Raising 500 Million Yuan in Three Months: This Company Holds the Key to Embodied AI Traffic in 2026
 12/16 2025
12/16 2025
 561
561

Author | Mao Xinru
What’s the hottest term in embodied AI this year? VLA (Vision-Language-Action) models are certainly in the spotlight.
Both industry and academia have reached new heights of interest in VLA. According to public statistics, at ICLR, one of the top three machine learning conferences this year, submissions related to VLA models surged from single digits last year to 164, an 18-fold increase.
This technical approach, capable of end-to-end mapping from visual perception to action execution, is seen as a shortcut to achieving general machine intelligence, attracting significant R&D investment.
However, beneath the surface consensus, a profound debate on the technology’s ultimate direction has been quietly simmering.
As early as August this year, at the 2025 World Robot Conference, Wang Xingxing bluntly called the current popular VLA models a relatively simplistic architecture and expressed skepticism.
This explosive viewpoint sparked widespread discussion in the industry, with its underlying logic deserving deeper examination.
He argued that if a model merely combines vision, language, and action on the surface without stable world representation and prediction capabilities, such a system would reveal shortcomings in real-world interactions, such as over-reliance on data quality and diversity, and insufficient long-term planning and causal reasoning abilities.
Therefore, Wang Xingxing favors allocating more resources to the world model approach.
This perspective echoes the views of many industry insiders, who believe world models could alleviate the core bottlenecks of data scarcity and generalization difficulties in embodied AI, potentially becoming the key technology trend in 2026 after VLA.
In fact, this debate over ultimate intelligence extends beyond the humanoid robot industry. In autonomous driving, seen as a pioneer in embodied AI, leading players like Tesla and XPENG are exploring and weighing three paths: end-to-end, VLA, and world models.
The choice of technical route is likely to shape the industry landscape for the next five years.
Recently, VisionX, a startup focused on world models, secured 200 million yuan in Series A2 funding. Previously, it completed three consecutive rounds of financing—Pre-A, Pre-A+, and A1—totaling 500 million yuan in Series A funding over three months.
Investors include traditional institutions like CICC Capital and Guozhong Capital, as well as industrial capital like Huawei Hubble.
Notably, Huawei Hubble’s investment targets in embodied AI are relatively limited, with VisionX being one of them.
This investment aligns with Huawei’s strategic prediction that world models will top its list of “Ten Key Technology Trends for the Intelligent World 2035.”
Currently, VisionX is centering its business on world models while deploying two business lines: autonomous driving and robotics.
The company’s technical choices and commercialization paths provide an excellent case study for observing whether world models can truly become the universal brain for the next generation of robots.
A Full-Stack Elite Team
Despite the year-end, financing enthusiasm in the embodied AI industry remains strong, with a mix of large-scale and frequent multi-round funding events. VisionX clearly falls into the latter category.
Driving this series of capital moves is a composite founding team with top talent across academia, engineering, industry, and algorithms.
This full-stack configuration, covering the entire chain, is rare among embodied AI startups.
Huang Guan: Founder & CEO, serial entrepreneur with algorithm development experience at Microsoft and Horizon Robotics
Zhu Zheng: Chief Scientist, Tsinghua postdoc with over 70 top-conference papers; widely recognized as an academic leader
Mao Jiming: VP of Engineering, formerly led simulation and engineering at Baidu Apollo
Sun Shaoyan: VP of Product, formerly a director at Alibaba Cloud and general manager of Horizon Robotics' data closed loop (closed-loop) product line
Chen Xinze: Algorithm Lead, AI world champion VisionX Founder & CEO Huang Guan
VisionX Founder & CEO Huang Guan
Competition in embodied AI is, at its core, a battle for top talent.
From a technical standpoint, VisionX’s team structure exhibits a high-dimensional, cross-disciplinary characteristic, effectively bridging the gaps between visual perception, physical understanding, and robot control in traditional AI research.
From a business operations perspective, this combination of top-tier academia and large-scale industrial implementation experience also constitutes VisionX’s competitive edge.
Based on this composite capability, VisionX has chosen a seemingly more challenging yet more sustainable commercialization path: advancing simultaneously in both autonomous driving and general-purpose embodied AI while striving to achieve a full-stack closed loop from brain to body.
Beyond its team’s reputation, VisionX’s self-sustaining capabilities are also key to capital confidence. Starting with spatial intelligence R&D, VisionX has developed technologies in two directions: a data engine for physical spaces and a content engine for virtual spaces.
Its current product lineup includes full-stack software and hardware offerings such as the world model platform GigaWorld, the embodied foundation model GigaBrain, and the general-purpose embodied robot Maker.
Commercially, it has signed partnerships with multiple leading OEMs in the autonomous driving world model space.
In embodied world models and embodied brains, it has also secured collaborations with various embodied robot and terminal companies for applications in research, education, data collection, industry, and services.
Having established its intelligent brain, VisionX has not confined itself to a software provider role.
With initial stability in its large model business, VisionX began assembling a robotics team mid-year to apply large model capabilities to wheeled-arm robots.
In late October, it formed a strategic partnership with the Hubei Humanoid Robot Innovation Center to build the world’s first virtual-physical embodied AI data factory driven by world models.
In late November, VisionX launched its first wheeled humanoid robot, Maker H01, and initiated mass production and delivery.
The Maker H01 standard version stands approximately 1.6 meters tall, with over 20 degrees of freedom, designed for open scenarios like households, commercial services, and light industry. It is currently being deployed in real-world business scenarios such as object retrieval, inspection and reception, laboratory assistance, and warehouse handling. The official release of Maker H01 also marks VisionX’s completion of a trinity product architecture: action core + data engine + physical carrier (carrier).
This closed-loop layout from algorithms and software to hardware not only validates its world model technology but also aims to secure a complete ecological niche from intelligence to intelligent agents, laying the foundation for long-term competition.
Diving Deep with World Models
The core narrative of VisionX revolves around world models.
But what exactly are world models? Why are they considered key to the next-generation robot brain?
In layman’s terms, world models can be seen as a digital sandbox that has learned physical laws.
In this sandbox, AI can simulate real-world operations, such as a glass cup shattering when dropped from a table or the force needed to push a box.
Using this sandbox, robots can mentally preview the outcomes of various actions without multiple slow real-world trials, enabling them to learn optimal strategies.
This is the essence of VisionX’s technical paradigm: a trinity of world models + action models + reinforcement learning.
In this system, the three components have clear roles:
World models construct high-fidelity physical environments, addressing robots' generalization across different scenarios.
Action models, as the command center, interpret complex multimodal instructions and break them down into action sequences.
Reinforcement learning enables robots to optimize action strategies through repeated trial-and-error in virtual environments, improving task accuracy and robustness.
Under this architecture, the native world model GigaWorld-0 serves as the foundation and nourishment, while the native action model GigaBrain-0 controls decision-making.
GigaWorld-0 generates large-scale, high-fidelity interaction data through geometrically consistent and physically accurate modeling, achieving a data amplification effect and freeing model training from reliance on expensive, time-consuming real-world data.
This is VisionX’s world model framework designed specifically for VLA model training and the industry’s first to adopt FP8 precision end-to-end training.
Notably, FP8 precision training, known for its high computational efficiency, low memory footprint, and reduced communication bandwidth requirements, is widely used in training large language models like Deepseek-V3 and GPT-4, significantly boosting training speed while maintaining performance.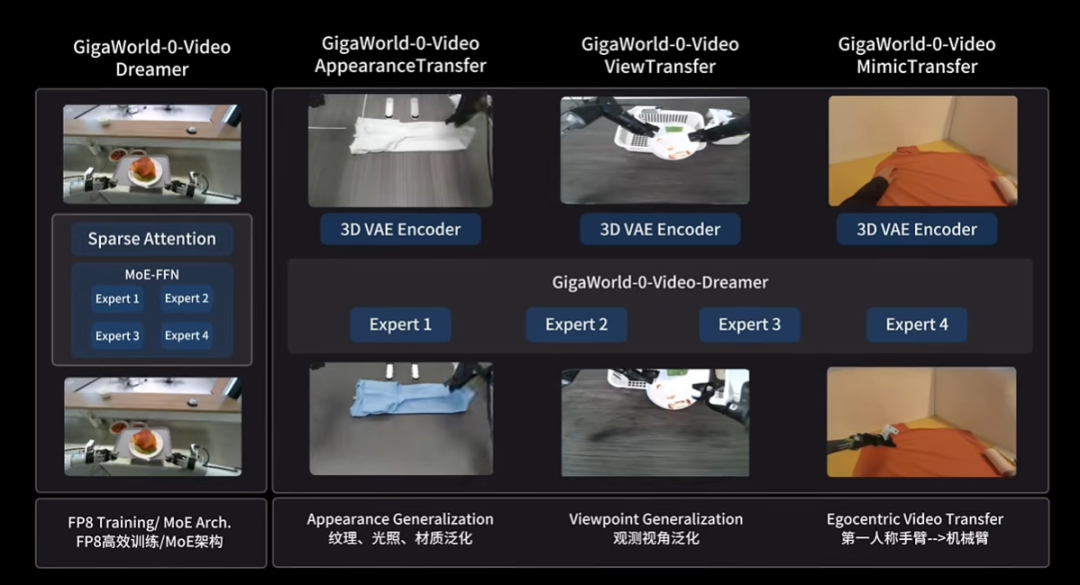
VisionX successfully increased the proportion of world model-generated data in VLA training to 90%, the first model company to achieve this globally.
This quantitative data leap brought qualitative performance improvements. The VLA model trained with generated data achieved near-300% performance gains across three generalization dimensions: new textures, new perspectives, and new object positions.
In the PBench (Robot Set) benchmark, GigaWorld-0 achieved the highest overall performance with the smallest parameter count. This small-parameter, high-performance characteristic clears cost barriers for subsequent engineering deployment.
GigaBrain-0 is an end-to-end decision-making control model designed specifically for embodied agents.
The VisionX team identifies three key challenges in current embodied AI: 1) scarce high-quality data, as real-world collection is costly and inefficient; 2) simulation-to-reality gaps in synthetic data, making direct utilization difficult; and 3) modeling errors in traditional simulators that constrain reinforcement learning effectiveness.
GigaBrain-0, powered by the world model GigaWorld-0, has the potential to break these bottlenecks.
Based on the VLA architecture, the model integrates multimodal inputs such as images, depth, text, and robot state, outputting structured task plans and motion instructions.
Addressing current robotic shortcomings in operational precision and reasoning, GigaBrain-0 emphasizes 3D spatial perception and structured reasoning, enhancing navigation accuracy and long-sequence task execution in complex environments for stronger generalization.
In complex tasks like coffee-making, desk organization, and object transportation, its model performance not only surpasses π0 but also rivals π0.5.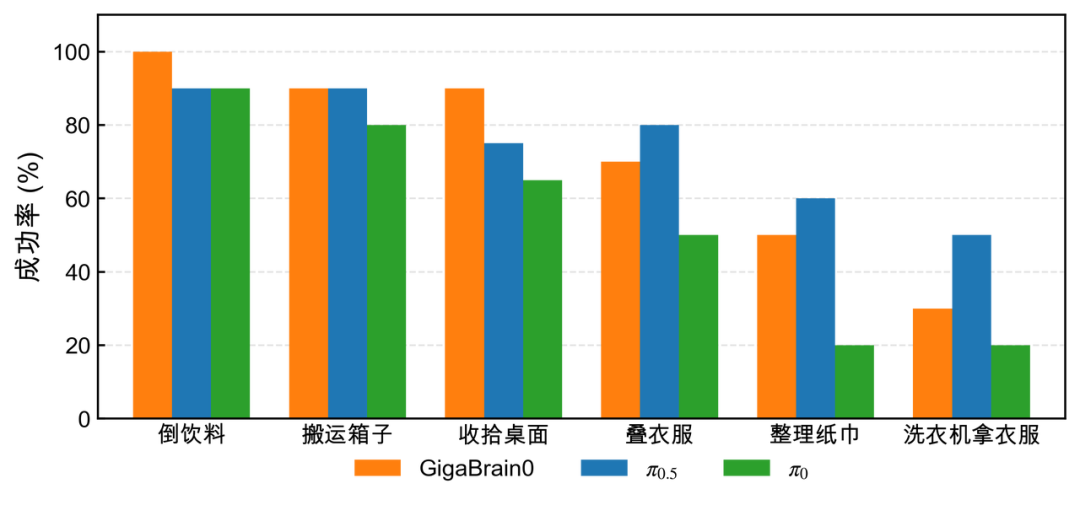
Notably, it excels in edge deployment. The deeply optimized lightweight variant GigaBrain-0-Small achieves an inference latency of just 0.13 seconds on the NVIDIA Jetson AGX Orin platform, far below π’s 1.28 seconds.
Yet its task success rate matches π0’s 80%, demonstrating efficient real-time reasoning on resource-constrained devices. This directly addresses the pain point of traditional large models’ high computational demands and deployment difficulties.
Overall, GigaBrain-0’s performance advantages are threefold:
Richer training data sources: More robust and generalizable under texture, lighting, and perspective variations.
Deeper architecture: Key submodules introduce deeper modeling for finer operational performance.
Dual-version models: The small model achieves 90% of the large model’s performance and enables real-time inference on edge Orin devices.
VisionX Chief Scientist Zhu Zheng notes that VLA and world models are increasingly converging.
However, the world model’s role is significant. Beyond data provision, it enables implicit future state prediction and explicit future video prediction within VLA, overcoming the sparsity of action-level supervision.
Who Will Dominate the Robot Brain?
Whether it’s the VLA models popular this year or the highly anticipated world models, their essence represents paradigmatic evolution in embodied AI brains across different stages.
While the ultimate paradigm remains undecided, world models have already captured global industry and academic attention, with giants like NVIDIA’s COSMOS and Google’s Genie-3 entering the fray.
Behind this lies a struggle for foundational control over the robot brain.
Currently, there are three main forces converging in the industry:
The first group consists of automotive OEMs with established scenarios and mass production pathways, such as Tesla and XPENG.
Their strength lies in possessing real driving data and closed-loop scenarios. Tesla has millions of vehicles on the road daily, generating real driving data that is difficult for any startup to match.
However, their limitation in generalization is equally apparent: transitioning from vehicle-based intelligence to general-purpose robots requires solving entirely new challenges in balance, manipulation, and complex interactions.
The second group includes platform-level giants both domestically and internationally, such as ByteDance and Alibaba in China, and Google and NVIDIA abroad.
These players boast advantages in computational power and data scale, often launching models with stronger generalization capabilities and multimodal understanding. However, most companies prefer to first scale capabilities in the cloud before extending to the edge.
The third group comprises startups dedicated to embodied intelligence, such as Figure AI, Jijia Vision, and StarMove Era.
The greatest advantage of these embodied startups lies in their pure path and focused business. Without historical burdens, they dare to bet on cutting-edge technological routes.
However, funding and scenario constraints pose significant challenges. Training a high-quality world model may require tens of thousands of GPU hours of computational investment, making it a massive money-burning game for startups.
At the same time, they lack their own large-scale hardware ecosystems and real data closed loops, relying heavily on external partners for deployment scenarios and data reflow (data reflow can be translated as "data feedback loops").
Regardless of which of the three groups gains the upper hand first, they must all address three major bottlenecks in the current industry development.
The first is the lack of real-world data. The success of large language models stems from the explosion of internet text data, but embodied intelligence requires real data with high-dimensional physical information.
Currently, companies like Jijia Vision are attempting to break through by using world models to generate synthetic data. However, the challenge for all players is how to reduce the performance degradation when strategies trained in simulated environments are deployed in the real world, ensuring that behaviors learned in simulators are stable and reliable in reality.
The second challenge is computational power and inference costs. Training a sufficiently intelligent model that understands the world requires computational consumption far exceeding that of current large language models.
Moreover, robots must make decisions and react within milliseconds, meaning computational power cannot be centralized solely in the cloud but must also be deployed at the edge.
This directly raises the financial threshold for embodied intelligence.
This is precisely the underlying logic behind Jijia Vision's Intensive financing ( Intensive financing can be translated as "intensive fundraising") of 500 million yuan within three months. Betting on world models is not just a technological race but also a capital endurance race.
For startups, the ability to continuously attract institutional, industrial, and local capital to ensure a steady supply of resources is essential for surviving this marathon.
The final challenge lies at the ecological level. The large-scale construction of a data closed loop involving "sensors-actuators-models" is still in its infancy.
Although the emergence of world models provides a new path for data generation, constructing a sustainable data source ecosystem remains a core issue the industry must address.
The battle for dominance has only just begun. The future outcome will depend on two core factors:
First, the degree of model generalization. Whoever can first train a general-purpose model not limited to specific hardware or scenarios will hold the core discourse power ( discourse power can be translated as "discourse power").
Second, ecological construction capability. In the future, competition in embodied intelligence will no longer be a contest of single technological points but an ecological battle encompassing models, data, hardware, and application scenarios.
Only companies with the broadest range of partners and the ability to form the fastest data flywheels are likely to emerge victorious in the long run.
And when the robot's brain truly acquires general physical understanding capabilities, the ChatGPT moment for the physical world will truly arrive.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






