How Autonomous Vehicles Detect Small Obstacles Such As Stones
 12/24 2025
12/24 2025
 672
672
Recently, a friend reached out, asking me to elaborate on the visual tasks autonomous vehicles undertake to detect small obstacles like stones. Before delving into the "how" of detection, it's crucial to address a more fundamental query: Do autonomous vehicles truly need to detect small obstacles like stones? And if they do, how is this detection accomplished?
What Do Autonomous Visual Systems Focus On?
Autonomous vehicles rely on an array of sensors to "perceive" their surroundings, with cameras playing a pivotal role. Once the camera captures real-time images, the visual perception system in autonomous driving converts these raw images into an "environmental model" that the machine can comprehend.
This environmental model encompasses a wealth of information, including the presence of vehicles ahead, pedestrians, lane markings, traffic signs, and even obstacles on the road surface. Visual perception forms the bedrock of the entire autonomous driving system. Without it, subsequent decision-making and control processes would be unfeasible.
Within the visual perception system of autonomous driving, two fundamental and core tasks stand out: object detection and semantic segmentation. Object detection involves locating targets such as cars, people, and motorcycles within an image and providing their positions. Semantic segmentation, on the other hand, assigns each pixel in the image to a category label, such as "this is a road," "this is a sidewalk," or "this is an obstacle."
To grasp these concepts simply, object detection answers the questions, "Is there an object here? Where is it? What is it?" while semantic segmentation addresses, "What category does this area belong to?" The fusion of these two task types constitutes the basic work of visual perception.
What Constitutes Abnormal Objects?
The small obstacles, like stones, mentioned by my friend, can indeed be classified as abnormal objects. An "abnormal object" refers to an entity not commonly found in the training set, with an unclear category, yet potentially posing a threat to vehicle safety. Visually, such objects may exhibit irregular sizes and shapes, and their colors may closely resemble those of the ground and shadows, presenting significant challenges for machine recognition.
In everyday driving scenarios, the most prevalent obstacles are large, conspicuous entities such as other vehicles, pedestrians, bicycles, and motorcycles. The visual system defines these as the primary target categories and repeatedly learns their features from the training data.
However, real-world roads are far from ideal. During driving, one may encounter abnormal objects like fallen cargo, tire fragments, plastic bags, and even stones. These objects do not conform to standard target categories and may lack a substantial number of samples in our training data. Yet, if a vehicle traveling at high speed encounters such objects, it could lead to safety risks like tire blowouts and control failures. Hence, accurately identifying these abnormal objects is of paramount importance.
Given that the visual perception system primarily learns features from data, scenarios involving stones, which only occasionally appear, lack sufficient examples for the system to learn to classify them as obstacles. Sometimes, stones may visually resemble the road surface, shadows, cracks, and other elements, making it challenging for the model to determine from a single image whether the stone poses a danger, its distance from the vehicle, and whether it should be avoided. Detecting and managing such situations presents a major challenge for autonomous driving perception.
How Do Visual Tasks Detect These Abnormal Objects?
Since abnormal objects like stones do not fall into regular categories, can the autonomous driving visual system still detect them? The answer is affirmative, but not through simple classification as a specific type of object. Instead, it identifies risks through various visual tasks and strategies.
Currently, autonomous driving employs deep learning models for visual perception. These models learn features such as the shapes, textures, and boundaries of different objects in images. Mainstream object detection models like YOLO, SSD, and Faster R-CNN can locate various targets in images and provide confidence levels and position boxes. For targets not belonging to known categories, such models may not output an explicit label like "stone," but will instead provide a detection result of "unknown object/obstacle" to alert the autonomous driving system of a noteworthy object ahead.
Semantic segmentation or instance segmentation also serves as a major means of identifying abnormal objects. It divides the image into labels such as "road surface," "non-road surface," and "obstacle." As long as the model has learned during training to distinguish between "normal road surface" and "abnormal areas on the road surface," even if it has not encountered a specific category like "stone," it will mark pixels that are visually out of place and do not belong to the road surface as "non-road surface/obstacle." Pixel-level labeling enables the system to discover abnormal areas on the road and report these areas to the subsequent decision-making and control modules as potential obstacles.
There exists a type of visual task specifically designed for detecting small abnormal objects, known as small object detection. It primarily addresses the recognition of objects that are minuscule in size, distant, and have irregular shapes. Since these targets occupy only a few pixels in the image, traditional object detection models may easily overlook them as noise. To address this issue, information from other sensors, such as LiDAR, can be incorporated. The spatial position and height cues provided by the 3D point cloud can be utilized to constrain and guide the visual model to focus on areas that "appear insignificant but actually exist in space." In this manner, the visual model no longer relies solely on appearance features but can integrate real 3D structural information, rendering the recognition of small obstacles more stable and less prone to missed detections.
Final Thoughts
The autonomous driving visual system encompasses a multitude of visual tasks, such as object detection and semantic segmentation, all of which transform the images captured by the camera into an understanding of the environment. For uncommon road objects like stones, which often lack standard category labels, the visual system can still identify them as potential obstacles through extensive training, model optimization, and the integration of information from other sensors. The ultimate goal of detecting these objects is to ensure that autonomous vehicles drive more safely and reliably.
-- END --
-
![]()
Zhuo Li Han Guang Officially Competes in the 2026 Optical Industry Annual Innovation Product Awards
-
![]()
China Raytronics Secures Nomination for 2026 Optics Industry High-Growth Enterprise Award
-
![]()
A Regular and Periodic Exchange Mechanism to Be Set Up! North Opto-electronics and Costar Forge New Avenues for Intelligent Integration
-
![]()
After Joining NVIDIA’s Core Supply Chain, This Optical Company Secures Fresh Funding!
-
![]()
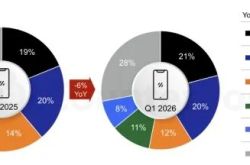
Quarterly Report | All-Channel Online Laptop Sales in China Plummet by 19% in Q1 2026; Lenovo, ASUS, Apple, HP, and Mechrevo Dominate with 80% Market Share
-
![]()
Who’s Encircling and Attacking OpenAI? A New Tech Giant War Has Begun
-
![]()
AI Application Integration Surges Eightfold in a Year! Your Job Might Be Vanishing Without Notice
-
![]()
Mobile Phone Manufacturers: The Time Has Come to Unveil True AI Phones