Unifying the Visual Realm! OpenVision 3 Unveiled: A Single Encoder Achieves Perfect Harmony Between Understanding and Generation, Outperforming CLIP in Both Aspects
 01/26 2026
01/26 2026
 564
564
Interpretation: The Future of AI-Generated Content
Key Highlights
Unified Architecture: OpenVision 3 is an advanced visual encoder capable of learning a single, unified visual representation that serves both image understanding and image generation tasks.
Simplified Design: The core architecture is highly streamlined, inputting VAE-compressed image latent space variables into a ViT encoder and training it to support two complementary roles (reconstruction and semantic understanding).
Synergistic Optimization: By jointly optimizing reconstruction-driven and semantics-driven signals within a shared latent space, the encoder learns representations that generalize well and synergize effectively under both mechanisms.
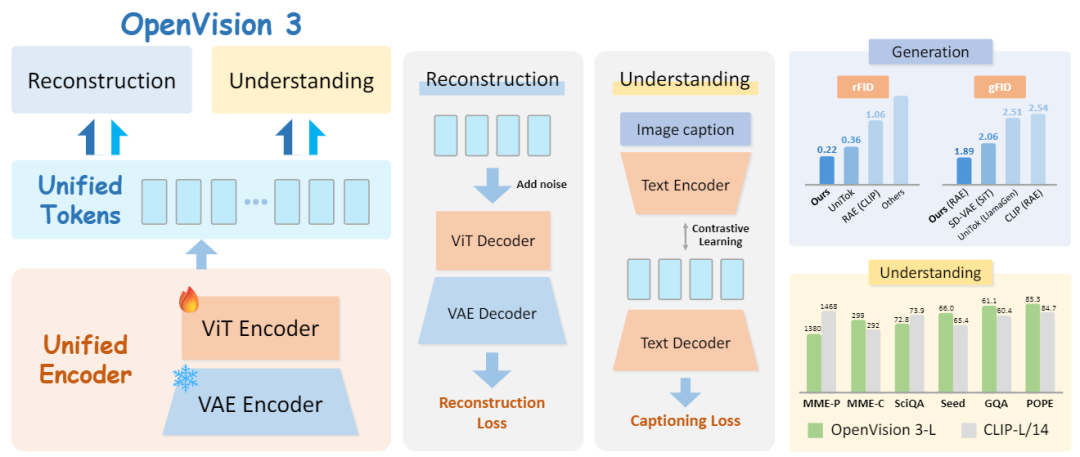 Figure 1. Overview of OpenVision 3's architectural design and performance highlights. Left Panel: Architecture of OpenVision 3. It employs a frozen VAE and a trainable ViT as a unified tokenizer, generating tokens that feed into both generation and understanding branches. Middle Panel: Learning objectives for the generation and understanding branches. In the generation branch, we focus on high-quality pixel-level image reconstruction; concurrently, the understanding branch is optimized through joint contrastive learning and captioning objectives. Right Panel: Performance summary showing that OpenVision 3 outperforms other unified tokenizers and semantics-based encoders in terms of rFID and gFID, while remaining competitive with CLIP in multimodal understanding capabilities.
Figure 1. Overview of OpenVision 3's architectural design and performance highlights. Left Panel: Architecture of OpenVision 3. It employs a frozen VAE and a trainable ViT as a unified tokenizer, generating tokens that feed into both generation and understanding branches. Middle Panel: Learning objectives for the generation and understanding branches. In the generation branch, we focus on high-quality pixel-level image reconstruction; concurrently, the understanding branch is optimized through joint contrastive learning and captioning objectives. Right Panel: Performance summary showing that OpenVision 3 outperforms other unified tokenizers and semantics-based encoders in terms of rFID and gFID, while remaining competitive with CLIP in multimodal understanding capabilities.

Addressed Challenges
Bottlenecks in Unified Modeling: Previous research often required separate encoders for generation tasks (capturing low-level pixel features) and understanding tasks (capturing high-level semantic features). Existing attempts at unification typically relied on complex discrete token designs (e.g., Vector Quantization VQ) or pre-trained checkpoints, and the construction of unified feature spaces and efficient training pipelines remained insufficiently transparent.
Proposed Solution
VAE-ViT Hybrid Architecture: Utilizes a frozen FLUX.1 VAE to compress images into latent space variables, followed by extraction of unified features through a from-scratch-trained ViT.
Dual-Branch Decoding:
Reconstruction Branch: Focuses on high-quality pixel-level image reconstruction, enhancing generalization capabilities through noise addition.
Understanding Branch: Optimized through joint contrastive learning and image captioning objectives to strengthen semantic features.
Applied Technologies
FLUX.1 VAE: Used for initial image compression, downsampling the input.
Vision Transformer (ViT): Processes VAE latent space variables with a patch size set to [specific value], achieving a total compression rate of [specific value].
Noise Injection: Adds Gaussian noise to the unified representation in the reconstruction branch to enhance the robustness of generation capabilities.
Multi-Objective Loss Function: Combines [number] reconstruction loss, LPIPS perceptual loss, contrastive loss, and captioning loss.
Achieved Results
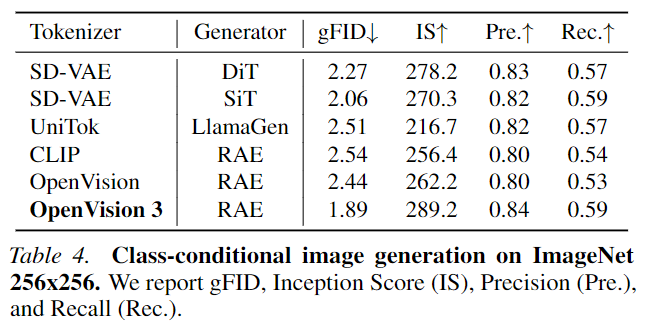
Generation Performance: On ImageNet, OpenVision 3 achieves a gFID of 1.89, significantly outperforming the standard CLIP-based encoder (2.54) and surpassing other unified tokenizers in both rFID and gFID.
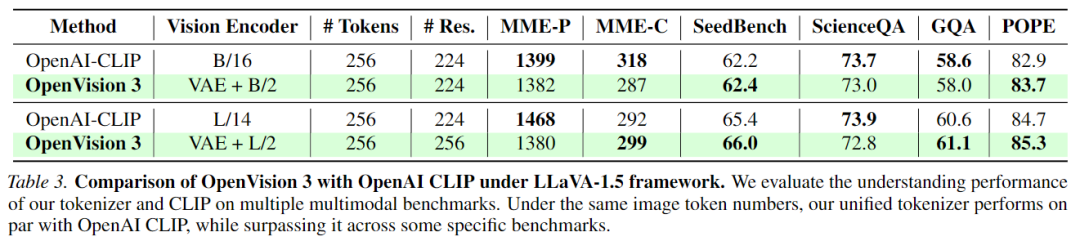
Understanding Performance: In multimodal understanding, when integrated into the LLaVA-1.5 framework, its performance is comparable to that of the standard CLIP visual encoder (e.g., 62.4 vs. 62.2 on SeedBench, 83.7 vs. 82.9 on POPE).
Methodology
Motivation
Developing a unified tokenizer is a critical step toward achieving unification of generation and understanding, yet it is often hindered by difficulties in establishing a unified feature space and inefficient training processes. Previous studies have proposed numerous impressive methods to overcome these barriers. However, exploration into constructing unified representations remains in its preliminary stages, and the associated training pipelines are still insufficiently transparent to the community. The OpenVision 3 model is proposed, which constructs a unified visual representation space in an effective and straightforward manner through VAE and ViT. It demonstrates how to efficiently train a unified tokenizer from scratch within the VAE latent space.
OpenVision 3: A Unified Tokenizer
OpenVision 3 employs a VAE encoder and Vision Transformer (ViT) to extract unified visual features. The input image [image] is first encoded by the VAE encoder [VAE] from FLUX.1-dev into VAE latent space variables [latent], with subsequent training processes conducted entirely within the VAE latent space. The VAE latent space variables are then input into the ViT encoder [ViT] to extract unified representations [representation] for both understanding and generation tasks.
During the VAE stage, FLUX.1 VAE downsamples the image height and width by [specific value], respectively. Thus, the patch size of the ViT is adjusted to [specific value], resulting in an overall compression rate of [specific value], consistent with common settings. This is formalized as follows:
Where [C] is the number of channels in the VAE latent space variables, and [D] is the dimension of the ViT. The encoded unified features [representation] then proceed to the reconstruction and understanding branches for decoding. OpenVision 3 employs two entirely independent branches to cultivate its ability to extract generative and interpretive visual representations, with their respective architectures detailed below.
Reconstruction Branch: The reconstruction decoding component mirrors the structure of the tokenizer, maintaining a nearly symmetrical configuration. Before decoding, noise is first added to the unified representation to enhance the generalization of generation capabilities. The perturbed features [perturbed] are generated by adding Gaussian noise scaled by sample-specific intensity:
Where [scale] is uniformly sampled from [range], and [constant] is a constant. Subsequently, a ViT decoder with a patch size of [specific value] and a linear layer are used to convert the noise-added unified features [perturbed] back into VAE latent space variables [latent_recon]. Next, the VAE decoder is applied to decode [latent_recon] into the reconstructed image [image_recon]. The reconstruction loss includes losses for reconstructing both the image [image] and VAE latent space variables [latent], along with an LPIPS-based perceptual loss. The entire reconstruction loss can be formalized as:
Understanding Branch: The paradigm of the understanding branch generally follows the design of OpenVision, performing contrastive learning and image captioning. As shown in Figure 1, a text encoder is used to extract caption features [caption_feature] for computing contrastive loss with the unified visual features [representation]. Meanwhile, a text decoder is utilized to autoregressively predict synthetic captions from the unified representation and compute the corresponding captioning loss. Formally, the understanding loss can be expressed as:
The overall training objective is:
During training, [lambda_recon] is configured to be twice [lambda_understanding]. Reducing [lambda_understanding] helps preserve generation quality while maintaining understanding capabilities.
Training Setup
Training Phases and Resolutions: Based on conclusions drawn from CLIPA, a progressive training strategy is adopted for the tokenizer, transitioning from low-resolution to high-resolution inputs. The tokenizer is first pre-trained at a resolution of [resolution_low], followed by fine-tuning at [resolution_high] or [resolution_higher]. The epoch allocation for the two training phases is maintained at approximately a 10:1 ratio. By concentrating most computation in the low-resolution phase, this approach significantly reduces the computational overhead typically associated with high-resolution training while achieving superior performance.
Training Details: As shown in Figure 1, a pre-trained FLUX.1 VAE is used and frozen throughout the entire training process. All other components (including the ViT encoder, ViT decoder, text encoder, text decoder, and linear layer) are randomly initialized and remain unfrozen throughout training. For both training phases, the global batch sizes are 8K and 4K, respectively, with base learning rates adopting cosine decay set to [learning_rate_low] and [learning_rate_high]. Detailed parameter configurations are provided in Table 1. The model is trained on the DataComp dataset, which has been re-annotated by LLaVA-Llama-3, ensuring high-quality training data.
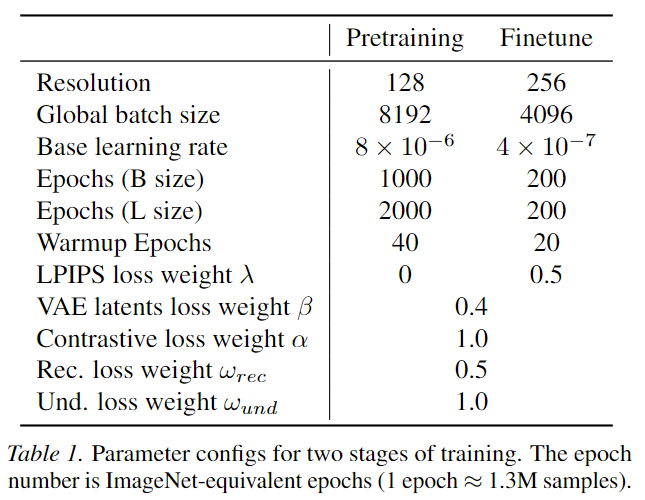
Experiments
Experimental Setup
To comprehensively evaluate the performance of the unified tokenizer, reconstruction, generation, and understanding performances are assessed separately. For generation, following the RAE configuration, a generative model is trained using DiT and a wide DDT head, and the generation fidelity of OpenVision 3 is evaluated. For understanding, the tokenizer is used to train a visual-language model within the LLaVA-1.5 framework, and understanding performance is evaluated across multiple downstream multimodal benchmarks.
Performance
Reconstruction Performance: OpenVision 3 significantly outperforms existing unified tokenizers across various metrics. For instance, on ImageNet, OpenVision 3 achieves a PSNR of 30.33 dB, substantially surpassing UniTok (25.34 dB) and Vila-U (22.24 dB). In terms of perceptual quality (LPIPS), it scores 0.061, outperforming UniTok's 0.132.
Generation Performance: When tested using the RAE framework, OpenVision 3 surpasses other tokenizers (including CLIP and SD-VAE) on metrics such as gFID, Inception Score (IS), Precision, and Recall.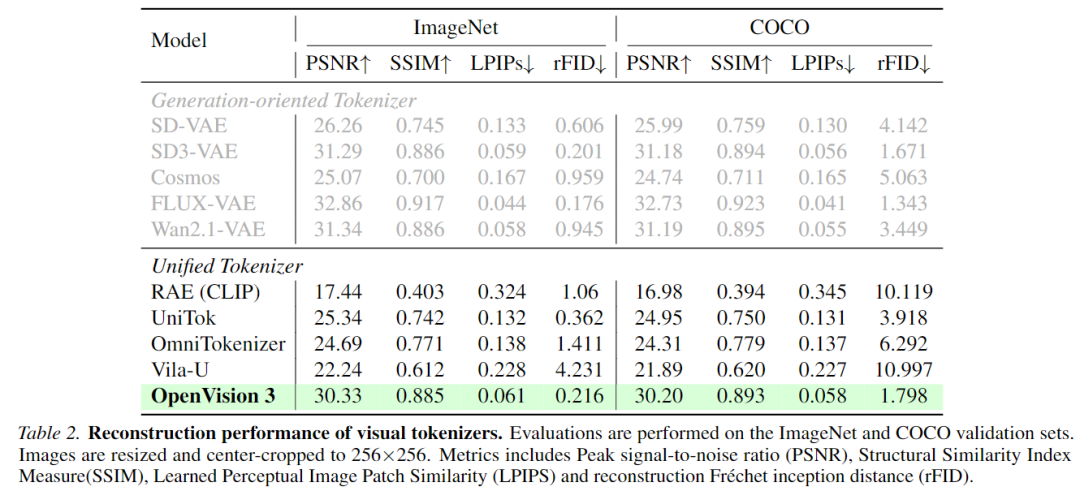
Interaction Between Understanding and Reconstruction
To investigate the mutual influence between these two objectives, ablation experiments are conducted:
Removing Reconstruction Loss: When trained solely with semantic loss, reconstruction losses (both pixel-level and latent space variable-level) still decline significantly. This indicates that the semantic objective contributes notably to image reconstruction.
Removing Understanding Loss: When trained solely with reconstruction signals, contrastive loss stagnates nearly completely, while captioning loss declines slightly. Interestingly, incorporating semantic loss improves reconstruction performance, further demonstrating a mutually beneficial synergistic relationship between the two branches.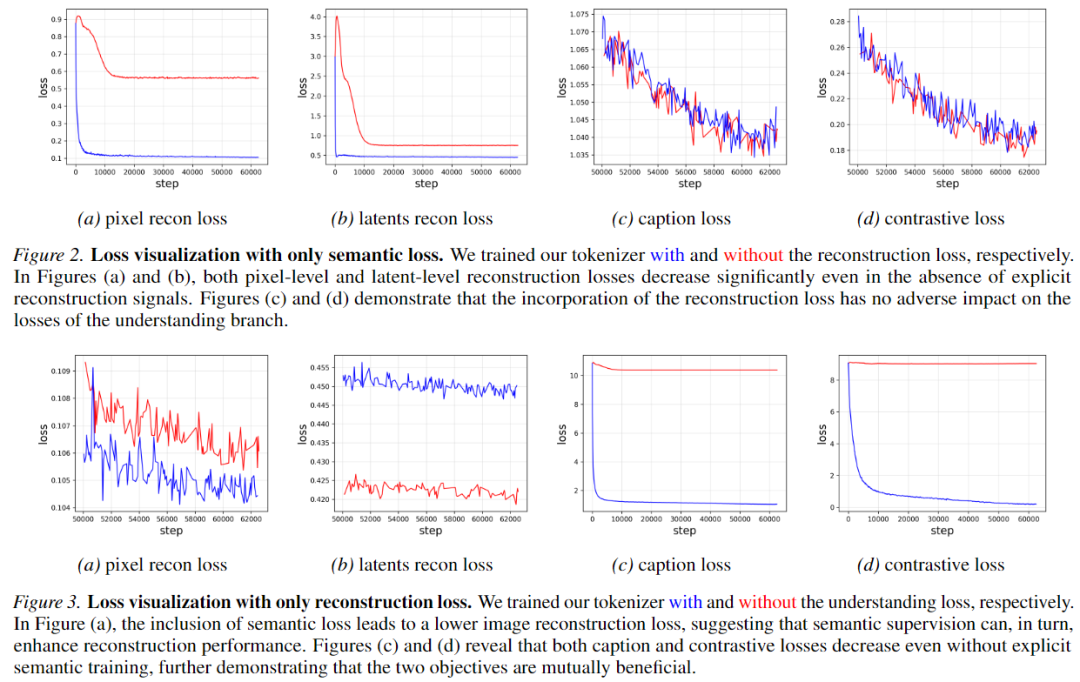
Conclusion
OpenVision 3 is a unified visual encoder for both understanding and generation. This study innovatively combines VAE with ViT to form a unified architecture, generating a single, unified representation that serves various downstream tasks. To efficiently train this tokenizer, a novel training paradigm is proposed that combines reconstruction-driven and semantics-driven signals for joint learning. Comprehensive evaluations demonstrate that the proposed model achieves exceptional results in both generation and understanding tasks through low-cost training. OpenVision 3 outperforms current unified tokenizers in reconstruction and generation and exhibits capabilities comparable to CLIP in semantic tasks.
References
[1] OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation
-
Hao Jida, Apple Supply Chain Coil Supplier, Switches Brokerage and Revives IPO Amidst Customer Dependency and Compliance Challenges
-
![]()
Annual Advertising Expenditure of VOYAH with Yudeshui: A Deep Dive
-
![]()
Can Computers, Despite Daily Price Hikes, Still Be a Viable Purchase?
-
![]()
January-June Auto Stocks' 'Resilience Ranking': Geely Alone Posts Gains, Six Plummet Over 40%, One Tumbles 54.5% | Mirror Pro
-
![]()
China’s Public Charging Market: Didi Charging, Teld, and Yunkuai Take the Lead
-
![]()
The First Year of AI-Native Mid-Year Shopping Festival: Technology Reconstructs Human-Product Matching for 618
-
![]()
Micron has released its financial report, showing revenues of $41.5 billion, a 74% increase quarter-over-quarter, with a gross margin of 84.6%. The company provided both short-term and long-term guida
-
![]()
Expert Interpretation of New Policy Combination: Activating the Trillion-Dollar Automotive Aftermarket