NanobananaPro/GPT-4o/Sora2: Which Domestic Model Takes the Crown? ViStoryBench: The First All-Encompassing Story Visualization Benchmark Revealed!
 12/22 2025
12/22 2025
 563
563
Insight: The Future Landscape of AI-Generated Content 
Key Highlights
If we conceptualize 'story visualization' as a cross-media process encompassing 'encoding-transmission-decoding'—where text scripts (encoding) are transformed into model-generated images/storyboards (transmission), which are then interpreted by audiences for character and plot understanding across multiple shots (decoding)—the challenge transcends merely creating visually appealing images. It hinges on ensuring narrative information is transmitted in a stable, controllable, and verifiable manner. The significance of ViStoryBench lies in its pioneering role in dissecting and rigorously testing this entire 'communication chain'.
First All-Encompassing Story Visualization Benchmark: ViStoryBench is a comprehensive benchmark suite that encompasses 80 multi-shot stories, 10 distinct visual styles, and over 1,300 storyboards. Its primary objective is to evaluate the generative capabilities of models under complex narrative structures, visual styles, and character settings.
12-Dimensional Rigorous Evaluation Metrics: It introduces 12 automated metrics, such as Character ID Consistency (CIDS), On-Screen Character Count Matching (OCCM), and Copy-Paste Detection. The reliability of these metrics has been validated through human evaluation.
Comprehensive Assessment of 30+ Mainstream Models: The evaluation encompasses open-source image generation models (e.g., StoryDiffusion, OmniGen2), commercial closed-source models (e.g., MOKI, Doubao, MorphicStudio), multimodal large models (e.g., GPT-4o, Gemini), and video generation models (e.g., Sora2, Vlogger). This reveals the structural strengths and weaknesses inherent in different technical approaches.
ViStoryBench-Lite: A lightweight version is introduced to mitigate high evaluation costs. It enables a 'representative' capability assessment at a lower cost while maintaining statistical distribution consistency. 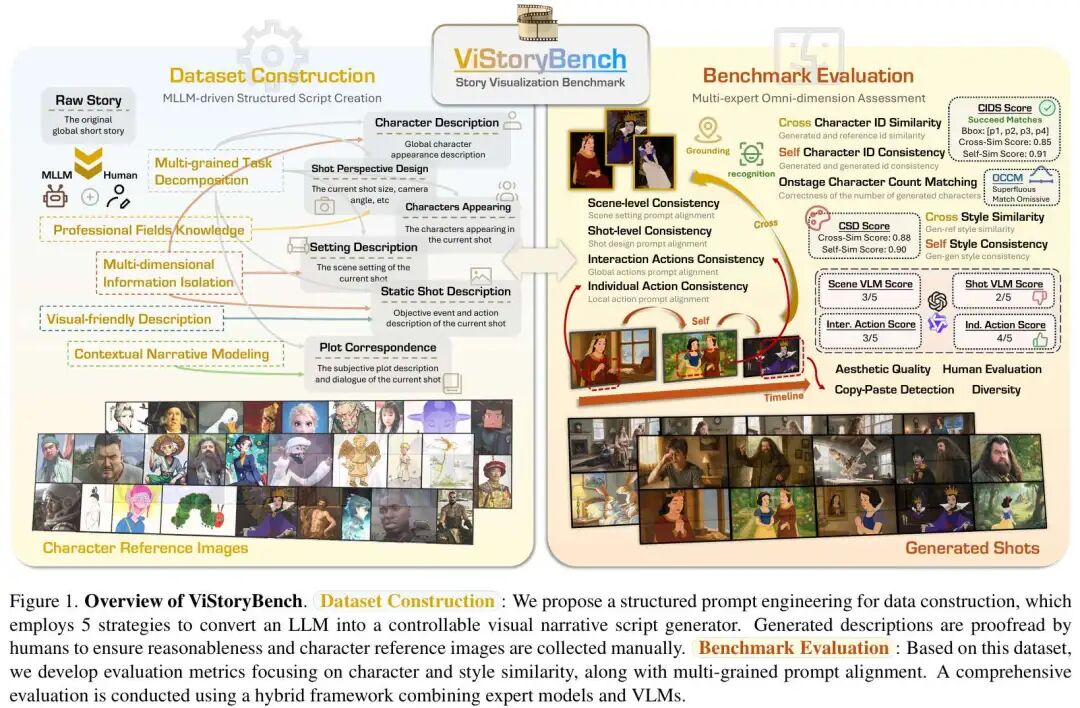
Addressed Challenges
1) Existing Benchmarks Focus Solely on Visuals, Neglecting Narrative Chains: Current story visualization benchmarks often have a narrow scope, limited to short prompts, lacking character reference images, or focusing solely on single images. Consequently, they fail to address the most critical communication goal in real-world creation: ensuring information consistency across multi-shot continuous narratives, encompassing characters, scenes, actions, and camera language.
2) Lack of Unified Standards Leads to Fragmented Evaluations: Many studies rely on a limited number of metrics, lacking common standards to measure narrative alignment, stylistic consistency, and character interactions. This results in a communication issue: it becomes impossible to discern whether a model 'understands the story' or merely 'generates coincidentally similar content'.
3) 'Copy-Paste' Cheating: Consistency Achieved Through Deception: Many models resort to directly 'pasting' reference images (or heavily reusing local features) into generated results to maintain character consistency, sacrificing the necessary action and expression variations required for the plot. Worse still, traditional metrics often misinterpret this 'cheating consistency' as an improvement in capability, skewing evaluation conclusions.

Proposed Solutions
Multifaceted Dataset Creation: ViStoryBench curates 80 story segments from diverse sources, including film scripts, literary classics, and folklore. LLM-assisted summarization and script generation are manually validated. Through structured prompt engineering, LLMs are transformed into 'controllable storyboard script generators,' with scripts structured across five dimensions:
- Setting
- Plot
- Onstage Characters
- Static Shot
- Shot Perspective Design
The dataset includes 344 characters, 509 reference images, and covers 10 visual styles (e.g., Japanese anime, realistic cinema, picture book styles). This approach disassembles 'narrative communication' into annotatable, verifiable units, ensuring evaluations transcend subjective resemblance.
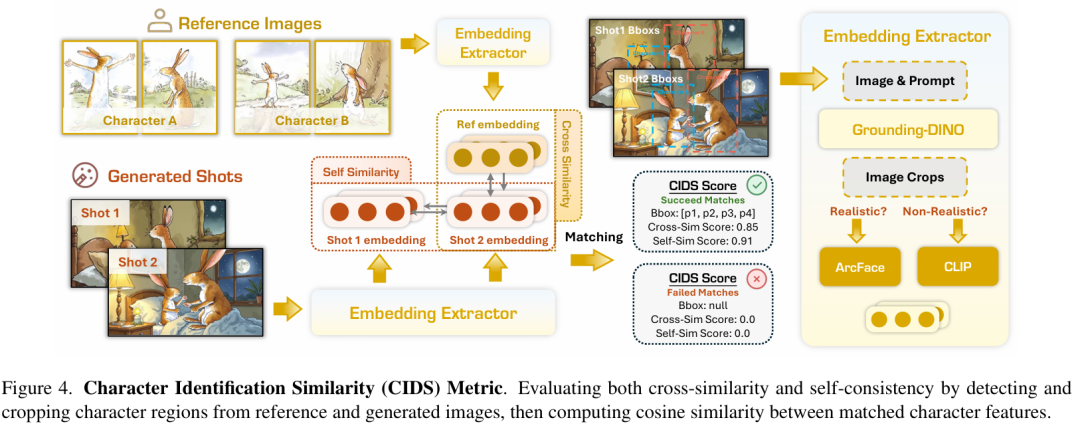
Comprehensive Evaluation Metrics: To quantify 'storytelling capability,' ViStoryBench designs 12 automated metrics, categorizing model outputs into several types of communication distortions: identity distortion, quantity distortion, alignment distortion, stylistic distortion, and speculative distortion. Examples include:
- Character Identification Similarity (CIDS): Detects characters, extracts features, and computes cosine similarity between generated images and reference images (Cross) as well as among generated images (Self).
- On-Screen Character Count Matching (OCCM): Quantifies accuracy in generating the correct number of characters, addressing 'hallucinated additions/omissions'.
- Copy-Paste Detection: Identifies speculative behavior by comparing geometrically normalized features to detect excessive reuse of reference images.
- Prompt Alignment: Utilizes expert models and VLMs to provide fine-grained scoring of scenes, camera movements, character interactions, and individual actions.
Applied Technologies
- LLM-driven Script Creation: Leverages large language models for structured script disassembly and storyboard expression.
- Hybrid Evaluation Framework: Combines expert models (e.g., ArcFace, Grounding DINO) with multimodal large models (e.g., GPT-4o, Qwen-VL) for assessment.
- Character Identification Similarity (CIDS): Calculates character consistency based on feature extraction and bipartite graph matching.
- Copy-Paste Rate: Measures 'overfitting pasting' of generated features to specific reference images using Softmax probability distributions.
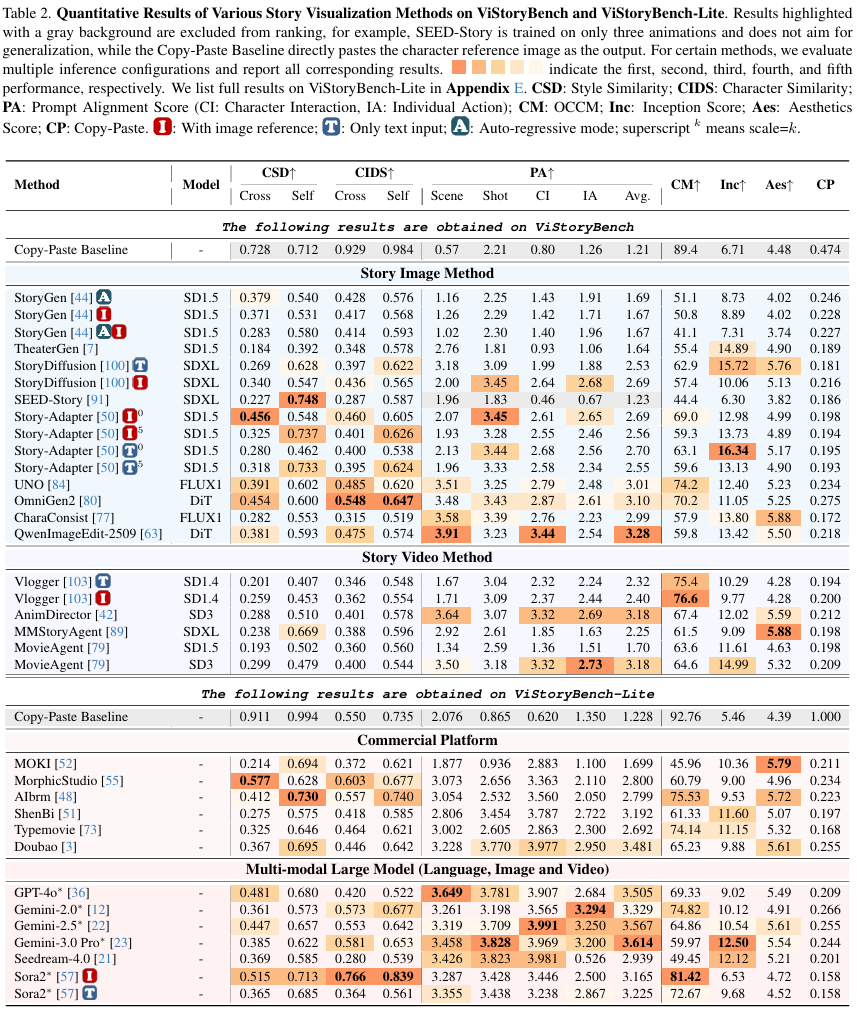
Performance of Domestic and International Models
A large-scale evaluation of over 30 methods yields several 'practical' conclusions: different approaches excel in distinct segments of the communication chain.
Dual Nature of GPT-4o:
GPT-4o excels in narrative alignment (Alignment Score: 3.67) and character counting (OCCM: 93.5), indicating robust capabilities in 'understanding scripts and organizing information per instructions'. However, it lags slightly in visual quality (Inception Score) and stylistic diversity, demonstrating that 'proficient storytelling' does not necessarily equate to 'proficient drawing'.
Strengths of Commercial Software:
Commercial tools like MorphicStudio and Doubao exhibit greater stability in aesthetic quality (Aesthetics) and stylistic consistency, resembling production-oriented 'visual presentation optimization'. However, they demonstrate weaker fine-grained narrative control and less precise responsiveness to camera language compared to LLM-based approaches.
Multi-Shot Capabilities of Sora2:
As a native video model, Sora2 stands out in cross-shot consistency (Self-Sim: 0.813), benefiting from learning film data. However, it still has room for improvement in adhering to specific visual references (Image Ref Cross-Sim)—it resembles 'film aesthetics' more than 'your specified characters'.
Video vs. Image Models:
Currently, video generation models (e.g., Vlogger, MovieAgent) generally underperform dedicated story image methods (e.g., OmniGen2, UNO) in single-frame quality and character consistency. The temporal dimension brings coherence benefits but also incurs detail loss per frame.
Trade-offs:
A clear trade-off exists between consistency (Consistency) and diversity (Diversity): higher consistency risks 'copy-pasting', while greater diversity risks 'character drift'. The Copy-Paste metric explicitly surfaces this latent conflict, preventing misguidance from 'score-brushing consistency'.
Conclusions and Limitations
ViStoryBench represents the most comprehensive and rigorous benchmark for evaluating story visualization tasks to date. It not only provides a high-quality multi-shot dataset but also dissects 'storytelling' into automatically measurable capability structures. Experimental results are intuitive: no single model dominates across all dimensions—LLMs excel in narrative organization, commercial tools in visual presentation, and video models in cross-shot coherence.
Limitations: The current focus is primarily on multi-image consistency assessment, excluding audio alignment or more complex temporal dynamic metrics. The VLMs used in hybrid evaluation may still exhibit occasional hallucinations (though stability testing has been conducted). Future work will incorporate background consistency assessment and expand toward long-video narrative benchmarks.
References
[1] ViStoryBench: Comprehensive Benchmark Suite for Story Visualization
-
![]()
Liang Wenfeng: Marching to His Own Beat
-
![]()
Trillion-Yuan Intelligent Computing Market Surge: Key Trends in the Computing Power Industry
-
![]()
Global Capital Betting Big on Chinese Robotics
-
Summary of the Online Voice Recorder Market in Q1 2026: A Touchstone for AI Integration into Hardware, with Initial Signs of Ecosystem-Based Competition Emerging
-
Summary of the Online Drone Market in Q1 2026: Ecological Breakthrough and High-Quality Development of the Low-Altitude Economy Entering a New Phase
-
![]()
Challenges in Claim Settlements and Soaring Premiums: A Ping An Good Car Owner's Tale of Woe
-
![]()
AI Glasses Achieve Breakthrough with Lightweight Design: Materials and Balance Emerge as Key Competitive Factors
-
![]()
Volvo Needs Geely, But Not Too Much Like Geely





