DeepSeek Model1 Code Unveiled: A 'Technical Easter Egg' to Mark the R1 Anniversary
 01/22 2026
01/22 2026
 643
643
Today, January 21, 2026, marks the first anniversary of the release of DeepSeek-R1. This open - source model, which made waves in the global AI community on January 20 of the previous year, not only graced the cover of Nature but also earned the title of the most - liked model on Hugging Face.
A year after the release of R1, DeepSeek's GitHub repository has seen an unusual update. In the commit history of the FlashMLA codebase, a new identifier, MODEL1, has surfaced in 28 different locations across 114 files.
This is a clear indication that DeepSeek's next - generation flagship model has entered the engineering development stage. According to previous reports, this new model, DeepSeek V4, is slated for release during the Lunar New Year in mid - February.
A thorough examination of the code differences gradually unveils the technical outline of MODEL1. Unlike V3.2, which maintained a 576 - dimensional configuration, MODEL1 reverts to a standard 512 - dimensional architecture.
This change is probably aimed at better aligning with the computational capabilities of NVIDIA's next - generation Blackwell GPU architecture. In fact, the codebase reveals extensive optimizations specifically tailored for the Blackwell architecture, including the addition of the new SM100 interface.
More significantly, MODEL1 brings about the evolution of Token - level Sparse MLA operators. The test scripts contain both sparse and dense decoding test files. The Sparse operator stores the KV Cache using FP8 but uses bfloat16 for matrix multiplication to ensure precision.
This mixed - precision design implies that the new model will reduce memory pressure and enhance speed through sparse inference in extremely long - context scenarios.
The Engram mechanism might be the most innovative feature of MODEL1. This new module separates factual memory from the computationally expensive continuous neural network operations, shifting to deterministic and efficient lookups.
Engram and MoE (Mixture of Experts) create complementary sparsity. MoE achieves conditional computation by activating only a few expert networks, while Engram enables conditional lookups by accessing only a minimal number of memory entries.
Over the past month, DeepSeek's intensive technical activities have set the stage for the release of V4.
On January 4, DeepSeek updated its R1 paper on arXiv, expanding it from 22 pages to a substantial 86 pages. The updated version provides a detailed breakdown of the training pipeline, extensive data from over 20 evaluation benchmarks, and dozens of pages of technical appendices.
The paper now includes a 'Failed Attempts' section, openly acknowledging that the team explored two popular industry approaches—MCTS and PRM—but without success.
In mid - January, DeepSeek published a paper titled 'Conditional Memory via Scalable Lookup,' formally introducing the Engram module. Authored by DeepSeek founder Liang Wenfeng, the paper lays out the theoretical foundation and engineering implementation of conditional memory.
According to reports, V4 will boast significantly enhanced code - writing capabilities. Internal tests suggest that its AI programming performance may outperform that of OpenAI's GPT and Anthropic's Claude.
V4 is designed to handle longer and more complex coding tasks, offering a substantial advantage to developers working on intricate software projects.
DeepSeek V3.2 has already outperformed OpenAI's GPT - 5 and Google's Gemini 3.0 Pro in certain benchmarks, and V4 is expected to achieve further breakthroughs.
The introduction of Engram technology could fundamentally transform how large models operate. By separating static memory from dynamic computation, models can access vast amounts of 'known patterns' with minimal computational power, reserving valuable resources for tasks that truly require reasoning.
From an engineering perspective, Engram's deterministic addressing supports prefetching from host memory at runtime, which is of great value for the local deployment of large models.
References:
https://36kr.com/p/3631908557374473
https://mp.weixin.qq.com/s/HwmgJH26lHUKk4oQdV_olg
-
![]()
The Agent hasn't arrived yet, but Ascend has already paved the way from hardware to software.
-
![]()
In 71 years, He sold products to 100 million people
-
![]()
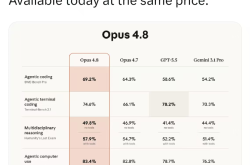
First-hand Practical Test! Opus 4.8 Vs ChatGPT 5.5 Vs Kimi 2.6: Which is the Most Usable?
-
![]()
Fourfold Uncertainty Challenges Facing China's Agent Industry - Interpretation of the 'Report' (Part Six)
-
Crazy Anthropic
-
![]()
CNPC’s Kunlun Model Advances with 152 Implemented Scenarios, Showcasing Proactive AI
-
![]()
Revenue Increases, But Profits Don't: Pinduoduo's Anxiety Amidst Billion-Dollar Brand Building
-
![]()
Half Flock In, Half Flee Out: The Dual Dynamics of Singapore as an AI Hub