Same-Day Showdown! DeepSeek V4 vs. GPT-5.5: Global AI Models Chart Separate Courses
 04/27 2026
04/27 2026
 458
458
Source: Duke Internet Society (ID: wlyxs888)

April 24 marked a watershed moment in AI history.
Without prior announcement or teaser campaigns, OpenAI abruptly launched GPT-5.5 in the early hours, touting its "extreme complex reasoning" capabilities—and doubled its API pricing: $5 per million tokens for input, $30 per million tokens for output.
Just 12 hours later, DeepSeek unveiled the full preview of V4, releasing it under the permissive MIT license with a standard 1 million token context window across all versions. The most striking move? Its pricing strategy: V4-Flash costs just $0.28 per million tokens for output, while V4-Pro costs $3.48.
One model is closed-source with soaring costs; the other is open-source with slashed prices. One prioritizes raw computational power to push boundaries; the other optimizes efficiency for broad accessibility. One is tightly bound to NVIDIA’s high-end ecosystem; the other supports both NVIDIA and domestic computing platforms.
This isn’t merely a corporate rivalry—it’s a reflection of diverging philosophies in global AI development. From this day forward, there will no longer be a single “correct” path in AI.
【Stop the “Catching Up to GPT” Hype—DeepSeek’s Real Edge Lies in Efficiency】
The internet is abuzz with claims that “Chinese models have finally caught up to GPT,” but this misses the core innovation behind DeepSeek V4. Its breakthrough isn’t in parameter size but in efficiency—a paradigm shift that redefines industry standards.
Let’s cut through the noise with hard data:
- V4-Pro: 1.6 trillion total parameters, 49 billion activated; V4-Flash: 284 billion total parameters, 13 billion activated.
- Both versions default to a 1 million token context window—a capability previously exclusive to elite closed-source models just six months ago.
- Under a 1 million token scenario, V4-Pro’s per-token reasoning computation is just 27% of V3.2’s, with KV cache usage dropping to 10%.
- For V4-Flash, these figures plummet to 10% and 7%, respectively.
In layman’s terms: Processing the same 1 million words of text, V4 requires only a quarter of the computational power and a tenth of the video memory compared to its predecessor. This isn’t achieved by buying more chips but through DeepSeek’s proprietary hybrid attention architecture, which fundamentally addresses the escalating costs of AI models.
The logic is straightforward: The model doesn’t need to process every word equally. It intensively analyzes core content with strong relevance, compresses weakly relevant background information, and skips irrelevant content entirely. Think of it like reading a book—focus on key chapters word by word, skim through appendices.
In contrast, OpenAI doubles down on brute-force scaling: adding parameters, training data, and computational power to boost capabilities. To support GPT-5.5’s reasoning, OpenAI has already secured over half of NVIDIA’s Blackwell chip production capacity for the year.

In real-world performance, V4-Pro already rivals GPT-5.4 and Claude Opus 4.6 in high-difficulty tasks like mathematics, STEM, and programming. In Agentic Coding evaluations, it sets the benchmark for open-source models, with delivery quality approaching Claude Opus’s non-deliberation mode. V4-Flash, despite its smaller parameter size, matches the Pro version in performance, offers faster response times, and costs just 1/12th of the Pro’s price.
Critically, DeepSeek adopted the MIT open-source license for V4. Anyone—individuals, startups, or enterprises—can freely download, modify, and commercially deploy these models. A three-person startup team can now deploy a top-tier large model with million-token context capabilities by renting a server for a few thousand dollars, without paying licensing fees.

【Stop the “Catching Up” Narrative—Chinese and U.S. AI Are No Longer on the Same Track】
The most outdated phrase in the AI industry today is “Chinese AI is catching up to U.S. AI.”
After witnessing these dual launches, it’s clear the two ecosystems aren’t even competing on the same playing field. From underlying logic to target users and business models, they’ve diverged entirely.
The U.S. AI ethos is “exploring boundaries.” Companies like OpenAI, Anthropic, and Google dedicate 90% of their resources to fundamental research and cutting-edge breakthroughs. Their goal is to create the “world’s smartest AI,” capable of solving mathematical problems, conducting scientific experiments, and writing complex code. To achieve this, they’re willing to ignore costs, using the most expensive chips to train the largest models.
The advantages are undeniable. GPT-5.5 scored 82.7% in Terminal-Bench 2.0 tests, 13 percentage points higher than second-place Claude Opus 4.7; in OSWorld-Verified tests, it achieved a 78.7% success rate, surpassing human baselines. No open-source model currently matches these top-tier complex reasoning capabilities.
But the path’s fatal flaw is equally obvious: costs are skyrocketing. GPT-5.5’s pricing has doubled compared to its predecessor, making it unaffordable for ordinary users, SMEs, and even many large enterprises. If this trend continues, AI will become a luxury reserved for tech giants and wealthy nations.
In contrast, the Chinese AI ethos is “practical application is king.” Companies like DeepSeek, Tongyi Qianwen, and ERNIE Bot prioritize creating “the most useful AI”—affordable, stable, easy to deploy, and capable of solving real-world problems across industries.
To achieve this, Chinese firms have pushed engineering optimization to new heights. While others stack parameters, they refine architectures; while others rely on expensive chips, they adapt to full-platform computing power; while others close-source and sell at premium prices, they open-source and build ecosystems. DeepSeek V4 exemplifies this approach: achieving near-top-tier closed-source model performance with less than a third of the computational power while fully supporting Huawei Ascend and Cambrian platforms.
These paths aren’t about superiority but choice. The U.S. route showcases AI’s future potential; the Chinese route ensures AI’s present accessibility. They’re not competitors but complementary forces driving the industry forward.
【A 100x Price Gap Isn’t a Price War—It’s Open Source’s Strategic Strike Against Closed Source】
Many frame DeepSeek’s pricing as a “price war,” but this underestimates its strategy. This isn’t ordinary commercial competition—it’s a systemic challenge by open-source models to closed-source monopolies.
Let’s break down the numbers:
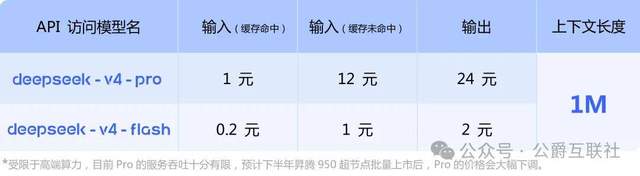
- GPT-5.5: $30 per million tokens for output (~216 RMB)
- Claude Opus 4.7: $25 per million tokens for output (~180 RMB)
- Gemini 3.1 Pro: $12 per million tokens for output (~86 RMB)
- DeepSeek V4-Flash: $0.28 per million tokens for output (~2 RMB)
This isn’t a marginal difference—it’s a two-order-of-magnitude gap. V4-Flash’s price is less than 1% of GPT-5.5’s.
Some question: Can DeepSeek profit at such low prices? The answer: Maybe not immediately, but certainly in the long run. Its business model differs fundamentally from OpenAI’s.
OpenAI’s model is “selling water.” It packages model capabilities into APIs and charges per usage. To maximize profits, it must raise prices while controlling costs—but larger models mean higher costs, forcing inevitable price hikes.
DeepSeek’s model is “building a reservoir.” By open-sourcing and offering free access, it attracts a massive user base. Monetization comes through cloud services, enterprise solutions, and technical support. Critically, user feedback and scenario data feed back into the model, creating a virtuous cycle of improvement.
This model’s power is already evident. Third-party data shows Chinese large models now surpass U.S. models in weekly usage. In emerging markets like Southeast Asia, the Middle East, and Latin America, Chinese open-source models’ market share is growing at 10% monthly. SMEs in these regions can’t afford OpenAI’s expensive APIs, but DeepSeek offers them an affordable alternative.
More importantly, open source is dismantling closed-source monopolies. Previously, AI technology was controlled by a few companies that could set prices and dominate ecosystems at will. Now, anyone can download a top-tier large model and run it on their own servers, with full data control. AI has transformed from a privilege for the few into a public infrastructure.
【The Future Has No “Global Number One”—Only the AI That Suits You Best】
The simultaneous release of DeepSeek V4 and GPT-5.5 marks the global AI industry’s entry into a diversified era.
There will no longer be a single “best in the world” large model or a one-size-fits-all development path. Different models will serve different needs and scenarios.
For ordinary users, this is the best era. Need complex reasoning? Use GPT-5.5. Need to process long documents, write code, or handle daily office tasks? V4-Flash is sufficient and cheap enough to use liberally. No need to pay for capabilities you don’t need.
For enterprises, this means more choices and lower risks. Previously, companies had to rely on OpenAI for AI, which was expensive and lacked data security guarantees. Now, they can deploy open-source models on private servers, fully control data, and fine-tune them for business needs. This alone can reduce intelligent transformation costs for traditional enterprises by over 90%.
For the industry, diversified competition is healthy. If one company monopolized the market and one path dominated the industry, innovation would stagnate. Now, with Chinese and U.S. approaches running in parallel and open-source and closed-source models competing and learning from each other, the industry’s iteration speed will only accelerate.
Of course, we must remain sober about the gaps. In top-tier complex reasoning and scientific computing, U.S. models still lead. Chinese AI still has a long way to go in fundamental research and original innovation. But we shouldn’t underestimate ourselves—in engineering, cost control, and industrial application, China is already a global leader.
April 24 wasn’t about one side defeating the other. It was a reminder: AI should never have just one form. Some look to the stars and explore unknown boundaries; others keep their feet on the ground and make technology benefit everyone.
That’s the future AI truly deserves.
Note: Some data in this article is sourced from publicly available online materials.
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







