and instruction T are input into the editor to generate the initial edited image. This edited image, along with the original image and instruction, is subsequently input into EditThinker, which generates an editing score St, refined prompt Tt, and corresponding reasoning process Rt. If the score falls below a threshold, the framework proceeds to the next iteration using the refined prompt until a satisfactory result is achieved.
To address this limitation, this paper introduces an MLLM-based thinker that transforms single-pass editing into an iterative, multi-round process. Our framework explicitly decouples the editing workflow into two distinct roles: a thinker for judgment and reasoning, and an editor for execution. The thinker is trained via SFT and RL, while the editor can be any existing image editing model (e.g., Qwen-Image-Edit, Flux-Kontext). Specifically, during each iteration, the thinker evaluates the previous output and simultaneously generates an instruction-following score, refined instruction, and reasoning process, as expressed by the following formula:
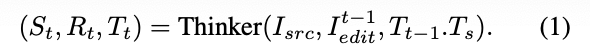
Subsequently, the editor executes the new instruction on the source image, generating an updated result, as shown in the following formula:
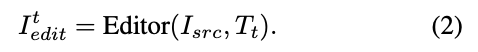
This iterative process, known as the 'critique-improve-repeat' loop, continues until the editing objective is achieved.
Design of EditThinker
This paper models EditThinker as a dual-role model, simultaneously performing evaluation and planning. Unlike decoupled approaches using separate models for evaluation (MLLM-based scorer) and planning (LLM-based rewriter), EditThinker executes both tasks in a single forward pass.
The key insight is that effective planning requires in-depth evaluation: the model must first critique the previous output (generating score and reasoning) before generating a refined instruction. By generating before , EditThinker creates an explicit chain of thought, basing instruction refinement on visual critique of and .
To implement this dual-role design, we define a structured input-output format that explicitly encodes the evaluation-then-planning process.
Input Tuple. EditThinker receives a multimodal tuple at each iteration, providing complete context of the editing state: and represent the original reference, is the current result to critique, and is the previous instruction that generated it.
Structured Output Format. The output is a structured text string that serializes EditThinker's reasoning process:

Here, represents the perceptual quality of , and denotes semantic alignment with the original instruction relative to . Both scores range from 0 to 10.
Training of EditThinker
Training EditThinker for this dual-role task requires specialized datasets and a multi-stage training strategy. We adopt a two-phase approach: first, supervised fine-tuning (SFT) to learn the output format and basic reasoning, followed by reinforcement learning (RL) to optimize instruction refinement based on actual editing feedback.
Supervised Fine-Tuning (Cold Start)
Using a demonstration dataset from an expert (GPT-4.1) (see Section 4), the base MLLM learns to adopt our structured I/O format (e.g., , , ), mimicking the expert's reasoning style and understanding principles of critique and instruction refinement.
Reinforcement Learning Fine-Tuning (RLT)
The SFT model learns the expert's ideal reasoning approach, but this reasoning is not grounded in the actual limitations of real editors. The model never observes real editing failures or learns which types of instructions are prone to misinterpretation by specific editors. Consequently, an instruction that appears optimal to the SFT model may still fail when executed by a real editor (e.g., Qwen-Image-Edit). This creates a gap between ideal reasoning and actual execution.
To bridge this gap, we introduce an RL phase that optimizes EditThinker based on actual editing feedback. We employ standard GRPO (Group Relative Policy Optimization) and design a carefully crafted reward function. As previously mentioned, EditThinker acts as a dual-role agent (i.e., critic and refiner), so we design a multi-component reward to provide learning signals for both aspects, as follows:
Critic Reward. This component trains EditThinker to be a more accurate critic. The model outputs predicted scores (including and ), which should align with the actual quality of the editing results. We use GPT-4.1 as a critic expert (E) to evaluate the resulting image . The critic reward penalizes prediction errors as follows:
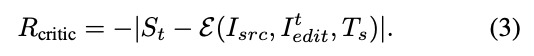
This reward encourages EditThinker to calibrate its self-assessment: overestimating quality (predicting 9 when the actual score is 5) or underestimating are both penalized. Through this feedback, the model learns to align its internal critique with actual editing results.
Editing Reward. This is the primary reward for training EditThinker to be a better refiner. It incentivizes the model to generate an instruction that leads to measurable improvements in image quality and instruction following. We use a differential reward, comparing the 'before' state () and 'after' state () using the same expert E, as follows:
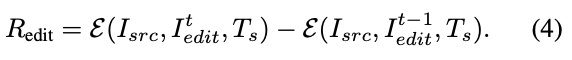
The reward is positive only when the generated instruction successfully prompts the editor to produce a better image than the previous step. This directly bases EditThinker's planning capability on actual execution results.
The final reward is as follows:
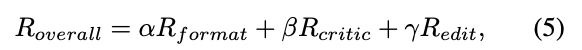
Here, represents the base reasoning format reward, and .
THINKEDIT Dataset
To train EditThinker, we require a high-quality dataset capturing multi-round 'thinking as editing' cycles. As illustrated in Figure 3 below, we designed an automated data construction pipeline to simulate this process, consisting of four sequential steps: trajectory generation, trajectory filtering, step-by-step filtering, and data partitioning. This pipeline enabled us to construct the THINKEDIT-140k dataset. Each step is detailed below.
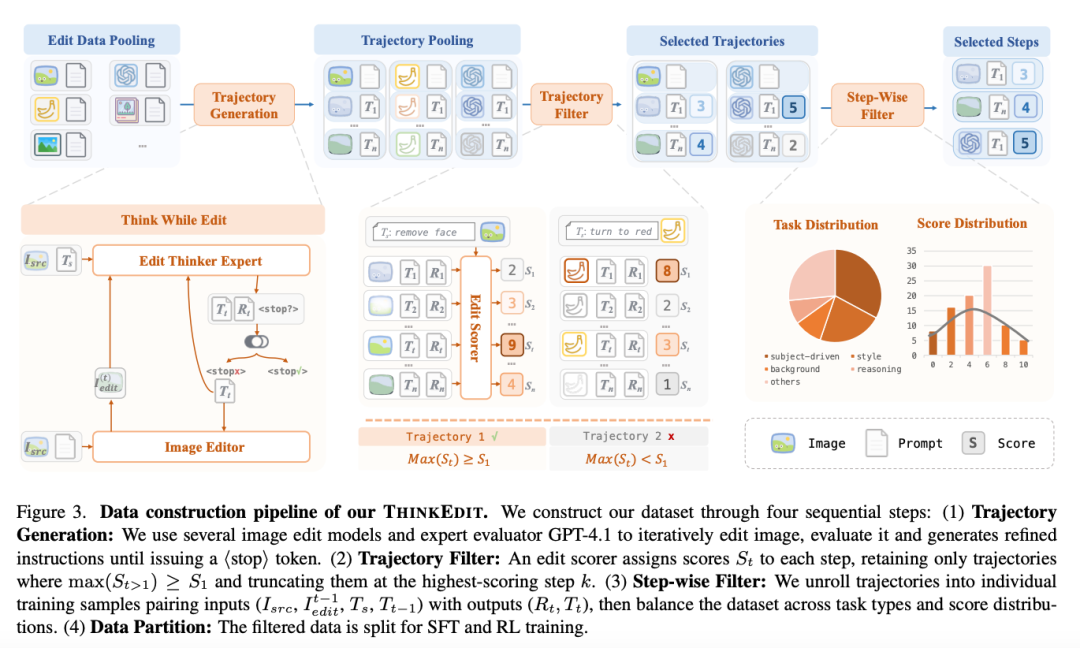
Trajectory Generation
The initial phase focuses on simulating multi-round 'thinking as editing' cycles. The pipeline commences with an editing data pool containing various (, ) pairs. At each step , an editing thinker expert (GPT-4.1) evaluates the current state (based on , , and ) and generates a new instruction (), reasoning process (), and a marker.
Notably, the expert does not output scores (). Instead, it directly decides when to halt the process by emitting a marker. This design choice stems from our finding that a single expert struggles to maintain high performance in both task refinement and output scoring simultaneously. If no marker is emitted, the image editor generates using the new . This loop continues until the expert triggers the condition (or reaches a maximum iteration limit N), thereby completing a full trajectory.
Trajectory Filtering
Since the editing thinker expert only generates refined instructions and markers without providing quality scores, we employ an additional editing scorer to evaluate each step and assign a score . After scoring all steps (), we apply a two-stage filtering process:
Filter failed trajectories. This paper only retains trajectories where at least one subsequent step () achieves a score higher than or equal to the initial step (i.e., ). Trajectories that do not meet this condition are discarded.
Truncate and retain trajectories. For the retained trajectories, this paper identifies the step with the highest score () and truncates the trajectory to include only steps from 1 to . All subsequent steps () are discarded.
Step-by-Step Filtering
Finally, this paper processes the curated trajectories from trajectory filtering to create the final training data through two steps:
Sample Extraction. First, this paper expands the truncated trajectories. Each individual step in the trajectory is converted into a distinct training sample. This sample pairs the input tuple (, , , ) with its corresponding ground-truth expert output (, ). The score for this step is retained as metadata for subsequent filtering.
Distribution Balancing. This paper applies a final filtering step to balance the dataset along two dimensions:
Task Distribution: This paper balances samples across different task types (e.g., object removal, color modification, adding items) to ensure uniform coverage.
Score Distribution: This paper normalizes samples between score levels to ensure a balanced representation of edit quality.
SFT and RL Data Partitioning
After trajectory filtering, this paper obtains a large collection of curated high-quality trajectories. From this set, two distinct datasets are created for the Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) phases. The partitioning principle is that SFT requires stable, high-quality examples, while RL benefits most from dynamically improving examples.
RL Dataset. This paper first identifies trajectories most valuable for reinforcement learning. The key criterion is high intra-trajectory score variance (i.e., "high-volatility" scores, Var() > ). These trajectories represent challenging cases where the model initially struggled but subsequently managed to improve, providing rich reward signals for learning. This paper filters 10k such high-variance trajectories while ensuring the set remains balanced across different task types and score distributions. When expanded, these trajectories yield 27k step-by-step samples that constitute this paper's RL dataset.
SFT Dataset. The SFT dataset aims to teach the model correct and stable refinement behaviors. Therefore, this paper selects samples with low score variance or consistently high quality. These "low-volatility" steps typically represent more straightforward, correct, and reliable refinement examples. This process yields a separate dataset of 140k step-by-step samples for SFT.
Experiments
Summary of Experimental Settings
This section details the experimental settings of the EditThinker framework. EditThinker is built upon Qwen3-VL-8B-Instruct. Training is divided into two phases:
Supervised Fine-Tuning (SFT): One epoch of training is conducted on this paper's newly constructed THINKEDIT-SFT-140k dataset. Key hyperparameters include a learning rate of 2e-5 and a batch size of 32.
Reinforcement Learning (RL): One epoch of training is conducted on the THINKEDIT-RL-10k dataset. Key hyperparameters include a learning rate of 2e-5, a global batch size of 128, a number of generated rollouts (N) of 8, and a KL divergence penalty coefficient of 1e-3. The maximum pixel count is set to 1024x1024.
The entire training process is conducted on 8 H800 GPUs and takes approximately 48 hours. During the inference phase, this paper's "Think while Edit" paradigm is used in conjunction with OmniGen2, Flux Kontext [dev], and Qwen-Image-Edit.
Benchmarks and Baselines: To comprehensively validate the effectiveness of the "Think while Edit" paradigm, this paper conducts a thorough evaluation on four distinct benchmarks: ImgEdit-Bench, GEdit-Bench, RISEBench, and KRIS-Bench. This suite of benchmarks is chosen for a multifaceted assessment, with RISEBench and KRIS-Bench specifically focusing on evaluating the reasoning capabilities of edit models.
Summary of Main Results
This section summarizes the evaluation results of the EditThinker framework on general editing and reasoning-based editing tasks, as shown in Tables 1 and 2 below.
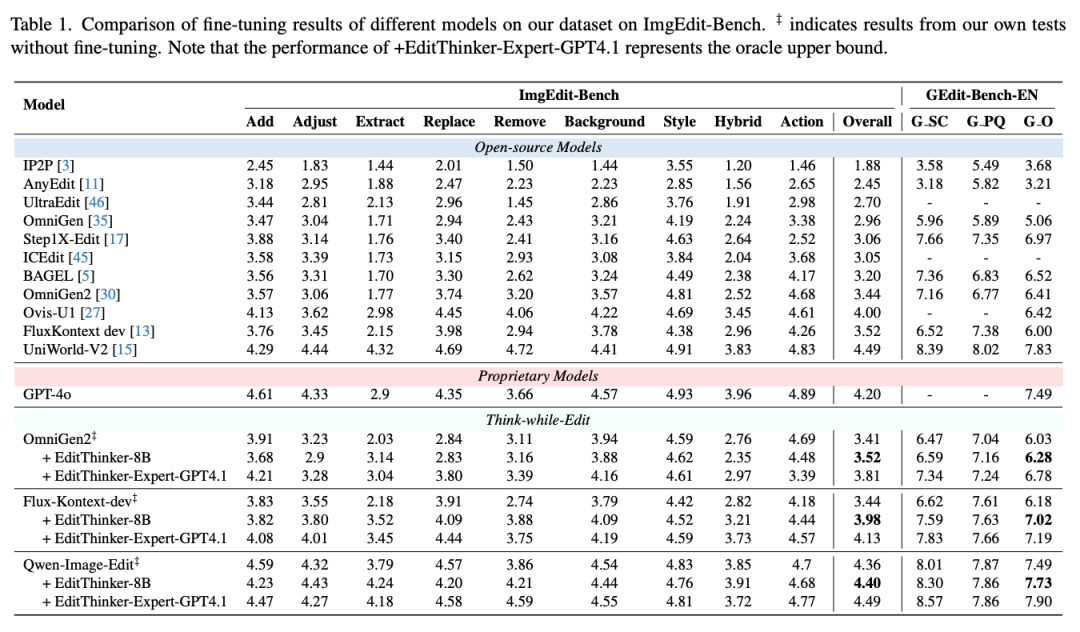

General Editing Performance: As shown in Table 1 above, this paper's "Think while Edit" framework significantly and consistently enhances the performance of all base models on the ImgEdit-Bench and GEdit-Bench-EN datasets.
On ImgEdit-Bench, EditThinker improves the overall score of FLUX.1-Kontext [Dev] from 3.44 to 3.98, OmniGen2 from 3.4 to 3.5, and Qwen-Image-Edit from 4.36 to 4.37. These results surpass some of the state-of-the-art models.
On the GEdit-Bench-EN dataset, this paper's method similarly achieves stable gains, increasing the score of FLUX.1-Kontext [Dev] from 6.18 to 7.05, OmniGen2 from 6.19 to 6.28, and Qwen-Image-Edit from 7.49 to 7.73.
Reasoning-Based Editing Performance: This paper's method also provides consistent improvements on tasks requiring deep reasoning, as shown in Table 2 above.
On RISE-Bench, the EditThinker framework offers stable performance enhancements for all models. FLUX.1-Kontext [Dev] improves from 5.8 to 14.4, OmniGen2 from 3.1 to 3.4, and Qwen-Image-Edit from 8.9 to 17.8.
Impact of Expert Model Capability: This paper observes a positive correlation between the framework's performance and the capability of EditThinker (the expert model) itself. As shown in Table 1 above, EditThinker-8B raises the FLUX score to 3.98, while a more powerful EditThinker (GPT-4.1) further increases it to 4.13. This pattern holds for other models and benchmarks, indicating that using a more capable expert model as the "thinker" directly translates to greater performance improvements in the final edit results.
Summary of Ablation Studies
This section summarizes the results of ablation studies on key components of the EditThinker framework. The FLUX.1-Kontext [Dev] model serves as the baseline and is evaluated on GEdit-Bench-EN and ImgEdit-Bench.
Analysis of Thinking Modes:
As shown in Table 3 below, this paper divides the model's edit-thinking paradigms into two primary approaches: "Think before Edit" and "Think while Edit." "Think before Edit" only uses the source image to rewrite the optimized prompt, while "Think while Edit" is this paper's proposed iterative reasoning and editing framework.
"Think before Edit" provides significant improvements but consistently falls short of "Think while Edit."
Initializing "Think while Edit" with a "Think before Edit" step leads to performance degradation, possibly because the initial "Think before Edit" introduces bias in the first round of reasoning, resulting in incomplete information transfer.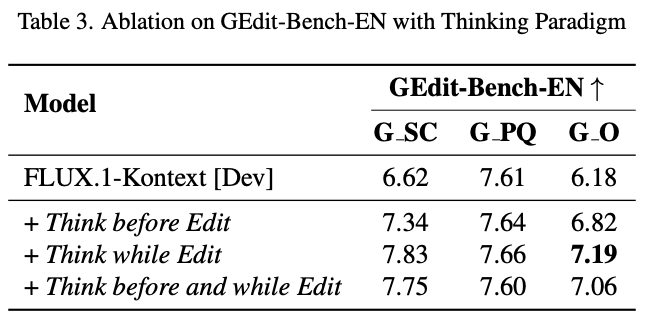
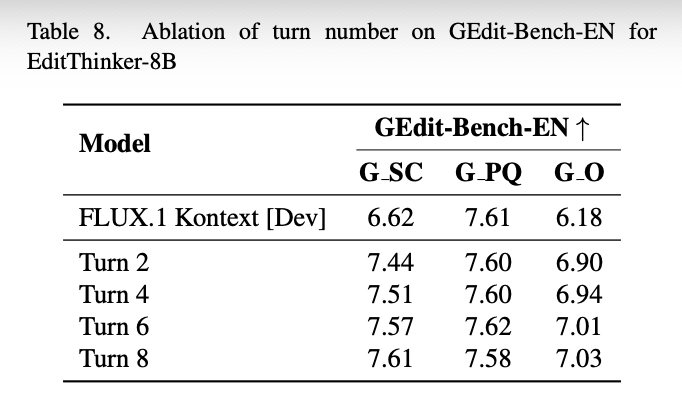
Effect of Thinking Turns:
As shown in Table 4 below, the baseline model (equivalent to a single pass, i.e., "Turn 1") achieves a G O score of 6.18.
Introducing the "Think while Edit" framework with a maximum of two turns (Turn 2) immediately boosts the G O score substantially to 6.95.
As the maximum allowed number of turns increases, the G O score continues to climb, reaching 7.13 at 4 turns, 7.16 at 6 turns, and 7.30 at 8 turns. This indicates that this paper's framework effectively leverages deeper, multi-step reasoning.
Furthermore, Table 8 below shows the multi-turn reasoning performance of EditThinker-8B. From baseline to Turn 8, performance consistently improves, rising from 6.18 to 7.03. The largest performance gain is observed at Turn 2, where the score jumps from 6.18 to 6.90.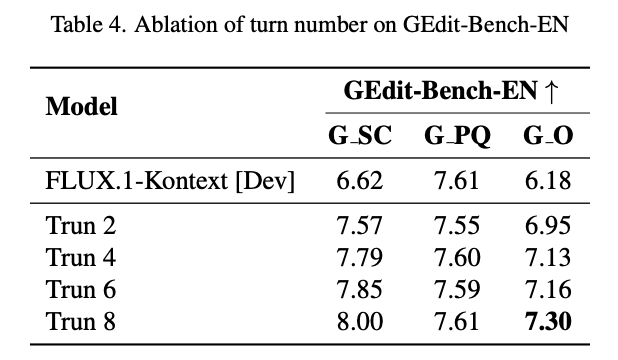
Analysis of Training Phases:
As shown in Table 5 below, the SFT phase itself (+ EditThinker-8B-SFT) brings significant performance improvements, raising the G O score from 6.18 to 6.93 and the overall score on ImgEdit-Bench from 3.44 to 3.57.
The subsequent Reinforcement Learning (RL) phase (+ EditThinker-8B-RL) provides additional and crucial optimizations. While achieving modest gains on GEdit-Bench (7.02 G O), its impact is most pronounced on the ImgEdit-Bench benchmark, increasing the overall score from 3.57 (SFT) to 3.95 (RL). This indicates that SFT is crucial for imparting foundational refinement capabilities, while RL is highly effective in optimizing expert judgment and fine-tuning decision-making strategies.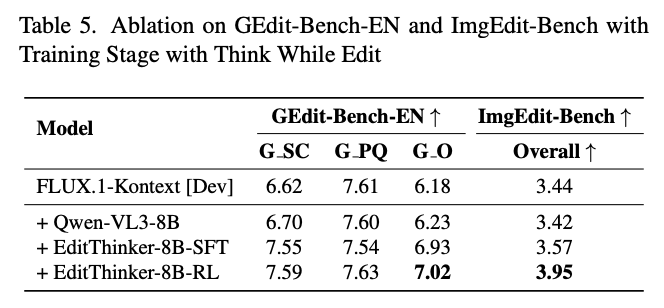
Impact of Different EditThinker Expert Models:
As shown in Table 6 above, this paper explores the framework's scalability by replacing the trained EditThinker-8B.
The baseline FLUX model achieves a G O score of 6.00. When this paper simply replaces the expert with a powerful off-the-shelf proprietary model like GPT 4.1, the G O score jumps to 7.19.
This confirms two key insights: 1) This paper's "Think while Edit" framework is a universal and highly scalable paradigm, not limited to this paper's specific trained expert. 2) The framework's performance is directly and positively correlated with the underlying reasoning and critical capabilities of the adopted expert model.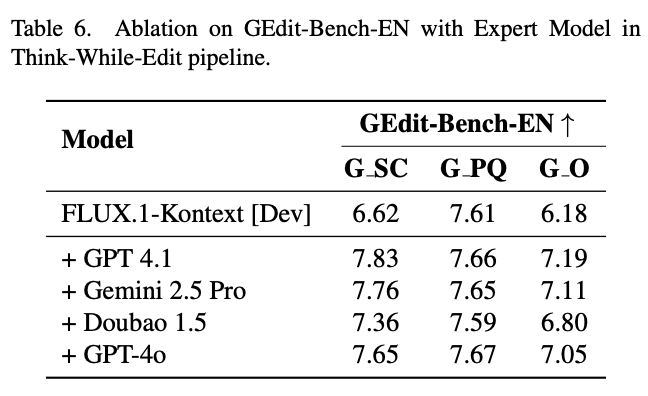
Conclusion
This paper proposes a thoughtful editing framework, EditThinker, which enables image editing models to "think" while editing, addressing the limited instruction-following capabilities in existing single-round methods due to inherent randomness and lack of deliberation. This paper's framework mimics human cognitive processes by simulating an iterative "critique-improve-repeat" cycle, enabling self-correcting image editing. By training EditThinker as a unified multimodal large language model (MLLM), it can jointly generate critique scores, detailed reasoning processes, and improved instructions. This paper also introduces THINKEDIT-140k, a large-scale, multi-round dataset for Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), to align EditThinker's planning capabilities with the constraints of real editors. Comprehensive experiments on four widely used benchmarks—ImgEdit-Bench, GEdit-Bench, RISE-Bench, and Kris-Bench—demonstrate that EditThinker significantly enhances the instruction-following capabilities of existing image editing models, particularly in tasks requiring complex reasoning. Ablation studies further confirm the critical contributions of the "Think while Edit" paradigm, iterative reasoning turns, two-stage training strategy, and expert model capability. This paper's findings underscore the importance of integrating deliberation and iterative reasoning into image editing workflows, paving the way for developing more intelligent and robust interactive visual systems. This paper plans to release all datasets and models to facilitate further research in the field.
References
[1] EditThinker: Unlocking Iterative Reasoning for Any Image Editor
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






