Behind the Sensational Launch of DeepSeek V4: Silicon Valley is 'Building Walls', While China is 'Constructing Roads'
 04/27 2026
04/27 2026
 608
608

On the morning of April 24th, the long-awaited DeepSeek V4 finally made its debut.
On the same day, DeepSeek-V4-Pro topped Hugging Face's open-source model rankings, with two 'game-changing innovations' generating buzz:
First, its ultra-long context capability in the millions, with a KV cache just 10% of V3.2's size, praised by Amazon engineers for addressing HBM shortages;
Second, its adaptation to domestic chips, achieved through close collaboration with Huawei during development, enabling immediate compatibility with chips like Ascend and Cambrian.
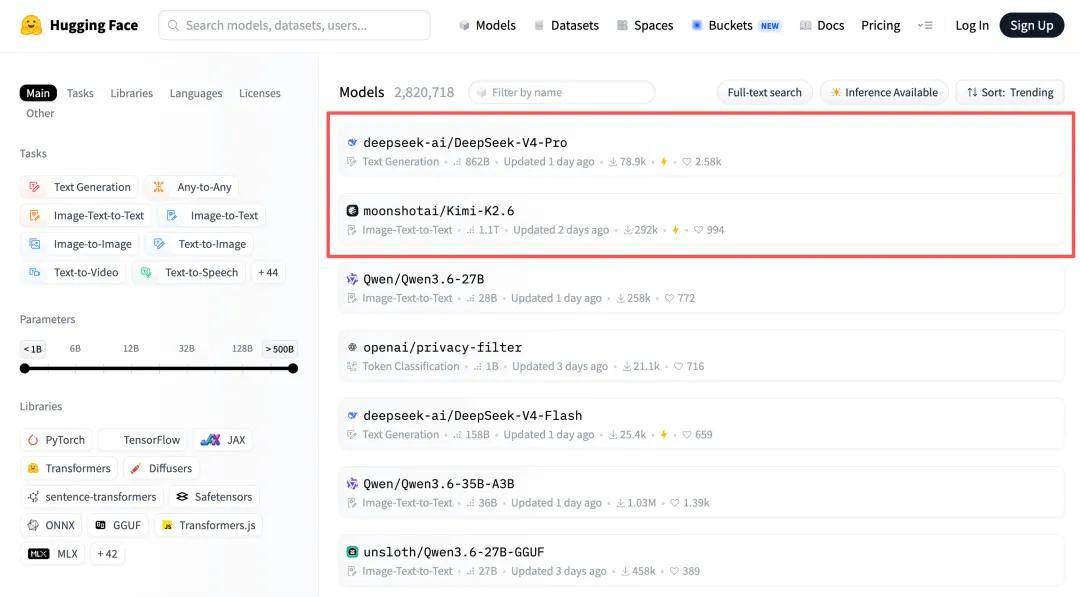
Coincidentally, Kimi K2.6, released and open-sourced late on April 20th, ranked second on Hugging Face's list.
Had this occurred across the Pacific, the simultaneous release of two trillion-parameter models would have likely sparked valuation (valuation)-driven and market-share rivalries. Instead, China witnessed a starkly different scene: no undercutting, no covert PR wars—even technical defenses were swapped.
Behind this 'unconventional' dynamic lies a divergence in AI tech paths between China and the U.S.: Silicon Valley is frantically 'erecting walls' to protect vested interests through closed-source models, while Chinese firms are 'tearing them down', evolving collaboratively in the open-source ecosystem.
01 Silicon Valley's 'Game of Thrones'
Unlike China's vibrant open-source landscape for large models, Silicon Valley's AI leaders—OpenAI, Anthropic, and Google Gemini—are staunch advocates of closed-source approaches.
As cutting-edge innovations remain locked in data centers, the 'Silicon Valley spirit' of openness and collaboration is fading under pressure from soaring computing costs and capital market expectations. Players are inevitably trapped in a zero-sum 'power game.'
Over the past two years, technical 'shadow warfare' has escalated into public feuds, with 'stealing the spotlight' as a key tactic: releasing major updates to drown out competitors' announcements has become a Silicon Valley norm.
As early as May 2024, OpenAI and Google simultaneously launched AI products—one claiming GPT-4o as globally leading, the other asserting Gemini's ecosystem-wide coverage. Both CEOs eventually took to social media to mock each other publicly.
Beyond Google, OpenAI's rivalry with Anthropic intensified: on April 16th, just hours after Anthropic released Claude Opus 4.7, OpenAI announced a major Codex update with the slogan 'Codex for (almost) everything.' The timing was no coincidence but a calculated 'ambush' against Anthropic.
Alongside verbal clashes, 'exposing rivals' flaws' has become commonplace in Silicon Valley.
On April 7th, Anthropic proudly announced $30 billion in annualized revenue, surpassing OpenAI's $25 billion.
A week later, OpenAI's Chief Revenue Officer claimed in an internal memo to all employees that Anthropic's $30 billion figure was inflated, as it used 'gross billing' to include commissions paid to cloud providers like Amazon and Google, overestimating revenue by ~$8 billion.
Such public undermining of rivals is rare in tech, aiming to signal to investors that Anthropic's growth narrative is exaggerated.
Once hostility takes root, it permeates every decision.
After Anthropic broke ties with the Pentagon over refusing to remove specific safety clauses in contracts, OpenAI announced a high-profile partnership with the U.S. Department of Defense hours later.
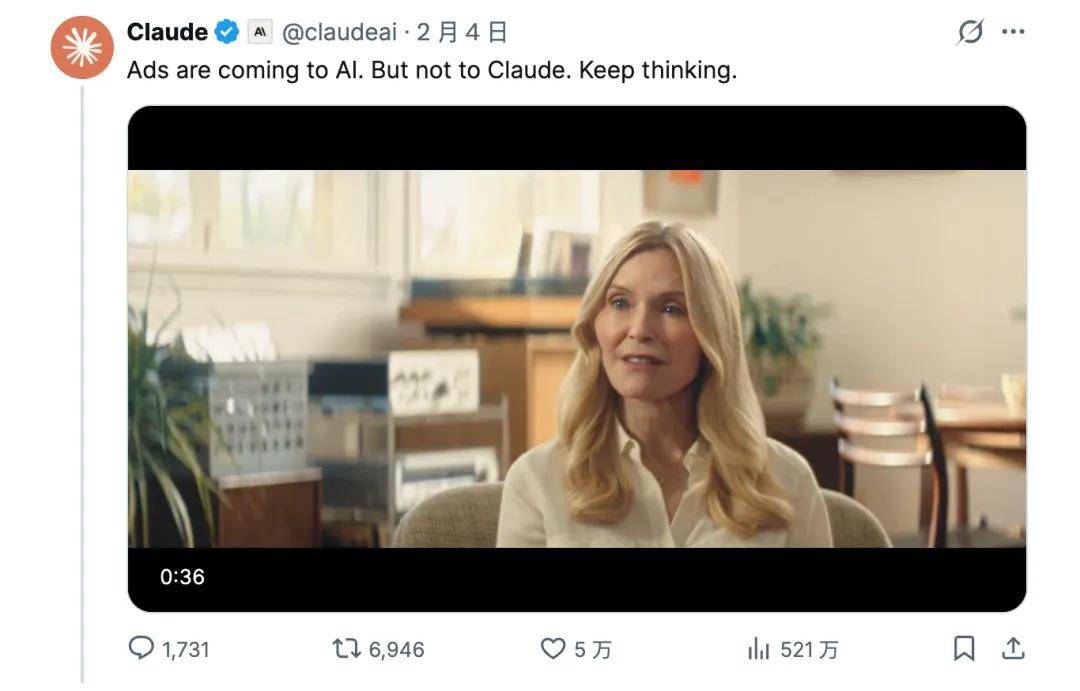
At the 2026 Super Bowl, Anthropic aired a costly ad stating, 'Advertising is entering AI—but not Claude,' directly targeting OpenAI's nascent ad testing...
Why have former 'allies' become irreconcilable?
The root lies in closed-source business models: survival depends on building moats, which requires blocking technology diffusion and monopolizing advanced productivity. Combined with incompatible tech paths and conflicting product narratives, a Nash equilibrium emerges: whoever 'ceases fire' first risks brand narrative collapse, trapping players in a self-destructive cycle.
02 Open-Source Camp's 'Collaborative Evolution'
Shifting focus to China, the script unfolds differently.
Over a year ago, DeepSeek-R1's emergence acted as a brake on the frenetic large model race, directly impacting the 'Six Little Tigers' in the final round. Unlike Silicon Valley, DeepSeek didn't play the 'shark' devouring all fish but acted as a 'catfish,' energizing China's AI ecosystem and driving widespread open-source adoption.
A prime example is Moonshot AI, whose growth trajectory closely mirrors DeepSeek's—both started in 2023 with small, elite teams and are staunch believers in Scaling Law.
In July 2025, Moonshot AI released Kimi K2, the world's first trillion-parameter open-source model, openly adopting DeepSeek's MLA architecture. For large models, handling ultra-long texts is a nightmare due to memory wall constraints, but MLA's breakthrough lies in compressing KV Cache by over 93%.
With DeepSeek setting this 'industry standard,' teams like Moonshot AI avoided reinventing the wheel, swiftly reducing inference costs.
The story didn't end there.
DeepSeek V4's technical docs detailed an architecture upgrade, replacing AdamW optimizers with Muon in most modules for faster convergence and training stability.
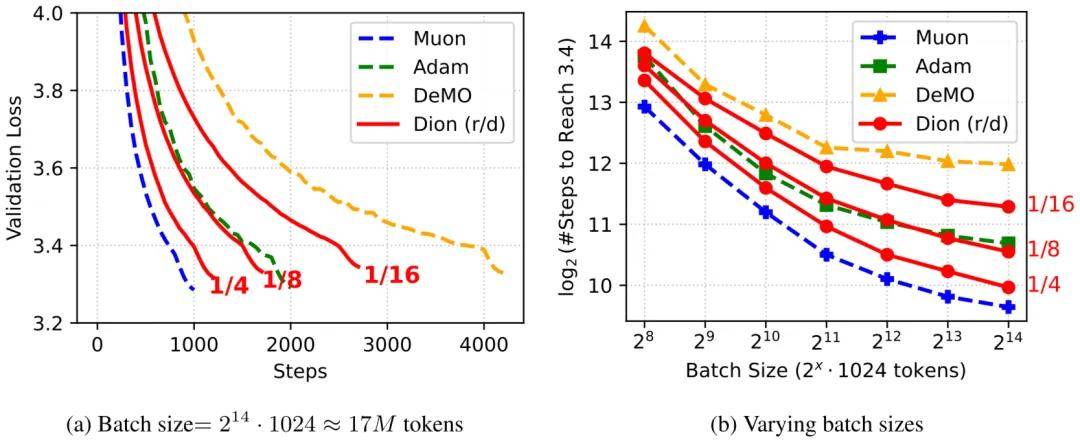
Kimi K2.6's technical docs also mentioned Muon, achieving 2x efficiency gains under the same training volume.
The Muon optimizer, first proposed by independent researcher Keller Jordan in a late-2024 blog, was improved by Moonshot AI in early 2025 with added Weight Decay and RMS control, renamed MuonClip.
Moonshot AI validated Muon's stability on Kimi K2, achieving 'zero loss spikes' throughout pre-training. DeepSeek adopted the same verified optimizer for V4.
Notably, open-source models' 'collaborative evolution' avoids homogenization, pursuing 'unity in diversity.'
For instance, DeepSeek-V4 focuses on core foundational model capabilities, raising the global performance ceiling for open-source models and providing a closed-source-rivaling base for the industry. Kimi K2.6 specializes in Agent engineering, solving long-term autonomous execution challenges and paving the way for real-world AI applications.
This process involved no protracted negotiations or patent wars. In the open-source camp, technological innovation flows freely—the best solutions are adopted by all.
Drawing nutrients from the open-source ecosystem and complementing tech paths, Chinese firms demonstrate an alternative to Silicon Valley.
03 U.S. 'Builds Walls,' China 'Constructs Roads'
While celebrating open-source collaboration, a commercial reality must be faced.
OpenAI and Anthropic now exceed $10 billion in annualized revenue, while China's top large model firms have just crossed the $100 million threshold.
OpenAI's secondary market valuation nears $880 billion, Anthropic's soars to ~$1 trillion, whereas Kimi and DeepSeek's latest funding rounds value them at $18 billion and $20 billion, respectively.
Some argue Chinese firms are undervalued; others warn, 'Converting technical reputation into cash is a make-or-break challenge.' Debates on open-source 'cost-effectiveness' abound.
To glimpse the endgame, consider the competitive phases of large models:
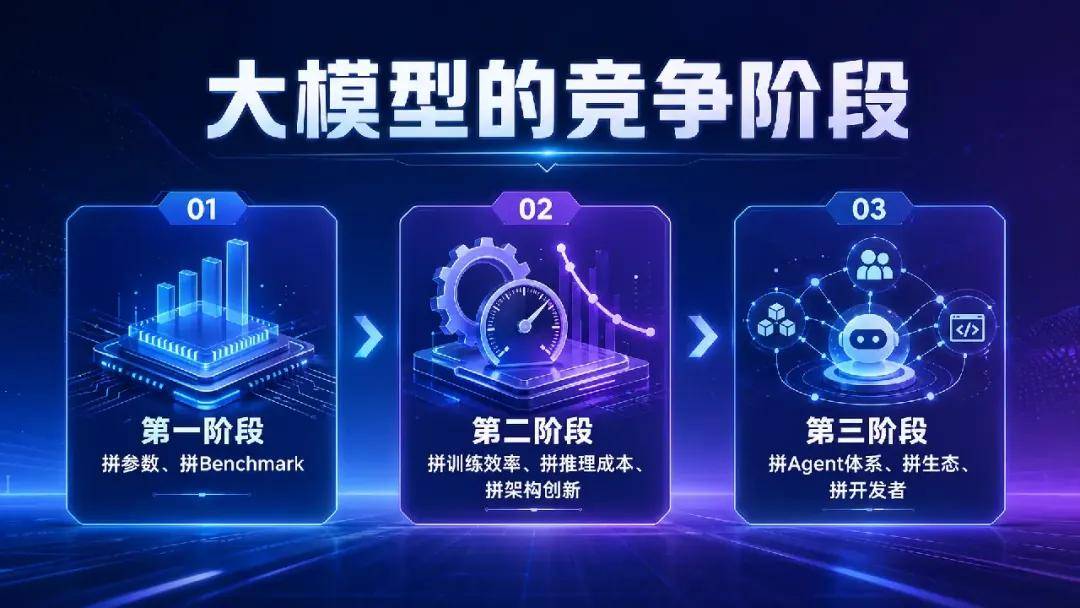
Phase 1: 'Parameter and Benchmark Races.' By late April 2026, this phase ended, with negligible performance gaps on leaderboards.
Phase 2: 'Training Efficiency, Inference Cost, and Architectural Innovation.' This is the current stage, driven by soaring computing costs.
Phase 3: 'Agent Systems, Ecosystems, and Developers.' When tokens shift from free traffic to task-execution 'fuel,' ecosystem vitality will determine survival.
Where do China's open-source models stand? Two data points offer clarity:
Training Costs:
GPT-5 (August 2025) cost >$500 million; Kimi K2 Thinking cost ~$4.6 million; DeepSeek didn't disclose V4's cost, but V3 cost just $5.576 million. Chinese firms train comparable models at a fraction of OpenAI's costs.
Usage Volume:
In 2026, OpenRouter's data showed exponential global token growth driven by Agent products like OpenClaw. China's 'open-source dream team,' renowned for affordability and usability, surpassed U.S. usage for weeks.
The reasons are clear:
China's open-source camp has unlocked a 'virtuous cycle': Company A open-sources foundational tech, Company B adopts and optimizes it, then feeds improvements back to the ecosystem. While closed-source models grow linearly through computing power, open-source routes enable exponential innovation diffusion.
According to JPMorgan, China's AI inference token consumption will grow ~330% CAGR from 2025–2030, surging from 10 trillion tokens in 2025 to 3,900 trillion in 2030—a 370x increase.
Thus, 2026 marks only the early AI boom; 500x growth opportunities lie ahead in the next five years. The race is far from over.
Confident in long-term prospects, while Silicon Valley builds walls, Chinese firms strengthen AGI pathways through collaborative supplementation.
04 Epilogue
Who will dominate this AI wave? The answer hinges not just on models but also on computing autonomy. If models are 'atomic bombs,' domestically produced computing power free from external blockades is the 'rocket' launching them.
Encouragingly, integration between domestic models and computing power deepens: DeepSeek V4's tech docs list Huawei's Ascend NPU alongside NVIDIA GPUs in hardware validation; Moonshot AI's latest paper runs model inference pre-filling and decoding on separate chips, opening doors for domestic chips in large-scale model reasoning (inference).
In early 2025, DeepSeek R1 earned Chinese firms a seat at the global AI table. By 2026, China's open-source camp is collaboratively forging the 'hard currency' to define AI rules.
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







