Who Has Been 'Shorted' by DeepSeek Again?
 04/27 2026
04/27 2026
 546
546

Overturning the Closed-Source Table, Igniting the Domestic Flame
Should the Collective Dive in Large Models Be Blamed on DeepSeek?
On April 24, Minimax's stock price plummeted in early trading, falling by -12.64% at one point, reaching a low of HK$750. Similarly, Zhipu's stock price dropped by -12.85% after lunch, hitting a low of HK$896.
The reason for the stock price decline is simple: their biggest potential competitor, DeepSeek, is back.
On April 24, China's DeepSeek company officially launched the preview version of its new model series, DeepSeek-V4, and made it open-source simultaneously.
It is reported that the DeepSeek-V4 series includes two MoE model versions: DeepSeek-V4-Pro (hereinafter referred to as DS-V4-Pro) for high-performance research and development, and DeepSeek-V4-Flash (hereinafter referred to as DS-V4-Flash) for cost-effective deployment needs.

Why does every model release by DeepSeek cause stock prices of companies in the AI industry chain to plummet? Who benefits from this release?
01
DeepSeek Breaks the 'Small Yard with High Walls'
What DeepSeek has broken this time is the commercial closed loop (closed loop) that relies on closed-source model API calls for profit.
Over the past two months, the domestic large model sector has undergone a silent shift, with many leading companies as if by prior agreement (inadvertently) taking the same path of closed-source models, API-based capabilities, and value charged per Token.
On March 16, Zhipu AI released GLM-5-Turbo, its first closed-source model since 2025, positioned as a base model deeply optimized for its OpenClaw Agent framework.
The reason for making Turbo closed-source is that GLM-5-Turbo is deeply optimized for Zhipu's own OpenClaw Agent framework. To use the model's best Agent capabilities, one must use OpenClaw, which requires calling Zhipu's API, which is also charged per Token.
At the end of March, Alibaba quickly launched three new Qwen models, all of which were closed-source. The model weights are not available for download and can only be called through the Alibaba Cloud platform.
Alibaba's logic is also clear: the cloud provider's computing power infrastructure is already in place, and models are the value-added services sold on top. Renting my GPUs costs money, and calling my models also costs money—ideally, both sides pay.
Minimax 2.7, which claims to be an open-source model, has also been called 'fake open-source' by overseas community users. The reason is that MiniMax quietly changed the open-source license of the MiniMax2.7 model, replacing the standard MIT license with a Modified-MIT license. The core clause that allowed unrestricted commercial use with only a copyright notice required has been overturned. All commercial uses must now be authorized by MiniMax, with no revenue exemption threshold set.
In other words, 'I've open-sourced it, but you can almost do nothing with Minimax 2.7.'
If you want to create a commercial product with MiniMax 2.7, you need to submit a report first. If you want to integrate it into your company's services, you need to obtain authorization first. Are you a small team with an annual revenue of 1 million? Sorry, no exemption.
After several large model companies have taken these combined actions, users are clearly arranged, but developers and callers find it difficult to jump up and curse 'unethical behavior.'
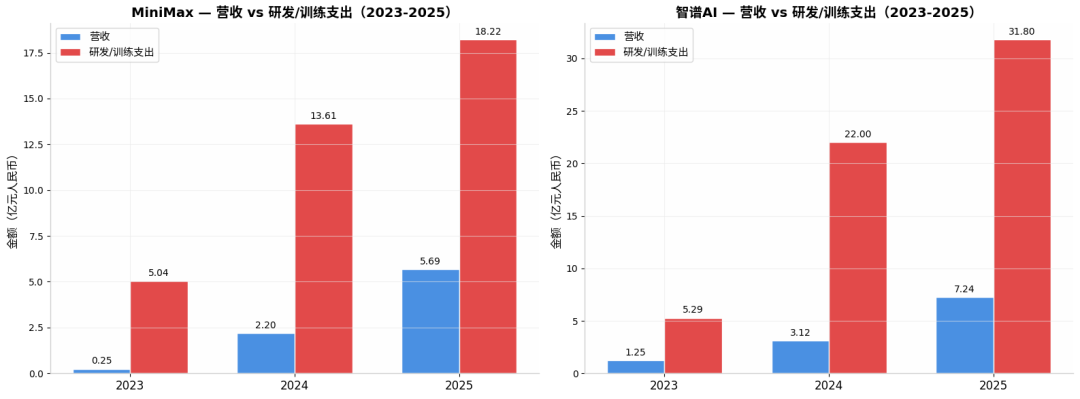
Zhipu's full-year revenue in 2025 was RMB 724 million, a year-on-year increase of 131.9%, which is indeed impressive. However, looking at the expenses: R&D expenditure was RMB 3.18 billion, 4.4 times the revenue. The net loss was RMB 4.718 billion, an increase of 59.5% over the previous year. In other words, for every RMB 1 Zhipu earns, it burns RMB 4.4 on R&D.
Neighboring MiniMax didn't fare much better, with a total revenue of USD 79.038 million (approximately RMB 560 million) in 2025, a year-on-year increase of 158.9%. R&D expenditure was USD 253 million, 3.2 times the revenue. The annual loss was USD 1.872 billion, although most of this was due to changes in the fair value of financial liabilities related to the listing. Even so, for every USD 1 earned, USD 3.2 was spent on R&D.
However, before they could enjoy the 'closed-source' API call meal for long, someone came to overturn the pot.
The weights of the two models in the DeepSeek-V4 preview version were all released on Hugging Face and ModelScope, available for download and modification at will.
To be honest, can DS-V4-Pro outperform GPT-5.1 or Gemini Ultra 3.0 in hard metrics? Not quite yet. The data in DeepSeek's own technical report is clear: it is slightly inferior to Gemini-Pro-3.1 in terms of world knowledge, and there is still a gap between its Agent capabilities and Opus 4.6's thinking mode.
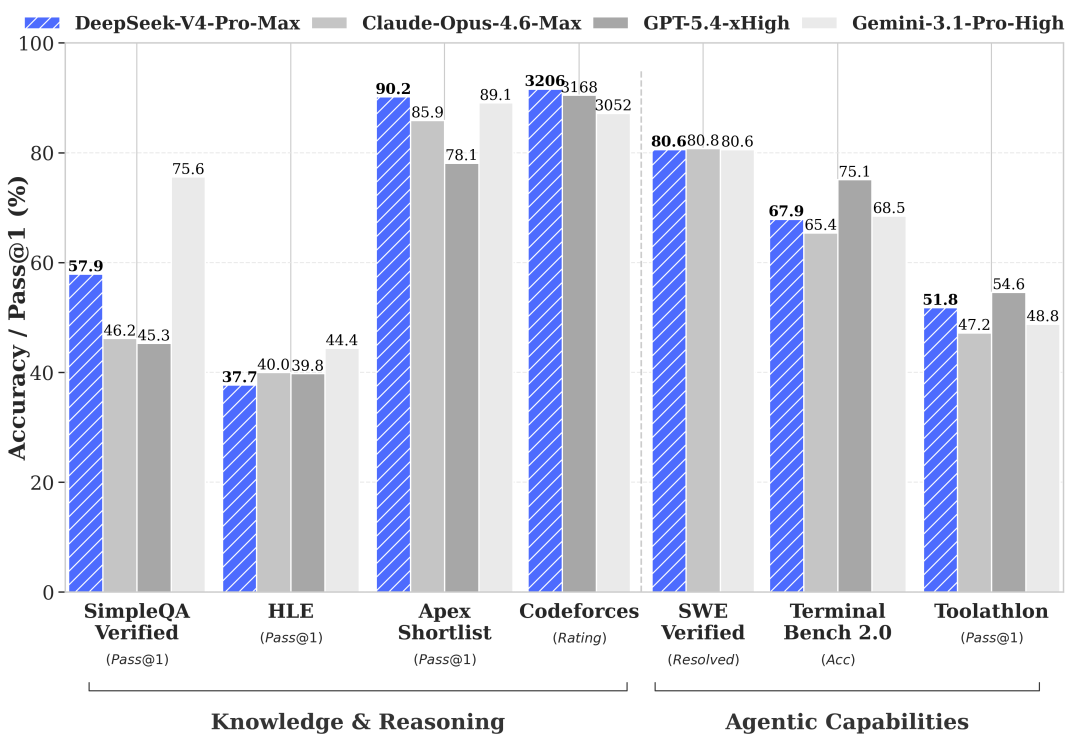
But the problem is, domestic competitors are not taking the path of benchmarking against OpenAI, Google, and Anthropic in terms of performance.
Take Openrouter as an example. Although the performance of Minimax, Kimi, and Zhipu is slightly inferior to Claude's, their prices are mostly in the range of 1/5 to 1/10, focusing on cost-effectiveness. After all, the API call price of GPT-5 is there, and not everyone can afford Gemini's computing power bill. The needs of domestic enterprises are not that extreme—80% effectiveness with 20% of the price is cost-effective enough.
Thus, a tacit commercial path has formed, with everyone silently choosing closed-source models and pricing them in the golden range of 'one order of magnitude cheaper than overseas and more convenient than open-source deployment.'
Enterprise customers calculate and find that renting cards to deploy open-source models has high operational costs, and the effectiveness is not necessarily stable. Calling domestic closed-source APIs is cheaper, hassle-free, and effective enough.
Until DeepSeek arrived, this calculation always made sense.
DeepSeek's approach is actually the 'road back' taken by these large model companies: comparable effectiveness, lower cost, and open-source. No matter how much you charge for your API, my own deployment or purchase cost on third-party platforms is halved or even more, and the effectiveness is on par. You bind frameworks, change protocols, set thresholds, while I offer a one-click download with the MIT license, not even bothering to restrict commercial authorization.
History is always similar. In the previous round, DeepSeek-V2 significantly lowered the price of domestic large models. This round, with V4's million-level context and open-source license, it seems poised to completely block the path of 'closed-source charging.'
How many more competitors will quietly upload their model weights back to Hugging Face next?
02
This Time, DeepSeek Saved HengTech's Life
However, DeepSeek is not just about 'destruction.' The other half of the story lies in the K-line chart of the Hang Seng Tech Index.
Today, with the official announcement of the DeepSeek-V4 preview version, Hong Kong stocks surged.
The first to benefit were chip manufacturing companies, with Hua Hong Semiconductor surging over 17% and SMIC rising over 10%, leading a collective counterattack by the entire chip sector. This was followed by internet AI-related companies, with Lenovo, Alibaba, and Baidu leading the gains, and the Hang Seng Tech Index climbing out of a -1.8% deep pit.
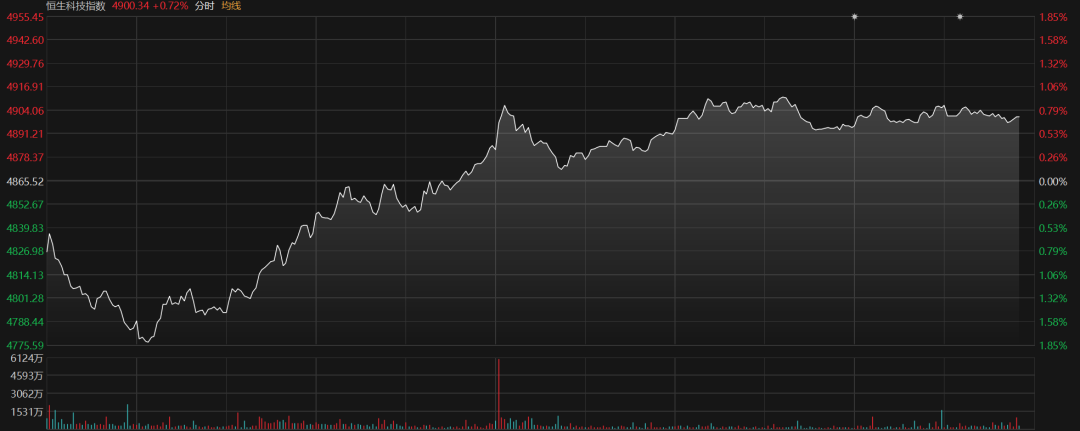
This scene seems familiar.
In early 2025, DeepSeek made its debut, injecting a strong dose of confidence into the Hong Kong stock internet sector, which was then in a valuation trough. That was 'saving a life.' This time, DeepSeek has given HengTech another boost.
But the logic behind the two rallies is fundamentally different.
Last time, the market was publicity stunt the 'AI concept,' with the excitement driven by the fact that a domestic company had finally caught up. This time, the capital's excitement has sunk to the technical foundation, with the chip manufacturing sector seeing the largest gains, followed by application companies with real AI landing scenarios.
Because DeepSeek-V4 has done something even more radical than 'open-source': it actively embraces domestic computing power.
In DeepSeek-V4's technical documentation, there is an inconspicuous line of small print that may be the most important sentence in the entire document: 'Due to limited high-end computing power, the current service throughput of Pro is very limited. It is expected that the price of Pro will be significantly reduced after the batch launch of Ascend 950 supernodes in the second half of the year.'
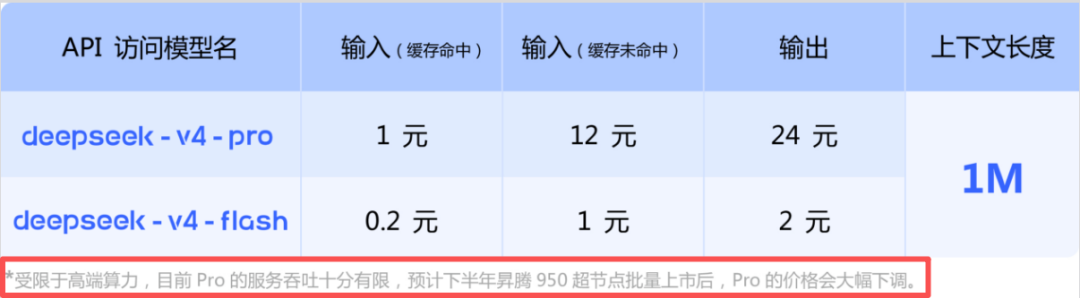
In other words, we're not running at full speed now not because the technology isn't up to par, but because there isn't enough domestic computing power available yet. Once Huawei's Ascend 950 supernodes are launched in large quantities, we can be even cheaper.
This statement is like a shot in the arm for the domestic computing power industry chain, as it once again verifies that domestic chips can indeed run domestic flagship large models.
Huawei also promptly stated that its Ascend supernode series products fully support DeepSeek V4.
According to Huawei, Ascend has always supported DeepSeek series models simultaneously. This time, through close collaboration between the chip and model technologies of both sides, full product support for the DeepSeek V4 series models has been achieved on the Ascend supernode series.
So you see, DeepSeek is not just boosting a single stock.
It is boosting the domestic computing power industry chain, making the capital market believe that domestic chips can not only be manufactured but also run large models.
It is boosting the commercialization prospects of AI applications. When inference costs drop to a fraction of the original, scenarios that 'didn't make economic sense' before start to become commercially viable.
It is boosting the freedom of choice for developers. And this is the most attractive aspect of open-source.
Some say that DeepSeek's pricing strategy for each model release is 'sacrificial.' But from another perspective, this may not be a sacrifice but an acceleration.
Accelerating the process of computing power localization, accelerating the arrival of AI inclusivity, and accelerating the business model (business models) that lie on the closed-source gravy train to be thrown into the trash bin of history.
As for those large companies that are eager to release models but lack the capabilities—DeepSeek has already summed it up with a single sentence on its official website:
'Not seduced by praise, not frightened by slander, following the path, and staying true to oneself.'
The rest is up to you to interpret.
- END -
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







