K2.6 is Yang Zhilin's first roadshow
 04/23 2026
04/23 2026
 389
389

On the night before last, Moonshot AI released Kimi K2.6 and adjusted the API input price from $0.60 to $0.95 per million tokens.
That's a 58% increase—the first price hike since the K2 series launch.
But it seems no one is paying attention.
Four months ago, in an internal letter on the last day of 2025, Yang Zhilin wrote that Moonshot AI was “not in a hurry to IPO in the short term.” By then, both Zhipu and MiniMax had already submitted their prospectuses to the Hong Kong Stock Exchange—a deliberate strategic differentiation.
In the same letter, he noted the company’s cash reserves exceeded $1.4 billion, with its Series C round oversubscribed by $500 million—implying the primary market’s potential was far from exhausted, so there was no rush for the secondary market.
Three months later, Bloomberg reported he had begun engaging with CICC and Goldman Sachs. Three weeks after that, K2.6 went live.
A man who dislikes “rushing” accomplished in four months what he previously said he wouldn’t do.
K2.6 certainly won’t be Moonshot AI’s final product release before going public. But this version’s launch marks Yang Zhilin’s first roadshow since the company began planning its IPO.
Kimi has never released a model like this before
Kimi used to follow a set routine for model releases:
Publish technical reports, open-source weights, climb the HuggingFace leaderboard, then await scrutiny from the tech community. K1.5 benchmarked against o1 for reasoning methodology, with more technical details than benchmark numbers; K2 Thinking directly released its weights on HuggingFace, letting developers run their own tests. These moves were tailored for developers and researchers.
The messaging followed suit: “Here’s the problem we solved, why our method is better, and you’re welcome to replicate it.”
K2.6’s approach is different.
Start with the price hike. In RMB terms, K2.6’s input price per million tokens is 6.5 yuan (cache miss), up from 4 yuan for K2.5. Output prices rose from 21 yuan to 27 yuan. Cache hit pricing is 1.1 yuan.
This is a structured price increase. On the surface, all tiers are rising, but the cache hit tier saw the smallest hike—from 0.7 yuan to 1.1 yuan, or $0.16 per million tokens.
That $0.16 is the key to understanding this price hike.
For enterprise users with long-term, static system prompts—code assistants, Agent orchestration frameworks, AI customer service—their prefix reuse rates are high, with cache hit rates reaching 75% to 83%. Moonshot AI has kept prices nearly flat for these clients.
For occasional users with unique prompts each time, the full price hike applies.
This is a friendly price adjustment for “enterprises already tied to Kimi” and an unfriendly one for “price-sensitive individual users.” The former represents “enterprise-locked customers” in IPO narratives; the latter are “long-tail users” that won’t appear in roadshow PPTs. Moonshot AI knows exactly which users drive its valuation.
The compute requirements for Agent-era workloads differ from conversation-era ones. Dialogue models involve dozens of token exchanges; Agents entail thousands of tool calls and millions of token consumption. In K2.6’s official cases—deploying Qwen3.5 locally on Mac with 4,000+ tool calls over 12 hours, or reconstructing the open-source exchange-core engine with 1,000+ tool calls over 13 hours—single-task token consumption is hundreds or even thousands of times higher than K2.5-era dialogue scenarios.
Of course, these cases demonstrate long-context reasoning capabilities, but combined with K2.6’s 300-Agent cluster, token consumption must be staggering.
At the old price of $0.60, such Agent tasks might lose money per call. At $0.95, they barely cover inference costs.
The price hike isn’t about confidence—it’s a necessity. Moonshot AI has raised $2.5 billion in total funding, with $1.4 billion in cash reserves from Series C to C+ rounds. But if the next-gen K3 truly has 3–4 trillion parameters, a single pre-training round could consume half of that.
Without the hike, gross margin data for the final quarters before the IPO would look ugly—and prospectuses must disclose gross margins.
This could have been explained openly—the Agent era demands new pricing models. But Moonshot AI didn’t. Why? Because C-end users just transitioned from K2 Thinking’s free tier, and telling them “we’re raising prices” isn’t a compelling product narrative.
It’s a story for another audience—Kimi already has enterprise clients who can’t function without it, even at higher prices. (I count myself among them.)
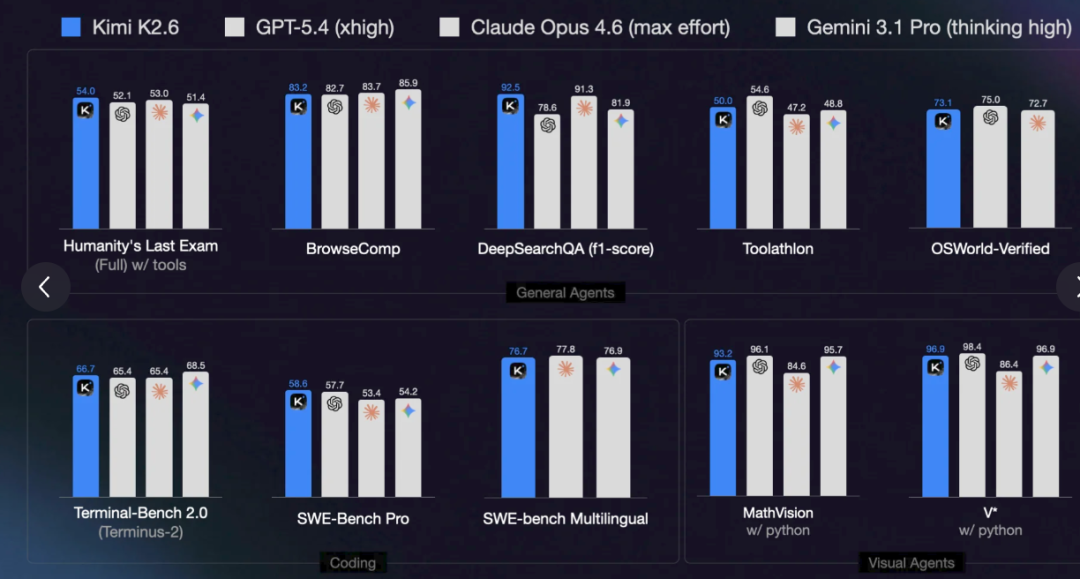
The second move is benchmark targeting. K2.6 officially benchmarks against GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro—all previous-generation flagships.
That same week, Anthropic released Claude Mythos, and Opus 4.7 went live—both a generation ahead of Opus 4.6. K2.6 didn’t benchmark against them.
This was a deliberate choice. Benchmarking against Mythos would position K2.6 as a “chaser”; against Opus 4.6, it lands in the “first tier.” A $18 billion valuation demands the latter.
Kimi rarely played this game before. When K2 Thinking launched, the official approach was to release full benchmark results—good and bad—letting developers judge for themselves. That’s how the tech community operates: they understand your strengths and weaknesses and accept a model with clear shortcomings but a coherent roadmap.
Roadshow PPTs don’t work that way. They need a conclusion a fund manager can grasp in 30 seconds: “On par with or superior to international top-tier closed-source models.” That’s verbatim from K2.6’s official blog.
The third move is Agent clusters and dual-track open-sourcing. K2.6 upgrades Claw Groups—a heterogeneous Agent ecosystem where Agents using different devices, models, and toolchains collaborate in a shared space, with K2.6 as the scheduler. 300 sub-Agents run in parallel, 4,000 steps of coordination, 5 days of autonomous operation.
These numbers are for enterprise clients, not developers. For a developer, “300 parallel Agents” is meaningless—they won’t run 300 Agents in a local project. This configuration only matters to large enterprises needing Agent matrices to automate full workflows.
It’s a Salesforce story, not a HuggingFace story.
Meanwhile, K2.6 goes fully open-source. Yang Zhilin stated at the Zhongguancun Forum on March 26 that “open-source will be the absolute winner.”

Open-source + enterprise-grade Agent clusters—this straddles DeepSeek’s and Anthropic’s models, half-committing to both. It’s a compelling story, but committing to both means proving both.
Capital markets don’t care if these questions have answers. They just need a narrative for each track.
Price hikes, benchmarking, Agent clusters—these three moves share an unusual commonality: none target the tech community.
Kimi’s old model-release logic was: “If developers love me, enterprise clients will follow, and capital markets will follow sooner or later.” This approach had a name: technical sincerity.
K2.6 doesn’t wait. The price hike is a direct declaration of B-end pricing power; benchmarking against GPT-5.4 stakes out valuation positioning in advance; Agent clusters and Claw Groups are showcase units for enterprise services.
Each move answers a question on roadshow PPTs: What’s your monetization capability? Where do you stand against competitors? What’s your B-end moat?
The compressed timeline—from Preview to GA in 8 days—follows this logic. Previous K2 versions had 2–3-month preview periods for community testing, feedback, and iteration. K2.6 denied itself that luxury. Not because the technology matured faster, but because the window won’t wait.
For a 2H 2026 IPO, the HKEX process requires 4–6 months for filing, inquiries, hearings, roadshows, pricing, and cooling-off periods. A September roadshow means product readiness by April.
No GA launch in April means no later window.
K3 is the real closer
But K2.6 isn’t Moonshot AI’s strongest hand.
The official blog understates it: K2.6 is the “runway for K3.”
12-hour long-context coding, 300-Agent clusters, context compressors—these aren’t the final form of the K2 series but infrastructure for a larger foundation model to leverage. Moonshot AI wouldn’t invest in refining these unless certain a bigger model would consume them.
Reddit leaks suggest K3 targets 3–4 trillion parameters—a foundational leap from K2’s trillion-scale.
If K3 launches during the roadshow window, it’s the real showstopper. K2.6 prepares the runway; K3 takes off.
The question is timing. Training a 3–4 trillion-parameter model takes how long? GPT-5 and Claude Opus 4.6 required ~6–9 months of pre-training, plus months for post-training and safety evaluations. Can Moonshot AI’s current compute—based on Alibaba Cloud partnerships and cash reserves—compress this to 5–6 months?
The bet is on K2.6.
Eight days from Preview to GA, expanding Agent clusters from 100 to 300, extending long-context execution from hundreds to 4,000 steps—every move compresses timelines to create space for K3’s possibility.
If K3 launches by August/September, it’s the roadshow’s grand finale.
If not, K3 becomes “the model launching post-IPO,” and K2.6 must carry the entire valuation narrative alone.
Moonshot AI is betting it can deliver.
What anchors the $18 billion valuation?
Back to valuation.
Three months ago, Moonshot AI was valued at $4.3 billion; two months ago, $5.5 billion; now, $18 billion.
It’s not that Moonshot AI grew fourfold in three months. It’s that Zhipu and MiniMax surged fourfold post-IPO, raising the sector’s ceiling. Zhipu’s HKEX market cap is HK$305 billion; MiniMax’s, HK$309.2 billion—both exceeding SenseTime’s historic peak.
Their valuations aren’t about “what next-gen tech can achieve” but “how AI assets can be priced in Hong Kong’s pool.”
Moonshot AI’s $18 billion valuation anchors to the same logic. It’s no longer proving itself as China’s strongest AI company but as China’s *pricable* AI company.
Every K2.6 move—price hikes, benchmarking, Agent clusters, dual-track open-sourcing—responds to this.
But one thing K2.6 hasn’t proven: Will Kimi’s C-end users pay for the price-hiked K2.6? Will paying subscribers defect to DeepSeek or MiniMax? How many enterprise clients actually run Claw Groups, and how many just signed PoCs?
Investors will ask these on roadshows. K2.6 can only present the product now. Whether it translates to numbers depends on the next three months.
When Zhipu filed, its prospectus showed unprofitable operations; MiniMax’s did too. Investors bought the story because the “China AI asset” narrative was just opening. Moonshot AI is six months late. Zhipu and MiniMax could say “we’re validating”; Moonshot AI must say “we’re monetizing.”
That pressure falls entirely on the three months between K2.6 and K3.
So back to the original question: Is K2.6 Moonshot AI’s final roadshow before going public?
No.
If K3 hits the roadshow window, it’s the real closer. K2.6 merely paves the way. If K3 misses the window, K2.6 must carry the entire IPO narrative—making it Yang Zhilin’s forced early debut.
Neither outcome was what Yang wanted four months ago.
But everything that happened in these four months—Zhipu and MiniMax going public, the valuation ceiling rising, the compressed window—has forced a man who dislikes “rushing” to do exactly that.
When K3 launches, that’ll be the second act.
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






