Delving Deep into Minimax and Zhipu: Is the Large-Scale Model Industry a Brutal Clash of Computing Power and Financial Endurance?
 01/27 2026
01/27 2026
 608
608
Nearly three years after ChatGPT's debut in early 2026, two prominent Chinese AI large-scale model startups, Minimax and Zhipu, went public almost simultaneously, each boasting a valuation of approximately $6 billion. Post-IPO, their stock prices soared, fueling a surge in the entire AI application sector. However, a closer examination of these two large-scale model companies' financial statements reveals a persistent pattern of "unending losses."
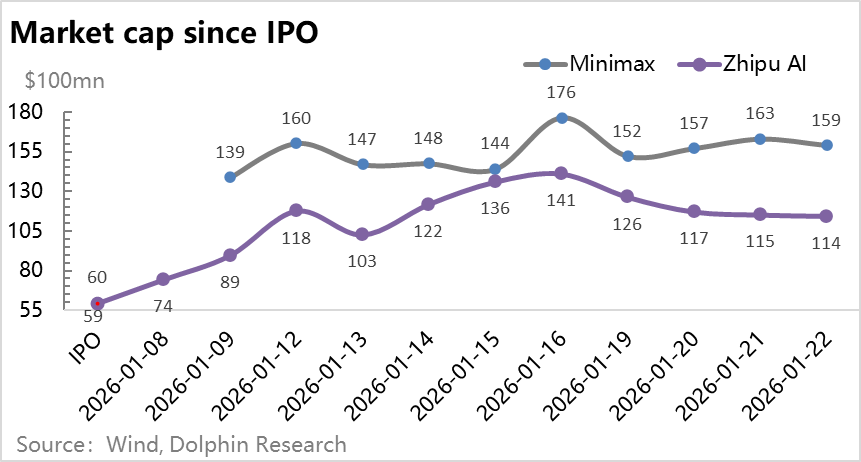
On one hand, the global market for large-scale models is witnessing a frenzy of price competition, turning these models into commodities. On the other hand, the bottomless pit of R&D investment for these models is accompanied by scenarios of soaring costs amidst the pursuit of profit. Amidst this clash of extremes, Dolphin Research has long questioned the fundamental nature of the large-scale model business.
This time, leveraging data from these two publicly listed companies, Dolphin Research aims to conduct a thorough exploration of the following questions:
1) What are the essential input factors and their required density for large-scale models?
2) What role does computing power play in this ecosystem?
3) How can the economics of model development be balanced?
4) Ultimately, what constitutes the business model for large-scale models?
Here is a detailed analysis:
I. Inflated Revenues, Alarming Investments
Both Minimax and Zhipu, the large-scale model companies, are "compact yet powerful" - featuring small teams, rapid product iterations, and swift revenue growth. By the latter half of 2025, their headcounts had not surpassed one thousand. Starting from zero revenue, both companies rapidly approached annualized revenues of $100 million within two to three years.
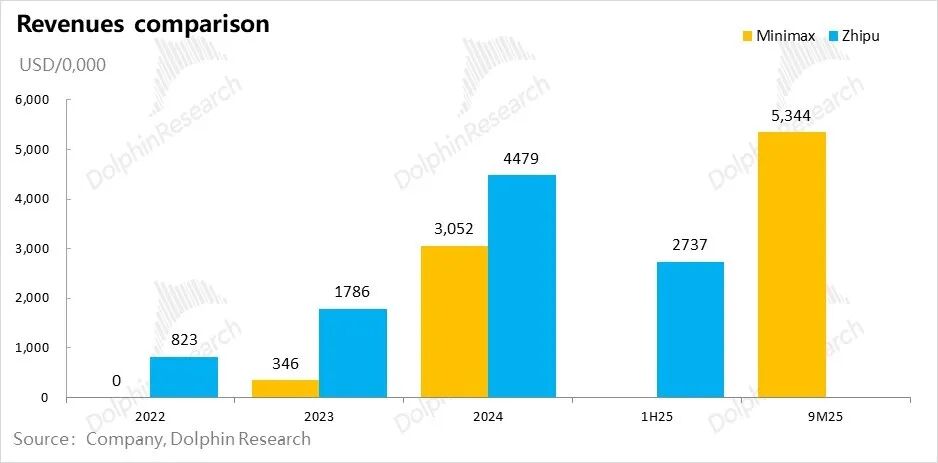
However, when it comes to expenditures, even the impressive revenue growth pales in comparison to the fierce investment levels. Despite maintaining high gross margins of 50% for the B2B-focused Zhipu and positive gross margins for the B2C-oriented Minimax during their revenue growth phases, the investment scenario tells a different story.
In 2024, the combined expenditures (costs and operating expenses) of the two companies were roughly tenfold their current revenues. After Minimax's revenue rapidly expanded in the first nine months of 2025, expenditures remained more than five times its revenue. Meanwhile, Zhipu appeared even less economically scalable in the first half of 2025.
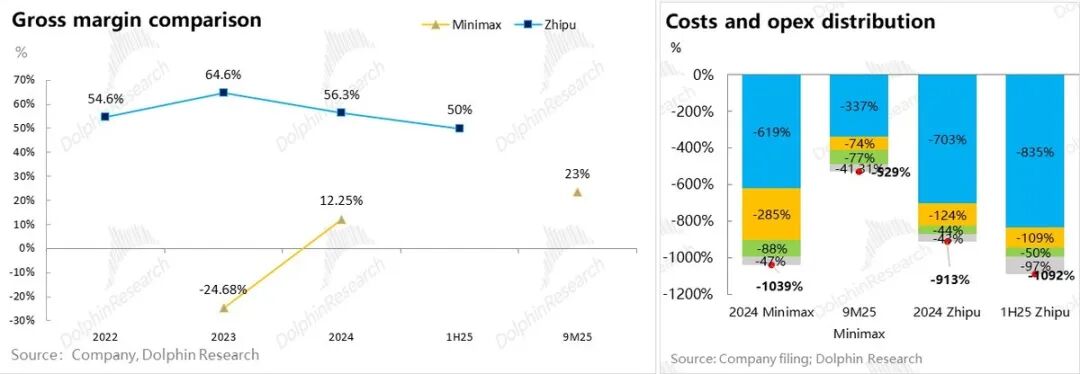
The core issue at hand is whether, for model companies, larger revenues lead to narrower loss rates or, conversely, higher loss rates due to diseconomies of scale.
The three underlying elements of model economics - data, computing power, and algorithms - are well-recognized. However, to ascertain whether models adhere to internet-style economies of scale, it is crucial to understand the input density required for large-scale models.
In the training of large language models, the specific training data utilized has never been fully disclosed by model developers. Nonetheless, there are roughly two consensus points on this matter: a. Public corpora encompass encyclopedias, code repositories, and the Common Crawl corpus; b. Public and standard corpora have nearly been exhausted for model training purposes.
By 2026, large-scale model companies have begun to rely on synthetic data and chain-of-thought data. Looking ahead, to feed models with more data, companies must either rapidly access more scenarios or possess proprietary data, akin to internet giants with significant data advantages. The remaining option is to compete in paying for private data.
However, due to data compliance and privacy concerns, no model developer would reveal data feed volumes in their financial statements. What truly appears on the statements are mainly computing power and algorithms, with algorithm advancement essentially relying on human talent and computing power corresponding to chips and cloud services. Let's examine these two issues individually.
II. Are Human Costs Exorbitant? Not the Core Issue!
Both companies boast overall headcounts not exceeding 1,000, with Minimax having fewer than 400 employees. R&D personnel constitute nearly 75% of the workforce in both companies, with a monthly cost per head ranging from RMB 65,000 to 85,000 (excluding equity incentives). Minimax's R&D personnel cost RMB 160,000 per month.
Thanks to its streamlined team, Minimax has been able to cover salary expenditures with revenue during its revenue expansion phase. In contrast, Zhipu, primarily focusing on B2B commercialization, requires more sales personnel. Moreover, its emphasis on general-purpose models in R&D has led to less noticeable improvements in human resource costs.
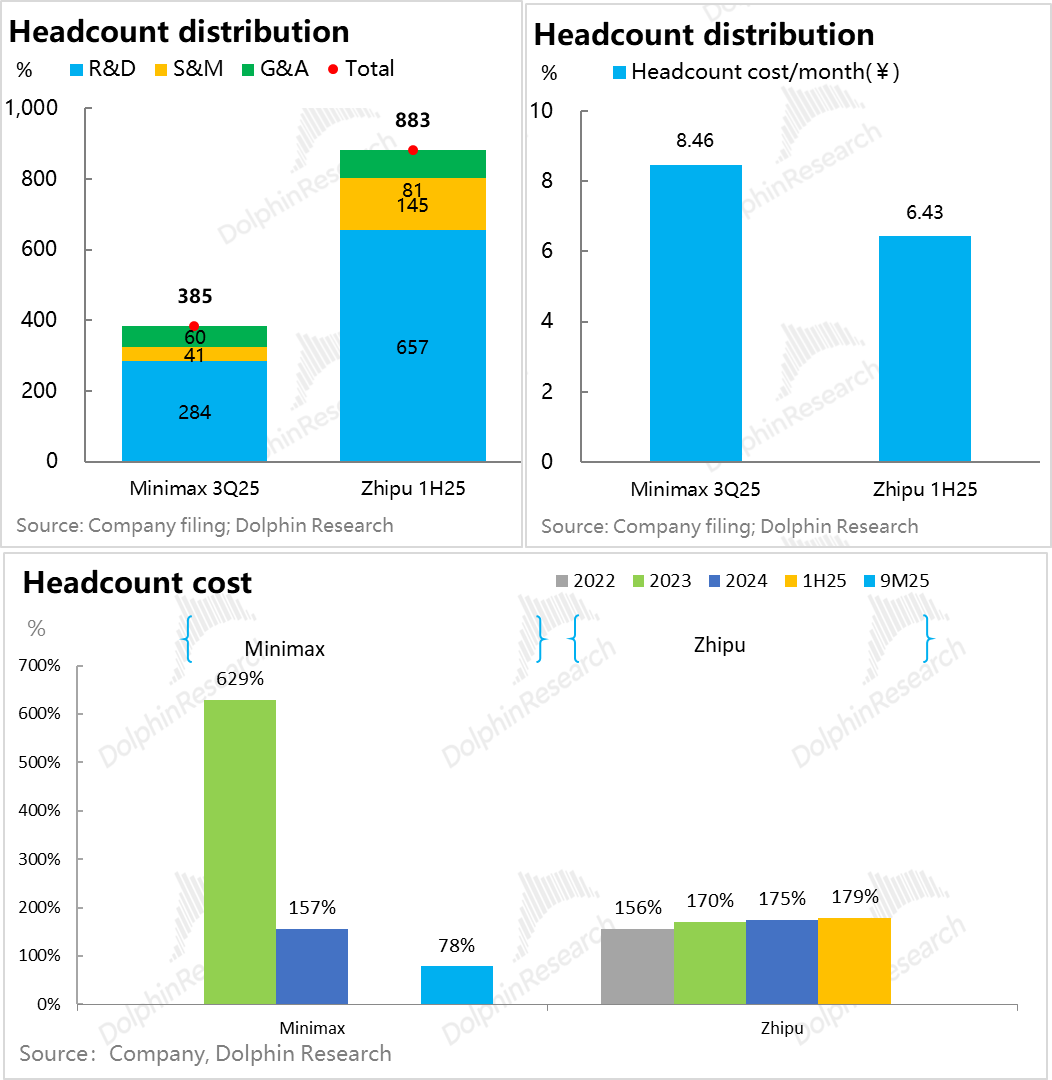
In reality, from examining these two companies, it becomes evident that large-scale model investments in human resources are more about talent "brainpower" density rather than sheer headcount. Even Minimax's talent density may foreshadow the human resource structure of internet companies in the AI era: a small number of elite large-scale model R&D talents, with a large number of other departmental roles being replaced by models (Minimax has numerous AI products but does not correspond to an excessively large headcount), resulting in overall salary expenditures showing extremely high per-capita salaries but overall controllable costs.
For instance, Minimax's total annual salary expenditure is approximately $100 million (roughly 90% of its revenue). Considering the iterative capabilities of these two companies' foundational models, the speed of multimodal releases, and the fierce competition for talent in overseas AI (with salaries for hiring a single individual often reaching hundreds of millions of dollars), such personnel expenditures are not excessive.
III. Core Conflict: Revenue Generation vs. Investment - Can Balance Be Achieved?
Although salary costs have largely "consumed" current revenues, compared to computing power investments, human salaries constitute just a small fraction. Salaries can at least be effectively diluted with revenue expansion. However, computing power investments, based on the current situations of these two companies, represent a type of investment with a steeper growth slope than revenues.
Moreover, from their financial statements, it is almost certain that both companies utilize third-party cloud services for their computing power needs due to very low fixed asset expenditures. They adopt a relatively asset-light model rather than OpenAI's highly self-controlled data center approach.
In the financial statements of large-scale model companies, computing power usage is categorized into training computing power and inference computing power.
During the model training phase, it is akin to developing a product or service capable of generating economic benefits, necessitating R&D investments. Before the product is deployed (the model enters inference scenarios), corresponding model training expenditures are "sunk costs" incurred before product launch and are recorded as R&D expenses.
Once the developed model is deployed in inference scenarios, the generated revenue is recorded as income. Meanwhile, the model's computing power consumption during the inference phase is recorded as a direct cost in the revenue generation process and is included in the cost items.
The underlying logic is straightforward: Large-scale model companies invest in human talent, computing power, and data for model R&D in laboratories, regardless of whether the model is developed for customer use. These are "sunk investments" that model companies must make.
Only when the model is developed and can be utilized in inference scenarios, whether customers call the model interface or the company directly uses the model to create apps for revenue generation, do inference revenues and inference computing costs arise.
For Minimax and Zhipu, training computing power investments alone account for more than 50% of total expenditures, representing the absolute majority of spending and a veritable "money pit," contributing to more than half of the expenditures behind their 5-10 times loss rates.
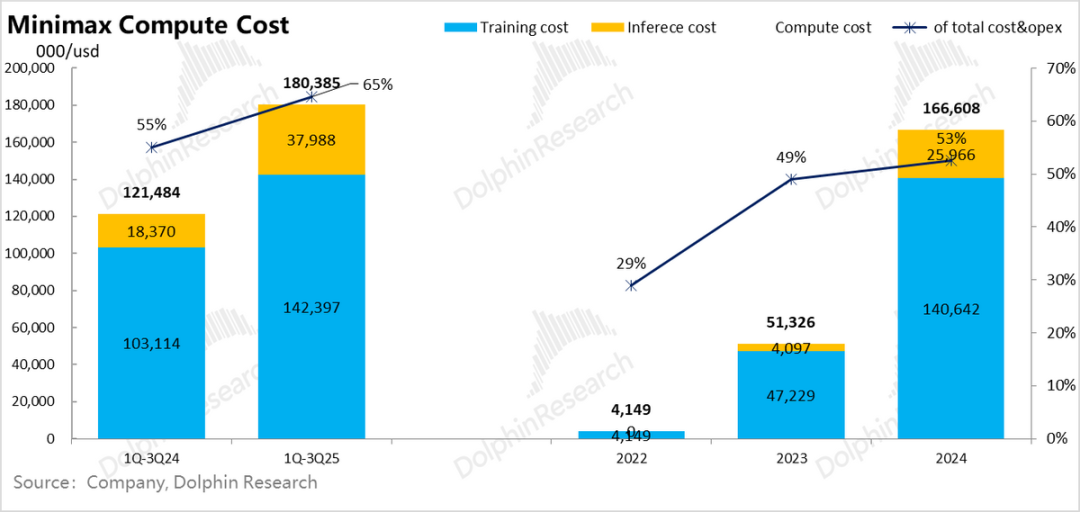
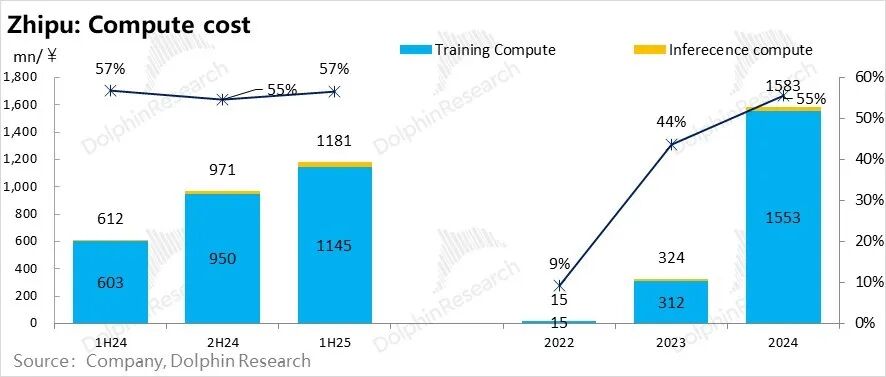
This proportion directly quantifies the claim made by Dolphin Research in "The Original Sin of the AI Bubble: Is NVIDIA an Irreplaceable 'Stimulant' for AI?" regarding computing power draining profits from the entire industry chain.
Comparing revenue generation to model training investments further intuitively reveals the intensity of training investments:
From Minimax's perspective, revenue generated in 2024 was only 65% of the model training computing power investment in 2023. Although revenue grew rapidly in the first three quarters of 2025, its ability to cover the training computing power costs in the same period of 2024 further decreased to 50%. Zhipu's coverage rate was even lower at 30% in the first half of 2025.
Due to its product deployment focusing on overseas B2C emotional AI chat, Minimax incorporates many gaming and internet value-added monetization models (detailed product and commercialization deployment will be analyzed separately). The internet-style economies of scale for B2C, coupled with strong overseas payment capabilities, result in less pressure on revenue to cover training costs.
However, Zhipu's situation clearly demonstrates high revenue growth but a weaker ability to recover training costs due to the steeper growth slope of training costs.
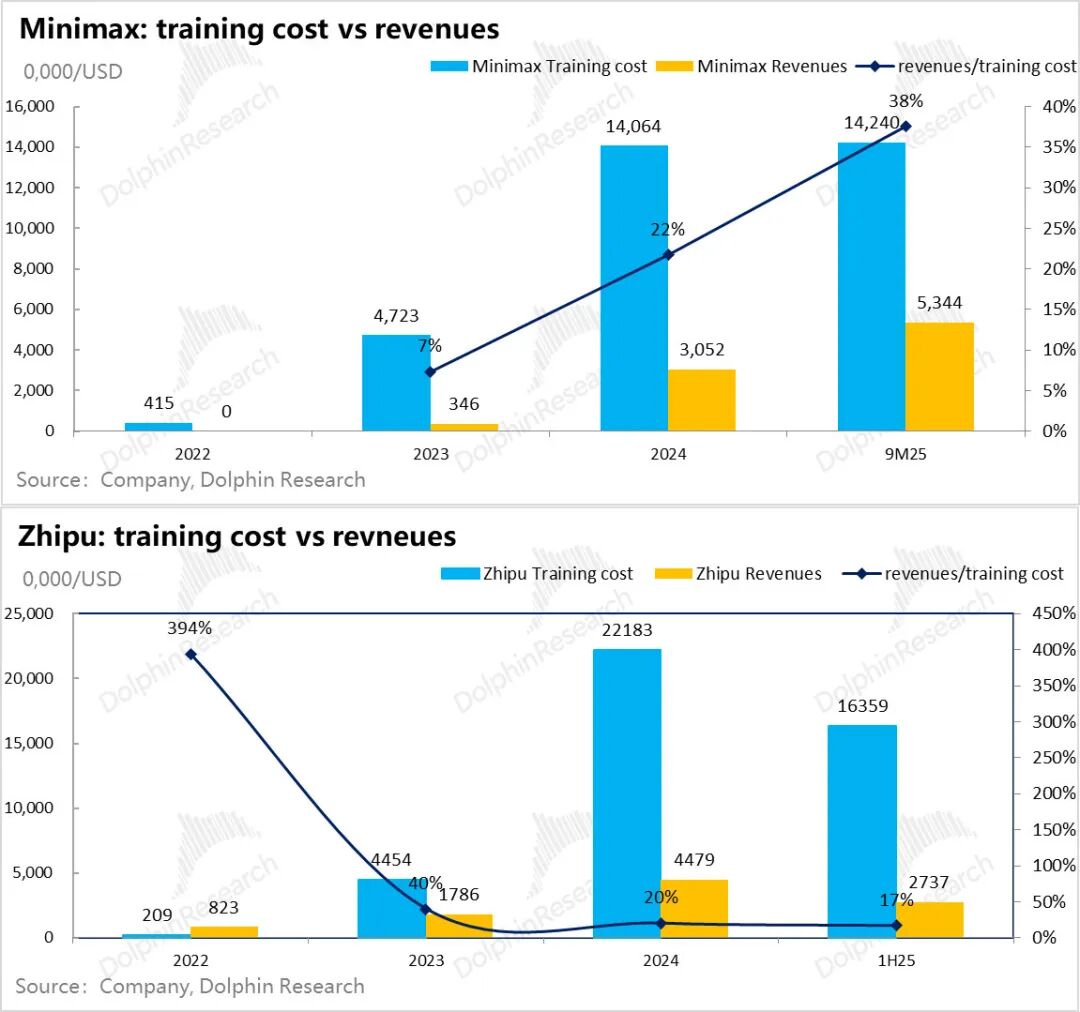
Over the past two years, although both companies, as leading independent model companies in China, have exhibited high revenue growth slopes, the compensation for current revenue to cover previous year's R&D investments has been unsatisfactory.
For a model to excel, training costs are higher; no matter how fast revenue grows, it cannot keep pace with escalating model investments. Then, the contradiction arises: the more models are developed, the greater the losses. How can the commercial value of such a business be understood?
IV. What Constitutes the Business Model of Large-Scale Models?
The staggering 1000% loss rates of large-scale models vividly illustrate that their R&D represents a business model that is triple-intensive in talent, computing power, and data.
The resonance of strong investments and rapid iterations, in Dolphin Research's view, essentially transforms a capital-intensive business with a robust balance sheet into one that "fully resides" on the income statement.
When it possesses long-term economic and commercial value, the model reverts to a true "balance sheet" business - where models no longer require annual investments, but a year's training cost can sustain revenue generation for the next 10 or even 20 years. Only at this point can training costs be amortized over the long term, providing a true commercial basis for R&D capitalization of model training costs. Specifically:
1) Computing Power: Ever-Increasing "Fixed Asset Investments"
Taking Minimax and Zhipu as examples, training a model in 2023 cost between $40 million and $50 million. However, to achieve linear generational differences in the next model, data volume, model parameter count, and computing power investments must increase exponentially. Ultimately, improved computing power efficiency, paradoxically, raises the total demand for computing power.
From these two companies, it can be seen that upgrading a model generation typically increases training costs by 3-5 times.
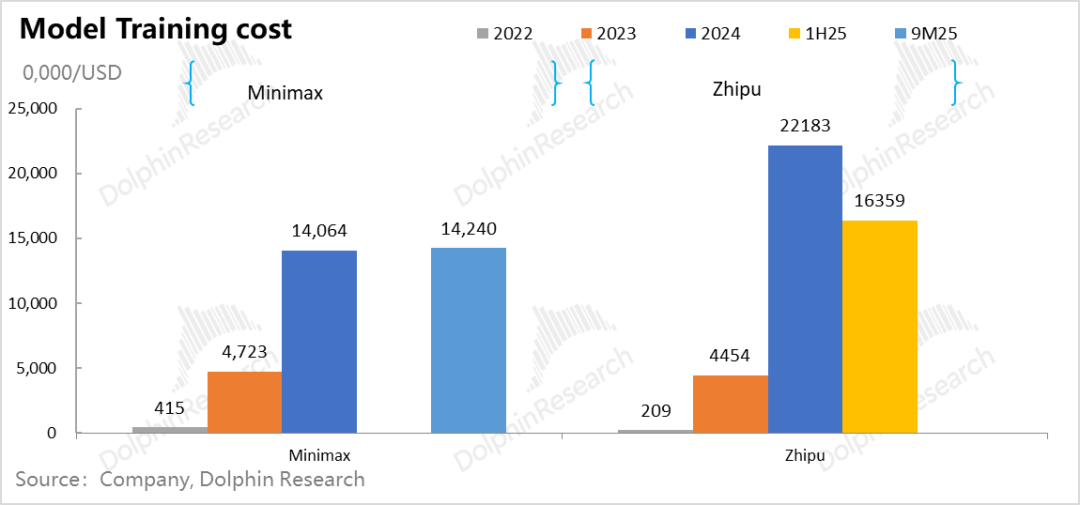
The current competitive pace of large-scale models typically sees a new model generation released annually. In other words, a model trained in the previous year only corresponds to a one-year revenue generation period from inference in the following year.
Such high computing power investments cannot be amortized or depreciated and must be fully recorded as current R&D expenses, resulting in the "dismal" loss rates mentioned earlier, with losses 5-10 times higher than revenues.
2) Rapid Iterations: Revenue vs. Investment - A "Cat and Mouse Game" That Can't Keep Up?
Both Zhipu and Minimax face the common situation where their models' revenue generation capabilities cannot cover their computing power investments. Although revenue growth cannot keep pace with training costs, the inevitable fate of R&D for large-scale models is to incur heavy losses while heavily investing.
To survive until the dawn, companies must almost certainly rely on financing funds that are 3-5 times higher than their revenues, considering this generation's model revenue and R&D salary expenditures, to continue funding the next model generation and prevent market obsolescence.
Continuing this snowball effect leads to a situation where revenue consistently lags behind future investments. As long as a company remains in the large-scale model competition, it must continuously seek financing, with the financing gap widening as the company grows - a "capital race" game.
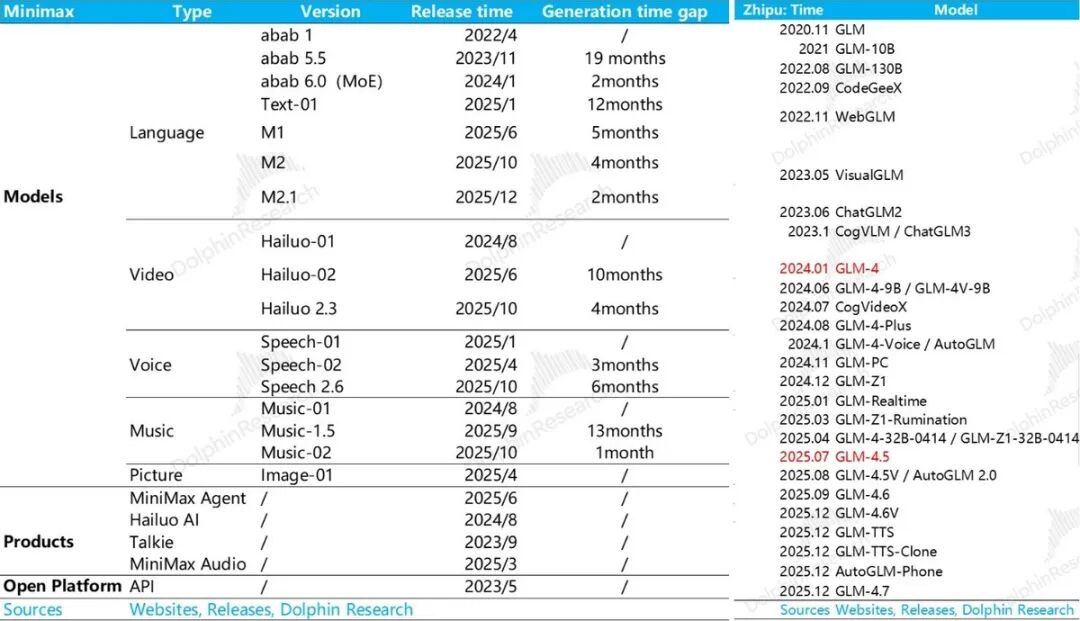
3) Scaling Law Failure: The End of the Capital Game?
A natural question arises: When will this end? Clearly, with significant cost-side investments, the core conflict is not simply whether revenue growth can match training cost growth but, more importantly, when models will no longer require such massive investments or such rapid iteration speeds.
For large-scale model technology itself, the time when investments are no longer required is when the scaling law fails. In other words, when the computing power required to increase a small amount of intelligence begins to surge exponentially, the necessity for model training diminishes.
When models no longer necessitate frequent training iterations, it signals the cessation of high-density training capital investments. After making an investment in a new model generation, this particular generation can yield revenue for a decade or even longer. Even when models no longer require training investments but can continuously bring in profits, a business model akin to that of 'Yangtze Power' comes into being.
However, the foundational assumption here is that leading large model manufacturers have outlasted a multitude of competitors in the protracted battle involving capital, manpower, and data consumption. The few remaining competitors have reached a tacit understanding to halt price wars, ultimately creating an oligopoly market with a highly concentrated market share, similar to the current cloud services market. Under such circumstances, the business model for large models would naturally become feasible.
4) The Brutal Capital Game Before the Final Showdown
Before the moment when the scaling laws lose their effectiveness arrives, large model companies will continue to be insatiable consumers of capital. In such a scenario, the competition over business models essentially transforms into an unrelenting capital race for continuous financing.
Certainly, if a large model company can, like NIO, turn financing into a distinctive survival skill, that would indeed constitute a core competency. However, for the majority of companies, financing is not about deceiving others. The willingness of capital to invest inherently hinges on a company's product and execution capabilities. Successfully raising funds with increasing valuations is itself a process of mutual selection.
According to media reports, China's model war has evolved from an initial clash involving hundreds of players to a current showdown among five leading foundational models: ByteDance, Alibaba, StepFunction, Zhipu, and DeepSeek.
Among the original 'Six Little Dragons' of model startups—StepFunction, Zhipu, MiniMax, Baichuan Intelligence, Moonshot AI, and 01.AI—the latter two have lagged behind after DeepSeek's overnight rise to fame and its complete disruption of model pricing through open-source alternatives.
Overseas, the landscape has similarly consolidated into a five-way rivalry: OpenAI, Anthropic, Google Gemini, xAI, and Meta Llama. Even Meta's model has fallen behind the pack.
Some companies have managed to sustain continuous financing with rising valuations, while others have rapidly collapsed along the way. From the perspective of large model survival, financing capability is ultimately the result of the combined effects of core talent, model strength, and product implementation progress.
Core talent remains the focal point of a billion-dollar talent war in the AI field, which shows no signs of abating. The other two critical factors are the model's intelligence level and its eventual ability to generate revenue.
1) Model Strength:
As can be seen below, surviving model startups generally rank prominently on model leaderboards. This reflects their competitive edge across various detailed metrics (such as model intelligence, hallucination rate, model parameters, and the waiting time before the first token output in responses).
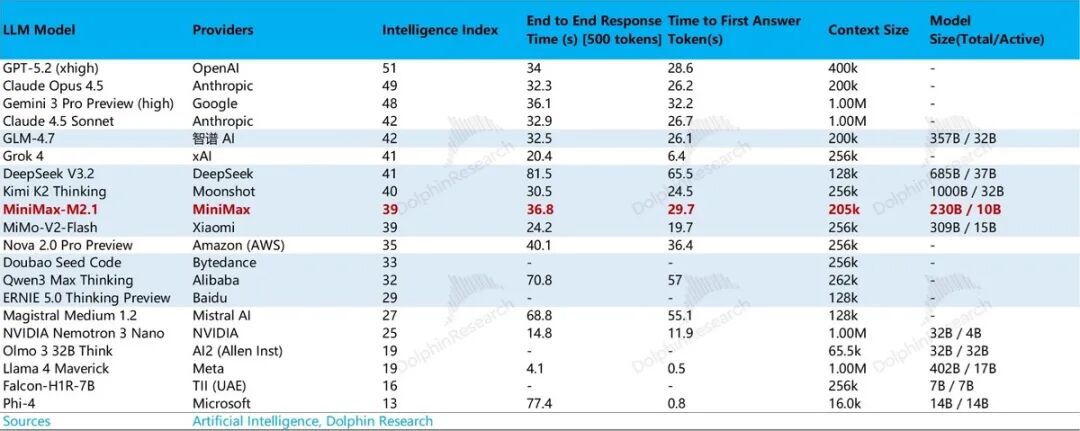
2) Product Implementation Capability
Over the past year, most independent startups have either lost talent to internet giants, struggled to generate revenue from product implementations, or been outcompeted by cost-effective open-source models in pricing battles, leading them to fade into obscurity.

In summary, before and even for some time after the 'dawn' when the Scaling Law reaches its limits, we will witness models collapsing in the three-dimensional competition of talent acquisition, model development, and product implementation.
Those truly capable of reaching the finals will depend not only on talent and financial strength but also, more critically, on the progress of model development and the level of product implementation.
In the next analysis, Dolphin Research will examine Zhipu and MiniMax's model and product implementations to understand how to evaluate the capital market value of large models.
- END -
// Reprint Authorization
This article is an original work by Dolphin Research. Reproduction requires authorization.
// Disclaimer and General Disclosure
This report is intended solely for general comprehensive data reference, catering to users of Dolphin Research and its affiliated institutions for general reading and data consultation. It does not take into account the specific investment objectives, product preferences, risk tolerance, financial situation, or special needs of any individual receiving this report. Investors must consult with independent professional advisors before making investment decisions based on this report. Any person using or referring to the content or information in this report for investment decisions assumes full risk. Dolphin Research shall not be liable for any direct or indirect responsibilities or losses arising from the use of data contained in this report. The information and data in this report are based on publicly available sources and are provided for reference purposes only. Dolphin Research strives for, but does not guarantee, the reliability, accuracy, and completeness of the information and data.
The information or views mentioned in this report shall not, under any jurisdiction, be construed or regarded as an offer to sell securities or an invitation to buy or sell securities, nor shall they constitute advice, inquiries, or recommendations regarding relevant securities or related financial instruments. The information, tools, and data in this report are not intended for, nor are they intended to be distributed to, jurisdictions where the distribution, publication, provision, or use of such information, tools, and data conflicts with applicable laws or regulations, or where Dolphin Research and/or its subsidiaries or affiliates are required to comply with any registration or licensing requirements in such jurisdictions for citizens or residents thereof.
This report solely reflects the personal views, insights, and analytical methods of the relevant authors and does not represent the stance of Dolphin Research and/or its affiliated institutions.
This report is produced by Dolphin Research, with copyright solely owned by Dolphin Research. Without prior written consent from Dolphin Research, no institution or individual may (i) produce, copy, replicate, duplicate, forward, or create any form of reproduction or replica in any manner; and/or (ii) directly or indirectly redistribute or transfer to other unauthorized persons. Dolphin Research reserves all related rights.
-
Hao Jida, Apple Supply Chain Coil Supplier, Switches Brokerage and Revives IPO Amidst Customer Dependency and Compliance Challenges
-
![]()
Annual Advertising Expenditure of VOYAH with Yudeshui: A Deep Dive
-
![]()
Can Computers, Despite Daily Price Hikes, Still Be a Viable Purchase?
-
![]()
January-June Auto Stocks' 'Resilience Ranking': Geely Alone Posts Gains, Six Plummet Over 40%, One Tumbles 54.5% | Mirror Pro
-
![]()
China’s Public Charging Market: Didi Charging, Teld, and Yunkuai Take the Lead
-
![]()
The First Year of AI-Native Mid-Year Shopping Festival: Technology Reconstructs Human-Product Matching for 618
-
![]()
Micron has released its financial report, showing revenues of $41.5 billion, a 74% increase quarter-over-quarter, with a gross margin of 84.6%. The company provided both short-term and long-term guida
-
![]()
Expert Interpretation of New Policy Combination: Activating the Trillion-Dollar Automotive Aftermarket