Just Now, Jensen Huang Kept the Entire Silicon Valley Awake Again
 03/17 2026
03/17 2026
 668
668

At 2 a.m. in the SAP Center in San Jose, Jensen Huang once again took the stage in that seemingly ageless black leather jacket. Over the course of a two-hour keynote, Huang unleashed a barrage of "nuclear bombs."
The First Bomb: The Vera Rubin Platform. Seven brand-new chips are now in full production. The Vera Rubin platform consists of seven breakthrough chips, five racks, and one colossal supercomputer. Alongside, the Vera CPU was unveiled, boasting twice the efficiency and 50% faster speeds compared to traditional rack-mounted CPUs.
The Second Bomb: $1 Trillion. On stage, Huang announced that NVIDIA currently sees at least $1 trillion in demand orders stretching through 2027.
The Third Bomb: Tokens as a Commodity. "Tokens are the new commodity," Huang declared, elaborating on the AI factory's business model—a tiered pricing system for tokens, ranging from a free tier to a premium tier.
The Fourth Bomb: NemoClaw for the OpenClaw Community. This open-source project "achieved in weeks what Linux took 30 years to accomplish," Huang asserted, "Every company needs an OpenClaw strategy."
This event left a wealth of information to digest. Chips, factories, robots, AI agents... every term could be the gateway to the next trillion-dollar market. If you missed the livestream tonight, this article will tell you exactly what Jensen Huang said.
01
The Nuclear Arsenal of Chips
Vera Rubin has arrived.
Vera Rubin is NVIDIA's newly designed next-gen computing platform tailored for "Agentic AI."
Compared to its predecessor, the Blackwell platform, Vera Rubin demonstrates astonishing efficiency gains. The system requires only 1/4 of the GPUs to train Mixture-of-Experts (MoE) large models, while achieving up to 10x higher inference throughput per watt and slashing single-token generation costs to 1/10th. In terms of infrastructure, the new NVL72 rack connects 72 Rubin GPUs and 36 Vera CPUs via sixth-gen NVLink. Huang specifically noted that the sixth-gen NVLink switching system is an extremely difficult technology to achieve, but NVIDIA has successfully accomplished this feat.

Additionally, the Vera Rubin system adopts a 100% liquid-cooling design, utilizing 45°C warm water for cooling and completely eliminating traditional cumbersome cabling. This not only significantly reduces data center cooling pressures and energy costs but also shrinks installation time from two days to a mere two hours—a staggering reduction.
The platform integrates Vera CPU, Rubin GPU, NVLink 6 switches, ConnectX-9 SuperNICs, BlueField-4 DPUs, and Spectrum-6 Ethernet switches, along with the newly integrated Groq 3 LPU. These chips work in tandem to form a powerful AI supercomputer, supporting every stage of AI—from large-scale pre-training, post-training, and test-time scaling to real-time intelligent inference.
Huang stated, "Vera Rubin represents a generational leap—composed of seven breakthrough chips, five racks, and one massive supercomputer, designed to power every stage of artificial intelligence."
The Debut of Vera CPU
A major highlight of the conference was NVIDIA's first display of its strong ambitions in the central processing unit (CPU) sector. NVIDIA initially unveiled its first-generation Grace CPU at the 2022 GTC conference. Tonight, Huang officially launched the Vera CPU and Vera CPU rack, marking NVIDIA's formal entry into direct CPU sales and positioning it as a formidable competitor to Intel and AMD in the traditional CPU market.
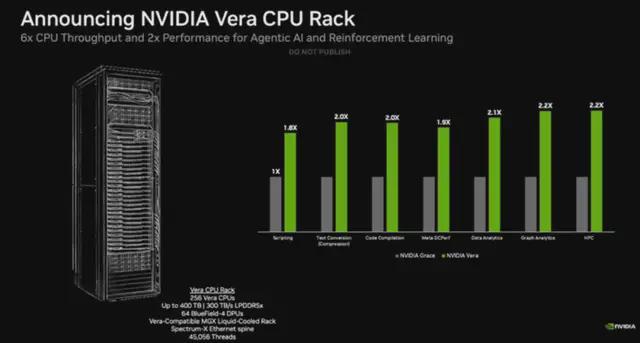
The Vera CPU is designed for large-scale data processing, AI training, and agent-based inference scenarios, boasting twice the efficiency and 50% faster speeds compared to traditional rack-mounted CPUs.
To meet the ultra-fast response requirements of AI tools, the Vera CPU is engineered for extremely high single-thread performance, robust data processing capabilities, and exceptional energy efficiency. A single Vera chip features 88 cores and 144 threads, utilizing NVIDIA's deeply customized Arm v9.2-A Olympus cores, achieving a 1.5x generational improvement in instruction-level parallelism (IPC).
Even more revolutionary, the architecture introduces the groundbreaking "Spatial Multithreading" technology, which physically isolates pipeline components to enable multiple threads to truly run simultaneously on a single core, completely eliminating the computational power loss caused by resource queuing in traditional multithreading techniques. The Vera CPU is also the world's first data center CPU to adopt LPDDR5, delivering unparalleled single-thread and per-watt performance.
As part of the NVIDIA Vera Rubin NVL72 platform, the Vera CPU is paired with GPUs via NVLink-C2C interconnect technology, providing 1.8 TB/s of coherent bandwidth (7x that of PCIe Gen 6) for high-speed data sharing between CPUs and GPUs.
NVIDIA stated that Alibaba, CoreWeave, Meta, and Oracle Cloud Infrastructure, along with global system manufacturers such as Dell Technologies, HPE, Lenovo, and Supermicro, are all partnering with NVIDIA to deploy Vera. Meanwhile, NVIDIA unveiled the Vera CPU rack, offering dense liquid-cooled infrastructure based on NVIDIA MGX, integrating 256 Vera CPUs to provide scalable, energy-efficient capacity and world-class single-thread performance, thereby unlocking the potential of intelligent AI at scale.
The Vera CPU is now in full production, with deliveries expected to begin in the second half of this year.
After Acquiring Groq, LPU Makes Its Debut

NVIDIA acquired the team behind Groq chips and deeply integrated their technology with Vera Rubin.
Why is LPU needed?
Unlike most AI accelerators that rely on HBM as their working memory layer, each Groq 3 LPU integrates 500MB of SRAM—the same type of ultra-fast cache memory used in CPUs and GPUs. While this pales in comparison to the 288GB of HBM4 on each Rubin GPU, this SRAM delivers 150 TB/s of bandwidth, far exceeding HBM's 22 TB/s. For bandwidth-sensitive AI decoding operations, the substantial bandwidth increase of the Groq 3 chip offers tantalizing advantages for inference applications.
Unifying Two Extreme Processors: LPU + Vera Rubin. "We came up with a brilliant idea," Huang explained. "We completely rearchitected the inference process. We put work suited for Vera Rubin on Vera Rubin, then offloaded the decoding generation, low-latency, bandwidth-constrained parts to the LPU."
The unification of these two extreme processors—one for high throughput, the other for low latency—produced astonishing results: inference throughput per megawatt of power consumption increased by up to 35x, while the opportunity for gains in trillion-parameter models rose by up to 10x.
"35x," Huang repeated, "the world has never seen this before."
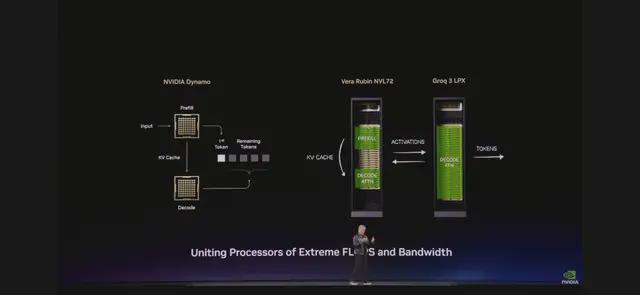

NVIDIA built the Groq 3 LPX rack containing 256 Groq 3 LPUs. This rack provides 128GB of SRAM and 40 PB/s of inference acceleration bandwidth, connecting these chips via a dedicated 640 TB/s per-rack expansion interface.
When deployed at scale, LPU clusters function as a single giant processor, enabling rapid, deterministic inference acceleration. Integrated with Vera Rubin NVL72, Rubin GPUs and LPUs significantly boost decoding speed by jointly computing each layer of the AI model for every output token.
The LPX features a full liquid-cooling design, built on MGX infrastructure, and seamlessly integrates into the next-generation Vera Rubin AI factories set to launch in the second half of this year.
Reshaping Network and AI-Native Storage Architectures
In network connectivity and cluster scaling, NVIDIA showcased the next-generation Kyber rack, a system designed specifically for Rubin Ultra compute nodes. Unlike traditional horizontal insertion, Kyber adopts a vertical insertion design, connecting through a midplane on the backplane, successfully linking up to 144 GPUs within a single NVLink domain and breaking through the distance limitations of traditional copper connections.
Meanwhile, NVIDIA collaborated with TSMC to exclusively mass-produce the revolutionary Co-Packaged Optics (CPO) technology named COUPE, applied in the world's first CPO Spectrum-X switch, enabling direct optical signal connection to the chip.
NVIDIA redesigned the entire storage system: the BlueField-4 STX storage rack. It seamlessly extends GPU memory across the entire POD (Physical Data Center). Powered by BlueField-4, which combines Vera CPU and ConnectX-9 SuperNIC, STX provides a high-bandwidth shared layer optimized for storing and retrieving massive key-value cache data generated by large language models and intelligent AI workflows.
Space Computing Has Arrived

At the GTC conference, Huang also announced the NVIDIA Space-1 Vera Rubin module, marking NVIDIA's formal launch of space computing services. Compared to the NVIDIA H100 GPU, the Rubin GPU on this module provides up to 25x higher AI computing power for space-based inference, enabling next-generation computing capabilities for ODC (Distributed Computing Centers), advanced geospatial intelligence processing, and autonomous space operations.
According to NVIDIA's official press release, the Vera Rubin space module is designed for orbital data centers that directly run LLMs and advanced foundational models in space, featuring a tightly integrated CPU-GPU architecture and high-bandwidth interconnects aimed at real-time processing of massive data streams from space instruments.
Huang stated, "Space computing, this final frontier, has arrived. As we deploy satellite constellations and venture deeper into space, intelligence must reside wherever data is generated."

The event also showcased a complete chip roadmap. "One new architecture per year," Huang summarized. "That's NVIDIA's speed."
02
$1 Trillion: The Demand NVIDIA Sees
"$500 billion." That was the high-confidence demand and purchase orders NVIDIA saw, as announced by Huang at last year's GTC conference.
At the time, he believed this figure was already astonishing. "But now, a year later, standing right here, I see at least $1 trillion in demand stretching through 2027."
Why is the demand so enormous? "Because the inflection point for inference has arrived," Huang explained in detail during his keynote.
What happened in the past two years? "Three things," Huang recalled. First, ChatGPT launched the generative AI era. "It doesn't just understand and perceive—it can translate and generate unique content." Second, inferential AI (o1/o3) emerged. "It can reflect, think, plan, and break down an incomprehensible problem into understandable steps. This truly made ChatGPT take off." Third, Claude Code appeared: the first agentic model. "It can read files, write code, compile, test, evaluate, and iterate. Claude Code revolutionized software engineering."
Huang cited a key statistic: "AI computing demand has increased roughly 10,000x over the past two years. AI must now think. To think, to execute, to read—it must all infer. Every interaction involves inference. The era of training is over. This is the era of inference." This is the source of the $1 trillion demand. Every company is building AI factories, and every factory needs token production.
Tokens Are the New Commodity
"Tokens are the new commodity." When Huang uttered these words at GTC 2026, the business model of the entire AI industry was being redefined. On the "most important chart" Huang displayed, the x-axis represented token rate, and the y-axis represented throughput. This chart will dictate every CEO's decisions going forward—because it directly relates to AI factory revenue.
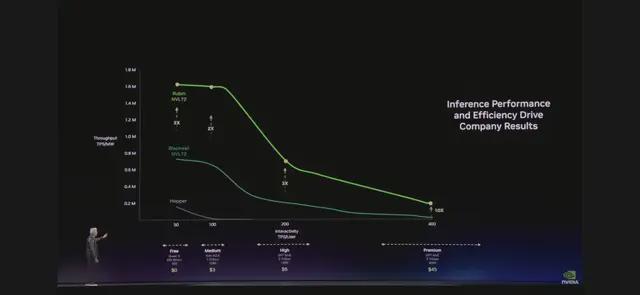
Jensen Huang explained in detail the business model of AI factories, including the tiered pricing for Tokens:
Free tier: High throughput, low speed—designed to attract users. Tier 1: Moderate speed—$3 per million Tokens. Tier 2: High speed, long context—$45 per million Tokens. Premium tier: Ultra-high speed—$150 per million Tokens.
"Just like in any industry," Huang explained, "higher quality, higher performance, and lower capacity. Grace Blackwell delivers massive throughput in your free tier, but at the tier where you can monetize the most, it boosts performance by 35x. Vera Rubin further enhances this by another 10x."
"Suppose you use 25% of your power on the free tier, 25% on the moderate tier, 25% on the high tier, and 25% on the premium tier. Your data center has only 1 gigawatt. You need to decide how to allocate it." Huang did the math: The free tier attracts users, while the premium tier serves the most valuable customers. This combination, as calculated in this chart—Blackwell can generate 5x the revenue, and Vera Rubin adds another 5x.
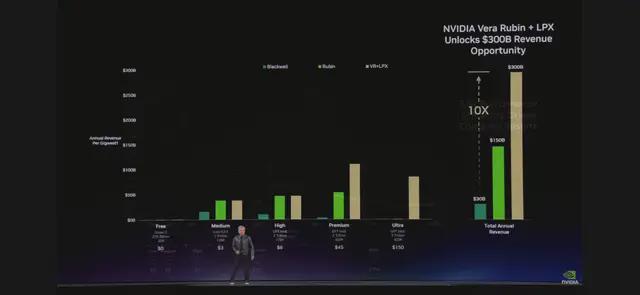
"You should act quickly on Vera Rubin," Huang advised, "because your Token costs will decrease, and throughput will increase."
"Over two years, in a 1-gigawatt factory, using the math I showed earlier, Moore's Law will only give us a few steps of improvement. But with this architecture, our Token generation rate will increase from 22 million to 700 million—a 350x boost." This is the power of "extreme co-design." Huang calls it a strategy of "vertical integration followed by horizontal openness."
03
Jensen Huang Praises Lobster
"OpenClaw is the most popular open-source project in human history. It achieved in weeks what Linux took 30 years to accomplish."
When Huang announced NVIDIA's support for OpenClaw, the audience erupted once again. OpenClaw is an operating system for Agentic systems. It connects to large language models, manages resources, accesses tools and file systems, performs scheduling, and creates sub-agents—making it nearly a complete operating system.
"Before OpenClaw, personal computers became possible because of Windows," Huang said. "Now, OpenClaw makes creating personal Agents possible. The implications are profound."
Agentic systems can access sensitive information, execute code, and communicate externally, posing significant security challenges. NVIDIA introduced NemoClaw, which uses the NVIDIA Agent Toolkit software to optimize OpenClaw with a single command. It installs OpenShell, provides open models and isolated sandboxes, and adds data privacy and security safeguards for autonomous agents.
04
Conclusion
From a single GPU to an AI factory, Jensen Huang has completed NVIDIA's evolution over the past decade. The curtain has risen on GTC 2026. After watching this launch event, what is the question you care about most?
Do you think NVIDIA will be "deified" or "brought down from its pedestal" in the next decade?
Let's discuss in the comments.
-
![]()
Zhao Ming Departs, IPO Postponed, AI Phones Underperform—Can Honor Still Live Up to Its Name?
-
![]()
Explosion of Recording Hardware! Four Major Product Categories Compete for New AI Entry Points, with Agent Capabilities Becoming Standard
-
![]()
China’s LEO Satellite Internet Achieves Strategic Progress: Over 100 Additional Satellites Set for Launch
-
![]()
Musk Sustains $88 Billion Loss in AI Pursuit, Now Rents GPUs to Rivals, Anticipating $500 Billion Revenue Over Three Years
-
![]()
Report | Token Economics: Envisioning a New Path for RMB Internationalization
-
![]()
Trends丨Gartner's Latest Forecast: These Seven Transformations Will Reshape the Technology Landscape Over the Next Five Years
-
Betting on Embodied AI: Bosch's New Game Plan in China
-
![]()
WeChat Collaborates with Huawei/Honor/Xiaomi on A2A: Is This the Dawn of AI Integration?






