The Computing Power Shortage for Kimi, Minimax, and Others: AI at Bargain Prices, But You Can't Get It
 03/27 2026
03/27 2026
 550
550
Local 'Shrimp' models still carry significant risks, prompting the launch of various cloud-based alternatives.
Kimi released K2.5, and I immediately signed up for the Allegretto plan—a 199 RMB/month package, the minimum required to deploy KimiClaw—to test the capabilities of Agent clusters. I also tried MiniMax's Coding Plan.
The result? Kimi frequently displayed notifications like 'Insufficient computing power during peak hours,' and Agent tasks often failed mid-execution. MiniMax was even worse: after deploying 'Lobster,' conversations would drop after just a few exchanges, and the API constantly returned rate-limiting warnings.
For 199 RMB, I essentially bought a spot in a computing power queue.
Browsing user groups, complaints were rampant. One MiniMax user @'ed customer service: 'I've been disconnected continuously today—drops after two sentences.' The reply? 'We suggest checking your local network.' Another user posted a terminal screenshot showing a MiniMax API rate_limit_error, paired with a 'Cyber Overworked Horse' meme: 'Bro, I'm just one shrimp. I sent a message after five minutes, and you throttle me?'
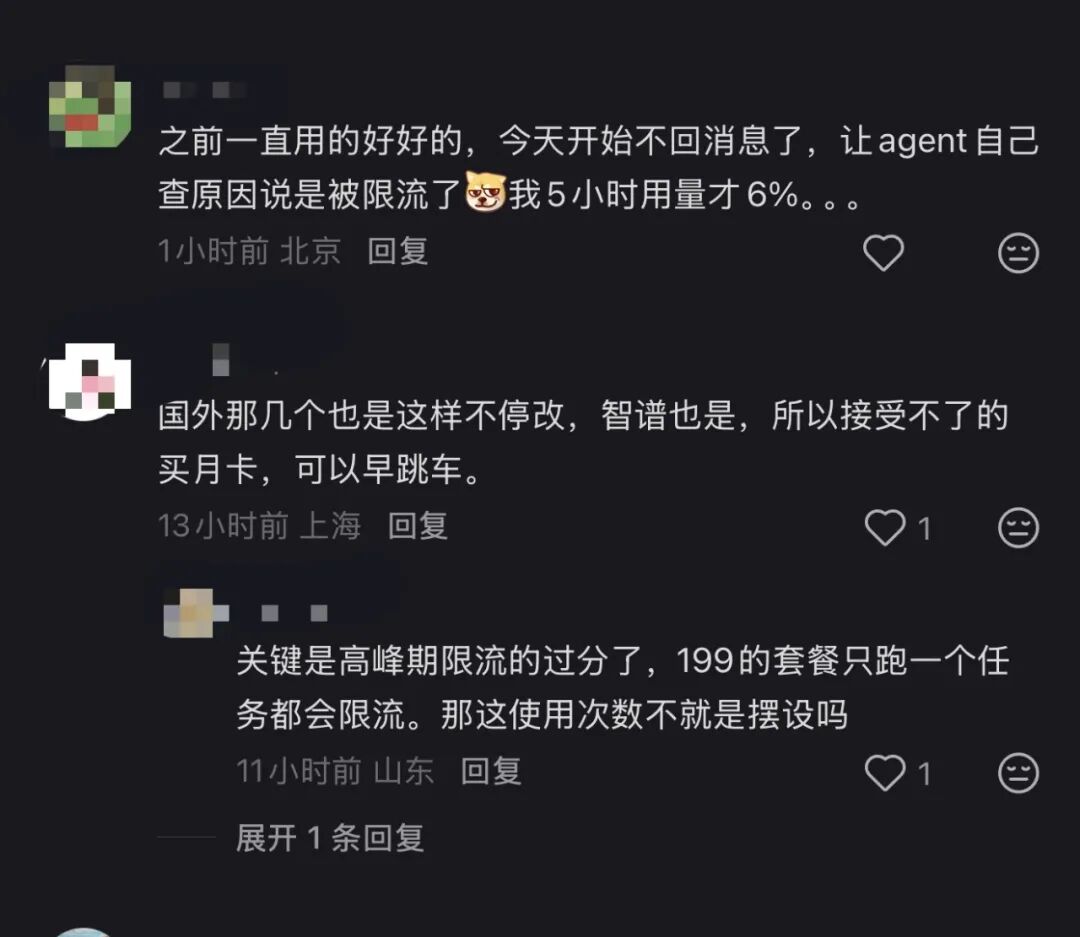
On Xiaohongshu, the consensus is to 'bail out.'
In short: you pay, but the computing power isn't guaranteed. Availability depends on luck, as throttling during peak hours is severe.
Claude over there imposes quotas, while we face throttling. Still, 'Artificial General Workers' are great—running for a day only requires two buns.

However, the computing power shortage is nothing new. On February 10, Kimi went down due to a computing crisis, responding with what bordered on performance art: 'Um, we're seeking computing power. Try DeepSeek for now.' A company with over $2 billion in funding and $10 billion in cash directed users to a competitor during its product's peak popularity. DeepSeek fared no better—massive outages occurred on February 28 and March 5 due to server overload.
By spring 2026, domestic AI collectively entered an era of 'unavailability.'
Computing Infrastructure: Early Overload
Intuitively, the 'computing power shortage' seems tied to trade restrictions. That's plausible but imprecise.
Restrictions provide context, but models like DeepSeek and Qwen were designed under resource constraints from the start. Their MoE architectures inherently save computing power. Kimi president Zhang Yutong stated bluntly at Davos: 'Using just 1% of the resources of top U.S. labs, we built a global-leading open-source model.'
The real infrastructure breaker is Agents.
Chatbots operate on a question-and-answer basis, with linear, predictable computing consumption. Agents are different—a single task may trigger dozens or hundreds of model calls: planning, decomposition, execution, reflection, error correction. Each step requires model processing. Long contexts continuously occupy VRAM, while tool calls leave GPUs idling.
In the Chatbot era, GPUs were like restaurant servers—moving to the next table after serving one. With Agents, servers stay with a single table from ordering to payment, unable to leave even during menu deliberations. The same number of servers can now handle far fewer tables.
Rough calculations show Chatbot single-round dialogues consume 1,000–3,000 tokens. An Agent completing a task—like running a deep research analysis with 'Lobster'—requires multiple perception-planning-execution-reflection cycles. Moderate complexity easily consumes 100,000 tokens; complex tasks reach millions.
Developers report single OpenClaw runs burning 8 million tokens. Coupled with reasoning chain models like K2.5 Thinking, hidden tokens from the thinking process amplify costs by 10–30x. Conservatively, computing consumption per task balloons 30–100x from Chatbots to Agents, exceeding 1,000x in extreme cases.
Deloitte highlights a macro paradox: token unit prices dropped 280x over two years, yet corporate AI bills surged—inference costs fell 1,000x, but demand grew 10,000x.
The issue? Kimi and MiniMax don't own GPUs.
Financially, MiniMax reports minimal fixed asset expenditures. Kimi, though unlisted, follows a similar pattern—nearly all computing power comes from third-party cloud services, a stark contrast to OpenAI's self-built data centers. Kimi relies on dual-track supply from Volcano Engine and Alibaba Cloud: Volcano Engine exclusively provided training and inference solutions since 2023, while Alibaba's $800 million investment in Yuezhi Aymian partially settled as Alibaba Cloud computing credits, with Yang Zhilin publicly endorsing Alibaba Cloud. MiniMax's supplier list is more complex—Alibaba Cloud, Tencent Cloud, and Volcano Engine all compete, with early bidding wars driving prices down to 20% of original quotes.

No one anticipated how rapidly token demand would explode with the arrival of 'Lobster.'
After Agents emerged, the logic of price wars collapsed. 'The future' became 'the present'—the window to gradually expand infrastructure vanished overnight.
While users curse Kimi's lag, Kimi likely curses Volcano Engine and Alibaba Cloud for theirs. The computing shortage cascades through four layers: chips to cloud services to model companies to users. Kimi and MiniMax, at the bottom, bear compounded pressure from every level.
Can upstream providers hold up?
Signs indicate strain. In March 2026, domestic cloud providers collectively raised prices for AI computing and storage products, with increases ranging from single digits to over 30%. UCloud implemented across-the-board hikes. Overseas, AWS and Google Cloud tested price adjustments on select products. SK Hynix stated publicly that storage chip price hikes through 2026 are inevitable, with DRAM inventory at just four weeks. The two-decade rule of 'cloud prices only going down' has shattered under AI demand.
The pricing logic is straightforward. Cloud providers spent billions expanding AI infrastructure over the past year, but AI's profit margins remain thin, far from covering capital expenditures. Token usage grew exponentially—180 trillion tokens consumed daily by mainstream domestic models in February 2026—yet token revenue can't keep pace with data center costs. Price hikes aren't driven by greed but by supply chain pressures.
More daunting is equipment depreciation. AWS, Google Cloud, and Azure uniformly extended server depreciation schedules from 3–4 years to 6 years in 2023–2024, collectively saving ~$18 billion in annual depreciation expenses. Yet NVIDIA's chip iteration cycle is just 18–24 months—GPUs in data centers built today may be suboptimal in two years, yet depreciated over six.
Satya Nadella admitted: 'I don't want to carry depreciation for four to five years on one chip generation.'
Consider the computing market landscape. Volcano Engine leads with 63 trillion tokens daily via Doubao, capturing 49.2% of public cloud model calls—nearly half the market. Alibaba Cloud ranks second with 32 trillion, followed by Tencent Yuanbao (28 trillion) and DeepSeek (22 trillion). However, call volume leader ≠ revenue leader—Omdia statistics show Alibaba Cloud dominates the AI cloud market with 35.8% revenue share, exceeding the combined total of ranks two to four. Volcano wins with 'light' assets; Alibaba with 'heavy' infrastructure.
Kimi and MiniMax's computing lifelines rest in these two companies' hands. After MiniMax's IPO, capital markets raved about token growth—M2.5's debut week saw calls surge to 3.07 trillion tokens—but each token represents real inference costs. MiniMax generated under $80 million in 2025 revenue with a $250 million adjusted net loss, its gross margin barely reaching 25%. Upstream price hikes could erase that fledgling profitability.
For consumers, the outcome is clear: endure further price hikes or usage limits. Kimi's cheapest Allegretto plan now costs 199 RMB/month, nearly matching Claude Pro's price, which includes Co-work and Claude Code. If prices rise further, 'bargain-basement AI' will vanish.
As this article went to press, Tiger Brokers reported that Yuezhi Aymian is considering a Hong Kong IPO. Kimi must now answer: continue leasing computing power or invest in hardware? Prioritize profit margins or user retention? MiniMax already stands in the spotlight, its quarterly earnings reports under scrutiny. Kimi, with $10 billion in cash, faces no immediate capital market pressure—but today, rumors swirl about its own Hong Kong listing.

If true, Kimi and MiniMax must confront a critical choice: prioritize users or profit margins. As price hikes cascade, the likelihood of being 'squeezed from both ends' rises sharply.
Final Thoughts
In 2026, Agents reshaped computing demand curves. Cheap AI didn't become expensive—how we use it changed, straining resources.
When will price hikes stop? Not anytime soon. Agent demand curves remain steeply ascending—Kimi K2.5 surpassed 2025 annual revenue within a month of launch; MiniMax M2.5's debut week token consumption exceeded three competitors combined. Multi-Agent parallelism, long-context reasoning, and programming scenarios are just beginning to explode, each new use case driving token usage higher. Meanwhile, supply-side expansion occurs in yearly cycles—data centers take ≥18 months from planning to operation, and chip replacement under restrictions is slower. Demand grows weekly; supply annually. The gap fuels hikes and throttling.
More profoundly, Chinese cloud providers may enter a new capital-intensive era. For two decades, cloud computing narrative centered on 'lightness'—elasticity, pay-as-you-go, minimal upfront investment. Agents flipped this. Alibaba pledged $57 billion over three years for AI infrastructure; ByteDance's Volcano Engine deployments are equally aggressive. These investments are irreversible—fail to build today, and tomorrow's tokens lack capacity. But built capacity depresses profits via depreciation for five to ten years.
This mirrors telecom operators' 3G/4G rollouts two decades ago: demand explosions forced massive infrastructure builds, which forced price hikes or subsidy cuts, reshaping industry profit structures. China Mobile and China Unicom endured capital expenditure races then; today, Alibaba Cloud and Volcano Engine may face the same. The difference? Telecom had licensing barriers and policy protections. Cloud providers do not.
For Kimi and MiniMax at the chain's end, computing costs won't return to price-war lows. For users running 'Lobster' on 199 RMB plans, the window for 'cheap, good AI' may close faster than anyone imagined.
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






