CVPR 2026 | 'All-Powerful AI Poster Designer' PosterOmni Goes Open Source: Excelling in Six Major Tasks within the Open-Source Community, Rivaling Closed-Source Commercial Solutions
 02/26 2026
02/26 2026
 497
497
Interpretation: The Future of AI-Generated Design
Many AI poster generation tools start from a single prompt (Text-to-Poster) by default. However, in real-world design workflows, it is more common to begin with a reference image/old poster/main product visual: You aim to retain key subjects while performing operations such as image expansion, completion, aspect ratio adjustment, style change, and layout change, ultimately achieving a result that 'more closely resembles a finished poster.'
The core idea behind PosterOmni is:
one model for generalized multi-task image/poster-to-poster generation
Using a single open-source model, it uniformly covers common design-side requirements: capable of both fine editing and high-level style and layout recreation.
Many traditional solutions resemble a combination of 'a set of photo editing tools + a set of generation tools,' which can work but are often disjointed;
PosterOmni functions more like a 'design assistant starting from a reference draft': You provide it with a reference image, and it can perform both detailed refinements and reconstructions based on style/layout intentions.
Key Highlights
1) Unified 'Image-to-Poster' Paradigm: One Model Covering Six Typical Design Tasks
PosterOmni does not split poster capabilities into multiple models/plugins. Instead, it systematizes typical image/poster-to-poster requirements into six task categories and unifies them within a single model:
Local Editing (Refinement): Extend (image expansion), Fill (completion), Rescale (aspect ratio adjustment), Identity-driven (ID preservation)
Global Creation (Redesign): Style-driven (style reference), Layout-driven (layout reference)
The focus is not on the 'task list' but on how they collectively correspond to a real-world workflow:
Given a reference image/old poster → Perform edits/rearrangements/style changes/layout changes as needed → Output a new poster.

2) 'Data-Distillation-Reward' Closed Loop: Enabling One Model to Balance Refinement and Creation While Reducing Multi-Task Interference
One of the most challenging issues in multi-task learning is interference: Local editing emphasizes pixel-level consistency and natural subject preservation; global creation emphasizes abstract overall style and layout structure recreation. Directly training them together often results in a model that 'does a bit of everything but lacks stability.'
PosterOmni's training approach is more restrained:
First, train local editing experts and global creation experts separately.
Then, use task distillation to fuse their capabilities into a single student model (PosterOmni-SFT).
Finally, introduce unified rewards and reinforcement learning to align both 'aesthetic preferences' and 'editing precision/instruction adherence.'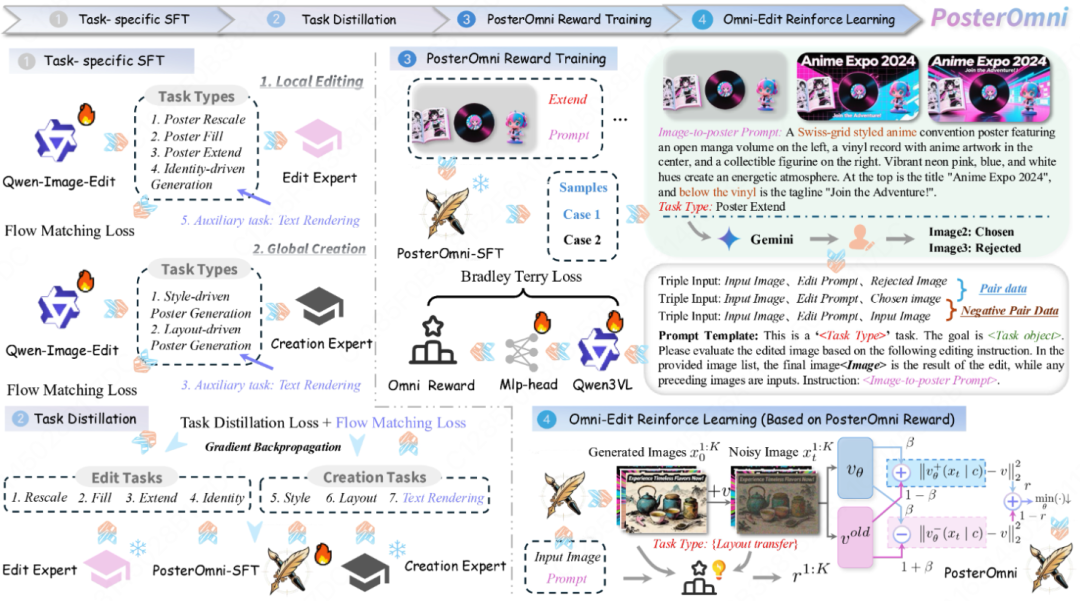
3) PosterOmni-Bench: Clarifying 'Common Design-Side Requirements' with a Unified Benchmark
We established a multi-task benchmark, PosterOmni-Bench (1020 test prompts in both Chinese and English, covering six tasks), and conducted systematic evaluations. The results show that PosterOmni performs more consistently across all six task categories, particularly excelling in high-level understanding tasks like layout transfer/style transfer. It also demonstrates greater stability in local tasks such as aspect ratio adjustment/ID preservation. Under fair evaluation and scoring methods, its overall performance surpasses some advanced commercial systems and closely approaches the most cutting-edge commercial models.
Overview: What 'Common Design-Side Requirements' Can PosterOmni Address?
The 'Dual Challenges' of Real-World Workflows: Proportions need adjustment, layouts need modification; styles need emulation, content must not be copied; subjects must remain stable, details must appear natural.
PosterOmni focuses not on 'generating a visually appealing image' but on addressing a combination of design-side requirements.
For example:
Rescale (aspect ratio adjustment): Not simply cropping/stretching, but more akin to 'the aspect ratio changes, and the layout rearranges accordingly.' For instance, converting a vertical event poster into a square social media cover requires adjusting title hierarchy, white space, and element spacing while ensuring the subject remains stable.
Style-driven (style reference): While preserving user prompt requirements, it aims to learn abstract stylistic elements such as 'color schemes/textures/lighting/font aesthetics' rather than directly copying specific elements from the reference image (a phenomenon some existing commercial models exhibit as 'collage-style copying' in certain scenarios).
Layout-driven (layout reference): While preserving user prompt requirements, it reuses structural logic (visual focus, information zoning, hierarchical relationships) rather than rigidly applying templates, which can result in awkward assemblies.
PosterOmni incorporates both 'refinement' and 'redesign' within a single image/poster-to-poster engine, enabling common design operations to be completed within one model.
Methodology
PosterOmni's core objective is to unify the common real-world design scenario of 'one reference image + one instruction' into one model for generalized multi-task image/poster-to-poster generation: capable of both local refinement (e.g., image expansion, completion, scaling, ID preservation) and global creation (layout transfer, style transfer), achieving both 'accurate modifications' and 'visually appealing results' within the same model.
To enable a single model to possess both capabilities simultaneously, we designed a complete SFT training pipeline of data-expert-distillation, culminating in Omni-Edit reinforcement learning to align both 'aesthetics' and 'task completion' while avoiding common multi-task interference.
Phase 1: Automated Data Construction and PosterOmni-200K
High-quality, multi-task, controllable paired data forms the foundation of a unified model. PosterOmni first generates PosterOmni-200K using a fully automated synthesis pipeline and simultaneously constructs the evaluation set PosterOmni-Bench. The entire data construction process forms a closed loop: 'creative prompt generation—candidate image generation—multimodal filtering—task-specific pairing.' It first generates prompts and base images with authentic poster contexts, applies strict screening, and finally generates input-output pairs according to tasks, which are then filtered to form training and evaluation data suites.

(1) Prompt and Base Image Generation (Resembling 'Real Design Briefs')
Instead of using simple captions, PosterOmni combines 'subject/category + scene + style tags' and has VLMs (such as GPT, Qwen3) write them into structured prompts with typographic and aesthetic constraints (e.g., title/subtitle/position, overall style intentions). It then renders multiple candidate images using powerful T2I generators (such as Qwen-Image) and preemptively eliminates samples lacking subjects, with text corruption, or layout collapse.
The significance of this step is to ensure all subsequent tasks revolve around 'authentic design-side requirements' rather than just general image editing.

(2) Multimodal Filtering (Ensuring 'Trainability and Evaluability')
The biggest issue with synthetic data is not scale but noise. We implemented hierarchical filtering:
Training set: Uses PaddleOCR for text readability/keyword consistency checks, then Jina-clip-v2 for image-text consistency, removing samples with typos, incorrect languages, semantic errors, or unreasonable layouts.
Evaluation set: In addition to OCR, introduces Gemini-2.5-Flash to judge 'task suitability' (e.g., layout transfer tasks must have parsable layout structures), ensuring benchmark comparability and reliability. Meanwhile, SAM-2 is used for segmentation/region generation, providing mask-level supervision signals for subsequent tasks like 'filling/image expansion.'
(3) Paired Construction for Six Task Categories (Translating Common Design Requirements into Data)
Based on the filtered 'text→poster' base corpus, we generate image/poster-to-poster training pairs according to six task categories: Extending/Filling/Rescaling/ID-driven/Layout-driven/Style-driven, corresponding to real-world needs such as spatial completion, aspect ratio rearrangement, subject consistency, layout reuse, and style transfer. Subsequently, VLM/manual filtering ensures quality for each task.
In implementation, each task uses a modular data constructor:
extending/filling uses SAM2 to generate local regions or missing masks;
rescaling uses BrushNet-like/closed-source methods to construct supervision pairs for 'aspect ratio change→content rearrangement';
ID-driven uses PaddleDet to extract subjects and combines them with strong editors to form 'ID-preserving variations';
layout/style-driven constructs training pairs for 'reusing layouts/styles without copying content' through prompt-controlled rerendering.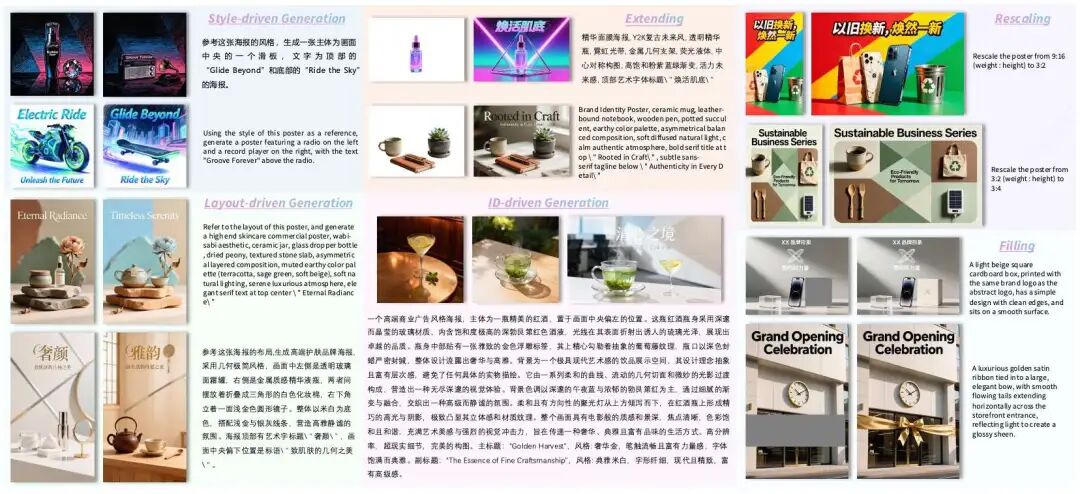
Phase 2: Task Distillation (Divide and Conquer, Then Unify: Enabling 'Refinement' and 'Creation' to Coexist in One Model)
Directly training six tasks together most commonly leads to task interference: Local tasks pursue pixel-level alignment, while global tasks pursue compositional and stylistic abstraction. Within the same parameter space, these objectives pull against each other, making model optimization and convergence difficult. PosterOmni's approach is to train experts first, then distill their capabilities into a student model.
(1) Expert Training: Local Experts + Global Experts
Local editing experts: Focus on extending/filling/rescaling/ID-driven tasks, emphasizing entity consistency, natural boundaries, and text clarity for 'controllable editing.'
Global creation experts: Focus on layout-driven/style-driven tasks, learning abstract layout logic and stylistic tones, producing outputs that resemble 'redesigns.'
Simultaneously, we introduce auxiliary training signals related to text rendering to prevent models from sacrificing text readability when focusing on certain editing tasks (as 'correct text' is a fundamental capability in poster tasks).
(2) Distillation into a Single Student: PosterOmni-SFT
The final unified model does not rely on 'hard parameter fusion' but trains a student network to align with the experts' velocity fields/prediction behaviors: The total loss consists of two parts—
One part is the auxiliary text rendering loss (ensuring stable, clear text);
The other part is the task distillation loss (making student outputs approximate those of corresponding task experts).
In the paper, this is written as a total objective (comprising Auxiliary Text Rendering Loss + Task Distillation Loss), with student predictions denoted as and expert outputs as , thereby migrating both 'local refinement certainty' and 'global creation generativity' into the same backbone.
After this phase, PosterOmni-SFT can be understood as 'a model inheriting the strengths of both types of teachers': capable of both strictly controlled local editing and executing abstract layout/style instructions, rather than relying on multiple models in series.
Phase 3: Unified Reward Model Training (Turning 'Good Looks + Task Completion' into Optimizable Signals)
Supervised fine-tuning (SFT) enables models to 'learn to do,' but it struggles to make models 'learn to do better—more aesthetically pleasing and designer-like.' Unlike the SFT phase, where objectives like 'aesthetics, fidelity, and task goals' often conflict, the evaluation of final posters actually shares a common set of principles across subtasks (e.g., balanced composition, clear hierarchy, harmonious colors, and text readability). Therefore, we train a unified reward model that simultaneously outputs a comprehensive reward combining general aesthetics and task-specific completion, driving subsequent reinforcement learning (RL).
(1) How to Collect Preference Data
We use PosterOmni-SFT to generate paired results for the same image-to-poster prompt. First, Gemini-2.5-Pro filters the outputs, and then annotators select the one that is 'more visually appealing and better aligned with the task.' More critically, we introduce a practical negative-pair strategy: treating the 'input reference image' as rejected and the 'model-edited output' as chosen. This forces the reward model to recognize that 'meaningful edits' themselves hold value, preventing the model from learning to cheat on certain tasks—such as directly copying the reference image in layout/style tasks.

(2) Model Architecture and Training Objective
Built on a Qwen3-VL encoder + lightweight MLP head, it simultaneously encodes 'visual quality + instructions + task type.' Using the Bradley–Terry objective, preference pairs are converted into an optimizable ranking loss, ensuring that the score for the chosen output is higher than that of the rejected one.
The result: The model learns not just 'good looks' but also 'what counts as correct or lazy for a given task.'
Phase 4: Omni-Edit Reinforcement Learning
With a reward model in place, the key challenge is how to effectively 'write' the reward back into the diffusion/flow-matching model while ensuring stable training. PosterOmni follows approaches like DiffusionNFT: instead of traditional policy gradients in the reverse process (which are prone to instability), it performs direct optimization on the forward diffusion process, using a contrastive diffusion loss to guide the velocity predictor toward high-reward behaviors and away from low-reward ones. DiffusionNFT constructs implicit positive/negative policies from the old policy and uses a reward-weighted objective function to steadily constrain updates to 'higher-reward' regions. Rewards are also normalized for stability.
DiffusionNFT provides a stable paradigm for 'contrastive updates during forward diffusion/flow matching.' Our contribution lies in adapting it to the conditional input format of image-to-poster (input image + instructions + task type) and developing a practical Omni-Edit RL training pipeline: enabling the velocity predictor to handle both 'local editing' and 'global creation' tasks under the same mechanism.
Many works directly use logits/scores from strong vision-language models (VLMs) as universal editing rewards, but such rewards often fail to grasp the 'completion criteria' of poster tasks, leading to cheating solutions that 'look the part but do not follow the task.' The core difference of PosterOmni is that we use to provide task-aware scores, encoding both aesthetic quality and task alignment/completion under a unified reward scale. This ensures that RL updates not only make outputs 'more visually appealing' but also 'more aligned with the task.'
Poster evaluation shares significant commonalities across tasks (composition balance, hierarchy, readability, color schemes, etc.). Thus, we use a unified reward model to optimize these shared quality dimensions while explicitly conditioning on task-specific standards through task tags/descriptions, preventing one task's preferences from interfering with another.
Experiments: What Makes PosterOmni Strong?
We break down evaluations into three parts: a unified benchmark (PosterOmni-Bench) → automated evaluation and comparison → ablation studies of key modules.
1) PosterOmni-Bench: Systematizing 'Designer-Centric Needs' into an Evaluatable Benchmark
We first created PosterOmni-Bench, a dedicated multi-task benchmark for image/poster-to-poster tasks, covering six task categories: Extend/Fill/Rescale/ID-driven/Layout-driven/Style-driven.
To better reflect real-world usage, the benchmark includes both Chinese and English prompts: 540 Chinese + 480 English, totaling 1,020 prompts, evenly distributed across six themes (products, food, events/travel, nature, education, entertainment). Inputs include both single-reference and multi-reference images.
For evaluation, we use a strong VLM (Gemini-2.5-Pro) to score outputs based on:
Aesthetics (overall visual harmony, composition balance, stylistic consistency, etc.)
Task completion (whether edits/migrations follow instructions and preserve required content)
A combined score (1–5 range, weighted into a final metric) is given.
Intuitively, this benchmark tests not 'whether a model can draw' but 'whether it can revise/redesign posters like a designer.'
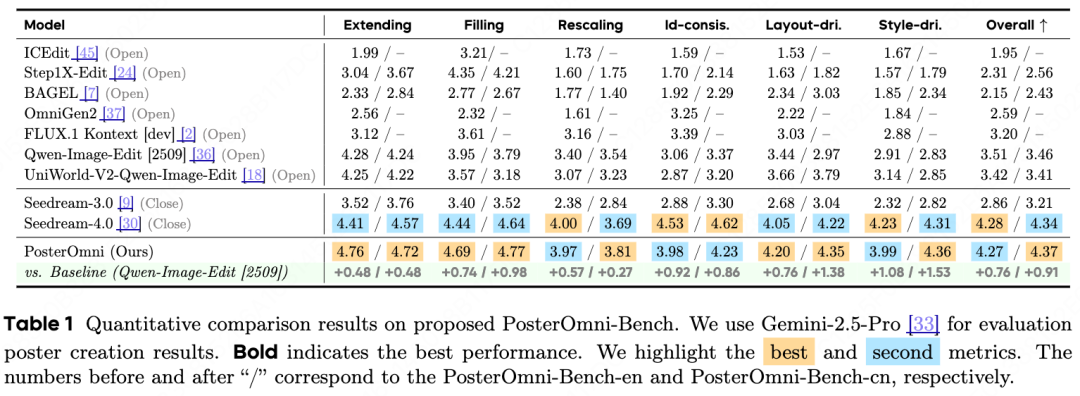
2) Quantitative Comparison: Leading Across All Six Tasks, Outperforming Open-Source Models, Nearing Closed-Source Ones
On PosterOmni-Bench, we compared mainstream open-source systems (e.g., Qwen-Image-Edit, FLUX.1 Kontext, BAGEL, UniWorld-V2) and strong closed-source systems (e.g., Seedream series). The results were consistent: PosterOmni achieved the highest scores across all six tasks compared to open-source models, surpassed some existing closed-source models in overall evaluation, with improvements stemming not from a single task but from simultaneous strengthening of both 'local refinement' and 'global creation' capabilities.
Vs. Qwen-Image-Edit: PosterOmni showed significant improvements in all six tasks (Extend/Fill/Rescale/ID/Layout/Style), especially in Layout-driven/Style-driven tasks requiring high-level design understanding (not just 'patch-based migration' but 'learning layout/style rules for generation').
Vs. Seedream-4.0: PosterOmni's average performance exceeded Seedream-4.0, proving that open-source single models can now handle complex demands at a usable level.
3) Qualitative Comparison: Why Does It 'Learn Styles/Layouts' Instead of 'Direct Copying'?
Two typical failure modes in many baselines (including some closed-source systems) are evident in qualitative results:
Style-driven: Some models directly 'paste' local elements from reference images, resulting in a 'collage-like' appearance or even copying specific objects that should not be replicated. PosterOmni, however, learns 'style essentials' like color schemes, material textures, brushstrokes/lighting, and typographic qualities, then migrates these to new subjects.
Rescale/Layout-driven: Many systems merely crop/stretch or crudely squeeze elements into new canvases. PosterOmni behaves more like 'resizing → re-layouting': adjusting title hierarchy, whitespace, element spacing, and maintaining subject stability. 
4) Ablation Study: What Does Each Module Contribute?
We conducted systematic ablations to answer: Where does PosterOmni's improvement come from—is it 'more training data' or 'actually resolving multi-task interference + aesthetic alignment'?
(a) Task Distillation vs. Direct Mixed Training:
We compared:
Base model (e.g., Qwen-Image-Edit)Six-task mixed training (Mixed Training)Training only local/global experts separatelyFirst training experts, then distilling to a student (Task Distillation)Adding auxiliary text rendering loss (PosterOmni-SFT)
Results:
Direct mixed training helped slightly but still suffered from conflicts between 'local refinement' and 'global composition.' Standalone local/global experts were noticeably biased. The distilled student model was the most stable, and adding auxiliary text rendering further improved text clarity (crucial for poster tasks).
(b) Expert Fusion: Why Does 'Hard Parameter Fusion' Fail?
We also compared common LoRA fusion methods (linear interpolation, ZipLoRA, etc.) with our distillation strategy:
Parameter fusion often 'collapsed toward one expert' or simply 'copied the reference image.' Distillation teaches the student to mimic behaviors (output distributions) rather than hard-fusing parameters, better preserving complementary capabilities. 
Summary: Why This Approach Supports 'One Model for Generalized Multi-Task Image/Poster-to-Poster Generation'
Data: Systematizes six real-world design needs into training pairs (with strict filtering), ensuring the model learns 'usable design capabilities.'
Distillation: Transfers advantages of local and global experts into a single student, avoiding capability conflicts from hard multi-task mixing.
Reward + RL: Uses a unified to turn 'good looks + task completion' into optimizable signals, then injects them into the model via DiffusionNFT's stable forward optimization, preventing cheating copies.
References
[1] PosterOmni: Generalized Artistic Poster Creation via Task Distillation and Unified Reward Feedback
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







