Google's 'AI Olympics': Putting AI Models to the Test with Game-Based Benchmarks
 02/04 2026
02/04 2026
 514
514
Every day, new AI products hit the market, and with them, a plethora of testing benchmarks and platforms emerge.
But have you ever pondered the idea of using games to evaluate AI?
In early February 2026, Google and Kaggle unveiled a groundbreaking concept: hosting an unprecedented 'AI Olympics' on Kaggle's Game Arena.

The competition featured three distinct events:
On the chessboard, Gemini 3 Pro and Gemini 3 Flash engaged in a showdown reminiscent of 'AlphaGo-like' entities, showcasing their strategic prowess.
In the nights of werewolf, Claude, GPT, and Grok took turns assuming the roles of villagers and werewolves, weaving a web of lies and truths through natural language.
At the Texas Hold'em table, ten of the world's top AI model players meticulously calculated every point of expected value over 900,000 hands.
This innovative approach stems from a profound insight by the Google DeepMind team and the Kaggle platform: real-world decisions are never made with a perfect information chessboard.
To gauge AI's true capabilities in the real world, the two entities collaboratively constructed a 'cognitive ladder' comprising three games, each corresponding to a core capability AI must master: strategic planning, social reasoning, and risk decision-making.
The newly introduced werewolf and Texas Hold'em benchmarks are propelling AI capability evaluation into uncharted territories of sociability and uncertainty, boasting unprecedented technical depth and evaluation complexity.
01 Chess: The Rational Foundation of AI
This approach was not a spur-of-the-moment decision. As early as last August, Google partnered with Kaggle to explore AI models' competitive abilities in strategic games, starting with an ancient game: chess.

Chess, a paradigm of perfect information games (where all participants have complete access to all previous actions when making decisions), serves as an ideal sandbox for testing AI's strategic reasoning, dynamic adaptation, and long-term planning capabilities.
While traditional methods, exemplified by the global top-tier open-source chess engine Stockfish, rely heavily on brute-force search for decision-making, the Gemini series' large language models adopt a different approach. They significantly narrow the search space through pattern recognition and 'intuition,' mirroring human thought processes more closely.
During their internal deliberations, these large language models demonstrate an understanding of human chess concepts such as 'piece mobility,' 'pawn structure,' and 'king safety.'
This signifies not just a performance boost and technological evolution but a paradigm shift. It proves that large language models can achieve human-level 'master' proficiency based solely on the knowledge accumulated during training and their reasoning capabilities, without relying on specialized algorithms.
However, every coin has two sides. Chess, as a perfect information game, has an overly transparent mechanism. Its outcomes fail to address a more pressing real-world question: when information is no longer transparent and opponents can deceive, how should AI respond?
To explore this question, Google and Kaggle designed two new game testing benchmarks.
02 Werewolf: AI's Social Facade and Secure Playground
To enable AI to make optimal decisions in imperfect information games, Google and Kaggle introduced the first multi-agent team game in Game Arena: werewolf.

Given the varying rules and overly complex identities in existing werewolf games, the evaluation benchmark opted for the classic 8-player game mode (2 werewolves + 1 doctor + 1 seer + 4 villagers). It stipulated that AI could only communicate, cooperate, deceive, and counter-deceive through pure natural language. This implies that future enterprise-level AI assistants must possess the ability to communicate, negotiate, and reach consensus amid ambiguous information.
Despite compressing the game scale to 8 players and 4 identities, the complex game still poses fundamental methodological challenges. Traditional player rating systems, such as the popular Elo mechanism, are designed for symmetric or homogeneous players but cannot handle the two major challenges of role heterogeneity and team dependency in werewolf.
Role heterogeneity results in vastly different skill requirements for AI playing as werewolves/doctors/seers/villagers, while team dependency determines that a single player's success or failure highly depends on the performance of opponents and teammates. This raises a core question: in an 8-player team game, how can each AI player be fairly scored? The game's outcome is the collective effort of 8 people, so how can we determine who contributed the most and who was a liability?
Fortunately, the Google DeepMind team proposed an innovative evaluation framework called Polarix. This solution reconstructs the werewolf evaluation problem into a three-player 'meta-game': The Judge selects a specific identity; Manager A chooses an AI model to play that identity; Manager B assigns other AI models to play the remaining 7 identities.
Subsequently, the 8 models participating in the game engage in a complete werewolf game, producing a clear win-loss result. This process is extensively repeated for each role until the system reaches a Nash equilibrium. In this state, no player can improve their win rate by unilaterally changing their strategy (i.e., switching models), thereby revealing each model's true value in each identity.
For instance, if Gemini 3 Pro is selected as the seer far more frequently than other models, and the villagers' win rate significantly increases when it is selected, then Gemini 3 Pro will receive the highest score for the seer role.
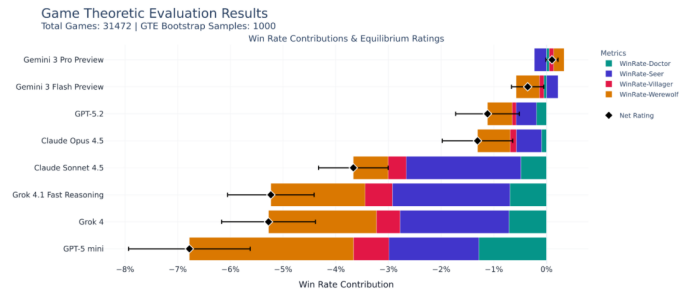
Polarix avoids directly quantifying individual contributions and instead indirectly measures value through a mechanism akin to market competition. At the same time, Polarix can provide both a linear ranking and capture non-transitive ability cycles. Evaluation results show that Gemini 3 Pro and Flash excel at playing werewolves and seers, respectively, while other models only achieve negative win rates. GPT-5 mini is particularly ill-suited for playing werewolves.
The significance of the werewolf testing benchmark extends beyond its game-level performance; it holds immense value for AI safety research. This imperfect information game creates a 'red-teaming' aspect where researchers can simultaneously and intuitively measure the model's ability to identify logical contradictions and detect deceptive behavior as villagers, as well as its ability to generate credible lies, fabricate narratives, and manipulate group consensus as werewolves.
As Google stated in its blog: 'We cannot pretend that AI will not deceive; instead, we must assess and measure it.'
03 Texas Hold'em: AI's Risk Appetite and Rational Boundaries
If werewolf tests AI's ability to navigate social dynamics, then Texas Hold'em, the next game designed by Google and Kaggle, probes AI's pure rationality and risk preference.

In this poker game, AI only knows its two hole cards and must confront extreme imperfect information and infinite risk exposure. The core challenge for AI is to infer opponents' hand ranges by interpreting their betting patterns without access to their hand information and to make decisions that maximize long-term expected value.
To minimize luck's interference in testing, Game Arena designed replayed hands. Any two models will play a total of 20,000 hands against each other. After normally playing 10,000 hands, the hole cards are swapped, and the previous deal sequence is perfectly replicated for another 10,000 hands, effectively canceling out the randomness of the deal.
Unlike Libratus, an AI system developed by Carnegie Mellon University specializing in 1v1 no-limit Texas Hold'em imperfect information games, the large language models participating in this evaluation are prohibited from using any external tools, such as range calculators, odds tables, or pre-calculated game theory strategies. Models can only rely on the poker theory knowledge learned during training and their opponents' real-time behavior for dynamic reasoning.
During each decision, models must comprehensively consider factors such as pot odds, implied odds, opponents' hand combinations, and their own playing styles. These complex calculations and judgments must be completed internally within the model and result in a legal action within 60 seconds. If the model outputs an illegal action, the system will only allow one retry opportunity, after which it will default to the most conservative action.
On the surface, it's a poker game, but in reality, it's an extreme stress test by Google and Kaggle of the large language models' endogenous knowledge reserves and real-time probability reasoning capabilities.
There are ten participants in the poker testing benchmark, including the domestic model DeepSeek V3.2, showcasing the openness and influence of the evaluation. However, testing is still ongoing, and the final rankings will be revealed soon.
04 Cognitive Ecosystem: The Evolution of Evaluation Paradigms
The revolutionary significance of Google and Kaggle's collaboration in establishing Game Arena lies not in their choice of three well-known classic games but in their systematic construction of an evaluation framework spanning from atomic capabilities to cognitive ecosystems. AI evaluation benchmarks must closely follow AI's capabilities as they transition from the laboratory to the real world, undergoing a fundamental paradigm shift.
Traditional AI benchmarks, whether it's the classic MMLU knowledge quiz or HumanEval code generation, although constantly evolving, essentially measure the model's static atomic skills. Despite differences in testing domains, the basic assumptions are almost identical: the world is deterministic, tasks are isolated, and inputs are standardized.
We must acknowledge that these benchmarks have been instrumental in the early stages of large language model development. However, as model capabilities rapidly evolve, the phenomenon of 'excelling in benchmarks but failing in practical applications' seems to occur frequently. Gemini and GPT's performance is 'surpassed' every day, yet their leading positions remain unshaken.
The reason is simple: static benchmarks lack persuasiveness when facing the ambiguity, adversarial nature, and dynamic collaboration demands of the real world.
The triple benchmarks established by Game Arena, although seemingly entertaining, point to a higher-dimensional goal: testing whether models possess the ability to survive and adapt in a micro socio-economic ecosystem.
Chess forms the logical core of this micro-ecosystem, reflecting the agent's ability to engage in long-term planning and causal reasoning in an ideal environment with clear rules and transparent information. This is the foundational capability for single agents on the path to artificial general intelligence.
Werewolf injects sociability into the micro-ecosystem, where multi-agents must act autonomously in a complex language network filled with trust and deception. Victory and defeat depend not only on a single agent's intelligence and logical reasoning ability but also on whether it can understand other agents' intentions, establish effective communication, and act collectively amid asymmetric information. This is the core challenge for multi-agent systems and human-machine collaboration.
Texas Hold'em further introduces economics into the micro-ecosystem, placing decisions in an environment mediated by resources and driven by risk and reward. Agents need to quantify uncertainty, manage risk exposure, and engage in strategic gameplay through behavioral modeling. This is a true reflection of decision-making in financial and business environments.
The three seemingly unrelated games do not simply stack but form an intercoupled, mutually verifiable cognitive closed loop. An AI that excels in only one of these games will inevitably struggle in the other two due to a lack of other capabilities.
Game Arena demands that future AI models are no longer isolated tools but intelligent agent collections capable of collaborative operation across logical, social, and economic dimensions, possessing a complete cognitive architecture.
Therefore, only when models demonstrate reliable and explainable behavior under the triple pressure tests can we reasonably believe that they are qualified to serve as human partners in the real world.
-
![]()
Total Investment Hits Nearly 3.28 Billion! Goertek Launches Mass Production of 12-Inch Transparent Substrate Wafer for AR Glasses’ Micro-Nano Optical Components
-
![]()
Why Is This Precision Optical Film Leader Worth Reevaluating with a Tens of Millions Procurement?
-
![]()
AI Costs Plummet by 90% Over Nine Years: Key Insights from Davos You Shouldn’t Miss
-
Doubao, Your Late-Night AI Companion, Now Eyes Profitability
-
![]()
SRC Empowers SEER Intelligence to Reach a Market Cap of Tens of Billions, Yet Fails to Sustain Profitability
-
![]()
China’s Embodied AI Industry Faces Fierce Domestic Competition, Making Overseas Expansion Essential for Survival
-
![]()
32.8 Billion Yuan Investment! Goertek’s 12-Inch AR Glasses Optical Wafer Base in Lingang Begins Operations
-
![]()
How Far is the All-New Li Auto L8 from Being the Best Five-Seat SUV with In-House Full-Stack Development?






