China's First Open-Source, Systematic Multimodal World Model HY-World 2.0: Performance Rivals Closed-Source Commercial Models
 04/28 2026
04/28 2026
 630
630
Interpretation: AI Generates the Future

Key Highlights
HY-World 2.0, a multimodal world model framework, seamlessly unifies 3D world generation and reconstruction.
Supports diverse input modalities such as text prompts, single-view images, multi-view images, and videos to generate high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes.
Introduces key innovations including HY-Pano 2.0 (panoramic generation), WorldNav (trajectory planning), WorldStereo 2.0 (world expansion), and WorldMirror 2.0 (world composition and reconstruction) to enhance panoramic fidelity, enable 3D scene understanding and planning, and strengthen view generation and prediction capabilities.
Introduces WorldLens, a high-performance 3DGS rendering platform supporting interactive exploration and avatar interaction.
Achieves state-of-the-art performance among open-source methods, remains competitive with closed-source model Marble, and releases all model weights, code, and technical details to facilitate reproducibility.

Multifunctional Applications of HY-World 2.0
Summary Overview
Problems Addressed
The current 3D world modeling landscape generally features a binary separation between generation and reconstruction tasks. Existing solutions typically focus on one area, resulting in generation methods struggling to maintain strict reconstruction accuracy, while reconstruction methods lack generative capabilities to hallucinate unseen regions.
The absence of a comprehensive, multimodal open-source foundational world model to bridge the gap between generation and reconstruction.
Limitations in the existing HY-World 1.0 version regarding panoramic fidelity, 3D scene understanding and planning, and view generation consistency.
Proposed Solution
Introduces HY-World 2.0, the first open-source, systematic multimodal world model that seamlessly integrates "generation" and "reconstruction" functions through a unified offline 3D world model paradigm.
The framework adapts to multiple input modalities such as text, single-view images, multi-view images, and videos, dynamically adjusting its behavior based on available conditions.
Designs a novel four-stage pipeline to drive world generation and upgrades the feedforward 3D reconstruction component to support world reconstruction.
Technologies Applied
Core Modeling: 3D Gaussian Splatting (3DGS) for scene representation and rendering.
Panoramic Generation: HY-Pano 2.0, employing a Multimodal Diffusion Transformer (MMDiT) and cyclic padding with pixel blending strategies.
Trajectory Planning: WorldNav, based on NavMesh, Dijkstra's algorithm, and five heuristic trajectory patterns (regular, orbiting, reconstruction-aware, wandering, aerial).
World Expansion: WorldStereo 2.0, utilizing Keyframe-VAE and camera-guided Video Diffusion Models (VDMs), combined with Global Geometry Memory (GGM) and Spatial Stereo Memory (SSM++) mechanisms, accelerated via Distribution Matching Distillation (DMD).
World Reconstruction: WorldMirror 2.0, employing a unified feedforward Transformer backbone and task-specific DPT decoder heads, introducing optimized strategies such as normalized position encoding, depth-to-normal loss, depth mask prediction heads, sequence parallelism, BF16 mixed precision, and FSDP.
Scene Optimization and Mesh Extraction: Mesh extraction based on Truncated Signed Distance Function (TSDF) volumes and the Marching Cubes algorithm.
Achieved Results
HY-World 2.0 outperforms existing open-source methods and rivals the results of the closed-source model Marble across multiple benchmarks.
Generates high-fidelity, navigable 3D Gaussian Splatting scenes with significantly improved visual quality, geometric consistency, and exploration capabilities.
Enables the generation and reconstruction of 3D worlds from diverse inputs such as text, single-view images, multi-view images, and videos.
WorldNav trajectory planning significantly enhances scene completeness and detail coverage.
WorldStereo 2.0 markedly improves camera control precision and multi-trajectory consistency.
WorldMirror 2.0 achieves state-of-the-art performance in point cloud reconstruction, camera pose, depth and normal estimation, and novel view synthesis, demonstrating excellent multi-resolution generalization capabilities and inference efficiency.
The generated 3D worlds support real-time collision detection and physics feedback, laying the foundation for downstream applications such as gaming, virtual reality, and embodied artificial intelligence.
The project's code, model weights, and technical details have been fully open-sourced, promoting research reproducibility.
Architectural Approach
In the overview of HY-World 2.0 shown in Figure 2 below, its multimodal world model is presented as a four-stage pipeline that simulates the process of understanding, synthesizing, and reconstructing the world. Specifically, the pipeline begins with panoramic generation, converting arbitrary text or image inputs into high-fidelity 360° world initializations. Subsequently, fine-grained trajectory planning is conducted to parse and understand the initialized world and derive optimal, information-rich observation paths. Along these planned routes, generative world expansion utilizes memory update mechanisms to ensure precise camera control and multi-view consistency in the generated keyframes. Finally, robust 3D reconstruction is performed by inputting these generated sequences into WorldMirror 2.0, complemented by tailored 3DGS optimization, thereby achieving world composition for immersive 3D worlds.
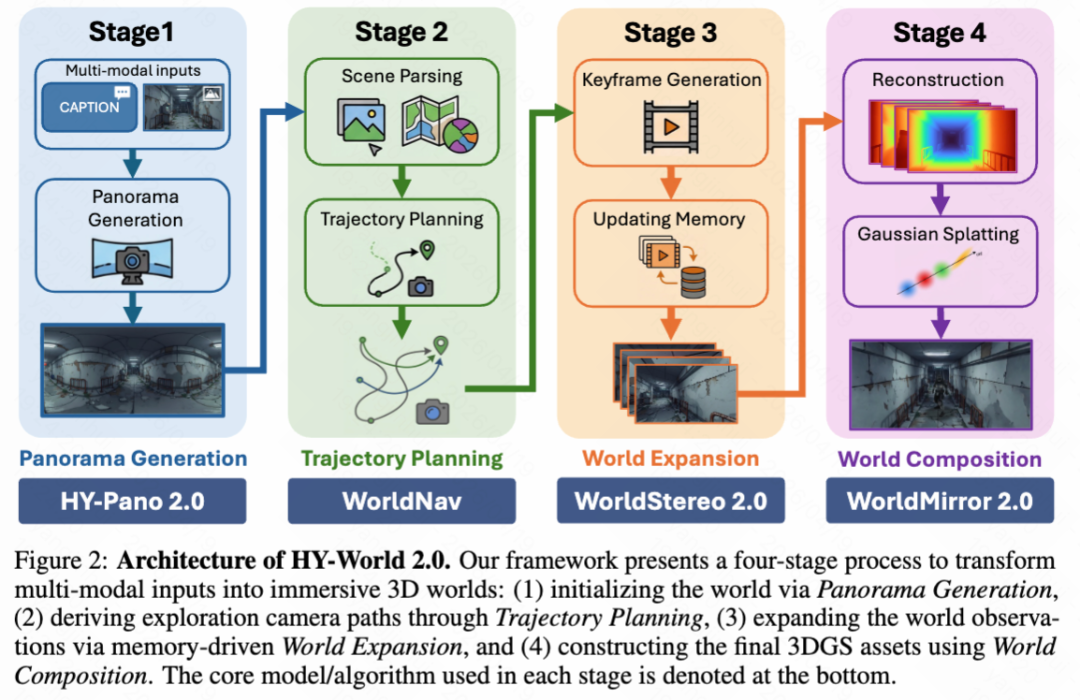
World Generation Stage One: Panoramic Generation
Panoramas capture a complete 360° × 180° Field of View (FoV) from a fixed viewpoint, providing a comprehensive and information-rich representation of the entire scene. Unlike standard perspective images that offer only limited views of the physical world, 360° panoramas preserve global spatial context and complex semantic relationships. As such, this holistic representation is increasingly recognized as the foundation for large-scale 3D world generation, providing the necessary spatial consistency for coherent viewpoint synthesis and immersive virtual exploration.
In this stage, we propose HY-Pano 2.0, aimed at synthesizing high-fidelity panoramas from multimodal conditions including text and single-view images. To achieve this goal, we optimize the generation pipeline from two orthogonal dimensions: (1) implementing an advanced data curation pipeline; (2) introducing a dedicated 360° generation model that implicitly learns the spatial mapping between perspective inputs and panoramic targets in a geometry-free manner.
To construct a solid foundation for high-fidelity panoramic synthesis, our data curation pipeline expands upon the established framework of HY-World 1.0 while significantly increasing the richness and diversity of training data. Specifically, our upgraded dataset integrates two primary data sources: (1) Real-world captures: Includes a large number of high-resolution real-world panoramas to equip the model with realistic lighting, complex textures, and natural structural priors. (2) Synthetic assets: Leverages large-scale synthetic environment datasets rendered through high-end engines such as Unreal Engine (UE). These assets provide precise geometric labels and diverse, imaginative scene configurations that are difficult to obtain in the wild. To ensure data integrity, we implement a rigorous data filtering phase to eliminate low-quality samples, particularly those exhibiting noticeable stitching artifacts or revealing the capture device (e.g., panoramic cameras). This hybrid data strategy effectively broadens the semantic distribution of the dataset and mitigates the domain gap between synthetic and real-world distributions, enabling the model to robustly generalize across complex indoor and outdoor environments.
To achieve synthesis from perspective inputs to high-fidelity panoramas, we go beyond traditional methods relying on explicit geometric warping, a paradigm previously employed in HY-World 1.0. Conventional pipelines typically require precise camera intrinsics (e.g., focal length and field of view) to perform spatial alignment between perspective and Equirectangular Projection (ERP) domains. However, such metadata is often unavailable or inaccurate in real-world scenarios. This bottleneck inherently limits the flexibility of the HY-World 1.0 framework and frequently leads to noticeable projection distortions. To address this issue, we adopt an implicit, adaptive mapping strategy driven by a Multimodal Diffusion Transformer (MMDiT), as shown in Figure 3 below. MMDiT does not rely on explicit camera priors but processes conditional inputs and panoramic targets within a unified latent space. By concatenating conditional image latents with panoramic noise latents into a unified token sequence, MMDiT leverages its self-attention mechanism to autonomously learn the underlying perspective-to-ERP transformation. This purely data-driven approach enables the network to directly establish spatial correspondences within the feature space, allowing it to flexibly hallucinate missing environmental details and maintain global structural consistency, even with uncalibrated and diverse input images.

A common challenge in ERP generation is discontinuity at the left and right edges. To eliminate these boundary artifacts, we introduce a refinement strategy combining cyclic padding and pixel blending, as shown on the right side of Figure 3 above. At the latent level, we apply cyclic padding to latent features, enforcing periodic boundary conditions during the denoising process. The padded latents are decoded into pixel space, where a linear pixel blending strategy is employed along the equirectangular edges. This combined coordination effectively smooths the 360° wrapping transition, ensuring perfectly seamless and structurally coherent panoramic outputs.
World Generation Stage Two: Trajectory Planning
Task Description. Following the synthesis of high-fidelity panoramas (Section 3), the next objective is to derive exploration trajectories that maximize coverage of the navigable space. To connect with the upcoming world expansion stage, we introduce WorldNav, a comprehensive trajectory planning strategy. WorldNav not only generates diverse camera paths to ensure broad viewpoint coverage but also pairs them with precise textual instructions, thereby providing clear guidance for the downstream generation process.
Given panoramic meshes, NavMesh, and 3D semantic landmarks, we design five heuristic trajectory patterns for WorldNav. These trajectories originate from the center of the panorama and aim to comprehensively cover diverse viewpoints while ensuring collision-free movement, as shown in Figure 5 below.
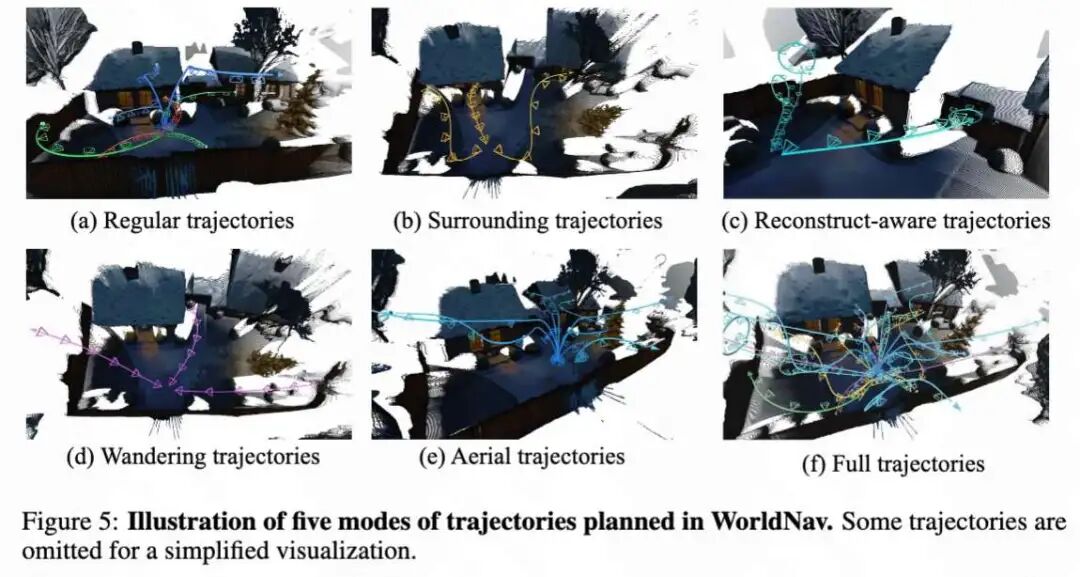
Regular Trajectory. We employ regular trajectories to universally extend visual coverage beyond the fixed origin of the panoramic space, as shown in Figure 5(a) above.
Orbiting Trajectory. To facilitate the visual quality of foregrounds during scene generation, we design trajectories that orbit the most salient objects, as shown in Figure 5(b) below.
Reconstruction-Aware Trajectory. To compensate for gaps in subsequent 3D reconstruction, we introduce iterative reconstruction-aware trajectories that specifically target under-observed regions, as shown in Figure 5(c) above.
Wandering Trajectory. To maximize scene coverage and reach the environmental boundaries of the scene, we propose wandering trajectories, as shown in Figure 5(d) above.
Aerial Trajectory. Finally, we introduce auxiliary aerial trajectories to eliminate remaining blind viewpoints, as shown in Figure 5(e) above.
The trajectory details of WorldNav are shown in Table 1 below.

World Generation Stage Three: World Expansion
Task Description. Building upon high-quality panoramas and broad-coverage camera trajectories, we propose WorldStereo 2.0. As an upgraded version of WorldStereo 1.0 [62], it leverages camera-guided video generation to synthesize a large number of novel views for world expansion. As shown in Figure 6 below, the training process comprises three stages aimed at achieving camera control, memory-based consistency, and efficient inference, respectively.

WorldStereo 2.0 Overview. WorldStereo 2.0 connects camera-conditioned Video Diffusion Models (VDMs) and 3D scene reconstruction by enabling consistent multi-trajectory video generation through geometry-aware memory in keyframe latent space, as demonstrated in Table 2 and Figure 7 below. Specifically, this paper first revisits the limitations of standard Video-VAE, whose spatiotemporal compression often leads to artifacts that degrade downstream reconstruction quality—instead, WorldStereo 2.0 is constructed in keyframe latent space with precise camera control to preserve high-frequency details. This is achieved through a novel Keyframe-VAE, as shown in Figure 9 below.
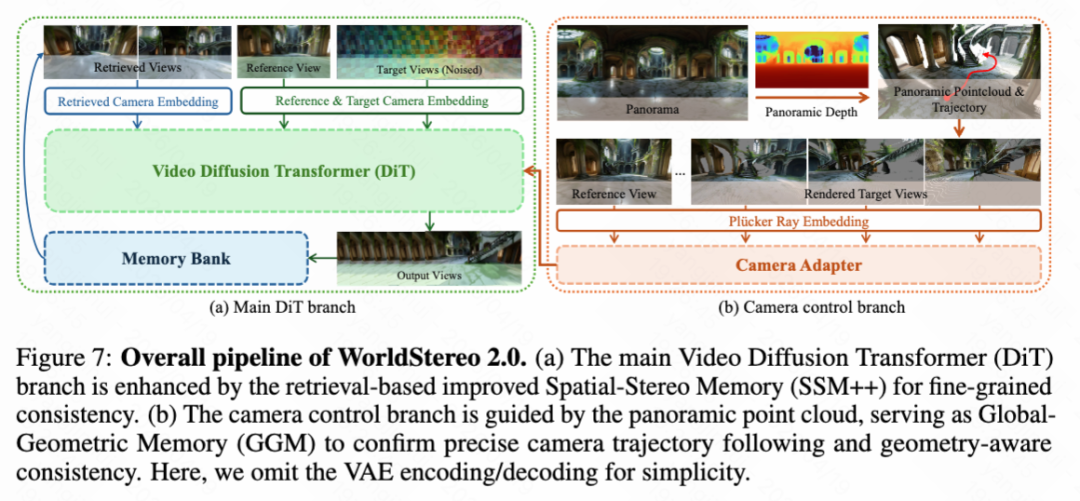
Explicit Camera Control. Following [8, 62], WorldStereo 2.0 is built upon a pre-trained video DiT and integrates a lightweight Transformer-based camera adapter trained from scratch, as shown in Figure 7(b) above. Formally, WorldStereo 2.0 fuses camera Plücker rays and point clouds as complementary camera guidance to enable explicit and precise camera control for subsequent 3D reconstruction. During domain adaptation, this paper uses only point clouds (N ≤ HW, after float filtering) extracted from reference views rather than full-scene point clouds. This paper warps them to each target view to obtain , represented as:
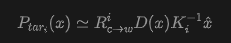
where and denote the camera-to-world matrix and intrinsic matrix for target view , respectively; is the monocular depth estimated for the reference view at pixel , while represents the homogeneous pixel coordinate.
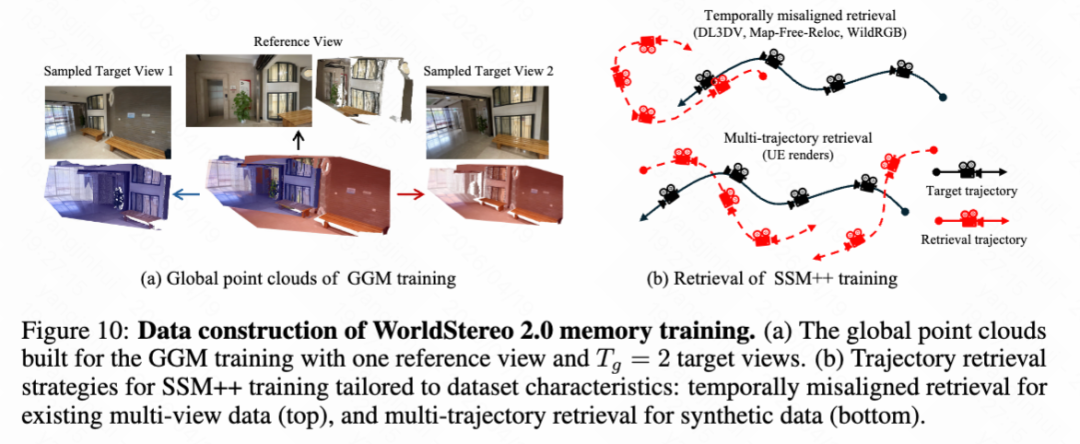
Intermediate Training: Memory Mechanism. The Global Geometry Memory (GGM) renders extended point clouds into videos as a global 3D prior to generate multiple consistent videos, as shown in Figure 7(b) below. Particularly in panoramic scenes, GGM allows WorldStereo 2.0 to internalize 360° environmental structures, significantly improving geometric consistency. This paper fine-tunes WorldStereo 2.0 using videos rendered from extended global point clouds that extend beyond the reference point , represented as:

where denotes additional point clouds randomly sampled from new views, as shown in Figure 10(a) below.
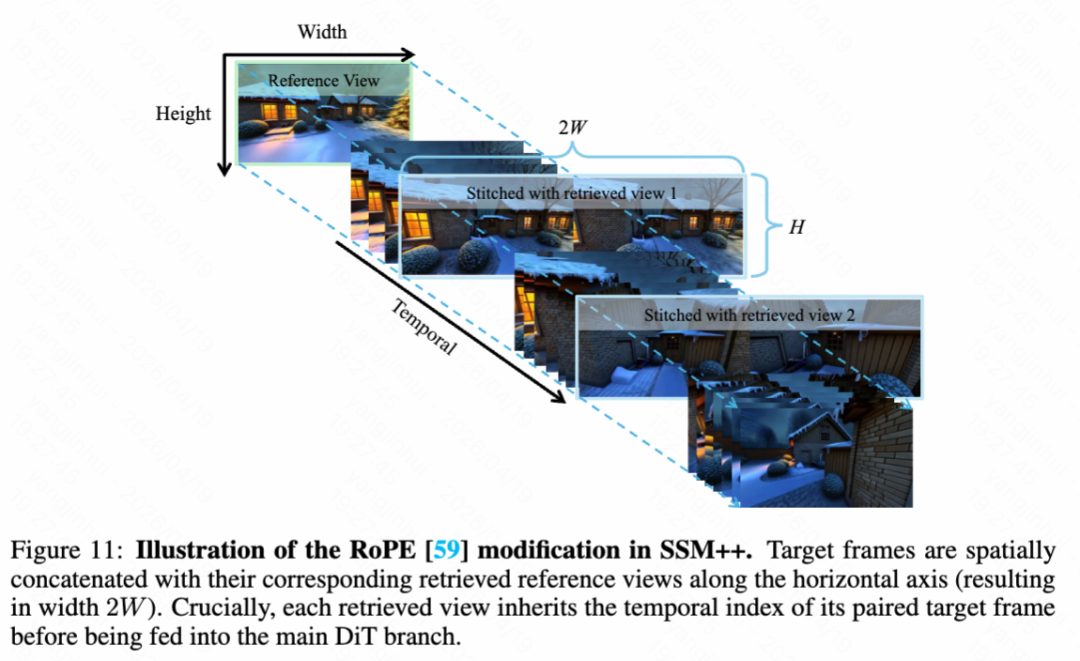
Improved Spatial Stereo Memory (SSM++). In WorldStereo 2.0, this paper enhances this design through SSM++, retaining the core concept of horizontal retrieval stitching while introducing significant improvements. First, this paper abandons the independent memory branch used in WorldStereo and instead integrates retrieved keyframes directly into the main DiT branch (as shown in Figure 7a above). Second, as shown in Figure 11 below, this paper modifies Rotary Position Embedding (RoPE) to accommodate this integration. Each target view is horizontally concatenated with its retrieved counterpart, sharing the same temporal index. Finally, to enhance flexibility, this paper replaces WorldStereo's explicit point map guidance with implicit camera embeddings. Formally, this paper normalizes all input camera poses into a unified world coordinate system and represents them as 7D vectors (quaternions and translations). These vectors are then encoded by a 3-layer MLP into camera tokens, added via zero-initialization to both target and retrieved keyframe features to provide geometric awareness.
Memory Bank and Retrieval Strategy. During intermediate training, this paper adopts different retrieval strategies to accommodate varying data characteristics, as shown in Figure 10(b) above. This paper employs temporal misalignment retrieval for existing multi-view data. Additionally, this paper constructs a synthetic dataset using UE, where each asset has multiple trajectories. For this synthetic data, this paper adopts multi-trajectory retrieval, selecting the most relevant frames from alternative trajectories based on 3D field-of-view similarity.
Memory Augmentation. To mitigate error accumulation that may arise from imperfect point clouds and retrieval generation, this paper employs comprehensive data augmentation during intermediate training to improve the robustness of memory components.
Late Training: Model Distillation. During late distillation, this paper applies modified Distribution Matching Distillation (DMD) to accelerate inference in WorldStereo 2.0. DMD extends the idea of Variational Score Distillation (VSD) by distilling a few-step diffusion student through an approximate Kullback-Liebler (KL) divergence constructed from the difference between a frozen real score function and a trainable pseudo-score function . The update gradient for DMD can be written as:

where denotes student generation given random Gaussian noise and , while represents the forward diffusion process.
World Reconstruction: WorldMirror 2.0
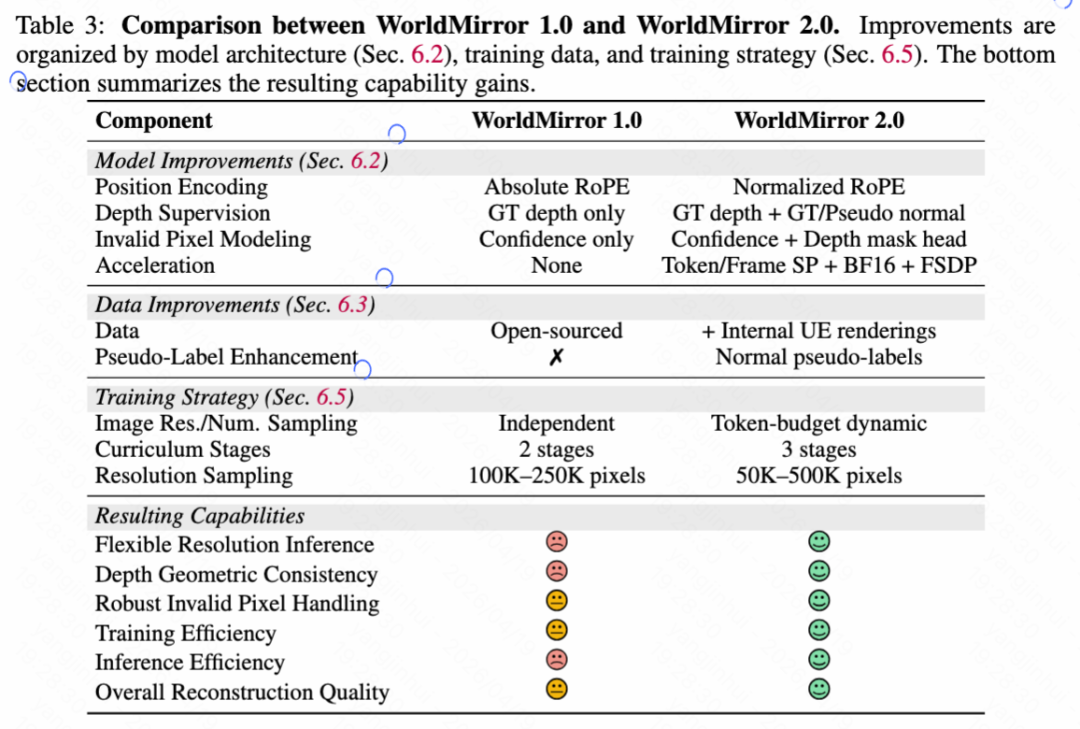
Before detailing the final world composition phase, this paper first introduces the upgraded feedforward 3D reconstruction model WorldMirror 2.0, which serves as a critical bridge between 2D keyframe generation and 3D world composition. World generation aims to synthesize explorable 3D worlds from sparse inputs (e.g., single-view images or text), while world reconstruction focuses on recovering geometrically precise 3D spatial relationships from dense 2D visual observations (i.e., multi-view images or videos). In HY-World 2.0, this paper builds this reconstruction capability upon WorldMirror, a unified feedforward model for comprehensive 3D geometric prediction. This paper addresses three key limitations of WorldMirror 1.0: (1) performance degradation at non-training resolutions, (2) limited depth geometric consistency due to the lack of explicit depth-normal coupling, and (3) excessive memory and latency when scaling to a large number of views. These issues are resolved through improvements in model architecture, training data and supervision, and training strategies (Section 6.5), respectively. Figure 12 below shows the overall model architecture, while Table 3 below summarizes the main differences between WorldMirror 1.0 and WorldMirror 2.0.
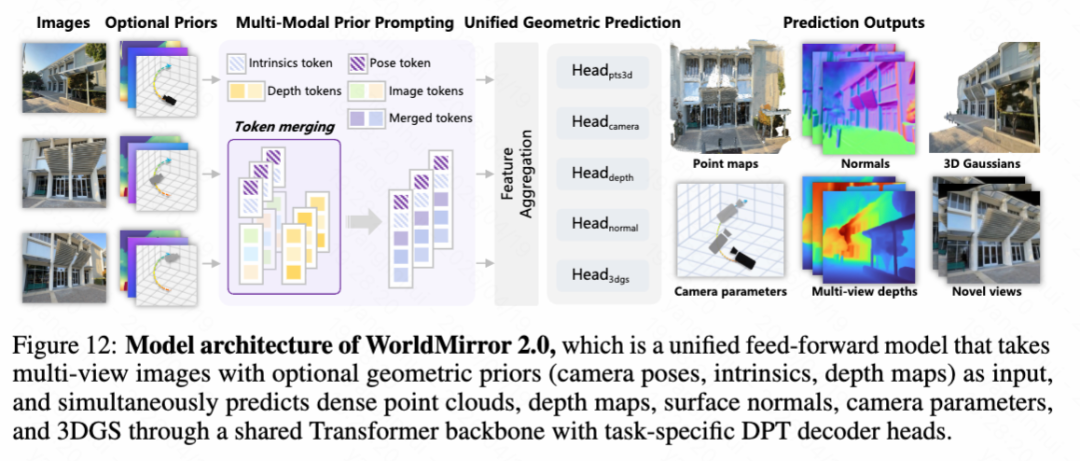
Revisiting WorldMirror 1.0. WorldMirror is a unified feedforward model for comprehensive 3D geometric prediction (see Figure 12 above). Its core design is "any-modality tokenization," which encodes all input modalities, including images, camera poses, intrinsics, and depth maps, into tokens within a unified sequence.
Model Improvements. As summarized in Table 3 above, this paper introduces three key model-level improvements in WorldMirror 2.0: normalized position encoding for flexible-resolution inference, explicit normal-based supervision for depth via a depth-to-normal loss, and a dedicated depth mask prediction head for robust handling of invalid pixels. The depth-to-normal loss is defined as:

where is the predicted depth map, while and are the x and y components of the predicted normal map, respectively. The depth mask prediction head outputs a validity logit for each pixel and is trained using binary cross-entropy loss:

where denotes ground-truth validity labels, and is the set of pixels with known validity.
Data Improvements. This paper expands the training data for WorldMirror 2.0 through two key supplements. First, this paper integrates high-quality synthetic renderings from Unreal Engine scenes, which provide pixel-accurate ground-truth geometry across diverse indoor and outdoor environments. Second, this paper adopts a normal-only pseudo-labeling augmentation strategy for real-world datasets.
Inference Efficiency Improvements. WorldMirror 2.0 introduces three complementary acceleration strategies to enable scalable multi-GPU deployment. First, this paper adopts sequence parallelism at two granularities: token-level parallelism for the Transformer backbone and frame-level parallelism for the DPT decoder head. Second, following VGGT-X [65], this paper applies selective mixed-precision inference by converting most parameters to BF16 while retaining a small subset of precision-critical modules in FP32. Third, this paper employs Fully Sharded Data Parallelism (FSDP) to shard model parameters across multiple GPUs.
Training Strategy Improvements. Token-Based Dynamic Batch Size Adjustment. This paper fixes a maximum token budget per GPU (e.g., 25,000 tokens). In each iteration, this paper first samples an image resolution (pixel count within a configurable range, e.g., 50K-500K) and aspect ratio, then calculates the token count per image . The maximum number of views is then derived as:
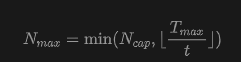
where is the architectural view count upper limit. The actual view count is uniformly sampled from . When the sampled view count is less than , multiple samples are packed into the same GPU to fill the token budget, ensuring strict confinement of token counts per GPU:
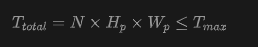
where is the total number of images on one GPU. Multi-Stage Curriculum Learning. In WorldMirror 2.0, this paper further decomposes geometric training into two sub-phases, resulting in a three-stage pipeline: Stage 1 trains all geometric heads using native annotations; Stage 2 introduces the depth-to-normal loss while significantly increasing the proportion of synthetic data; Stage 3 freezes the backbone and all geometric heads, training only the 3DGS head initialized from depth head weights.
World Generation Phase Four: World Composition
Task Description. The input to this phase is defined as a tuple containing the initial panorama (Section 3), its corresponding panoramic point cloud , and all new keyframes generated by WordExpand based on a predefined trajectory (Section 4). The goal of world composition is to integrate these inputs into a unified, navigable 3D representation. This process involves two sequential steps: 1) Point Cloud Extension: Construct a globally aligned point cloud by extending using the generated keyframes. 2) 3D Scene Optimization: Train a 3DGS initialized from the extended point cloud to synthesize a complete high-fidelity 3D world.
Reconstruction via WorldMirror 2.0. This paper first downsamples a subset of frames from the fully generated frame sequence. Subsequently, WorldMirror 2.0 is applied to estimate per-frame depth maps and normal maps for this subset, conditioned on their respective camera poses as geometric priors:
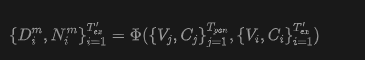
where denotes the WorldMirror 2.0 network.
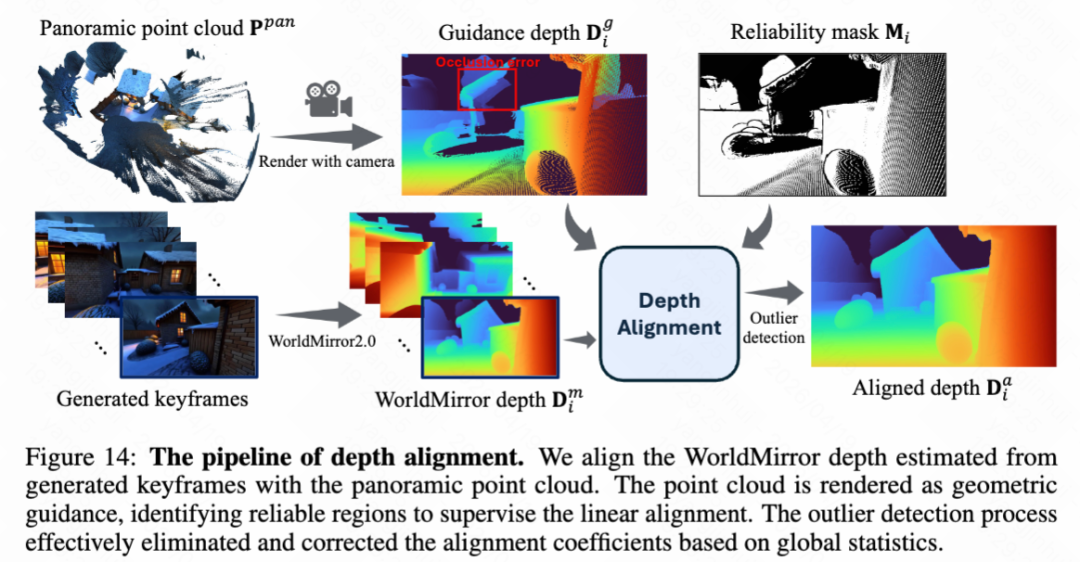
Depth Alignment. This paper proposes a robust alignment strategy that leverages the panoramic point cloud as geometric guidance to correct WorldMirror depth into aligned depth maps . Formally, this paper renders from the viewpoint of to obtain sparse guidance depth , as shown in Figure 14 below. The alignment process is formulated as:
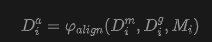
where denotes the reliability mask for view , indicating valid overlapping regions where alignment should be enforced. This paper defines as the intersection of multiple empirical masks:
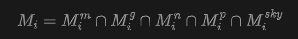
3D scene optimization. Growth and densification. This paper segments the initial point cloud into sky and scene subsets, denoted as and , respectively. The standard growth strategy is applied only to , achieving necessary densification in texture-rich regions while strictly preventing floating artifacts in the sky. This paper integrates MaskGaussian. Specifically, for the i-th Gaussian point, a binary mask is sampled from learnable mask logits via Gumbel-Softmax. This mask is then integrated into a tile-based rasterizer through a mask rendering scheme. For a given pixel , the rendered color and transmittance evolution are reformulated as:
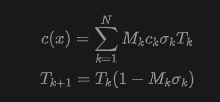
where denotes opacity, and is the transmittance of the j-th Gaussian point accumulated in depth order. To encourage sparsity, the squared loss regularizes the mean mask activation:
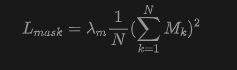
Optimization and loss. For the i-th training view, the 3DGS renderer generates an RGB image and a depth map . The corresponding surface normal is analytically derived from the normalized spatial gradient of . The photometric objective is defined as:

where the ground truth image is sampled from panoramas and generated keyframe-segmented view clusters. To enforce geometric consistency, this paper introduces a geometric loss:
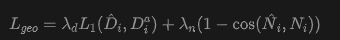
where denotes pixel-wise cosine similarity. Thus, the total 3DGS training objective is given by:
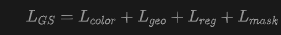
Mesh extraction. To support downstream applications such as collision detection and physics simulation, this paper further extracts a mesh from the optimized 3DGS representation. Specifically, RGB images and depth maps are rendered from all training views and integrated into a truncated signed distance function (TSDF) volume. The final mesh is extracted via the Marching Cubes algorithm [46].
Experimental Summary Results: Multimodal World Creation—Results and Analysis of HY-Pano 2.0
This paper qualitatively and quantitatively compares HY-Pano 2.0's panoramic generation with several state-of-the-art methods in text-to-panorama (T2P) and image-to-panorama (I2P) tasks. For T2P, this paper compares with DiT360, Matrix3D, and HY-World 1.0. For I2P, this paper compares with CubeDiff, GenEx, and HY-World 1.0.
Quantitative results. The quantitative comparison for T2P and I2P tasks is shown in Table 4 below. Generated panoramas are evaluated using multiple complementary metrics. CLIP-T (T2P) and CLIP-I (I2P) measure text-image and image-image alignment, respectively. Q-Align provides perceptual quality (Qual) and aesthetic (Aes) scores based on large multimodal models aligned with human ratings. As shown in Table 4 below, HY-Pano 2.0 achieves the best scores on most metrics for both tasks. These results demonstrate that HY-Pano 2.0 adheres more strongly to input signals (text prompts or reference images), exhibits higher fine-detail quality, and improves aesthetic scores compared to previous methods.
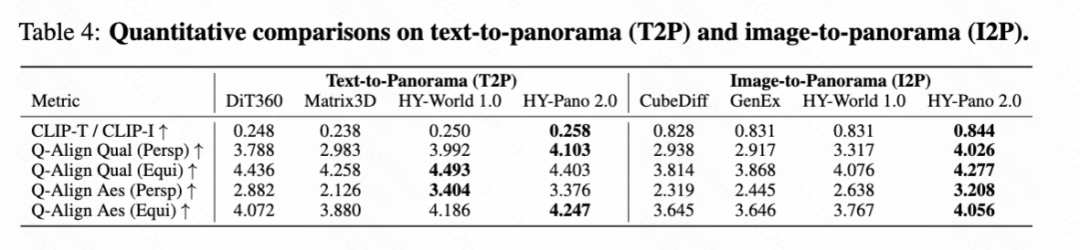
Qualitative results. First, some panoramas generated conditioned on image and text inputs are presented in Figure 16 below. Then, qualitative comparisons for T2P and I2P are shown in Figures 17 and 18 below, respectively. Compared to existing methods, panoramas generated by HY-Pano 2.0 exhibit more structurally coherent layouts, demonstrating reasonable spatial arrangements and consistent geometric structures across the full 360° field of view. Notably, it generates finer details, including sharper textures, clearer object boundaries, and richer high-frequency content, resulting in more realistic and visually appealing panoramas.



Results and Analysis of WorldNav
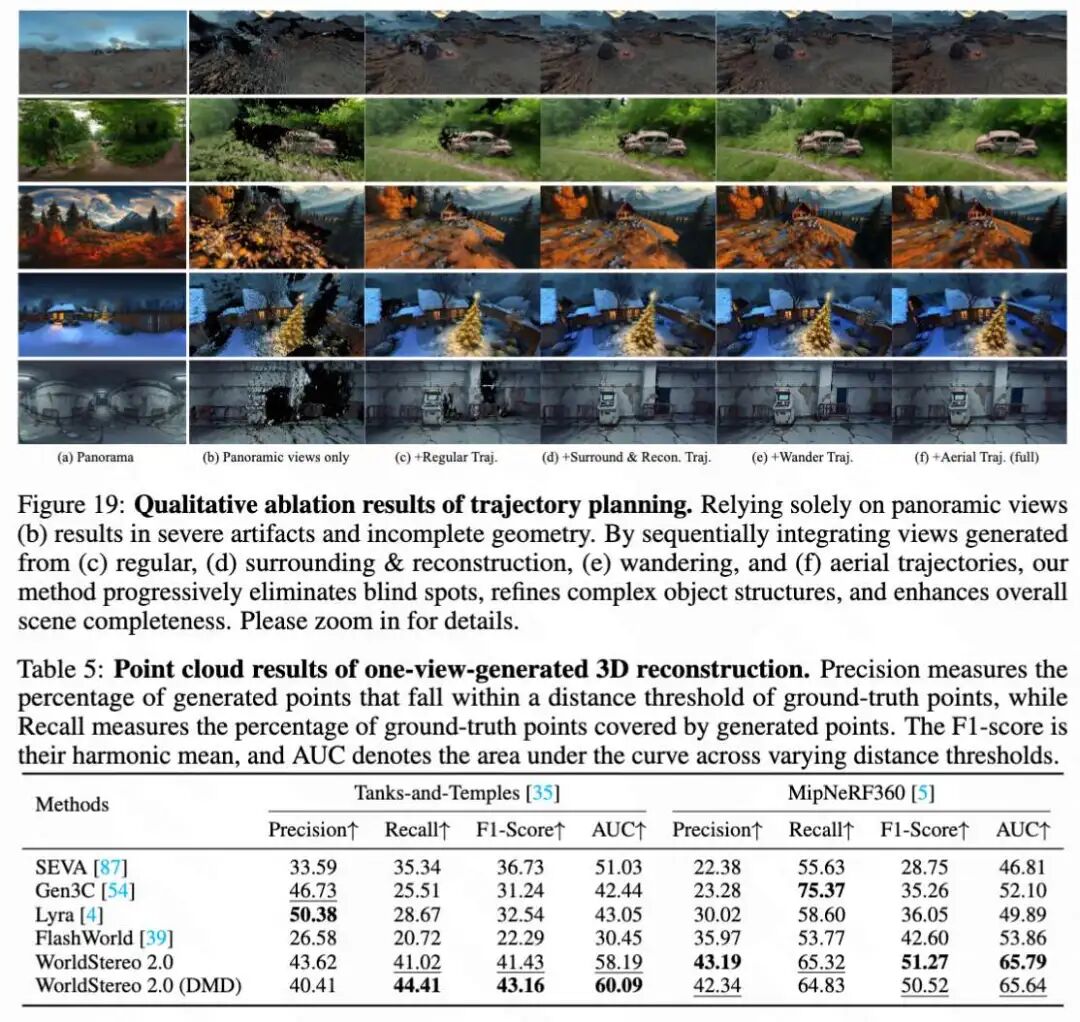
This paper conducts qualitative comparisons in Figure 19 below to intuitively demonstrate the necessity of each trajectory planning component. Training 3DGS solely on panoramic views (Figure 19b) inevitably leads to substantial geometric holes and poor rendering quality. By sequentially integrating views from different trajectories, scene completeness progressively improves. The 3D reconstruction point cloud results generated from single views are shown in Table 5 below, which evaluates point cloud precision, recall, F1-score, and AUC for various methods on the Tanks-and-Temples and MipNeRF360 datasets, where WorldStereo 2.0 and its DMD variant excel on most metrics. The trajectory details of WorldNav are shown in Table 1 below, which outlines the maximum numbers and characteristics of five trajectory modes: regular, orbit, reconstruction-aware, wandering, and aerial.
Results and Analysis of WorldStereo 2.0
Results of camera control capabilities. This paper quantitatively evaluates WorldStereo 2.0's camera control capabilities in Table 6 below, while conducting an ablation study in Table 7 below. Both evaluations use 100 out-of-domain images with challenging trajectories selected from [15]. WorldStereo 2.0 outperforms all video-based competitors with the lowest error rates across all camera metrics. Furthermore, this paper provides qualitative comparisons in Figure 8 below, further supporting this conclusion, which demonstrates that Keyframe-VAE exhibits better appearance consistency and fidelity in reconstruction and novel view generation compared to Video-VAE.
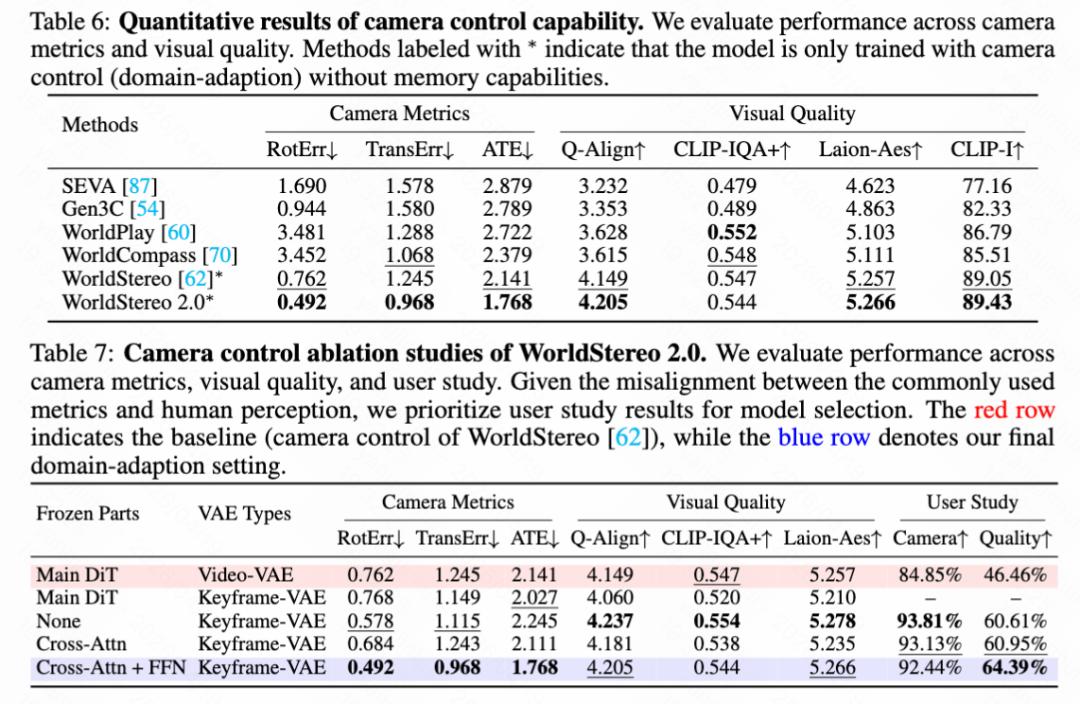
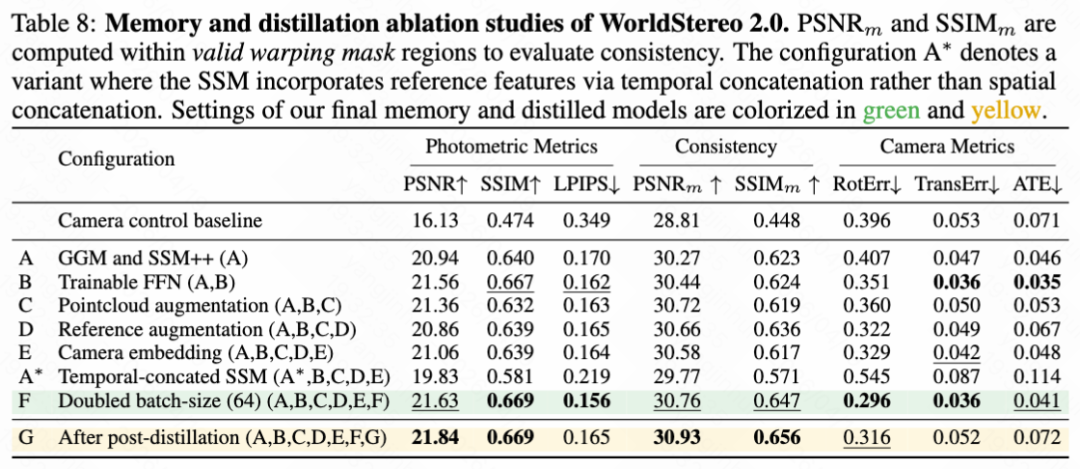
Ablation study of memory training and distillation. This paper comprehensively evaluates memory training and post-distillation in Table 8 above. Integrating GGM and SSM++ (Configuration A) significantly improves photometric quality and multi-trajectory consistency. Finally, after applying DMD post-distillation (Configuration G), the model not only maintains comparable camera control capabilities but even slightly improves photometric and consistency metrics.
Results and Analysis of World Composition
Reconstruction and alignment. Although the preceding sections confirm the effectiveness of WorldMirror 2.0's point cloud expansion under known camera poses, this paper further evaluates the overall composition pipeline against the contemporary world reconstruction method video2world in Figure 20 below. To ensure fair comparison, both methods are evaluated on 300-view images generated by WorldStereo 2.0. As shown in Figure 20 below, although video2world generates impressive point clouds via iterative closest point (ICP) through feature matching, the process is inherently difficult to parallelize, resulting in computational overhead of approximately 5 hours per scene. In contrast, this paper's lightweight linear alignment fully leverages camera pose priors, achieving comparable reconstruction quality in under 2 minutes.

Gaussian radiance fields. This paper conducts an ablation study of each component in the proposed 3DGS pipeline across 10 scenes, evaluated on a 20-view validation set (Table 9 below). Integrating MaskGaussian resolves this trade-off: redundant Gaussian points in low-frequency regions are pruned, reducing their count by 73.7% (from 5.254M to 1.383M), while PSNR only decreases by -0.14 dB.

Full Results and Comparison with Marble
Explorable and Interactive Worlds. As shown in Figure 21 below, HY-World 2.0 generates comprehensive multimodal 3D assets, including panoramas, aligned point clouds for 3DGS initialization, high-fidelity 3DGS renderings, and extracted geometric meshes. More importantly, these rich 3D representations transcend static visualization, serving as the foundational environment for explorable and interactive 3D worlds (see Figure 22 below), which demonstrates users interactively exploring the 3D world generated by HY-World 2.0, including virtual agent navigation and real-time collision detection.


Comparison with state-of-the-art. This paper compares the method with the closed-source commercial world model Marble. Comparisons are conducted under two settings: using identical panoramic inputs (Figure 23 below) and using identical perspective conditions (Figure 24 below). In contrast, this paper's method obtains high-fidelity results that strictly adhere to the provided conditions. Furthermore, this paper's generations outperform Marble in detail preservation and geometric consistency across novel views.


Runtime analysis. The overall runtime of HY-World 2.0 is evaluated on an NVIDIA H20 GPU, as detailed in Table 10 below, which lists the time costs for each stage, including panoramic generation, trajectory planning, world expansion, reconstruction and alignment, and 3DGS. By integrating systematic efficiency optimizations, the end-to-end pipeline for generating complete 3D worlds is accelerated, requiring only 10 minutes.

Reconstructing the World from Multi-View Images or Videos
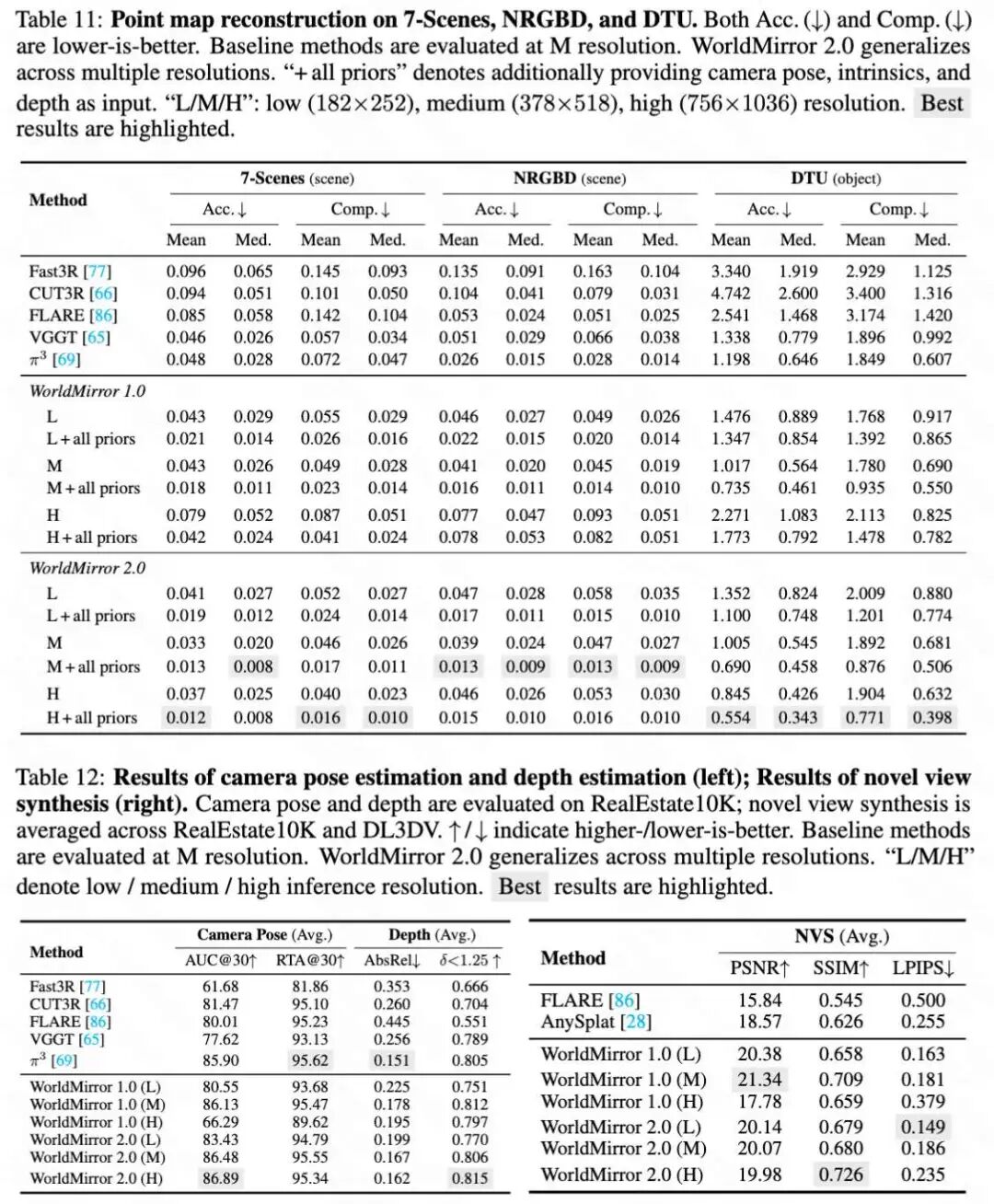
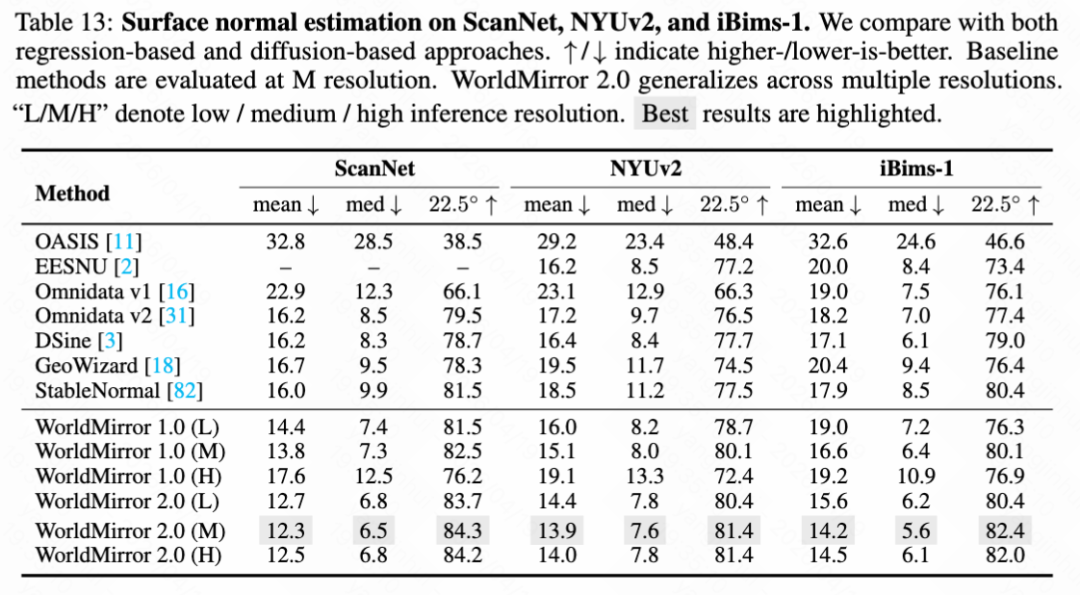
This paper evaluates WorldMirror 2.0 as a standalone reconstruction foundation model on a comprehensive benchmark covering point map reconstruction (as shown in Table 11 below), camera pose estimation, depth estimation, novel view synthesis (as shown in Table 12 below), and surface normal estimation (as shown in Table 13 below). All tasks are assessed at three inference resolutions: low (189×259), medium (378×518, the default setting for WorldMirror 1.0), and high (756×1036), to verify the resolution generalization capability achieved through normalized position encoding.
Results and Analysis of WorldMirror 2.0
Point Map Reconstruction. This paper evaluates point map reconstruction on scene-level datasets (7-Scenes, NRGBD) and object-level datasets (DTU), following the same sequence mapping as [69]. As shown in Table 11 below, WorldMirror 1.0 already surpasses all baselines at medium resolution. WorldMirror 2.0 demonstrates further improvements at each resolution. Integrating geometric priors brings additional gains.
Camera Pose, Depth, and Novel View Synthesis. In Table 12 above, this paper jointly reports camera pose estimation and depth estimation on RealEstate10K, as well as the average novel view synthesis on RealEstate10K and DL3DV. For camera pose, WorldMirror 2.0 improves AUC@30 over WorldMirror 1.0 at each resolution. For depth, WorldMirror 2.0 consistently reduces AbsRel. For novel view synthesis, WorldMirror 2.0 maintains stable performance across different resolutions.
Surface Normal Estimation. Following [3], this paper evaluates surface normal estimation on ScanNet, NYUv2, and iBims-1. As shown in Table 13 below, WorldMirror 2.0 achieves the best results on all three benchmarks at medium resolution, surpassing specialized single-task methods.
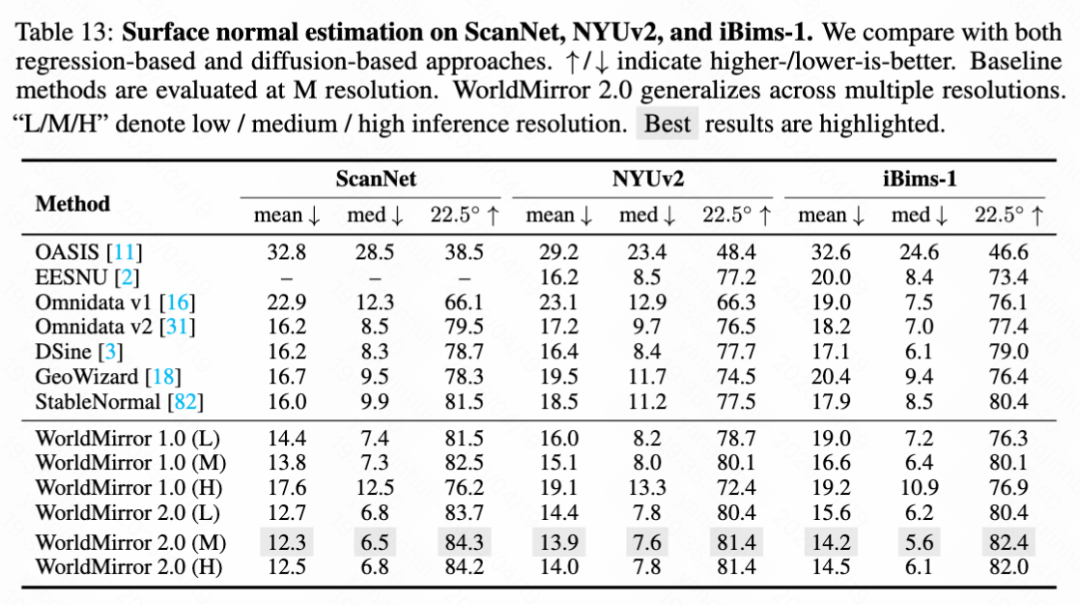
Qualitative Results. This paper presents visual comparisons between WorldMirror 1.0 and 2.0 in Figures 25 and 26 below. As shown in Figure 25, WorldMirror 2.0 generates sharper, geometrically more coherent surface normals. The figure intuitively demonstrates that WorldMirror 2.0 has finer structural details and higher consistency than WorldMirror 1.0 in terms of surface normals and reconstructed point clouds. Figure 26 further examines multi-resolution robustness, showing that WorldMirror 1.0 exhibits severe geometric degradation at high resolution, while WorldMirror 2.0 maintains stable and coherent reconstruction across all tested resolutions.

Evaluation at Inference Time
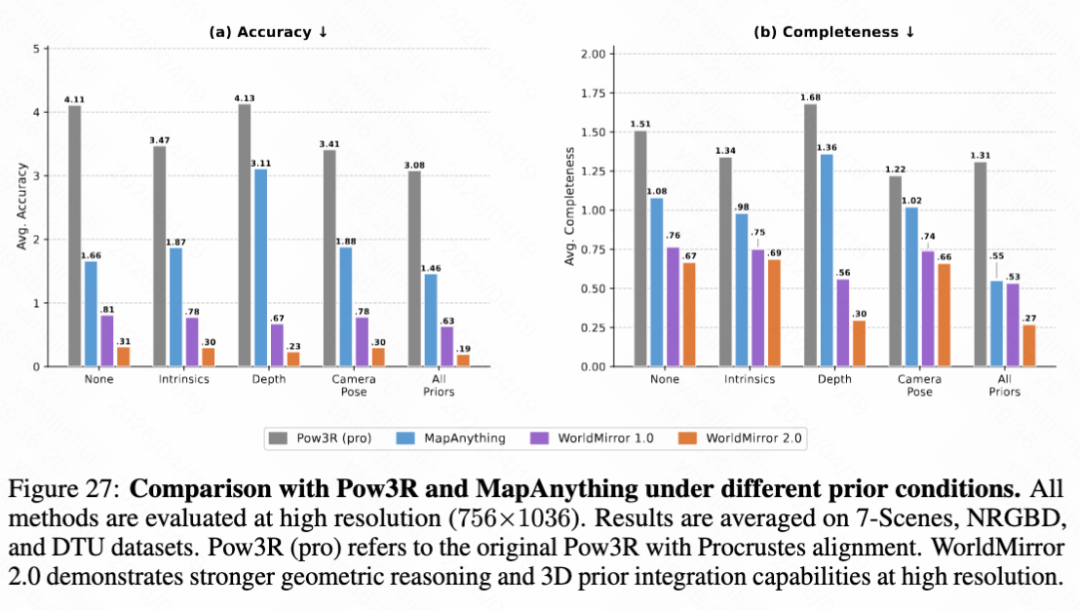
Geometric Prior Injection. A notable feature of WorldMirror is its ability to flexibly integrate geometric priors. This paper compares the performance of WorldMirror 1.0 and 2.0 with prior-guided methods Pow3R and MapAnything under different prior conditions at high resolution (as shown in Figure 27 below). WorldMirror 2.0 consistently outperforms all alternatives, showing the greatest improvement under camera conditions and all prior settings.
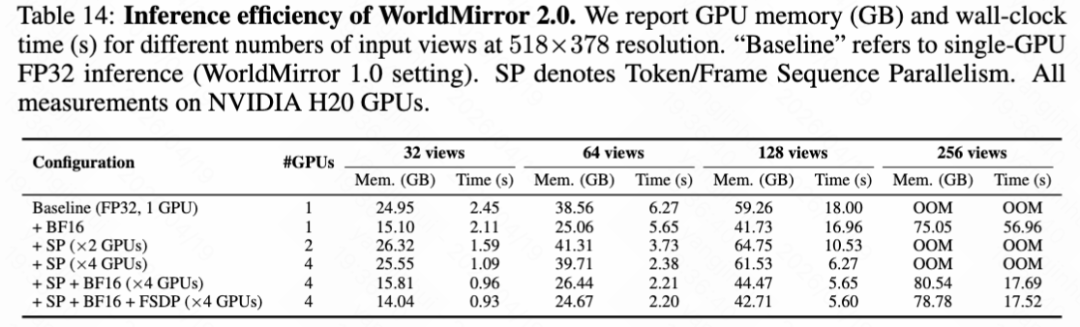
Inference Efficiency. This paper benchmarks the inference efficiency optimizations introduced for WorldMirror 2.0 in the preceding text. Table 14 below reports the per-GPU memory consumption (GB) and wall-clock inference time (seconds) for different numbers of views at a resolution of 518×378 on an NVIDIA H20 GPU. The full combination of SP, BF16, and FSDP across 4 GPUs achieves the best trade-off.
Conclusion
HY-World 2.0 is a comprehensive multi-modal world model framework that bridges the long-standing gap between 3D world generation and reconstruction. By dynamically adapting to diverse input modalities—ranging from sparse text and single images to dense multi-view videos—our framework establishes a unified paradigm for offline 3D world modeling. To achieve this, we introduce a four-stage pipeline. We upgrade panoramic generation (HY-Pano 2.0) to achieve high-fidelity world initialization and design semantic-aware trajectory planning (WorldNav) to guide optimal, collision-free routes for scene exploration. Additionally, we significantly upgrade generative world expansion (WorldStereo 2.0) by operating in a keyframe latent space with spatially consistent memory. Finally, we compose the world through an enhanced 3D reconstruction foundation (WorldMirror 2.0) to generate geometrically accurate and navigable 3DGS assets. We also propose a high-performance 3DGS rendering platform (WorldLens) to enable interactive exploration of 3D worlds with support for character and lighting control. Extensive evaluations demonstrate that HY-World 2.0 achieves state-of-the-art performance among open-source methods, with visual quality, geometric consistency, and exploration capabilities highly competitive with leading closed-source commercial models.
References
[1] HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







