Farewell to Spatiotemporal Collapse: Generative Games Embrace a 'Steady-State' Era! Nanjing University and Others Present StableWorld: Crafting Virtual Worlds with Infinite Endurance
 01/26 2026
01/26 2026
 588
588
Insights: The AI-Generated Future 
Key Highlights
Identified the root cause of instability in long-term interactive world modeling: minor drifts within the same scene accumulate over time, ultimately leading to overall scene collapse.
Introduced a simple yet effective method—StableWorld—which employs a dynamic frame eviction mechanism to prevent error accumulation at the source while maintaining motion continuity.
Validated the method's effectiveness across various interactive world models, including Matrix-Game 2.0, Open Oasis, and Hunyuan-GameCraft 1.0, under diverse scene conditions (static scenes, small/large motions, and significant viewpoint changes). Extensive experimental results show sustained and significant improvements in stability, long-term consistency, and generalization across interactive scenarios.
 Figure 1. StableWorld: Generating stable and visually consistent interactive videos across different environments, such as natural landscapes and game worlds, while maintaining continuous motion control and preventing long-term scene drift.
Figure 1. StableWorld: Generating stable and visually consistent interactive videos across different environments, such as natural landscapes and game worlds, while maintaining continuous motion control and preventing long-term scene drift.
Summary Overview
Problems Addressed
Current interactive video generation models (e.g., world models) exhibit severe stability issues and temporal inconsistencies when generating long sequences, manifesting as spatial drift and scene collapse.
Even in non-interactive or static scenes, models suffer from gradual frame deviation from the initial state due to error accumulation, undermining temporal consistency.
Proposed Solution
Introduced the StableWorld framework, centered around a dynamic frame eviction mechanism.
During sliding window generation, dynamically assesses and retains geometrically consistent keyframes (especially early, 'cleaner' frames) while evicting degraded or redundant intermediate frames, thereby suppressing error accumulation at the source.
Technologies Applied
Utilized the ORB + RANSAC algorithm to compute viewpoint overlap for assessing inter-frame geometric consistency.
Employed KV-cache window expansion analysis as technical justification, confirming that incorporating earlier, cleaner reference frames effectively stabilizes generation.
Quantified drift accumulation through inter-frame mean squared error (MSE) for phenomenon analysis and validation.
Achieved Results
Significantly enhanced stability and temporal consistency: effectively mitigated scene collapse and spatial drift in long-sequence generation.
Model-agnostic: validated effectiveness across multiple interactive video generation frameworks (e.g., Matrix-Game, Open-Oasis, Hunyuan-GameCraft), demonstrating strong generalization capabilities.
Maintained adaptability: suppressed cumulative errors without compromising the model's responsiveness to large motions and scene transitions.
Methodology
Preliminary Knowledge
Video Generation Models. Video generation models typically adopt a full-sequence generation approach, producing all frames simultaneously from noise under given conditions. Formally, the generation process can be defined as: where represents the state of the th frame at the th denoising step, and denotes the total number of frames generated. At each time step , all frames share the same noise variance and follow a unified noise schedule. While this method yields high-quality results, its high computational cost from modeling the entire sequence in a single forward pass renders it unsuitable for real-time interactive scenarios.
Interactive Video Generation. Unlike full-sequence models, interactive video generation employs an autoregressive paradigm, where each frame is generated conditioned on partial historical frames and the current action. This conditional generation is represented as , where denotes selected reference frames stored in the memory buffer, and represents the user-initiated or agent-driven action at the th step. This paradigm enables the model to generate frames sequentially based on user actions, facilitating real-time interaction and dynamic scene control.
Most recent approaches further integrate diffusion and autoregressive paradigms: diffusion models handle intra-frame denoising, while autoregression captures inter-frame temporal dependencies. Formally, the overall generation process can be expressed as: where denotes the th frame at diffusion time step . At each diffusion step, the model conditions on previously generated frames and the current action to denoise into . This formula combines spatial denoising within each frame and temporal dependencies across frames, achieving high-quality and real-time interactive video generation.
Causes of Scene Collapse
Although interactive video generation models can produce coherent short-term sequences, they remain prone to progressive scene collapse during extended generation, particularly when scenes remain highly similar over long periods (as shown in Figure 2 below). In contrast, when scenes frequently switch and models encounter new visual conditions, such collapse rarely occurs (as shown in Figure 6 below). This contrast suggests that collapse largely stems not from action control or motion complexity but from how visual information is preserved and propagated over time within the same scene.
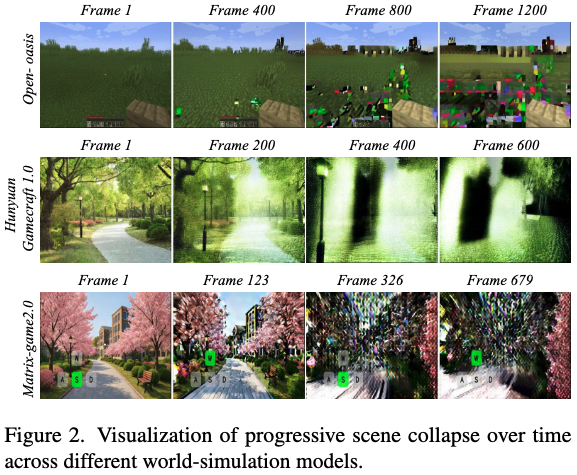

To understand this behavior, this work measured inter-frame mean squared error (MSE) distances to quantify how frame differences evolve during sequence progression in a single static scene, as shown in Figure 3 below. The left two plots display inter-frame drifts at varying intervals (1, 5, 10, 20) in latent space. Observations reveal that while adjacent frames exhibit only minor differences, these small drifts gradually accumulate over extended sequences. Frames compared at larger intervals (e.g., 10 or 20) show significantly greater drifts. Since such deviations already exist in latent space, pixel space exhibits similar drift patterns (as shown in the right two plots), ultimately manifesting as visual inconsistencies and scene collapse (Figure 2 above). These observations indicate that drifts within the same scene accumulate and propagate over time, eventually leading to global scene collapse.
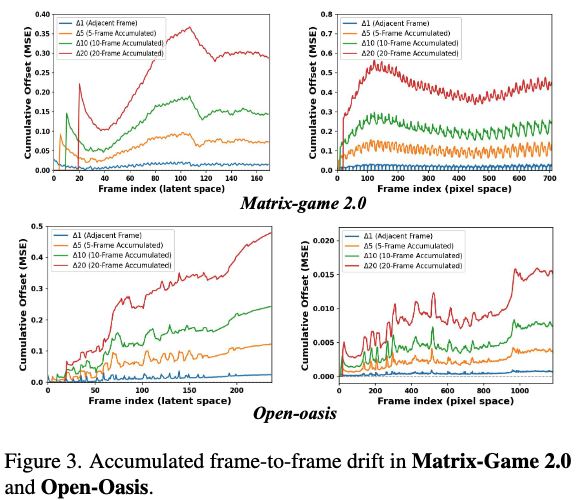
Based on this observation, this work hypothesized that using frames with smaller cumulative drifts as references could provide a more reliable basis for subsequent frame generation. To test this hypothesis, this work expanded the KV-cache window size, allowing the model to access clearer frames, as shown in Figure 4 below. It examined how frequency amplitude differences between each target frame and the first frame varied under different historical window sizes. Under default settings (window size = 9, Figure (a)), significant fluctuations appeared across all frequency bands. As the window size increased to 36 (Figure (b)) and 90 (Figure (c)), overall fluctuations slowed, indicating partial reduction in error accumulation. However, this improvement came at the cost of higher computational overhead and slower generation speeds, limiting its practicality.
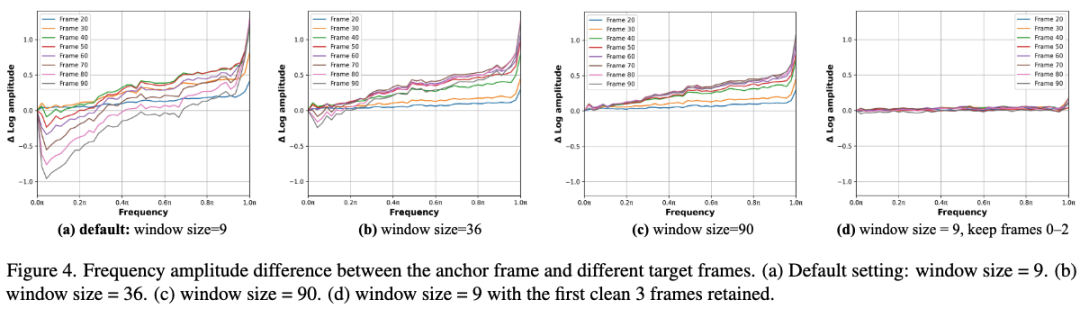
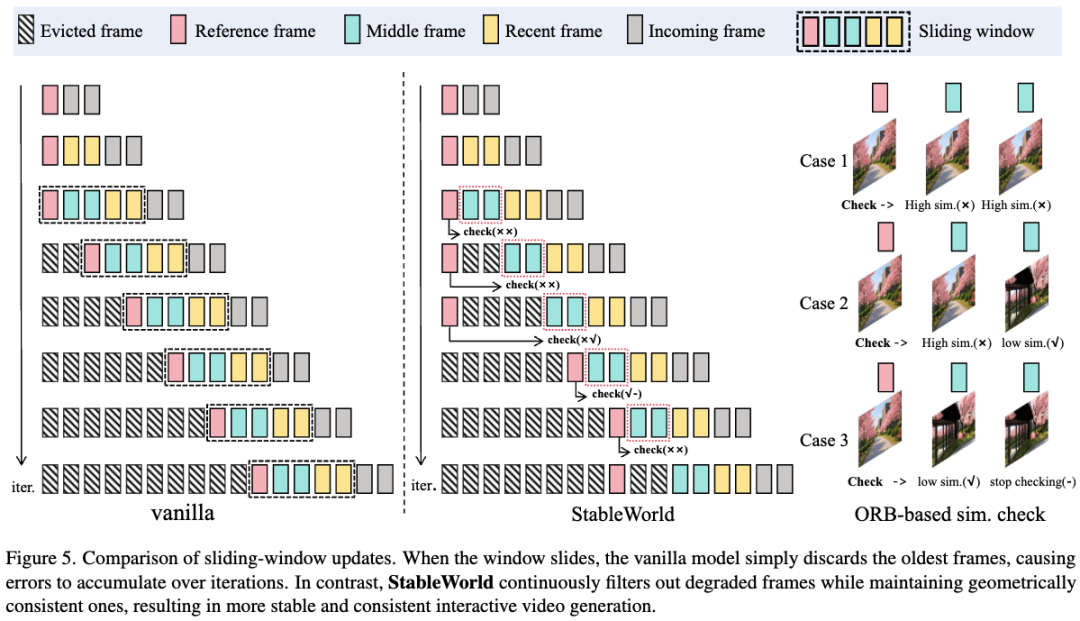
Further analysis revealed that the stability observed from larger windows primarily stemmed from retaining several clear early frames in the reference buffer. For example, in Figure (d), retaining a small number of reliable early frames within a fixed-size window resulted in significantly more stable generation, with later frames exhibiting minimal drift relative to the first frame. This finding underscores the critical role of early clear frame quality and preservation in mitigating cumulative errors. However, when large motions or dramatic scene transitions occur, retaining initial frames consistently becomes limiting. As shown in Figure 7 below, despite following identical action instructions, the setting strictly retaining early frames failed to switch to the new scene, indicating that excessive retention hinders scene transitions. To simultaneously mitigate cumulative drift and maintain flexibility in generating new scenes, this work introduced StableWorld, a simple yet effective framework based on a dynamic frame eviction mechanism (see Figure 5 below).

Dynamic Frame Eviction Based on ORB Geometric Similarity
To detect scene transitions, this work employed ORB feature matching combined with RANSAC-based geometric verification to measure inter-frame similarity. When explicit camera extrinsics are unavailable during inference, ORB provides an alternative by generating fast and rotation-invariant local features, making it highly suitable for detecting geometric consistency under minor camera motions. By integrating this similarity estimation with a dynamic frame eviction strategy, this work continuously filtered out degraded frames while retaining geometrically consistent ones, effectively preventing error accumulation across dynamic scenes.
When the window needs to slide, some frames must be evicted. For simplicity, assume each frame corresponds to a token, and one token is generated per iteration. Let denote the latent space tokens within the window, and their corresponding pixel space frames, where is the window size. Earlier frames in the window are defined as , where . Here, is treated as the reference frame, and is called the intermediate frame. At each update step, a new frame is generated, and an old frame is correspondingly evicted.
This work used the following strategy to determine which frame should be evicted. First, geometric similarity is measured by extracting ORB features from the reference frame and the intermediate frame . Let and denote the sets of ORB descriptors extracted from and , respectively, where and are the number of features detected per frame. Candidate correspondences are obtained through nearest-neighbor matching in descriptor space, followed by a Lowe ratio test: where is the ratio test threshold for filtering ambiguous matches, and represents the number of surviving correspondences.
Then, RANSAC is used in conjunction with homography matrix (H) and fundamental matrix (F) models to verify matches in , enforcing geometric consistency: where and denote the Sampson geometric errors evaluated under the estimated homography matrix and fundamental matrix , respectively, and and represent the corresponding inlier correspondence sets. is a predefined tolerance for inlier determination, with smaller errors indicating better geometric alignment. This work computed the inlier ratio: where and denote the number of inlier correspondences under the two models. The final similarity score is defined as:
If the similarity score exceeds a predefined threshold , the process continues to check farther frames . Once geometric similarity falls below , the process stops. Finally, if all intermediate frames meet the threshold, the farthest frame is evicted. Otherwise, the frame before the first failure is evicted (e.g., ). Detailed procedures and implementation settings are provided in Appendix A.
Experiments
Comprehensive experiments validated StableWorld's effectiveness across different models and scenarios.
Evaluation Metrics and Settings
This work conducted validation on three primary models: Matrix-Game 2.0, Open-Oasis, and Hunyuan-GameCraft 1.0.
Datasets: Covered natural scenes, game scenes, and diverse video sequences containing small and large motions.
Metrics:
VBench-Long: Assessed multidimensional indicators including video quality, aesthetic quality, dynamism, and temporal consistency.
User Study: Invited 20 participants to vote on video quality, temporal consistency, and motion smoothness.
Implementation Details: Set corresponding KV-cache window sizes and keyframe comparison strategies for different models. The ORB similarity threshold was uniformly set to 0.75.
Quantitative Results
VBench-Long Scores: As shown in Table 1 below, StableWorld significantly improved image quality and aesthetic quality across all three models.
On Matrix-Game 2.0, aesthetic quality improved by 14.61%.
On Open-Oasis, image quality improved by 7.38%.
On Hunyuan-GameCraft 1.0, aesthetic quality improved by 9.06%.
Although temporal quality and physical understanding metrics showed minimal changes (as original model collapses often led to static frames, misleading these metrics), StableWorld still demonstrated consistent improvements across most indicators, with computational latency increasing only by 1.00–1.02 times. 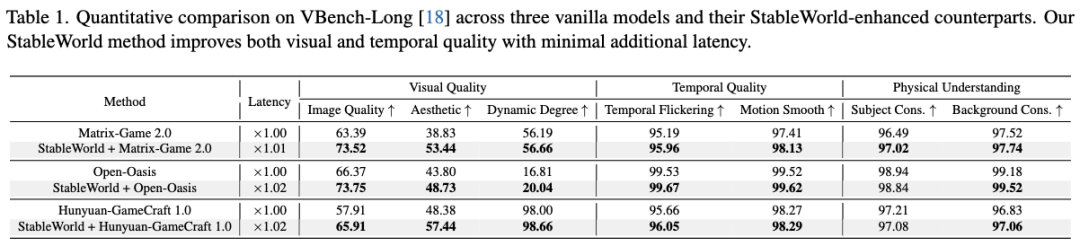
User Research: As shown in Table 2 below, StableWorld received the preference of the vast majority of users in terms of video quality, temporal consistency, and motion smoothness (e.g., on Open-Oasis, 96.4% of users believed that StableWorld videos had better quality). 
Qualitative Results
The figure below (Figure 8) shows a comparison of the three models before and after incorporating StableWorld.

The results show:
The Vanilla model experiences severe scene collapse and drift in long-sequence generation.
StableWorld effectively maintains scene stability, reduces drift over time, and preserves motion continuity.
More qualitative comparisons are provided in Appendix C, demonstrating the method's robustness in long sequences (thousands of frames) and small/large motion scenarios.
Ablation Experiments
Window Sizes: Figure 9 below shows that excessively large windows (e.g., 18 or 36) introduce residual artifacts from old scenes, interfering with new scene generation; a moderate window size (e.g., 9) yields the best results. 
Similarity Metrics: Figures 10 and 11 compare SSIM, cosine similarity, and ORB.
SSIM is overly sensitive to perspective changes, leading to premature removal of clear frames.
Cosine similarity is insensitive to spatial transformations, often missing scene changes and resulting in residual old frames.
ORB achieves the best balance between the two.
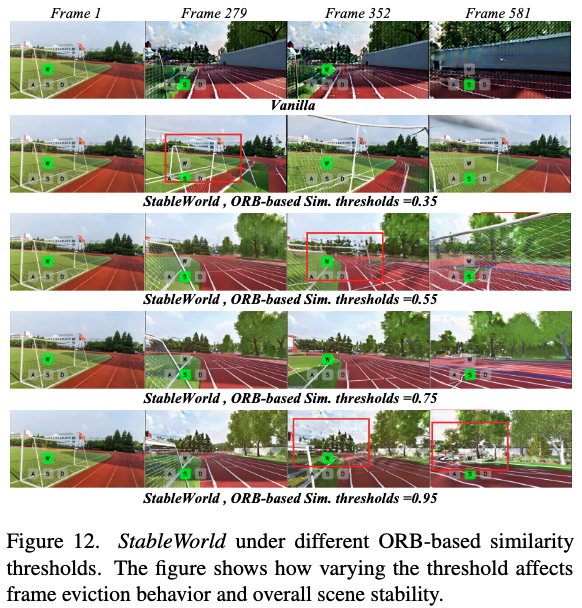
ORB Similarity Threshold: Figure 12 below shows that a threshold of 0.75 yields the best results. Too low a threshold causes old frames to persist too long, hindering new scene generation; too high a threshold leads to premature removal of clear frames, introducing cumulative errors. 

Conclusion
This paper identifies a prevalent issue in current interactive video generation models: scene collapse. Through in-depth analysis, it is found that this collapse stems from inter-frame drift occurring between adjacent frames within the same scene. This drift gradually accumulates over time, ultimately leading to a significant deviation from the original scene. Inspired by this observation, this work proposes a simple yet effective method—StableWorld, a dynamic frame removal mechanism that significantly reduces error accumulation while maintaining motion consistency. This work evaluates the method on multiple interactive video generation models (including Matrix-Game 2.0, Open-Oasis, and Hunyuan-GameCraft 1.0). Extensive experiments demonstrate that the proposed method substantially improves the visual quality of long-duration generation and shows great potential for integration with future world models.
References
[1] StableWorld: Towards Stable and Consistent Long Interactive Video Generatio
-
Hao Jida, Apple Supply Chain Coil Supplier, Switches Brokerage and Revives IPO Amidst Customer Dependency and Compliance Challenges
-
![]()
Annual Advertising Expenditure of VOYAH with Yudeshui: A Deep Dive
-
![]()
Can Computers, Despite Daily Price Hikes, Still Be a Viable Purchase?
-
![]()
January-June Auto Stocks' 'Resilience Ranking': Geely Alone Posts Gains, Six Plummet Over 40%, One Tumbles 54.5% | Mirror Pro
-
![]()
China’s Public Charging Market: Didi Charging, Teld, and Yunkuai Take the Lead
-
![]()
The First Year of AI-Native Mid-Year Shopping Festival: Technology Reconstructs Human-Product Matching for 618
-
![]()
Micron has released its financial report, showing revenues of $41.5 billion, a 74% increase quarter-over-quarter, with a gross margin of 84.6%. The company provided both short-term and long-term guida
-
![]()
Expert Interpretation of New Policy Combination: Activating the Trillion-Dollar Automotive Aftermarket