Lip-sync matching and identity preservation achieve comprehensive SOTA! Tsinghua & Kling X-Dub: Abandoning the inpainting mindset and achieving precise synchronization through 'editing'!
 01/04 2026
01/04 2026
 470
470
Interpretation: The Future of AI Generation 
Highlights
Paradigm Shift: This paper redefines visual dubbing from a pathological 'mask inpainting' task to a well-conditioned 'video-to-video editing' task.
Self-Guided Framework (X-Dub): Proposes a self-guided framework that utilizes a DiT-based generator to create 'ideal' paired training data (i.e., video pairs with identical visual conditions except for lip movements), allowing an independent editor model to learn robust dubbing within a complete visual context.
Time Step-Adaptive Learning: Introduces a multi-stage training strategy that aligns specific diffusion noise levels with different learning objectives (global structure, lip movement, texture details).
New Benchmark: Releases ContextDubBench, a comprehensive benchmark encompassing real-world complex scenarios (e.g., occlusions, dynamic lighting) to evaluate the robustness of dubbing models.
 Figure 1: Surpassing mask-inpainting, X-Dub redefines visual dubbing as a rich-context, full-reference video-to-video editing task, achieving precise lip-sync and faithful identity preservation even in challenging scenarios with occlusions and dynamic lighting.
Figure 1: Surpassing mask-inpainting, X-Dub redefines visual dubbing as a rich-context, full-reference video-to-video editing task, achieving precise lip-sync and faithful identity preservation even in challenging scenarios with occlusions and dynamic lighting.
Problems Addressed
Audio-driven visual dubbing faces a fundamental data bottleneck:
Lack of paired training data, i.e., video pairs where the subject's lip movements differ but all other visual conditions (pose, lighting, expression) are identical.
Previous Limitations: Existing methods typically circumvent this issue by occluding the lower half of the face and using inpainting techniques. This strips away critical visual context, forcing the model to 'hallucinate' missing content (e.g., occlusions) and extract identity information from potentially misaligned reference frames. This leads to visual artifacts, identity drift, and poor synchronization.
Proposed Solution
This paper proposes X-Dub, a self-guided framework:
Generator (Data Builder): A DiT model trained via self-reconstruction to generate a 'companion video' for each real training video. This companion video features altered lip movements (driven by different audio) while preserving the original identity and scene, forming synthetic 'aligned video pairs.'
Editor (Rich-Context Dubber): A second DiT model trained on these video pairs. As it receives the complete (unoccluded) companion video as input, it performs 'editing' rather than 'inpainting,' enabling precise lip modification and identity preservation using the full visual context.
Applied Technologies
Diffusion Transformer (DiT): Serves as the backbone network for both the generator and editor, trained using flow matching.
Contextual Conditioning: The editor concatenates reference and target videos along the frame dimension (token sequence) rather than the channel dimension, allowing interaction via 3D self-attention.
Time Step-Adaptive Multi-Stage Learning:
High-Noise Phase: Full-parameter fine-tuning for global structure and pose.
Medium-Noise Phase: Employs LoRA experts with SyncNet loss for lip clarity.
Low-Noise Phase: Uses LoRA experts for high-frequency texture and identity details.
Occlusion and Lighting Enhancement: Adopts specific strategies during data construction to ensure model robustness.
Achieved Effects
SOTA Performance: Surpasses existing methods (e.g., Wav2Lip, MuseTalk, LatentSync) on the HDTF dataset and the new ContextDubBench.
Superior Robustness: Excels in scenarios where mask-based methods tend to fail, such as dynamic lighting, facial occlusions, and large pose variations.
High Fidelity: Achieves better identity preservation (CSIM) and lip-sync accuracy (Sync-C) compared to baselines.
User Preference: Human evaluators significantly prefer X-Dub's results in terms of realism and synchronization.
Methodology
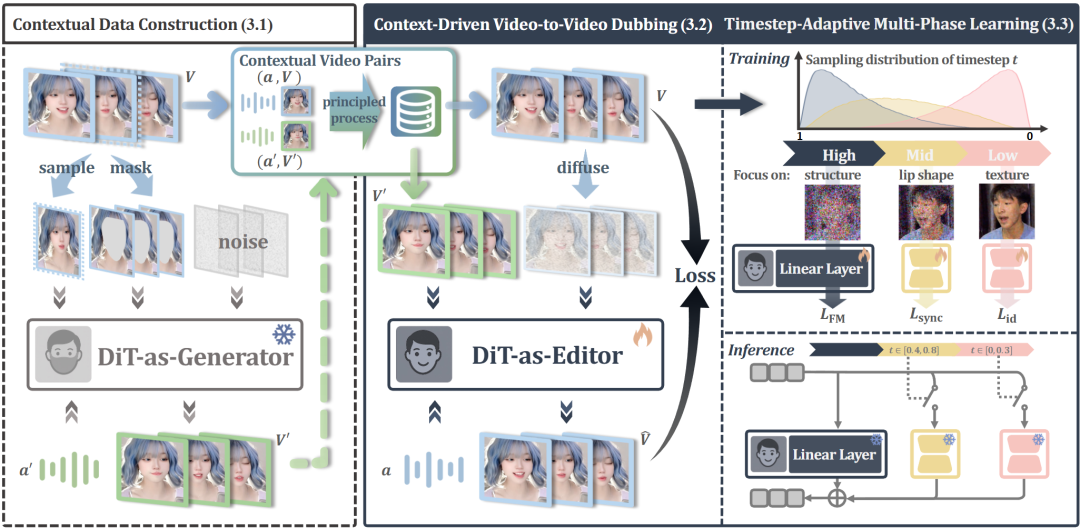 Figure 2: Overview of our self-guided dubbing framework, X-Dub. The core of the paradigm is using a DiT generator to create a lip-modified counterpart video for each input video, forming contextually rich pairs with the original (left). Then, a DiT editor directly learns mask-free, video-to-video dubbing from these ideal pairs, leveraging the full visual context to ensure accurate lip-sync and identity preservation (middle). This contextual learning is further refined through our time step-adaptive multi-stage learning (right), which aligns different diffusion phases with learning distinct aspects (global structure, lip movement, and texture details, respectively).
Figure 2: Overview of our self-guided dubbing framework, X-Dub. The core of the paradigm is using a DiT generator to create a lip-modified counterpart video for each input video, forming contextually rich pairs with the original (left). Then, a DiT editor directly learns mask-free, video-to-video dubbing from these ideal pairs, leveraging the full visual context to ensure accurate lip-sync and identity preservation (middle). This contextual learning is further refined through our time step-adaptive multi-stage learning (right), which aligns different diffusion phases with learning distinct aspects (global structure, lip movement, and texture details, respectively).
As shown in Figure 2, this paper establishes a self-guided dubbing framework where a DiT model first generates visually aligned video pairs with differing lip movements and then learns the dubbing task from these pairs, thereby reconstructing dubbing from a pathological inpainting problem into a well-conditioned video-to-video editing task.
First, the DiT-based generator is introduced. Trained with a masked inpainting self-reconstruction objective, it synthesizes companion videos with altered lip shapes purely as contextual inputs. To ensure these synthetic companions serve as reliable visual conditions, the paper introduces principled construction strategies. These strategies prioritize identity preservation and robustness over secondary lip accuracy and generalization capabilities, employing stringent quality filtering and augmentation measures to minimize artifacts and maximize visual alignment.
Building upon these meticulously curated video pairs, the DiT-based editor learns mask-free dubbing as a context-driven editing task, achieving precise lip synchronization, faithful identity preservation, and robustness to pose and occlusion variations. Finally, a time step-adaptive multi-stage learning scheme is proposed. This scheme aligns diffusion phases with complementary objectives (structure, lips, and texture) to facilitate stable training convergence within this editing paradigm and further enhance dubbing quality.
DiT Backbone Network: The backbone follows a latent space diffusion paradigm, utilizing a 3D VAE for video compression and DiT for sequence modeling. Each DiT block incorporates 2D spatial and 3D spatiotemporal self-attention, along with cross-attention for external conditions.
Generator: Contextual Condition Builder
Naive Masked Dubbing
The DiT-based generator is implemented under a masked self-reconstruction scheme, following prior dubbing methods. Given a target video and audio, a facial mask is applied, and the masked region is reconstructed under conditions and reference frames.
Although this setup does not produce perfect dubbing outputs, the generator is not designed to directly solve the dubbing problem but merely to synthesize companion videos as contextual inputs for the editor. By altering lip movements within otherwise consistent frames, the generator transforms sparse inpainting contexts into aligned video pairs, which are far more powerful than static reference frames.
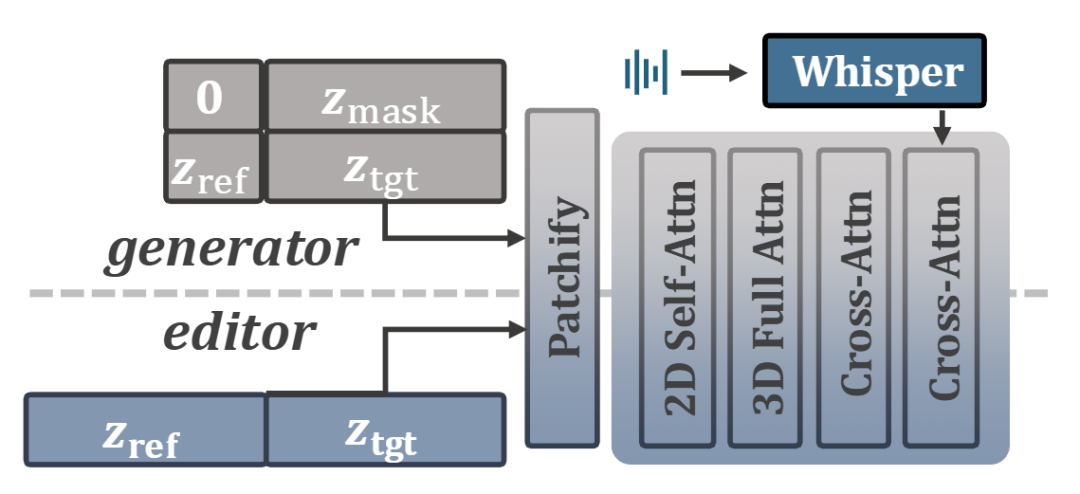 Figure 3: Conditioning mechanism of the DiT-based framework. Reference conditions (full-context video frames for the editor; single reference frames for the generator) and target videos are concatenated into a unified sequence for 3D self-attention. Audio is injected via cross-attention.
Figure 3: Conditioning mechanism of the DiT-based framework. Reference conditions (full-context video frames for the editor; single reference frames for the generator) and target videos are concatenated into a unified sequence for 3D self-attention. Audio is injected via cross-attention.
Conditioning Mechanism: As shown in Figure 3, masked frames and target frames are encoded by the VAE as, and reference frames as. is concatenated with noisy along the channel dimension, with zero-padding to align channels. Cross-frame concatenation produces a unified DiT input, enabling interaction between video and reference tokens via 3D self-attention. Whisper features are injected as audio conditions via cross-attention. To extend generation to long videos, motion frames are used: each segment is conditioned on the last few frames of the preceding segment. During training, the first frames of remain noise-free as motion guidance. Conditional dropout (50%) is employed to handle missing prior frames in initial segments.
Training Objective: Flow matching loss is adopted and weighted by facial and lip masks extracted via DWPose (denoted as element-wise multiplication):
After training in this manner, the generator produces a synthetic companion video for each real clip by replacing the original audio with alternative audio, yielding frame-aligned but lip-modified video pairs. Here, serves solely as a conditional input for the editor.
Principled Paired Construction Strategies
Naive masked dubbing inevitably produces imperfect results. Thus, this paper designs explicit trade-off strategies during the generator's data construction process to ensure synthetic companion videos, while imperfect, serve as reliable contextual inputs.
Three guiding principles are established:
In-Domain Quality Over Generalization: Focus on fidelity within the training distribution.
Visual Consistency Under Variations: Companion videos must preserve identity and remain robust to pose, occlusion, and lighting variations.
Lip Variation Over Accuracy: Lip shapes in should differ from those in to avoid leakage while tolerating moderate lip-sync inaccuracies.
Accordingly, several strategies are implemented. Leveraging short-term visual stationarity, the generator processes videos in 25-frame segments where pose and scene remain relatively stable. Motion frames then concatenate these segments into complete 77-frame videos for subsequent editor training. Alternative audio is sampled from the same speaker as to reduce cross-identity conflicts.
To enhance robustness, complementary techniques are incorporated. Occlusions are handled by annotating and excluding facial occlusions from the inpainting region. For lighting enhancement, identical relighting processing is applied to and to construct video pairs with consistent lighting dynamics. Quality filtering is performed using landmark distance, identity similarity, and overall visual quality scores. Additionally, 3D-rendered data is supplemented to obtain perfectly aligned video pairs.
Editor: Context-Driven Video-to-Video Dubbing
Given meticulously curated video pairs, a DiT-based editor is trained for mask-free dubbing. Unlike the generator, the editor directly tackles the dubbing task: given audio and companion video, it learns to generate as the target, thereby transforming dubbing from a sparse inpainting problem into a context-driven editing problem. In practice, benefiting from the rich contextual inputs provided by the video pairs, the editor surpasses the generator in lip accuracy, identity preservation, and robustness.
Contextual Conditioning Mechanism: As shown in Figure 3, paired reference and target videos are encoded as latent variables. Diffused is subsequently concatenated with clean across frames to form. Patching this sequence enables contextual interaction via 3D self-attention, fully leveraging the contextual modeling capabilities of the DiT backbone with minimal modifications. Audio features and motion frames are integrated in the same manner as in Section 3.1.
LoRA Expert-Based Time Step-Adaptive Multi-Stage Learning
While lip-modified video pairs significantly simplify the dubbing task, the editor's training must still balance three objectives: inheriting global structure, editing lip movements, and preserving fine-grained identity details. Diffusion models exhibit phased specialization across time steps. Inspired by this, the paper introduces a time step-adaptive multi-stage scheme where different noise regions target complementary objectives.
Phase Division: Following Esser et al., the moving time step sampling distribution is adjusted to concentrate on different noise levels during each training phase:
where is a log-normal distribution, and sets the offset intensity. This yields:
High-Noise Steps: For global structure and movement (background, pose, coarse identity).
Medium-Noise Steps: For lip movement.
Low-Noise Steps: For texture refinement involving identity details.
High-Noise Full-Parameter Training: Initially, the editor undergoes full-parameter optimization training under high-noise distributions. This promotes convergence and enables the model to seamlessly transfer global structure from reference contexts while achieving preliminary lip synchronization. The objective function remains the same masked-weighted flow matching loss.
Medium-Low Noise LoRA Expert Fine-Tuning: Subsequently, lightweight LoRA modules are appended for medium- and low-noise phases. Due to the need for pixel-level constraints, a single-step denoising strategy is designed to avoid computational overhead:
where ensures denoising stability at high noise levels.
The Lip Expert operates during medium-noise phases, supervised by an additional lip-sync loss (using SyncNet for audiovisual alignment).
The Texture Expert operates during low-noise phases, supervised by a reconstruction loss (combining L1, CLIP, and ArcFace identity losses) to restore high-frequency details. To safeguard lip-sync quality, the audio cross-attention mechanism is randomly disabled with a probability of 0.5 during texture fine-tuning phases, computing texture supervision signals solely under silent conditions.
During inference, each LoRA module is activated within its optimal time step range: the Texture Expert operates in the t ∈ [0, 0.3] interval, and the Lip Expert operates in the t ∈ [0.4, 0.8] interval, ensuring both function during their most effective generation phases.
Experimental Summary
This paper evaluates the proposed editor on HDTF (High-Definition Dataset) and the newly introduced ContextDubBench, comparing it against state-of-the-art methods such as Wav2Lip, VideoReTalking, TalkLip, IP-LAP, Diff2Lip, MuseTalk, and LatentSync.
Quantitative Results:
HDTF: The editor achieves the lowest FID (7.03) and FVD, along with the highest Sync-C (8.56) and CSIM (0.883), substantially outperforming previous best methods (e.g., FID reduced by 12.6%, Sync-C improved by 4.9%).
ContextDubBench: The advantages are even more pronounced on this challenging benchmark. The method achieves a 96.4% success rate (with the next best method reaching only around 72%), along with superior lip-sync accuracy (Sync-C +16.0%) and identity preservation capability (CSIM +6.1%).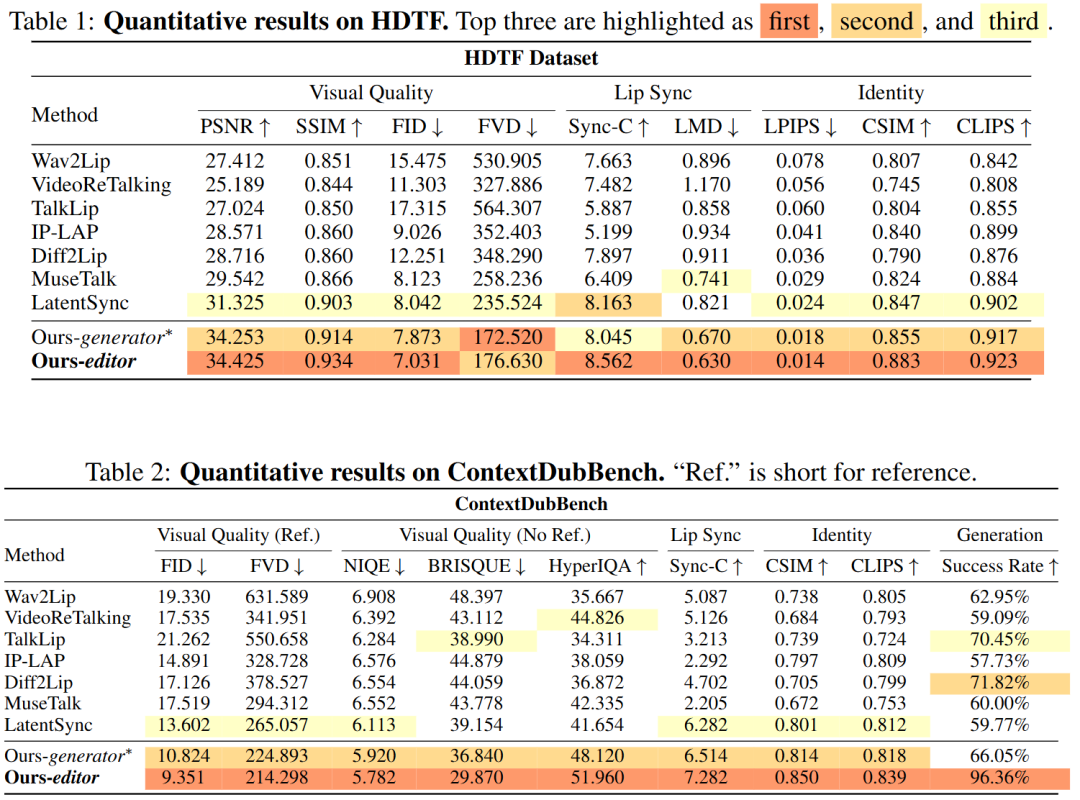
Qualitative Results:
The visualization results show that X-Dub can produce precise lip synchronization and maintain identity even in side views or with occlusions (such as hands partially covering the face), whereas mask-based methods typically fail or produce artifacts in these scenarios.
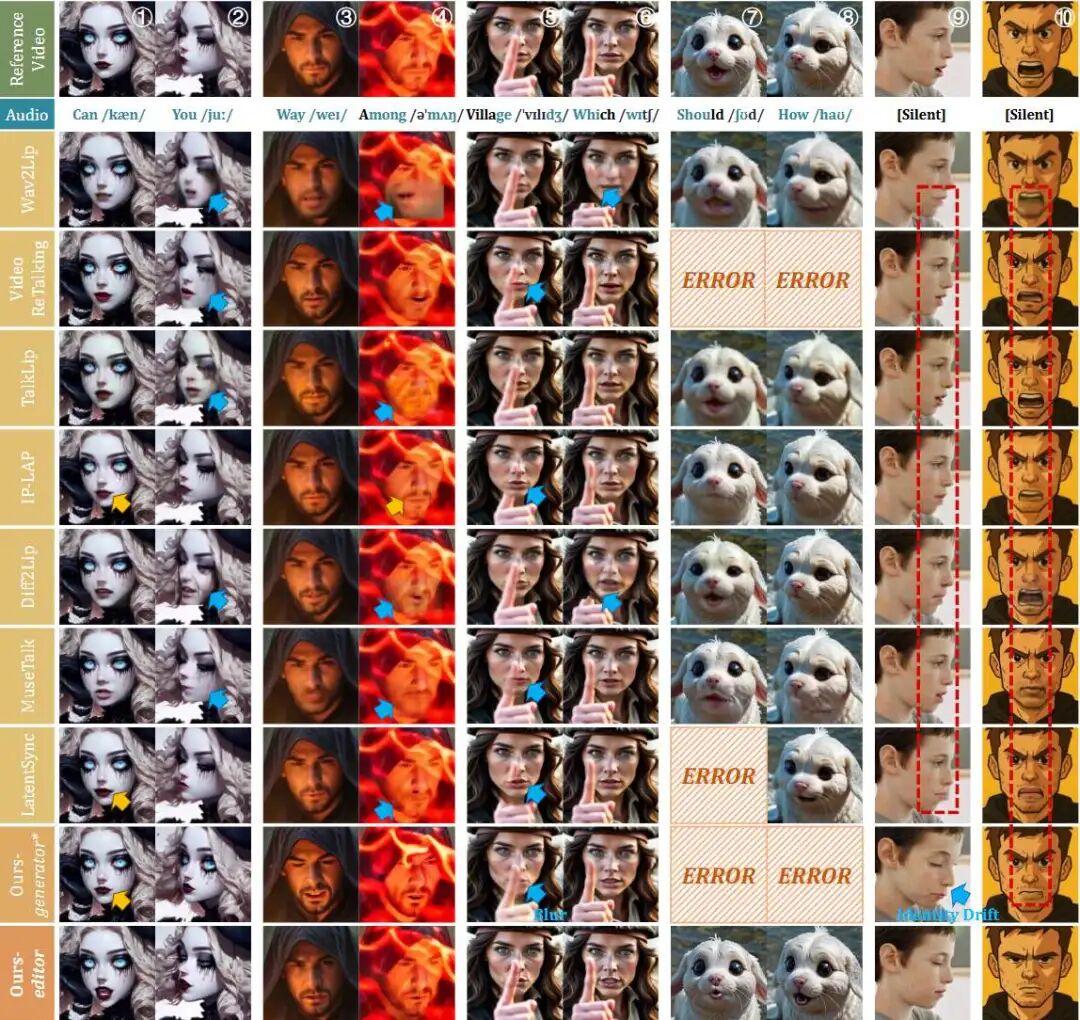 Figure 4: Qualitative comparison across various scenarios. Lip-sync errors are marked in yellow, visual artifacts in blue, and lip leaks during silence in red. "ERROR" indicates runtime failures due to unfound 3DMM or landmarks, despite best efforts. Our method demonstrates robust gums, superior lip accuracy, and identity consistency.
Figure 4: Qualitative comparison across various scenarios. Lip-sync errors are marked in yellow, visual artifacts in blue, and lip leaks during silence in red. "ERROR" indicates runtime failures due to unfound 3DMM or landmarks, despite best efforts. Our method demonstrates robust gums, superior lip accuracy, and identity consistency.
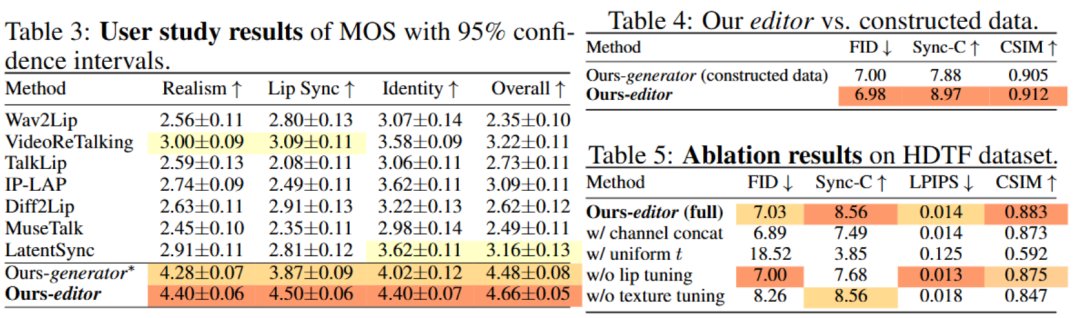
Ablation Study:
Conditioning: Token concatenation (across frames) outperforms channel concatenation, which impairs lip-sync accuracy.
Multi-stage Learning: Removing the lip fine-tuning stage decreases the Sync-C score; removing the texture stage harms identity metrics. Uniform time-step sampling leads to divergence or low quality.
User Study: In a study with 30 participants, the method received the highest Mean Opinion Score (MOS) for realism, lip-sync accuracy, and identity preservation.
Conclusion
This work introduces a novel self-bootstrapping paradigm to address the core challenge in visual dubbing: the lack of paired real-world training data. We argue that visual dubbing should not rely on mask inpainting but should instead be reframed as a well-conditioned video-to-video editing task.
Based on this paradigm, we propose X-Dub, a context-rich dubbing framework. It utilizes a DiT model first as a generator to create ideal training pairs with complete visual context, and then as an editor to learn from these carefully curated data. This process is further refined through a time-step adaptive multi-stage learning strategy, which decouples the learning of structure, lips, and texture, thereby enhancing the quality of the final output.
Extensive experiments on standard datasets and our newly proposed challenging benchmark, ContextDubBench, demonstrate that our method achieves state-of-the-art results. X-Dub exhibits exceptional robustness in complex in-the-wild scenarios, significantly outperforming previous works. We believe this work not only sets a new standard for visual dubbing but also provides valuable insights for other conditional video editing tasks lacking paired data.
References
[1] FROM INPAINTING TO EDITING: A SELF-BOOTSTRAPPING FRAMEWORK FOR CONTEXT-RICH VISUAL DUBBING
-
![]()
After AI Short Dramas Hit Their Peak, Douyin Chooses a Different Path
-
![]()
Weighing the Pros and Cons of In-House Chip Development: Most Automakers Shouldn't Feel Compelled to Pursue It
-
![]()
Can the Leapmotor D99 Gracefully Ascend into the Premium MPV Market as the Brand Climbs Higher?
-
Midea Bets 1 Billion Yuan on Liquid Cooling, Targeting AI Computing Power Market with 2027 Production Launch
-
Amidst Declining Profit Margins, Can Anwen Technology Sustain Its Edge in Automotive Cockpits?
-
![]()
5,000 Companion Robots Sold: Can UBTECH Breathe a Sigh of Relief?
-
![]()
NIO Maintains Brand Premium: Onvo Sets Minimum Price at 150,000 Yuan, Avoids Direct Competition with Leapmotor and BYD | MJ Pro
-
![]()
“From a 5-minute escape window to a zero-fire baseline, I finally feel confident driving an electric vehicle”