Price Surge Across the Board, Yet DeepSeek Chooses to Disrupt the Market
 04/28 2026
04/28 2026
 486
486

Have you noticed? Less than 48 hours after the release of DeepSeek V4 last Friday, before users even had the chance to thoroughly test it out, the official team dropped another bombshell.
The Pro version API is now available at a limited-time 60% discount, with the promotional period extending until May 5th. Immediately following this, the input cache hit prices for both the Pro and Flash versions were drastically reduced to just one-tenth of their original cost.
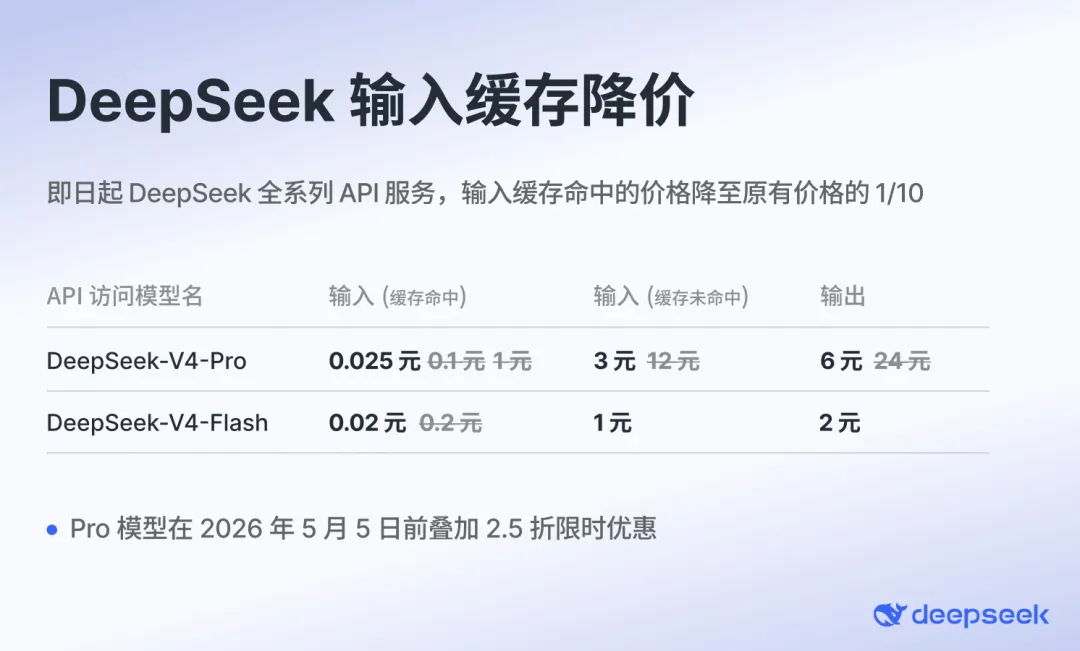
The initial reaction was one of bewilderment.
Since March, whether it's OpenAI and Anthropic abroad or Zhipu, Alibaba, and Tencent at home, AI products have seemed impervious to the concept of 'price reduction.' Models keep expanding in size, API prices keep climbing, benchmark scores keep soaring, and users are left stunned when the bills arrive. In just a month, the industry reached a staggering consensus: AI should keep getting pricier. To access superior intelligence, you must pay a premium. Yet, DeepSeek V4 Pro's pricing is now nearing the lower bounds of domestic AI products, and the Flash version is even cheaper than older models. Continuing to slash prices at this juncture defies conventional logic.
The second reaction was one of astonishment.
Input cache hit prices plummeted to 0.025 yuan—calling this 'nearly free' in the era of intelligent agents is hardly an overstatement. Moreover, this cache hit price reduction is permanent, not a fleeting promotion. A natural question arises: Is this just a semantic trick? You need a cache hit to benefit from this price, but how often does that truly occur in practice? Real-world testing provides the answer: This is no gimmick—it's genuinely affordable.
While domestic and international competitors are still cautiously contemplating pricing adjustments of a few dollars, DeepSeek directly moved the decimal point one place to the left on its price list. To developers, this resembles charity. To competitors, it looks like a price war. But neither perspective captures the essence.
This is about market disruption. It's a cost-based annihilation where the outcome was predetermined long ago.
The reason DeepSeek can afford such aggressive pricing adjustments amid compute shortages and talent turnover lies concealed in its 58-page technical report. It no longer needs to burn money to capture market share. Instead, it's leveraging a completely refactored (reconstructed) underlying architecture to drive reasoning costs for large models to unprecedented lows.
01
The Industrialization of Memory
Delving into the technical report, one figure stands out: In million-token context scenarios, V4's KV Cache usage is merely 10% of its predecessor V3.2's. The origin of this one-tenth pricing strategy lies here.
To elucidate this, we must begin with KV Cache. Today's interactions with large models are far more intricate than a few years ago—it's common to attach dozens of pages of documents as references. The model must retain all this extensive content to answer questions accurately. This memory is KV Cache.
The issue is that memory from lengthy documents is both complex and cumbersome. A million-word book may appear slim, but the model requires dozens of costly GPU memory cards just to store that memory. The expense of implementing long context windows has remained persistently high.
Some choose to accept this reality. DeepSeek opted for a different path: Overhauling traditional memory methods.
The first innovative approach is called compressed sparse attention. In conventional attention mechanisms, each token corresponds to a set of KV vectors. Compressed sparse attention calculates compression weights through learnable linear projections and Softmax functions, merging KV states from multiple consecutive tokens into a single entry along the sequence dimension.
In layman's terms: Previously, models needed to recall user input verbatim. Now they learn to summarize paragraphs, condensing the core meaning of every few dozen words into one sentence. In V4 Pro, with a compression rate set to 4, this step alone reduces cache size by 75% along the sequence length.
The second method is even more radical: heavy compression attention. It attempts to cram token memories much larger than conventional compression windows into a single entry, performing global dense attention calculations without sparse retrieval. The trade-off is increased computational overhead, but the reward is astonishing compression rates. In V4 Pro, this layer achieves a compression rate of 128. Paragraph summarization isn't sufficient—it directly extracts key concepts, condensing entire pages into a few keywords.
However, aggressive compression comes at a cost. Fine-grained local information and strict causal relationships are sacrificed in this brute-force approach. DeepSeek's solution is to incorporate an independent branch into the attention mechanism: a sliding window with a size of 128. The most recent 128 tokens remain uncompressed, ensuring precise perception of recent context. For cache management, a heterogeneous KV Cache architecture independently handles uncompressed tokens as a separate state, maintaining answer quality under high compression ratios.
One more crucial step cannot be overlooked: mixed-precision storage and disk reuse. Among KV Cache's feature dimensions, only the final 64 dimensions used for rotary position encoding retain BF16 precision—all others are quantized to FP8 format. This halves the physical storage requirements.
After these layered reductions, cache size has been compressed by over 90%. Consequently, V4 can directly store these highly compressed KV entries on affordable solid-state drives. When users request long-text processing, the system retrieves compressed cache directly from the hard drive, bypassing expensive GPU prefilling calculations while dramatically conserving HBM memory.
A tenfold cost reduction naturally follows.
This epitomizes the industrialization of memory. Previously, memory resembled handcrafted workshops where every detail had to be preserved intact. Now memory has transformed into an assembly line with standardized processes, compression algorithms, and tiered storage. Redundancy is eliminated; essence is retained.
02
Structural Slimming of Compute Power
Beyond memory usage, the number of floating-point operations during inference calculations is the primary metric for measuring compute consumption. Under 1M-length contexts, V4 Pro's per-token inference FLOPs are just 27% of its predecessor V3.2's.
The core of this reduction lies in a dynamic sparse selection mechanism. Even with compressed caches, calculating attention scores between a query vector and tens of thousands of compressed KV vectors remains computationally intensive. DeepSeek's approach: For each current query vector, the model maps it to a low-dimensional latent space through downsampling and upsampling matrices, generating an index Query vector. This index vector calculates rough scores with historically compressed blocks, retrieving only the top 1,024 highest-scoring compressed KV entries per token generation before proceeding to core attention calculations.
In traditional attention mechanisms, decoding computational complexity grows linearly with context length. Compressed sparse attention forcibly truncates this complexity to constant-time operations. When context length reaches one million, this constant-time calculation becomes nearly negligible. This structural innovation explains the 27% figure.
Simultaneously advancing is systematic precision compromise. V4 not only quantizes expert weights in its Mixture of Experts (MoE) architecture to FP4 precision but also, for the first time, incorporates FP4 deep into the core of attention calculations. Query and Key vector activation caching, loading, and matrix multiplications all operate at FP4 precision. During quantization-aware training, index scores also drop from FP32 to BF16. At the hardware level, FP4 precision offers twice the throughput of FP8. This extremely low-precision computing doubles attention calculation speed for long contexts while maintaining 99.7% KV retrieval recall.
This 99.7% recall rate warrants reflection. It means compute power has decreased while precision remains virtually intact. People instinctively assume cheaper means worse. DeepSeek proves with data that this equation doesn't always hold. In the engineering realm, redundancy and margins don't inherently equate to superior results.
03
Extreme Exploitation of the Underlying Layer
Viewing the complete algorithm optimizations from top to bottom, one layer deeper lies DeepSeek's consistent expertise: Thorough exploitation of underlying infrastructure. This optimization reaches 'frugal' levels but constitutes the real source of cluster throughput improvements and pricing advantages.
V4 Pro boasts 1.6 trillion parameters, second only to Kimi series models domestically. But this creates challenges: In MoE architectures, cross-node communication for expert parallelism becomes a bottleneck as parameters expand. The DeepSeek team utilizes its self-developed TileLang language to craft underlying fused operators, dividing MoE layer computations into waves. Once one wave of expert communication concludes, GPUs immediately commence computation while the network layer simultaneously initiates parallel transmission of the next wave's tokens. This pipeline-style overlapping scheduling accelerates routine workloads during inference by 1.50 to 1.73 times, pushing hardware utilization to its limits. The amortized compute depreciation cost per request is further diminished.
There's also a unique optimization for intelligent agent application scenarios. When AI models perform complex tasks, they often need to run an additional small model first for intent recognition or tool invocation judgments. V4's solution is more ingenious: It appends dedicated special tokens to mark input sequences. Since the model natively supports multi-level reasoning and long/short-term memory management, it can directly reuse the main model's KV Cache to execute these auxiliary tasks in parallel. The maintenance costs of extra models and redundant prefilling computations are eliminated together.
The significance of this step extends beyond saving a few servers. It points to a philosophical division of labor: The boundary between tools and intent becomes internalized within the model. Functions that previously required external auxiliary systems are now absorbed into the model's own structure. This is compression, but also unification.
04
Transfer of Pricing Power
Hybrid compressed attention combined with low-cost hard drive caching equals one-tenth cache hit pricing. Sparse attention plus FP4 precision plus extreme underlying exploitation equals 60% off inference pricing. Understanding these technologies reveals that this sudden price cut isn't about charity or price wars. It's a dimensional reduction attack leveraging technological generational gaps.
Ironically, amid domestic AI market price hikes, the industry formed a tacit consensus within a month: AI should keep getting pricier. Then DeepSeek remained silent, shattering that consensus. Its self-developed trillion-parameter MoE architecture and hybrid attention mechanism that slashes per-token costs make API pricing drop to levels competitors neither want nor dare to match.
This is no longer competition on the same dimension.
DeepSeek never considered burning money for market share. Behind it stands a self-developed complete reasoning framework with full-stack control from underlying operators to upper-layer services. The price cuts occurred simply because costs genuinely decreased.
Meanwhile, enterprises that chose to raise prices—whether actively or passively—inadvertently exposed a harsher reality: Their technology stacks and cost structures aren't under their own control.
After this reshuffling, pricing power in the large model market will shift.
Previously, prices were defined by 'the cost of the best model I can acquire.' Now, prices are defined by DeepSeek's self-developed model costs. When the anchor has been slammed to floor-level pricing, vendors who raised prices will suddenly find themselves with no cards left to play.
The affordable processing capability for million-token contexts makes long-text analysis, complex agent tasks, and cross-round memory/planning—previously suspended due to cost concerns—economically viable. This isn't just a breakthrough in model capabilities; it's the underlying permission for an impending explosion in application-layer development.
The DeepSeek platform promptly dispelled rumors that this price cut was 'to respond to competition.' 'This adjustment reflects the natural transmission of our cost advantages to the market after forming a positive cycle between technology and scale effects,' the company stated. This explanation carries more weight than any counterattack.
05
Final Thoughts
Looking back at this entire event, a deeper narrative emerges.
Prices are never just numbers; they're the material manifestation of power structures. When pricing power shifts from suppliers to efficiency leaders, it signals the breakdown of old paradigms.
In the early 20th century, Ford utilized assembly lines to slash car prices from luxuries for the wealthy to something affordable for the working class. The driving force wasn't charity but a generational leap in production efficiency. Today, DeepSeek cutting large model API prices to one-tenth of competitors' follows the same logic. Whoever masters underlying efficiency gains pricing power. Whoever holds pricing power defines the next era's infrastructure.
Silicon Valley propagates a widespread narrative: AGI will be secretly born in some lab and single-handedly reshape the world. DeepSeek's practice offers a quieter narrative: True power shifts don't require spectacular benchmark runs or groundbreaking papers. They just need a technical report hiding a line of text that reduces costs to levels no one can follow. Then, on an ordinary weekend, the price list gets quietly updated.
Tokens will eventually become as basic a resource as electricity and water. This has been said for years, always sounding like a vision. Until this weekend, when it suddenly became something purchasable for 0.025 yuan.
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







